We are thrilled to announce that Oracle Database 23ai (Release Update 23.5) is now available for the on-premises Exadata Database Machine, enabling our customers to reap the latest and greatest data management technology benefits.
It is an exciting time for Oracle, with many ground-breaking announcements, such as the excellent Exadata Database Service on Exascale Infrastructure and the revolutionary Exadata Exascale technology it utilizes, and the fantastic new partnership with Google to deploy Exadata, Oracle Database, and other data management cloud services into Google data centers.
Today marks another milestone with the general availability of Oracle Database 23ai for our on-premises Exadata customers. Oracle Database 23ai is the latest long-term support release of Oracle Database. It includes an extraordinary list of new features and capabilities, including AI Vector Search, JSON Relational Duality, True Cache, Lock-Free Reservations, Priority Transactions, JavaScript Stored Procedures, built-in SQL Firewall, and over 300 more, all meticulously crafted to increase productivity, efficiency, performance, availability, and security. With the release of Oracle Database 23ai, Exadata Exascale is now also available on-premises on X8M and newer Exadata Database Machines.
Please take a few minutes to watch Juan Loaiza, Oracle’s Executive Vice President of Mission-Critical Database Technologies, provide an overview of the latest release of our flagship database.
I also encourage you to read Dom Giles’ fantastic blog post announcing Oracle Database 23ai, which highlights many key improvements.
In this post, we’ll focus on how the Exadata platforms – Exadata Database Machine, Exadata Cloud@Customer, and Exadata Database Service – accelerate and enhance Oracle Database 23ai.
The AI Era
Oracle Database 23ai introduces impressive new capabilities to enable new and existing applications to search data semantically and combine the meaning of data with the business data already stored within the database. We call this capability AI Vector Search. As Doug Hood and Ranjan Priyadarshi put in their blog post explaining AI Vector Search:
A vector, or vector embedding, is a popular data structure used in AI applications. A vector is a list of numbers, generated by deep learning models from diverse data types (e.g. images, documents, videos, etc.), that encodes the semantics of the data.
Oracle AI Vector Search allows you to generate, store, index, and query vector embeddings along with other business data, using the full power of SQL. As an example, for searching documents, vector search is often considered more effective than keyword-based search, as vector search is based on the meaning and context behind the words and not the actual words themselves.
Oracle AI Vector Search allows you to combine semantic document search with searches on structured document properties. For example, in a database of technology articles, a question such as “find articles about fine-tuning Large Language Models (LLMs) for enterprise use cases that have been published in the last 5 years by a certain author and a certain publisher in a certain country”, requires searching both the article text as well as article attributes, that may be present in one or more tables.
In other words, the Oracle Database stores, processes, and joins this new type of data with existing business data to enhance applications and user interactions with more contextual and meaningful results.
To enable this capability, Oracle Database 23ai introduces the VECTOR data type, new SQL operators to create the vector embeddings stored in the VECTOR data type, new VECTOR optimized indexes, and new SQL operators to easily express similarity search in business queries and combine semantic information with business data. Exadata and the recently released Exadata System Software 24ai bring complementary new features that accelerate this new generation of use cases.
