Containers have been used for many years and are a part of everyday life for most of us. Today I’m going to take a moment to talk about what it takes to be successful when working with containers in a multi-architectural world.
What we’ve done in the past
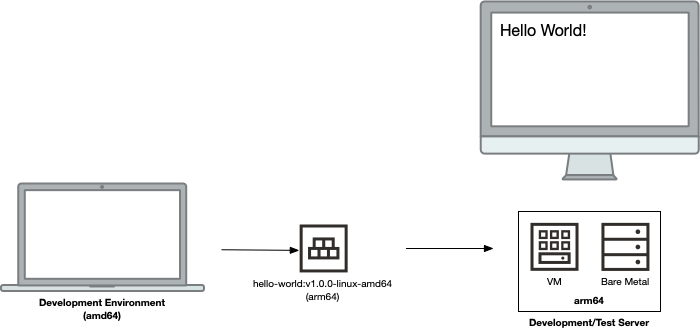
When building containers, the default is to build a container for a target architecture that’s the same as the local CPU architecture. For several years, most computers (both desktops and servers) have used an amd64 (aka x86_64) CPU architecture, which makes things relatively simple. It’s super easy to build a container, push it to a registry (such as OCI Registry) and then test it on a server. Before anyone writes in, this wouldn’t be a suitable scenario for production use-cases, but is more thinking of a development/testing use-case (more rigor and discipline is needed for production environments, which I won’t go into in this article).
Here’s an over-simplified view of what this might look like:
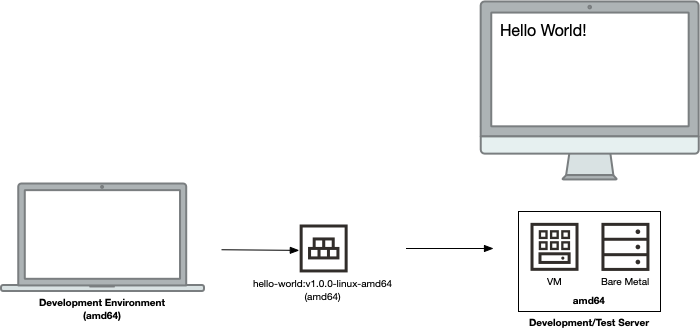
Mixing it up
What happens when we introduce Arm processors into the equation? This is a real-world reality. Arm processors are prolific within the personal computer space (hello Apple M1!) and some cloud providers are offering Arm computing services (such as Oracle Cloud Infrastructure (OCI) Arm shapes). If you’ve not looked at the OCI Arm (A1) shapes, you really should take a look at them! They’re available in both bare-metal and virtual machine and offer a tremendous cloud computing solution.
Let’s say that I get a new Apple M1-based computer and have been using an OCI VM.Standard.E4.Flex shape (an amd64 / x86_64 shape). If the shape name seems confusing, check out the OCI docs for a bit more info on the different OCI shapes. Here’s what this would look like:
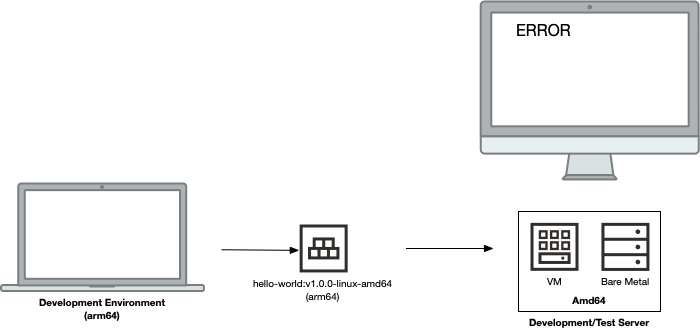
Uh-oh! The container I built on my local Apple M1, by default, is for arm64 (aka aarch64). But the server I’ll be testing against is amd64 (aka x86_64). By default, when the container is run, it will result in an error. This makes sense, as we’ve built binaries (using binaries that are taken from the base container, plus any other application binaries we might have compiled locally) for one architecture (arm64) and tried to run it on a different architecture (amd64). Fireworks. Explosions. Tense action music. Yep, you get the picture. It doesn’t work.
To be a bit more exhaustive, it is possible to emulate one architecture on a different architecture. This is typically a fallback (last resort), not something that we want to rely on. Just because something is possible does not mean that you should do it! Be aware that there are risks and potential failures that can occur should you head down the emulated path.
Let’s flip the tables and say that I’m using an Intel-based computer to generate containers that I try running on an OCI VM.Standard.A1.Flex (an arm64 / aarch64) instance. Here’s what this scenario looks like:
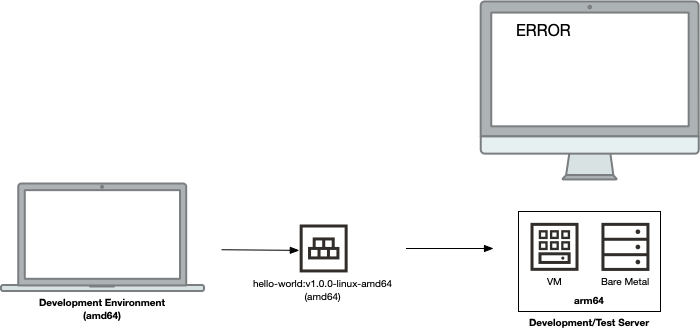
This is another architecture mismatch, which will result in failure! That is, unless you head down the emulation route (which is not an ideal scenario).
