Microservices offer clear advantages for cloud-based applications where scalability and portability are non-negotiables. One of the biggest challenges for developers creating microservices is the complexity that results from being forced to use special-purpose databases. While these databases are good at managing one type of data—for example, documents, spatial, graph, or events—developers have to learn multiple database technologies, each with its own nuances.
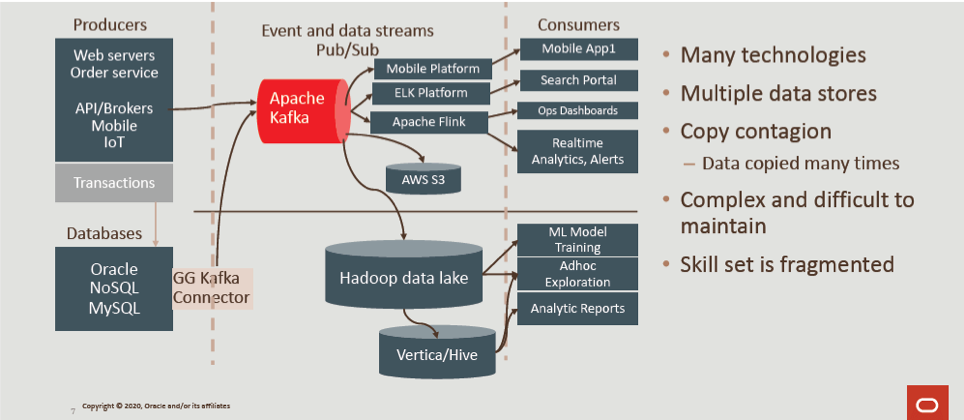
In addition, developers have to copy data from where it’s generated to where it can be processed or stored based on the data type—documents in one place, spatial in another, events in yet another. This leads to copy contagion, data security vulnerabilities, creating a DevOps nightmare.
How a Converged Database Reduces Persistence Layer Complexity
When you’re using special-purpose databases, it’s the developers who have to manage all these different types of data in the application tier. This leads to massive complexity and coding errors for data-driven applications. Developers are basically creating database-like persistent structures in this application tier, which is not where their focus should be.
Is there a way to overcome this complexity? A converged database is a database in which various types of data can all be stored. You can think about it as a software-defined data layer where you can store any type of data—documents, numeric, graphs, spatial, analytical, and events—in any ratio. Contrast this with special-purpose databases where you need to have different technologies and often different vendors and then choose the capacity and optimization techniques for each type of data.
This data store layer—called the persistence layer—is where data is stored beyond when it is generated either from a device or as part of an application workflow. We can use an example of when a mobile order comes in; it triggers some downstream actions in checking inventory, credit checks, and delivery/shipping scheduling. The persistence layer stores this for each microservice so operational analytics can be done in real-time. Metadata can be stored for workflow optimization, especially with multiple instances and multiple threads, which is sometimes stored in the middle tier. If you have this database convergence in the persistence layer, you can maintain that state of the application in the data tier.
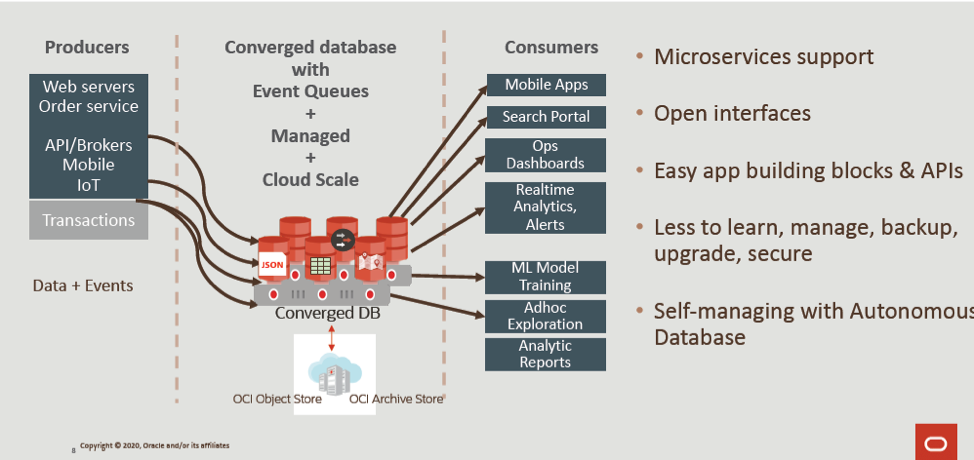
Developers Want Simplicity
Developers are looking for simplicity as they design more complex applications, and microservices need to interact with each other. Because microservices developed by a small team are loosely coupled and have a bounded context, they need to come together like an orchestra does to create a symphony.