Low-Latency AI Queries
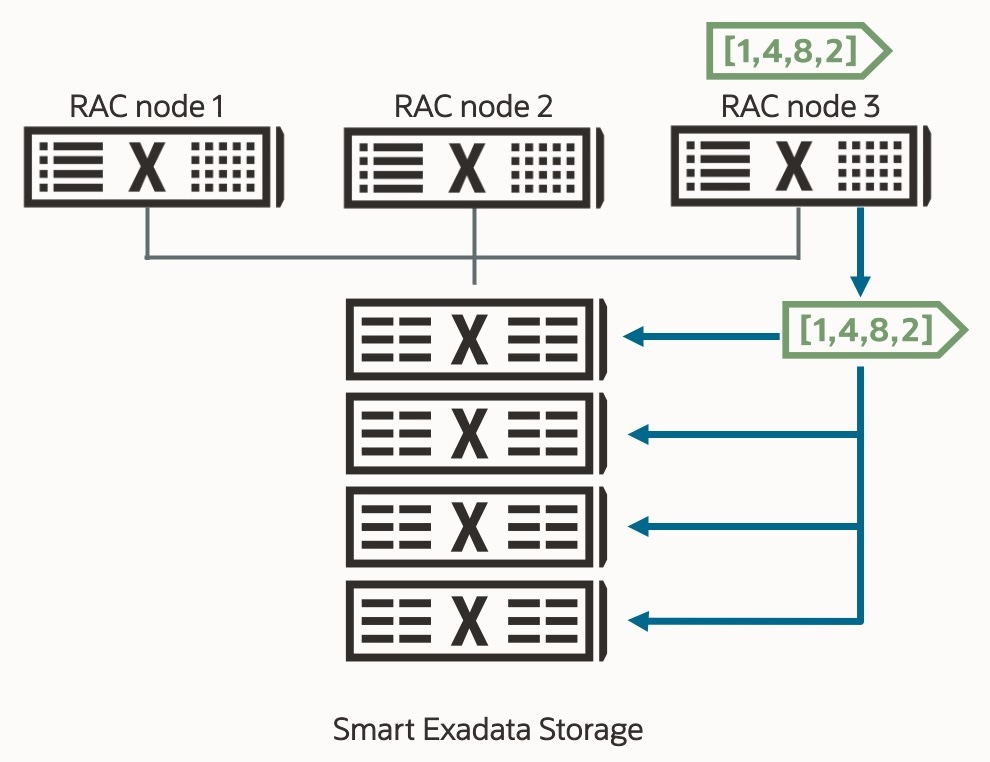
One of the fundamental attributes of Exadata is its ability to scale workloads. It does this using the horizontal scalability of Real Application Clusters (RAC) on the database servers – utilizing the ultra-fast RDMA network and unique data transfer optimizations to increase performance – and by offloading work from the database to the Exadata storage servers to process data in place, rather than send data from storage to the database servers, only for much of it to be discarded. This data processing offload, known as Smart Scan or SQL Offload, has been available on Exadata since its inception. It is typically used for data analytics, where vast volumes of data are scanned and joined before the result set is returned to the database for final processing.
With AI Vector Search, the need exists to scan vast volumes of vector data, but rather than a report being the result, which may take seconds, minutes, or even hours to produce for complex analytics, AI Vector Search is used in transactional workflows. For example, when asked, “Find articles about fine-tuning Large Language Models (LLMs) for enterprise use cases published in the last five years” the results must come back quickly. If the question has to be refined and asked again after seeing the results, the query performance needs to be as fast or faster. The number of articles we might need to scan here (or the vectors representing them) could be quite significant.
Smart Scan has been optimized for AI workloads to achieve ultra-fast response times when scanning billions of vectors. It scans billions of records on the storage servers, pruning and filtering unneeded data as it does for a traditional analytic workload. It returns only the data required to fulfill the search. However, when executed for AI Vector Search, Smart Scan has been optimized to start faster, allow for reuse of already created Smart Scan sessions (memory and connections), and reduce round-trip data transfers.
Vector Distance Computation
Vectors make it possible to translate the semantic context of a data object as humans perceive it into a position in a vector space—a multi-dimensional mapping of vectors. To determine the semantic similarity of one data object with another, the proximity of the vectors representing these data objects is computed. The closer the vectors are to one another, the more similar they are. Conversely, the greater the distance, the less similar they are. On Exadata, the task of computing the vector distances is given to AI Smart Scan. Recall that we rarely compare the distance between only two vectors and are more likely comparing millions or billions of vectors. By parallelizing not only the scan of the vectors but also pushing the distance computation down to the storage servers, we again avoid unnecessarily moving data to the database servers and instead utilize the optimizations in the high-performance database kernel on the storage servers, resulting in up to 30x faster AI Vector Search queries.