The solution
A multi-architectural environment introduces some additional complexities. It requires a degree of intentionality that we’ve not had to exercise historically. Let’s look at each of the above failed scenarios and see what would result in success.
First, when building an image on an Arm-based platform (such as an Apple M1-based system) and deploying to an amd64 system, we need to build the container for amd64:
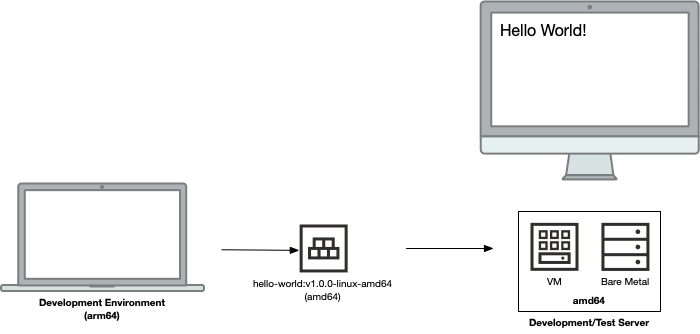
Things are terrific with this scenario! Although it’s not the native architecture on the development desktop, by building the container (and obviously any associated application binaries) for amd64, we’re able to seamlessly run the container on an amd64 system.
For the second failed scenario, we simply build the container (and application binaries) for the target architecture we’re deploying against. In this scenario, we need to build an arm64 container (and binaries) on an amd64 host:
Hello Manifests
We can ensure that we’ll have the maximum compatibility by building containers (and application binaries) for both target architectures (arm64 and amd64) at the same time. This is the best solution, as regardless of which architecture the container might be run on, we’re prepared for it. Here’s what this looks like:
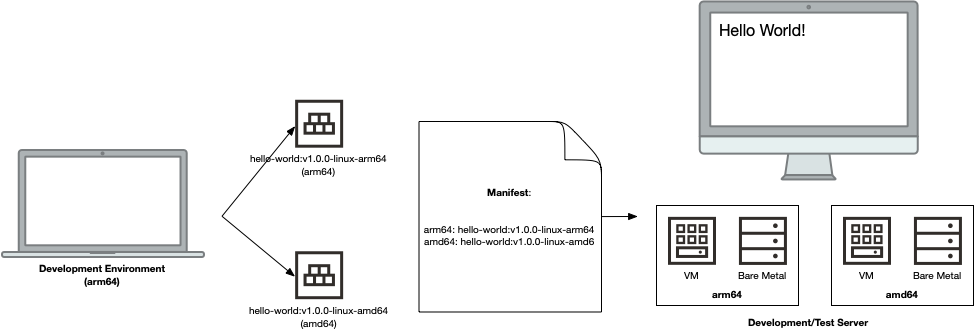
There are a couple of ways that we can do this. We could take the approach of generating the containers so that each architecture has its own architecture-specific tag. While this is pretty nifty, it has the drawback that the correct tag must be used for the target (runtime) architecture. This isn’t too big of a deal when manually running a container. Looking at operationalizing the container (taking it production), it’s a different story. We don’t typically want Kubernetes (K8s) deployments to have different deployments for different target architectures, but rather deployments that “just work” and successfully run a pod without issue, regardless of the node architecture. This is where manifests come into play!
A manifest effectively stores the digests and (architecture) attributes of multiple container images and provides a single, clean tag that can be used, regardless of architecture. A picture is worth a thousand words, so let’s look at a sample manifest:
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.list.v2+json",
"manifests": [
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 529,
"digest": "sha256:1234...",
"platform": {
"architecture": "arm64",
"os": "linux"
}
},
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 529,
"digest": "sha256:9876..",
"platform": {
"architecture": "amd64",
"os": "linux"
}
}
]
}
The manifest is able to be referenced like a container and tag (such as hello-world:v1.0.0), however it simply points to other containers, depending on what the runtime (target) architecture is, so that the proper architecture-specific container can be run.
If I was doing docker run hello-world:v1.0.0 on a amd64 OCI instance, Docker would read the manifest and then look for a digest that matched linux/amd64 (the 9876… one). Likewise an arm64 OCI instance would run the container with a digest of 1234…!
Manifests are super awesome, making life simple. They’re like a directory (or index) of containers-matched-to-target-architectures so that the runtime environment can select the correct container for its architecture.
Conclusion
This article has been pretty high-level, as I want to cover the basic principles and goals for what we’re doing. As with any subject, there’s a great deal of complexity and lots of rabbit holes that we can dive into, however this suffices for a high-level “getting started” perspective.
Keep an eye out for future articles where we’ll dive into the practicalities of this, looking at how to build container images for multiple architectures, as well as package them nicely into a manifest. Until next time, happy coding!