Here’s a key concept: Simplicity in the application tier is usually guided by the simplicity in the data tier.
A converged database can make microservices simple to write, scale, modify, and support—both for data-driven and event-driven applications. Data-driven applications can take advantage of the converged database, which has the event/messaging system built-in. The main advantage is transactional messaging that simplifies code development by making a microservice idempotent; i.e., it doesn’t have to handle a message separately the first time and subsequent times.
Oracle’s container technology supports the multiple data types that the converged database supports—i.e., documents, numeric, relational, graph, spatial, and events—in a single database addressable by a popular standards-based single query language, and with drivers for Java, Python, and Node.js.
This is possible because Oracle has containerized the database. Now the developer can take these pluggable databases and move five, 10, 20, or hundreds of them around among containers, cloud regions, and so on.
The gap that still exists is that in a DevOps model, the developer is working in the application tier but now needs to work with an architect to manage what’s happening in the data tier. The developer shouldn’t be focusing on security, routing, networking, and the deployment mesh for the microservice being on-premise or in the cloud.
The Oracle Autonomous Database helps solve this dilemma. Autoscaling is probably the best example of this. Most enterprises today develop data-driven and event-driven apps, where data is front and center to the developers. Typically, developers need to collaborate with architects and DBAs to choose, configure, tune, backup, recover, and scale their application’s data needs. With the Autonomous Database, all these steps can be done without any human direction, once policies are set.
How to Get Started With Microservices Development Using a Converged Database
Developers who have seen the Oracle converged database are asking for easy examples to show them how to use it either to create new microservices or to transition from monoliths to microservices. They are looking for easy-to-use starting points, also to connect the application tier and the data tier and the cloud and on-premise deployments.
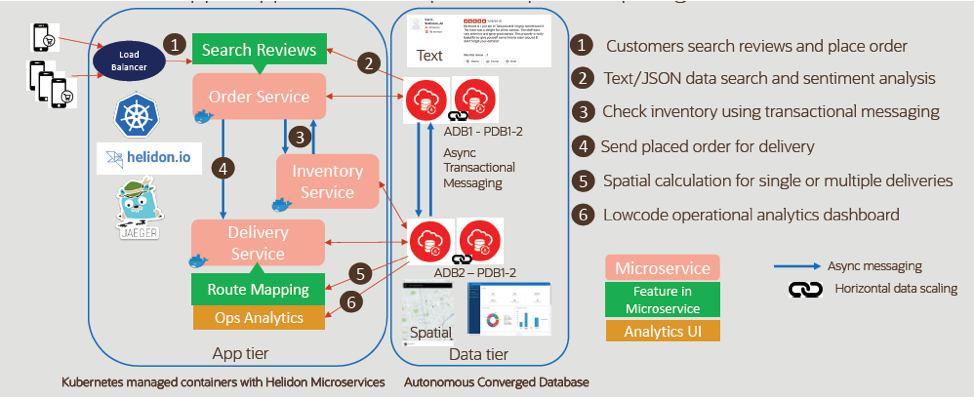
For them, we have designed a set of self-service, hands-on-labs that build “GrubDash,” a hypothetical mobile food ordering application on the cloud. It works off a browser and illustrates the solution approach we’re taking for simplifying microservices.
There are other databases available on Oracle Cloud Infrastructure, including special purpose databases like MongoDB, Kafka, and others that developers can use. There is a caveat: These can add to application complexity as discussed above. However, in some rare cases, workflows may very well be suited for them.
The converged Oracle Database is designed specifically to help simplify application development. When using microservices, the capability of a converged database makes keeping state and data flexible with multiple data types in a flexible database container model. These factors make using an Oracle Database an ideal model for microservices development in the cloud. It’s a fast, flexible, and stable environment for DevOps teams.
Learn more about how you can deploy microservices using an Oracle converged database and Helidon. For help join the databasehome.slack.com (#microservices) slack channel.
Sanjay Goil is Oracle Vice President of Product Management leading product management for Oracle Event Queues in the database, helping developers build robust event pipelines and microservices at horizontal scale—events, messaging, data flows, notifications—building a consistent data and platform experience with the Oracle Database.