Top-K on Storage Servers
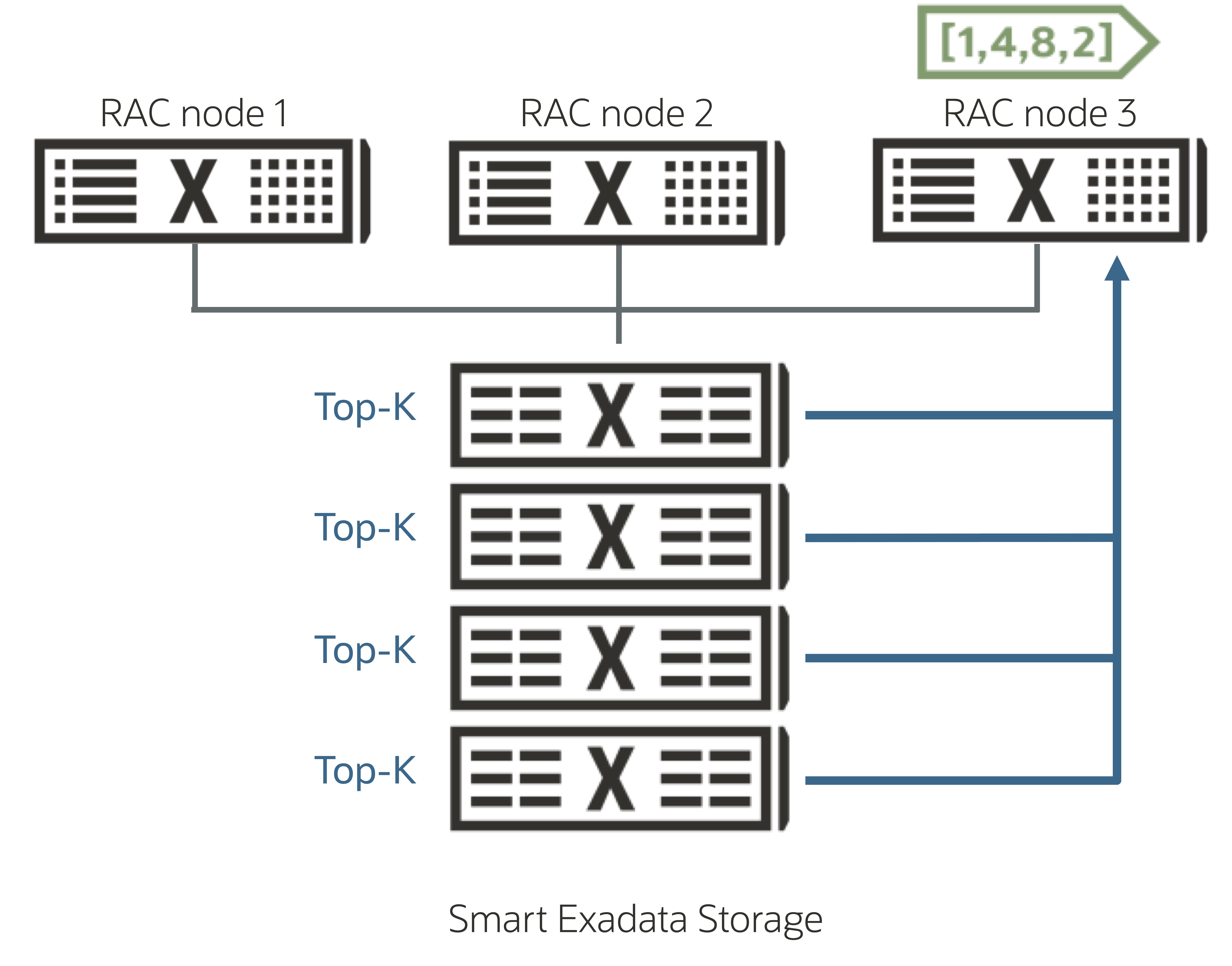
AI Vector Search is inherently a similarity search–approximate search–rather than exact value matches. Consider the straightforward example we explored above–”Find articles about fine-tuning Large Language Models (LLMs) for enterprise use cases that have been published in the last five years“. This query searches for articles that semantically approximate the requirements of being about LLMs and describe enterprise use cases from the last five years. We aren’t expecting an exact match to this query; we are expecting the closest articles. This is known as Top-K (where K represents the number of similar articles we want to return).
