In this sixth article of the series, we describe and provide full source for a mixed reality app that takes any visual and audio input from a user’s surroundings, processing it with various AI, and returning output of summaries, results of generative AI, etc.
This is the sixth piece in a series on developing XR applications and experiences using Oracle and focuses on visual and audio input from a user’s surroundings, processing it with various AI, and returning output of summaries, results of generative AI, etc. Find the links to the first five articles below:
Develop XR With Oracle, Ep 1: Spatial, AI/ML, Kubernetes, and OpenTelemetry
Develop XR With Oracle, Ep 2: Property Graphs and Data Visualization
Develop XR With Oracle, Ep 3: Computer Vision AI, and ML
Develop XR With Oracle, Ep 4: Digital Twins and Observability
Develop XR With Oracle, Ep 5: Healthcare, Vision AI, Training/Collaboration, and Messaging
As with the previous posts, I will specifically show applications developed with Oracle database and cloud technologies using Magic Leap 2, HoloLens 2, Oculus, iPhone and Android, and PC and written using the Unity platform and OpenXR (for multi-platform support), Apple Swift, and WebXR.
Throughout the blog, I will reference the corresponding demo video below:
Extended Reality (XR) and AI in Everyday Life with Contextual and Situational Awareness
I will refer the reader to the first article in this series (again, the link is above) for an overview of XR. This piece is focused on Mixed Reality/Augmented Reality use cases and AI though there are certainly an amazing number of examples where AI is used in VR and we will explore those in future blogs in the series. The combination used to develop these applications is a powerful and perfect one. Unity, Cohere, and other Oracle AI services, and at the heart of the solution the Oracle database.
A Perfect XR AI Fullstack Solution: Unity, Kubernetes, Oracle AI and Cohere, and Oracle Database
The application architecture consists of a full stack with Unity creating the front-end, Java Spring Boot and other microservices running in Kubernetes (which can consist of NVidia compute) forming the backend and calling out to the various AI services and the Oracle database storing the various information including vector, spatial, etc. data.
Here are some of the many examples.
Each is triggered by a voice command via the XR headset’s voice recognition system.
“Explain this…”


In reaction to this command, the Unity client-side app takes a picture from the headset wearer’s point of view and sends the picture to a serverside Spring Boot app running in Kubernetes (though Kubernetes is not a requirement nor is Spring Boot, and this can be achieved with Python, Javascript, .Net, and other languages including languages running directly within the database). The server-side app calls the Oracle Vision AI service which detects and returns the text in the picture (the text can be at any angle, etc. and the service will interpret it correctly). The server-side app then takes this text and passes it to Cohere (or Hugging Face or OpenAI) to get an explanation of the health report, in both text and speech, in simple terms and suggestions on ways to improve results/health. The image, content, and summary are stored in the database where further analysis can be conducted, from basic advanced text search to image analysis, Oracle Machine Learning and AI, etc.
This use case shows how complex medical information and health test results can be easily and quickly interpreted and corrective actions taken by a common person without the need for or supplementary to a professional health care worker.
User says: “Summarize this…”


This example is very similar to the “Explain this” example and simply illustrates the versatility of such command functionality. In this case, the content is summarized, again in both text and speech, in x (eg 3) sentences or less.
This use case shows how mass amounts of information can be quickly consumed.
User says: “Select all from summaries”


In reaction to this command, the Unity client-side app calls the server side to query the Oracle database and return various information such as the images and texts of the previous commands that were recorded.
This use case obviously goes beyond this scenario. It is effectively the ability to query the database for anything and do so from anywhere and use all of the complex features the Oracle database has to offer. Queries can be based on text, speech, images, AI of voice-to-text-to-SQL, situational and environmental information and sensors, etc. and include advanced analytic queries, etc.
User says: “Transcribe [YouTube video]…”


