Hello there,
This is an introductory blog post that discusses the usage of Oracle Streaming Service (OSS) with Apache Kafka Connect.
For an introduction on getting started with Oracle Streaming Service, check out the following blog posts;
Did you know that instead of creating a bunch of code you can use Kafka Connect and just with a settings file do a lot of connections? You can connect with JDBC, HDFS, Object Store, and many others in a simple way.
Kafka Connect (or Connect API) is a framework to import/export data from/to other systems. Connectors are meant to provide a simple way of connecting to external systems, only requiring a configuration file, while the scaling, distribution, and persistence of state are handled by the framework for you. Connectors for common things like JDBC, Object Store, HDFS, Elasticsearch, and others already exist at the Confluent Hub. Official blog announcement and overview

Source connectors allow you to ingest data from an external source. Sink connectors let you deliver data to an external source.
You can check my overview blog post: Kafka Connect a complete overview and look at the Kafka Documentation for more details.
Confluent provides a page where you can see and download all connect available.
Oracle Streaming Service is Kafka compatible and you can use OSS with Kafka connect and get the best of all words. This means that now you can connect with JDBC, Object Store, HDFS, Elasticsearch, and others in a really simple way, only changing a config file.
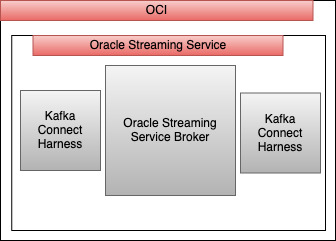
Kafka Connect Harness – Oracle Streaming Service Announced Kafka Compatibility with its Pay-Per-Use fully managed Streaming service, opens up a wide range of use-cases.
Oracle Streaming Service + Kafka Connect harness offers the possibility for developers to move into a fully managed service without having to refactor their code.
Kafka Connect Harness is a part of the OSS that stores some metadata for Kafka connect and enables OSS to connect with other Kafka connectors. The following picture shows the full architecture of a Kafka Connect setup.
On the left part, Source and Sink are the origin and destiny of the data and they can be anything, file system, database, object store, and others, this part can be on-premises or in any place, on the right is the OCI part with the OSS and Kafka Connect Harness inside. In the middle is where we add the Kafka source and Sink part, and this is the part that we need to check how we can host and deploy.

Full architecture overview
The idea here is to show some options on how we can deploy Kafka Connect.
Deploy Options
You can use OSS with Kafka Connect in some ways.
-
On-premise Kafka
-
Docker
-
OKE
-
OCI
This is not an exhaustive list.
Here there is nice a blog post that shows some options.
Starting point
1) On-premise Kafka
Download the JAR file and place it in a folder on your Kafka Connect worker.
Locate your Kafka Connect worker’s configuration *.properties file, and open it in an editor. Search for plugin.path setting, and amend or create it to include the folder(s) in which you connectors reside
In the Kafka Connect configuration file connect-standalone.properties (or connect-distributed.properties) reference the plugins.
plugin.path=/opt/connector/plugin |
Considerations: This is an easy and simple solution, it is good to start, but this will not scale for a big throughput. Good for a test and dev environment.
2) Docker
Confluent provides a Docker image here, but you can use any Kafka connect docker image like Debezium
You just need to copy the jar inside the docker image, but depending on what image you are using the path will be different.
Debezium example:
docker run -it --rm --name weather-connect-demo -p 8083:8083 -e GROUP_ID=1 \
-e BOOTSTRAP_SERVERS="bootstrap_URL" \
-e CONFIG_STORAGE_TOPIC=”ID-config” \
-e OFFSET_STORAGE_TOPIC=”ID-offset” \
-e STATUS_STORAGE_TOPIC=”ID-status” \
-v path/to/local/your_connect.jar/:/kafka/connect/your_connect \
debezium/connect:latest |
Considerations: simple to configure and start and can use an image with everything already configured.
3) OKE (Oracle Kubernetes Engine)
You can run Kafka on Kubernetes
https://www.confluent.io/blog/getting-started-apache-kafka-kubernetes/
You can run with Strimzi as well.
Strimzi on Oracle Kubernetes Engine (OKE)+ Kafka Connect on Oracle Streaming Service(OSS)

Considerations: Resiliency, High Availability, and Fault Tolerance, will scale horizontally, but difficult to configure and start, it brings additional overhead with it that some may consider being too much for trivial use cases.
4) OCI
The idea here is the same as using On-premise Kafka but hosting the Kafka itself in OCI. Of course, here you can run your docker image or run a Kubernetes as well.
Considerations: simple to configure and start.
Getting Started
First, you need to add the right policy in your tenancy
Allow group xyz to manage connect-harness in tenancy |
Authentication
In order to authenticate yourself with Kafka protocol, you will need to use an auth-token. They can be generated in the console on the user details page.

It is strongly recommended to create a dedicated group/user and grant that group the permission to manage connect-harness in the right compartment (or the whole tenancy). You then can generate an authToken for the user you created and use it in your Kafka connect configuration.
tenancyName/username/compartmentId |
For your bootstrap servers, you can use the domain of the region with the 9092 port.
streaming.{region}.oci.oraclecloud.com:9092 |
Setup
In order to set up Kafka Connect, you will require a connect harness OCID which can be obtained on creating a new connect harness or using an existing one.
Connect Harness can be created using Java, Go, Python, or Ruby SDK or by using the console.
Simple Java Example to Create Connect Harness.
List Connect Harness Example
Kafka Connect settings
The following properties are required for your Kafka Connect.
bootstrap.servers=streaming.{region}.oci.oraclecloud.com:9092 security.protocol=SASL_PLAINTEXT sasl.mechanism=PLAIN sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username=”tenancyName/username/streamPoolID” password=”authToken”
Producer Settings
Consumer Settings
Config, Status and Offset Topics
Throttle/Limits
Each message can have a maximum size of 100kb. Request throughput is throttled to 50kb/s.
We also enforce a minimum maxWait time of 200ms.
Every Connect Harness is configured to publish a maximum key size of 10,000 keys or the total size of the keys to not exceed 10mb of total storage.
If the total number of keys or the total size of the keys reaches the set limit, none of the workers will be able to publish any messages.
Upon reaching the max limits you could re-create Kafka Connect Harness and delete the existing one.
Photo by John Barkiple on Unsplash