In Oracle Database 23ai, a new optimized index specifically for AI Vector Search–the Inverted-file-flat (IVF)–has been introduced to store vectors efficiently. This index is used by AI Smart Scan to dramatically reduce the search space and offload the Top-K calculation from the database servers to the storage servers, again avoiding large data movements to the database servers. The Top-K from each storage server is returned to the database, making the holistic Top-K’s final determination by the database extremely efficient. AI Smart Scan leverages many of Exadata’s impressive performance optimizations–including In-Memory Columnar formats, SIMD processing, Smart Flash Cache and Exadata RDMA Memory (XRMEM) Data Accelerator, and the high-performance database kernel–when calculating vector distance (see above) and Top-K calculation to the storage servers significantly accelerating vector processing.
Memory Speed Vector Search on Storage Servers
The IVF Index (see above) is created as a partitioned table within the Oracle Database. Each partition represents a collection of vectors. As with any table structure on Exadata (even though, in this case, we use it as an index), the hottest data is automatically and transparently converted into the Database In-Memory Columnar format and placed on Exadata Flash Cache to accelerate AI Smart Scan queries. As discussed later in the post, the hottest of this columnar data is automatically promoted into XRMEM, further accelerating AI Smart Scan and enabling AI Vector Search to run at memory speed across vast data volumes.
Exadata Exascale
Exascale Exascale (Exascale) reimagines how compute and storage resources are managed on Exadata platforms by decoupling and simplifying storage management, paving the way for innovative new capabilities. It ensures industry-leading database performance, availability, and security standards that organizations expect from Exadata.
One of Exascale’s ground-breaking features is its reimagined approach to database snapshots and clones on Exadata. It enables space-efficient thin clones from any read/write database or pluggable database, significantly boosting developer productivity. Exascale seamlessly integrates with development, test, and deployment pipeline requirements while providing native Exadata performance.
Databases on Exascale are automatically distributed across all available storage in the Exascale storage cloud, providing ultra-low latency RDMA for I/O and database-aware intelligent Smart Scan with up to thousands of cores available to all workloads. Data is automatically stored on multiple storage servers to ensure fault tolerance and reliability.
Virtual machines and Linux filesystems, such as ACFS and XFS, can also take advantage of Exascale. The awesome new Exascale Block Volumes provide ultra-low latency RDMA for block device I/O and enable virtual machine image files and other filesystems to be hosted on shared storage. Hosting Exadata virtual machine image files on Exascale volumes will enable simple, fast online migrations between physical database servers for Exadata’s unique RDMA-enabled database workloads. This is expected to significantly reduce virtual machine downtime and performance brownouts during planned physical server maintenance in the short term, ending with online virtual machine migration and eliminating virtual machine downtime for physical server maintenance in the longer term1.
Exascale is engineered to coexist with existing Exadata deployments, allowing our customers to choose when to take advantage of its capabilities.
More information on Exadata Exascale is available on Exadata Exascale Announcement Blog.