In reaction to this command, as opposed to “Transcribe Audio” which takes or records an audio clip for transcription, the app will check to see if a YouTube URL is in the user’s view and if so will use the API to get the transcription of the video. It can additionally be “transcribed and summarized” as described previously.
This use case again shows how mass amounts of information can be quickly consumed and can be taken from a number of different input sources including video and audio which may be advantageous for a number of reasons or for those with vision or hearing impairment.
User says: “Generate image [of …] stop generate image”

In reaction to this command, the Unity app starts recording the user’s speech and stops when the user says “Stop generate image”. The speech is sent to the server-side application which then transcribes it, removes “stop generate image” from the end of the transcription, and sends the text description to Stable Diffusion (or DALL-E, etc.) which creates an image and passes it (or it’s URL location) back to the application and back to the headset which displays the image in front of the user.
This is a very simple example of course, and this functionality is no longer limited to 2D but also 3D images, sounds, etc., and demonstrates the ability to dynamically generate and add visual context for quick storyboarding, collaboration, and training, AEC (architecture, engineering, and construction), etc. and of course gaming. This can also be used with USD (Universal Scene Description) and tech such as NVidia’s Omniverse platform for extremely compelling collaboration experiences.
User says: “Tell a dystopian story about this and give sentiments…”


In reaction to this command, again the Unity client-side app takes a picture from the headset wearer’s point of view and sends it to the server-side component that this time uses Oracle Vision AI to identify all of the objects in the user’s view. It then sends these objects to Cohere (or other AI) and asks that a story of a certain style be generated from the contents. This story is then further analyzed using Oracle’s AI Sentiment Analysis service and the story and the sentiment analysis are sent back to the user to view in both text and speech.
This use case again shows not only a potential for creativity and creating of a story around a mood or interesting setting of objects but can be used for situational analysis in any number of military and police, health and safety, social, etc. scenarios.
In the third blog of this series (Develop XR With Oracle, Ep 3: Computer Vision AI, and ML), two other examples were given…
User says: “Identify objects…”


