How’s it going there?
Today I want to show how we can get the Oracle Streaming Service (OSS) data using Data Science.
- Data Science is a platform for data scientists to build, train, and manage models on Oracle Cloud Infrastructure using Python and open source machine learning libraries.
- Oracle Streaming service is a Kafka compatible, secure, no lock-in, pay as you use, scalable, cheap streaming solution that allows the purpose mentioned with very low effort and ease to develop and deploy.
- The idea here is to get Donald Trump tweets in almost real-time and do some kind of analysis.
Requirements:
-
OSS instance;
-
Data Science instance;
How does this works?
Oracle OCI Streaming service is mostly API Compatible with Apache Kafka, hence you can use Kafka APIs to produce/consume from/to OCI streaming service and based on that we are going to use the Kafka-Python API.
To connect with Twitter we are going to use the Tweepy API.
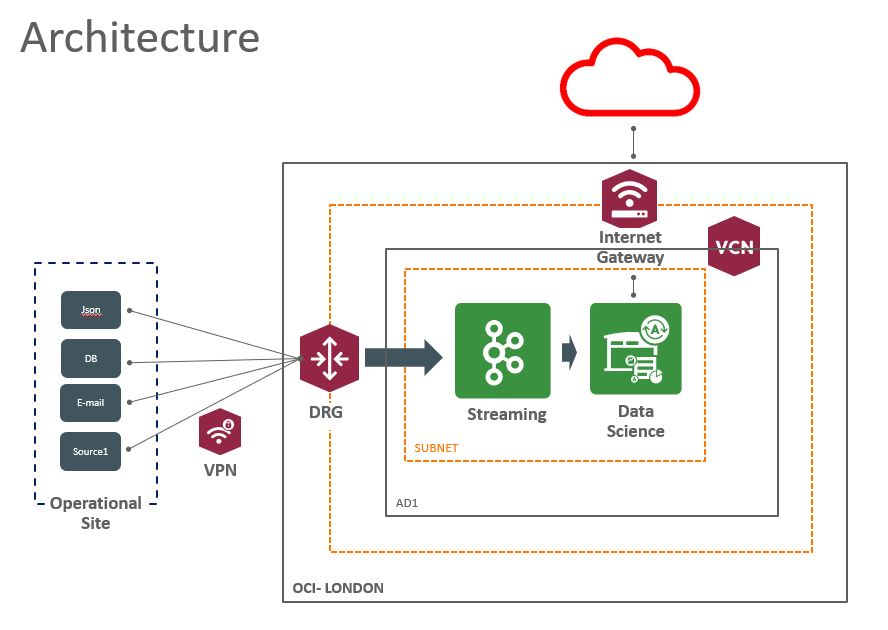
Note: Because OSS is Kafka compatible we can use a Kafka API and this means that you can in an easy way change to use Kafka broker.
Data Science Environment
First, you need some configurations in your tenancy for Data Science.
here
You need to allow Data Science environment to access the internet and for this, you need to configure a NAT Gateway.
here
Note: I suggest you follow the “getting-started.ipynb” first to validate your environment. If you get an “HTTPsConnectionPool” error means that you have an error in your NAT Gateway configuration.
open the Data Science terminal and install the two lib’s.
pip install tweepy pip install kafka-python
OSS Environment
For the OSS you just need to check the authentication part, and for this, you need:
Show me the code
Producer – Application that sends the messages.
Consumer – Application that receives the messages.
For connecting with Twitter you will need credentials.
here.
Great, at this point the tweets are being captured. The execution speed will depend on how “hot/trending” the keywords you defined currently are on Twitter. I defined keywords to collect data about Donald Trump, which is always a hot topic.
Now let’s do some kind of analysis: we can create a class that gets the tweets and saves them than in a file, we can stop streaming when it reaches the limit.
here we can convert the tweets data to pandas
This is a very simple DataFrame, but we can still check some interesting stuff;
df.lang.value_counts() df.source.value_counts()
Now you can play with and so some nice analyses and visualizations as well.
Links