In-Memory Columnar Speed for JSON Queries
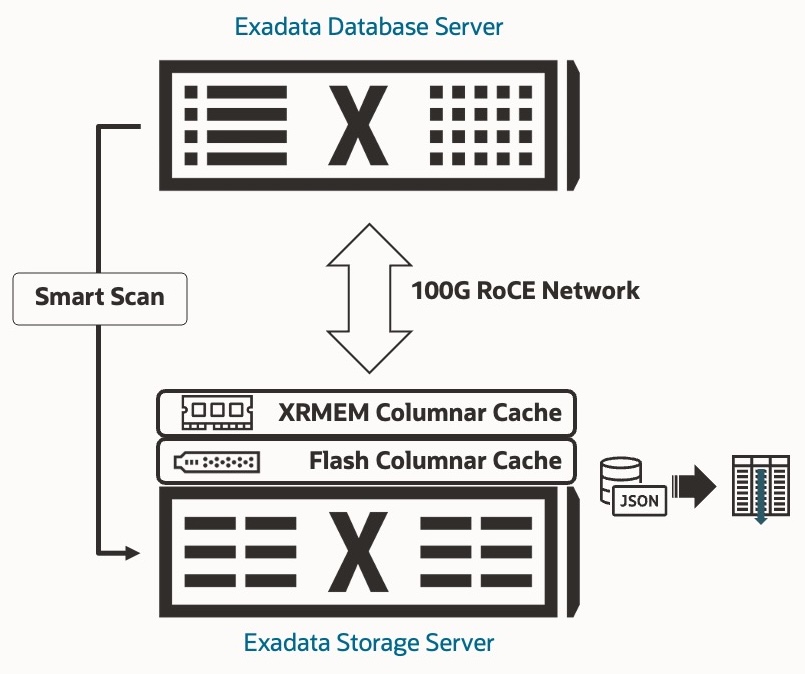
The JSON data format is the de facto standard for data exchange. It is widely used in application development owing to its lightweight structure and ease of readability by machines and humans. With support first added in Oracle Database 19c, the use of JSON and storage thereof in Oracle has increased significantly, as has the need to perform analytics on JSON data stored in the Oracle Database. Analytics, you say. Right in Exadata’s wheelhouse. (Anything related to data is in the Exadata wheelhouse).
To accelerate analytics on data stored in JSON documents, Exadata automatically and transparently converts JSON documents (19c OSON representation and the 23ai native JSON data type) into the Database In-Memory columnar format and loads them into Flash Cache. The In-Memory columnar format has been available on Exadata since Exadata System Software 12.2.1.1.0 (released in 2017) and extends the Database In-Memory feature (introduced in Oracle Database 12.2) into flash on the storage servers, vastly increasing the amount of capacity for columnar data processing (up to 27.2 TB flash per storage server). We call this In-Memory Columnar Cache on Exadata Storage Servers. By converting data stored in JSON documents to the In-Memory columnar format on the storage servers, analytic queries can achieve up to 4.4x higher throughput and up to 4.4x lower latency. In other words, more and faster analytics queries on JSON data.
Columnar Smart Scan at Memory Speed
Exadata RDMA Memory (XRMEM) is a data caching tier that utilizes memory in X8M and newer Exadata storage servers to cache the hottest OLTP data in memory. Oracle Database 19c and newer uses Remote Direct Memory Access (RDMA) to read data in the storage servers as if in the database server, decreasing single-block read latency to as little as 17 microseconds on X10M storage servers.
Just a minute – you said the In-Memory Columnar Cache was beneficial for analytics. Why are we talking about XRMEM, which is used to accelerate OLTP?
I’m glad you asked. Beginning with Exadata System Software 24ai, Exadata X10M automatically and transparently promotes the hottest columnar format data from Flash to XRMEM, just as with OLTP data. Smart Scan now directly accesses the columnar data in memory, accelerating analytic queries up to 6.5x and enabling sub-second, OLTP-like AI Vector Search queries using the new AI Smart Scan facilities.