In reaction to this command, again the Unity client-side app takes a picture from the headset wearer’s point of view and sends it to the server-side component that this time uses Oracle Vision AI/Object Detection to detect the objects and their relative coordinates. These are sent back to the Unity client-side app which projects raycasts through these coordinates to draw bounding boxes with identification labels on the spatial location of the objects in the room and to also speech the object names from the spatial coordinates where they are located.
As far as use cases in this and other commands/functionality mentioned, it is not difficult to imagine the potential to assist with vision impairment, Alzheimer’s, identification of unknown and difficult-to-isolate items, analysis of threats, interests, etc., by having the XR device give contextual audio and visual feedback about one’s surroundings.
User says “Start conversation…”
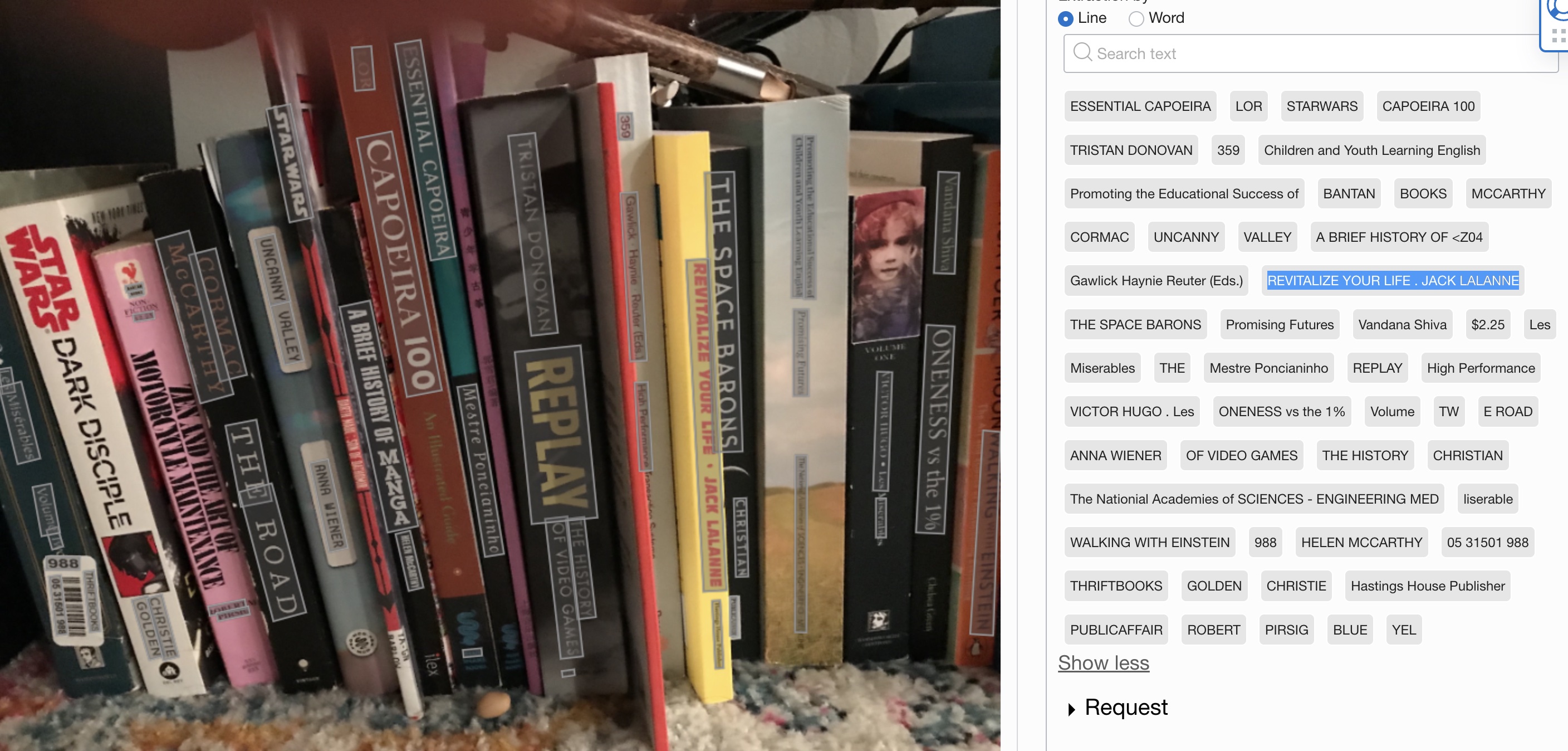