Transparent Cross-Tier Scan
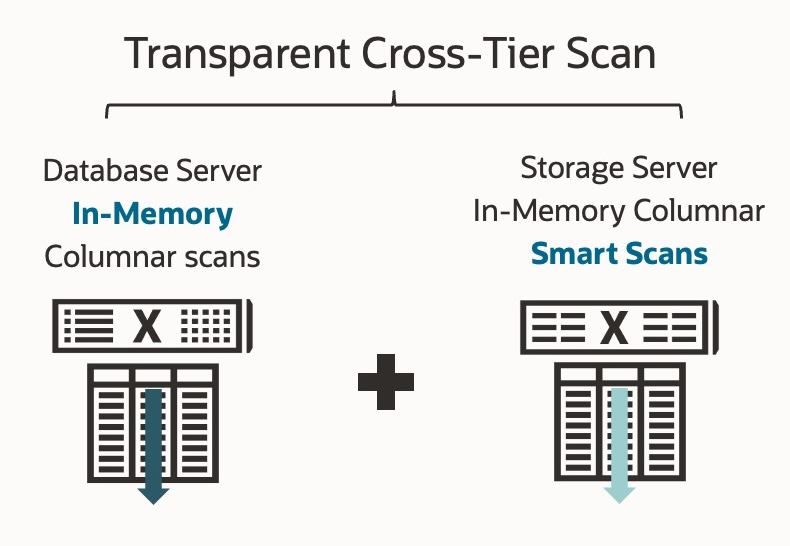
Exadata has been capable of extending the Database In-Memory (IM) Columnar format into the storage servers since 2017. When using Database In-Memory on Exadata, data can be stored in the database and stored on the storage server in the in-memory columnar format. When in-memory columnar data is used, the database optimizer must decide between reading the IM columnar stores on the database or storage server, but not from both. Depending on the volume of data being processed, using only the database or storage columnar store may be appropriate; however, if the volume of data needed by the query spans both the database AND storage server, this choice may result in a sub-optimal execution plan.
Exadata Storage Server 24ai and Oracle Database 23ai remove the need to choose with Transparent Cross-Tier Scan. With Transparent Cross-Tier Scan, the database optimizer no longer must choose between in-memory columnar stores on the database and storage server. A single query (executed in serial or as a parallel query) can scan both the in-memory store on the database servers AND use Smart Scan to scan the In-Memory columnar formatted data in Flash and XRMEM on the storage servers.
Enabled by CPU optimizations, including SIMD Processing, data pruning, dictionary encoding, and data compression, Transparent Cross-Tier Scan accelerates analytic queries using the database AND storage servers’ in-memory capabilities by up to 3x.
Faster Hash Joins on Larger Tables
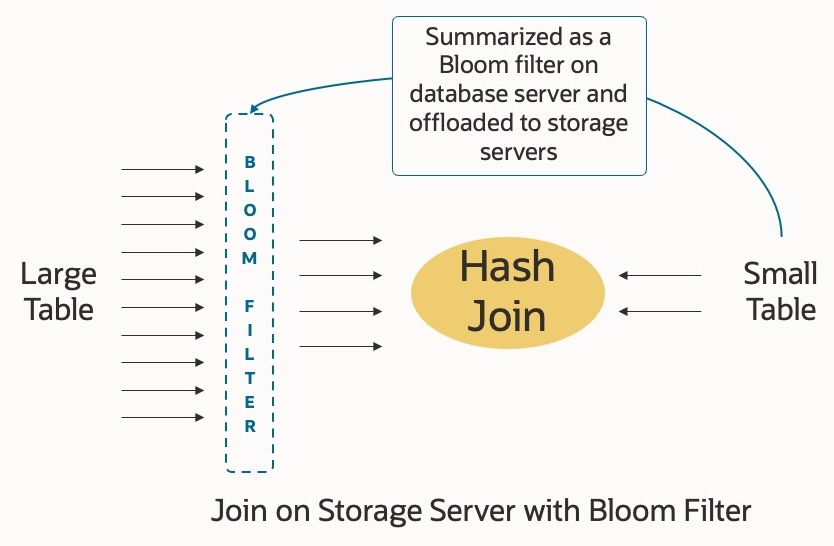
Analytics and reporting workloads operate on vast quantities of data, combining data from multiple large tables and providing insights and trends over multiple years of data. The primary method for joining tables in such workloads is the Hash Join.
Since Exadata’s inception back in 2008, Oracle Database has used Bloom filters to optimize hash joins. Bloom filters can be considered summaries of the smaller table in a join, which enables the database optimizer to quickly test the probability of whether an element (a row in the larger table) exists in the smaller table. This probability test enables the database to discard unmatched rows extremely quickly and improves the effectiveness of hash joins. On Exadata, we have always offloaded (pushed down) these Bloom filters to the storage servers to avoid pulling data from storage to the database servers that will be discarded and distributing the hash join across multiple storage servers in parallel.
Bloom filters are not objects stored in the database, but despite being relatively small, they require memory on the storage servers. As tables grow, the potential size of a Bloom filter also increases. With each new generation of Exadata, the memory capacity of the storage servers has increased. In Oracle Database 23ai, the size of Bloom filters offloaded to storage servers has increased significantly to accommodate larger tables, enabling the storage servers to do more work where the data resides.
By increasing the size of Bloom filters offloaded to the storage servers, analytic query performance increases by up to 2x! This is a nice speed-up without having to change any application SQL.
Data Encryption
Data security – and data encryption in particular – has become a perpetual topic in our daily conversations and a common requirement for Oracle databases on-premises and in the cloud. Oracle mandates the use of Transparent Data Encryption (TDE) in Oracle Cloud database services, i.e., Exadata Database Service on Cloud@Customer, Exadata Database Service on Dedicated Infrastructure (including Database@Azure and Database@Google), Base Database Service, and our many Autonomous offerings.
Migrating Oracle databases to Oracle Cloud Infrastructure, or even when using TDE in your on-premises databases, requires database files to go through an encryption process. In the cloud, encryption happens during the migration. On-premises encryption allows you more control over when the encryption takes place. In both cases, however, many customers require these databases to be immediately usable after the migration and during encryption. Online encryption has been possible since Oracle Database 12cR2 (12.2). Still, for databases residing on Exadata, Smart Scan would be disabled on data in tablespaces (and data files) being encrypted, potentially resulting in lower performance.
With Oracle Database 23ai, Smart Scan is always available during encryption, providing up to 4x high analytic query performance. In addition, Smart Scan supports the AES-XTS encryption mode for TDE tablespace encryption added in Oracle Database 23ai. Moreover, Smart Scan is available during online rekey and related operations, automatically and transparently handling non-encrypted and encrypted data.
Index-Organized Tables
Index-Organized Tables (IOTs) are handy in high-throughput OLTP applications such as online trading, payment, and retail platforms. They store data alongside the data retrieval key in a B-tree index structure for fast access and pre-sorting data when used in analytics. Beginning with Oracle Database 23ai and Exadata System Software 24ai, IOTs, including compressed IOTs, now use Smart Scan. Analytic queries on IOTs using Smart Scan are up to 13x faster.
Wide Tables
Oracle Database 23ai increases the number of columns a table may contain from 1000 to 4096. Some workloads and applications are designed to denormalize data to the point that 1000 columns on a table are insufficient. In these circumstances, joining multiple tables was an oft-used, though not ideal, workaround. The increased column limit reduces the complexity of heavily denormalized data. On Exadata, this increase in the width of a table is transparently and automatically handled by Smart Scan (SQL Offload).
Smart Scan During Timezone Upgrades
Countries may occasionally change their time zones or adjust how they handle daylight savings time (DST), leading to the ongoing need for updated time zones and DST data to be loaded into the database. While this new time zone data is generally shipped with Oracle Database updates and patches, customers may choose to install it if needed in their database. With Database 21c, installing new time zone data does not require a database shutdown. It is important to note that, unlike most updates and patches applied to the database, time zone updates can change metadata and table data.