In reaction to this command, again the Unity client-side app takes a picture from the headset wearer’s point of view and sends it to the server-side component that this time uses Oracle Vision AI/Document AI to retrieve the text found (various book titles), pick a title at random, and send the text to a number of (at that point GPT-3 was the latest) conversation models which then feedback various conversational responses. These responses, or again any information from various models, are given to the user.
There are again so many situational awareness use cases that such functionality provides but the ability to strike up a good conversation is powerful enough.
The Source Code, OpenXR, and Other Dev Details
I will describe key snippets of the programs and components involved in this application in this blog. The full source code for both the Unity frontend and Java backend can be found at https://github.com/paulparkinson/develop-xr-with-oracle. This repos will continue to grow with examples of other functionality, different languages, frameworks, etc. It is also where code for an upcoming “Develop XR with Oracle” workshop will be located. A basic understanding of Unity and Java (for these particular examples) will be required along with particulars of the XR headset you are using.
This application has been tested on Hololens 2 (shown in the pictures and video of this blog) and Magic Leap 2. The Unity application is coded using MRTK 3 (mixed reality toolkit) which conforms to the OpenXR standard. Magic Leap recently joined the MRTK steering committee which was formed by Microsoft and includes Qualcomm as a member. This wide adoption of OpenXR makes applications written to it more portable, however, Apple is not a member, and similar to other technologies where software and varying hardware must work together, even with this standard code must have adapters for certain native functionality, particularly in the XR space where approaches and features may differ greatly between products.
For example, the application(s) described are actually fairly simple (where 1/input generally has a device-specific setup, whereas 2, 3, and to a large extent 4, are generally portable as-is):
- input (picture, video, audio, ..) is taken from the XR device
- input is sent to the server (for AI, database, etc. processing)
- response is received from the server side
- content of the response is given as output (text, picture, video, sound, …)
Let’s look at the “no code” and code involved in the order list above.
We add a MRTK object to our Unity scene. This object contains profiles with configuration for Experience Settings, Camera, Input, Boundary, Teleport, Spatial Awareness, etc. Under Input there are various settings for Controllers, Gestures, etc. including Speech. Here, we simply specify Keywords such as “Explain this”, “Generate image”, etc.
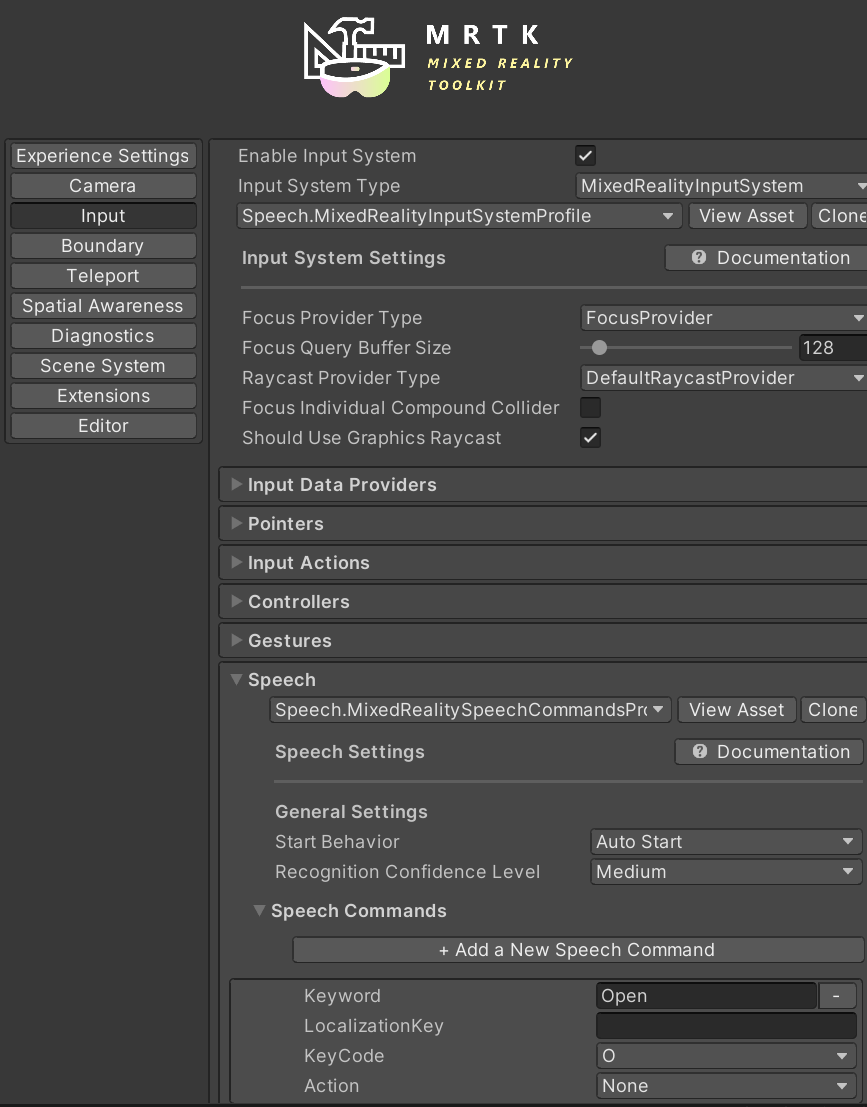
We then add a Microsoft.MixedReality.Toolkit.Input.SpeechInputHandler component to the scene which maps the keywords we defined to actions. For example, here we see the ExplainThis method of an object with the TakePicAndProcessAI script/class will be called when the user says “Explain this”.