Before Oracle Database 23ai, Smart Scan could not be used for queries on tables with a time zone column during a time zone data update. Oracle Database 23ai improves query throughput during time zone data updates because Smart Scan remains available for queries on tables with a time zone column unless the table contains a TIMESTAMP WITH TIME ZONE data type.
Smart Scan Offload of New Functions and Operators
Oracle Database 23ai adds the BOOLEAN data type to simplify storing and processing TRUE and FALSE truth values. Along with the BOOLEAN data type, the TO_BOOLEAN() function and ‘IS FALSE,’ ‘IS NOT FALSE,’ ‘IS TRUE,’ and ‘IS NOT TRUE’ predicate operators have been added. 23ai also adds new Date CEIL and FLOOR functions and Interval CEIL, FLOOR, ROUND, and TRUNC functions. All these operators and functions have been included in Smart Scan in Exadata System Software 24ai, increasing analytic query performance.
Pipelined Log Writes
Redo log write latency has always been critical to the overall performance of Online Transaction Processing (OLTP) applications. The sooner the redo is written to persistent media, the sooner the transaction is finalized. On Exadata, Smart Flash Log Write-Back automatically and transparently caches the redo logs in the Flash Cache in write-back mode, eliminating hard disk latency as a potential performance bottleneck by writing to Flash. Smart Flash Log Write-Back is transparently coupled with Exadata Smart Flash Log, which simultaneously sends the log write to two flash drives to eliminate write I/O latency.
Oracle Database typically treats each redo write as a serial and atomic operation, which means that before the next redo write is issued to storage, the previous write has to be acknowledged as received and written to storage. On Exadata X10M, the database has access to an ultra-fast network between the database and storage servers, super-fast flash, and the previously mentioned optimizations. The log writer process (LGRW) in Oracle Database 23ai (and Database 19c RU22 – January 2024) no longer waits for the acknowledgment of the previous log write before sending the subsequent redo write request. LGRW will begin sending the next redo write while the last request is still in motion. This overlapping of write requests creates a pipeline of redo log writes flowing from database servers to storage servers, improving transaction processing by up to 1.45x.

Automatic KEEP Object Load into Exadata Flash Cache
Some OLTP workloads benefit from permanently pinning a table in the Smart Flash Cache. Administrators can proactively pin such tables by altering the table definition in the database to add the CELL_FLASH_CACHE KEEP attribute, then initiating a full table scan to begin loading the table into the Flash Cache.
Beginning with Oracle Database 23ai and Exadata System Software 24ai, the need to manually execute the full table scan from the database is removed. It’s gone! Alter the table as below, and the storage servers automatically start loading the table into Flash Cache.
Pinning tables in Flash Cache is generally not required nor recommended, but if you have a table that absolutely must achieve a 100% Flash Cache hit ratio, this is the way to do it.
You can watch the load process for the table in question by using CellCLI to ‘list flashcache content where objectnumber=<table_object_number> detail'.
Summary
The release of Oracle Database 23ai is exhilarating. It represents our flagship database’s latest long-term support release and includes a tremendous list of new features and capabilities, such as AI Vector Search, JSON Relational Duality, Priority Transactions, SQL Firewall, Readable Per-PDB Standby, and over 300 more. With Exadata, on-premises or in the cloud, Exadata Exascale, and Exadata System Software 24ai, significant performance, security, and ease-of-use capabilities are available to help you meet any data management requirement.
For more great information, take a look at the following valuable resources:
- Exadata System Software 24ai New Features documentation
- My Oracle Support Note – Exadata Database Machine and Exadata Storage Server Supported Versions (Doc ID 888828.1)
- My Oracle Support Note – Release Schedule of Current Database Releases (Doc ID 742060.1)
- Oracle Database 23ai New Features Guide documentation
- Oracle Database General Availability Announcement
Footnotes
- Available in a future release