Looking closer at the TakePicAndProcessAI C# source we see the following for ExplainThis (similar to other commands involving the general process of sending a picture for AI processing:
C#
public void ExplainThis()
{
endPoint = "visionai/explain";
TakePicAndProcess();
}TakePicAndProcess() contains logic and settings to take a picture and (temporarily) save it locally as well as a OnCapturedPhotoToDisk callback.
OnCapturedPhotoToDisk in turn loads the pic/image into a Texture for display in front of the user and calls the ProcessAI subroutine. This ProcessAI subroutine has code that is dynamic based on parameters provided to it but has the overall purpose of making network calls to the serverside and marshaling data to and from it. It also displays the returned AI content in a text field (or 2d or 3d object as the case may be) for the user to see, executes text-to-speech for the user to hear, etc.
C#
byte[] imageData = image.EncodeToPNG();
WWWForm form = new WWWForm();
form.AddBinaryData("file", imageData, "image.png", "image/png");
if (genopts != null)
{
form.AddField("genopts", genopts);
genopts = null;
}
Debug.Log("Making AI etc. calls, providing file: " + filePath + "...");
UnityWebRequest request = UnityWebRequest.Post(backendURL + "/" + endPoint, form);
yield return request.SendWebRequest();
if (request.result == UnityWebRequest.Result.Success)
{
string jsonResponse = request.downloadHandler.text;
if (textMesh != null) textMesh.text = jsonResponse;
textToSpeechLogic.talk(textToSpeechObject.GetComponent<TextToSpeech>(), jsonResponse);
Debug.Log(jsonResponse);
}
On the server-side we have simple-to-use logic such as the following to process the image sent from the Unity app Vision AI and extract the text found…
Java
features.add(detectImageFeature);
features.add(textDetectImageFeature);
InlineImageDetails inlineImageDetails = InlineImageDetails.builder().data(bytesOfImagePassedInFromUnityApp).build();
AnalyzeImageRequest request = AnalyzeImageRequest.builder().analyzeImageDetails(analyzeImageDetails).build();
AnalyzeImageResponse response = aiServiceVisionClient.analyzeImage(request);
And the following to process the text retrieved from Vision AI to get a summary using Cohere (or Hugging Face or OpenAI)…
Java
AsyncHttpClient client = new DefaultAsyncHttpClient();
client.prepare("POST", "https://api.cohere.ai/v1/summarize")
.setHeader("accept", "application/json")
.setHeader("content-type", "application/json")
.setHeader("authorization", "Bearer [your bearer token here]")
.setBody("{\"length\":\"medium\",\"format\":\"paragraph\",\"model\":\"summarize-xlarge\",\"extractiveness\":\"low\",\"temperature\":0.3," +
"\"text\":\"" + textRetrievedFromVisionAI + "\"}").execute();
And the following to process Oracle database storage, retrieval, and other logic.
Java
//Using JPA
summaryRepository.saveAndFlush(new Summary(explanationOfResults, bytes));
Again this server-side logic can be in any language as all OCI services, Cohere services, and the Oracle Database support them all.
Additional Thoughts
I have given some ideas and examples of how AI and XR can be used together and facilitated by Oracle. I look forward to putting out more blogs on this topic and other areas of XR with Oracle Cloud and Database soon including the use of new advanced features in the Spatial component of the Oracle Database for geometric (.OBJ mesh, point cloud, …) storage, analysis, and processing that works with Unity at runtime in realtime and the ability to run server-side languages colocated within the Oracle database itself. A “Develop XR with Oracle” workshop will also be released in the near future.
Please see my other publications for more information on XR and Oracle cloud and database, as well as various topics around modern app dev including microservices, observability, transaction processing, etc. Finally, please feel free to contact me with any questions or suggestions for new blogs and videos, as I am very open to suggestions. Thanks for reading and watching.
