The Java ecosystem has no shortage of options for dealing with any particular aspect of application development, it is perhaps one of its greatest assets, data persistence is no exception. We’ve got from SQL-to-Java mappers, SQL parsers, SQL generators, ORMs, ODMs, and everything in between. Hibernate and JPA are quite the popular choices that developers pick to connect to databases and handle data but by no means are the only choices. Today I’d like to showcase Jdbi, a lightweight option that lets you combine direct SQL with Java type mappers, among other features.
Jdbi offers a couple of options for mapping Java types to SQL statements and backs. You may use RowMapper or ColumnMappers with SQL statements; if you’re familiar with Spring Framework’s JdbcTemplate then you know of what I’m talking about. Jdbi also lets you map and bind bean classes directly through a feature named SQLObjects, which may be closer to JPA managed beans except that bean classes do not require hints provided by annotations. Instead, Jdbi fosters the definition of DAO (Data Access Object) interfaces that contain the SQL and mapping options. Let’s see one way to combine Jdbi’s SQLObject with Oracle Autonomous Database.
First things first, you’ll need an Oracle Autonomous Database instance up and running, as well as the wallet required to connect to it. If you don’t have one already then I’d recommend you to follow the steps found in Connecting to Oracle Autonomous Database via JDBC and come back here. Next up, we need to configure the set of dependencies to make a simple example work such as
Let’s see, we have jdbi3-core, jdbi3-core, jdbi3-sqlobject, and jdb3-oracle12. Note that we had to use dependency exclusions because jdb3-oracle12 declares a dependency on a very old version of the Oracle JDBC drivers, it’d be better if we consume the latest version directly available from Maven Central, which at the time of posting this blog entry is 19.7.0.0; the use of the ojdbc8-production dependency brings all additional JARs required to connect to Oracle Autonomous Database. Finally, do not that the version number of the jdbi3 dependencies (3.15.0) does not match the version number of jdb3-oracle12 (3.5.1) yet both are the latest at the time of posting. One more thing, the example code makes use of Lombok to simplify bean definitions but in no way Jdbi is dependent on Lombok, you may skip it or use any other alternatives at your disposal to reduce boilerplate code.
Good, we can get started with the code. A single domain class is enough to demonstrate the basic capabilities of SQLObject, a domain class like the following one
There is nothing special about this class, just properties, a toString() implementation, and the use of the builder pattern to create instances using a fluent interface design. Again, all these could be created with different means if you do not like Lombok. Next in line is the DAO object, this is where we get our first contact with the Jdbi SQLObject API
The TodoDao class defines your typical CRUD operations: create, find one, find many, update, delete one, delete many. Note the use of direct SQL statements, some can bind their parameters to the properties found in the Todo bean. All operations require a transaction but only those that read require that the transaction isolation in read committed state. There are of course alternatives to passing a bean instance to these methods, you could pass in property values directly, or a collection of values; it really is up to you to define the surface and shape of the persistence layer that your application requires.
Alright, time to hook up the database with Jdbi. The easiest and performant way to do it is via a pooled DataSource in which case UCP comes naturally as it’s provided as part of the ojdbc8-production dependency. The following class shows a trivial setup of a pooled DataSource using UCP with just a handful of properties, you may of course use different values and/or properties as needed
This class pulls datasource configuration from an external file that loos like this
Great, now we can get to the main class of this example, which for convenience has every step labeled with comments so that we can tell what’s going on in every one of them
The class assumes that the wallet is located at the root directory of the project. If this were not to be the case then the location of the wallet in code must be updated. Next on step #1 the DataSource is created using the factory class we showed before. Jdbi gets initialized on step #2. Instances of Jdbi are thread-safe thus you may safely share them. Note that the SQLObject plugin must be applied otherwise Jdbi will be unable to understand the bean mapping capabilities we expect from the TodoDao type. On step #3 the table layout is created, this particular piece of code drops the table and recreates it every single time. Onward to step #4 is where we see the first use of the TodoDao type to create a set of Todo instances and store them in the database. After this step we expect all todo items to be successfully stored.
Finally, on step #5 we perform a series of queries to verify that the initial data is set up correctly; that we can update the state of a particular Todo item; deleting a single Todo item results in a smaller set when querying all items; lastly clearing the table of all data results in an empty collection when querying the table for all items once again. Running the application results in the following output
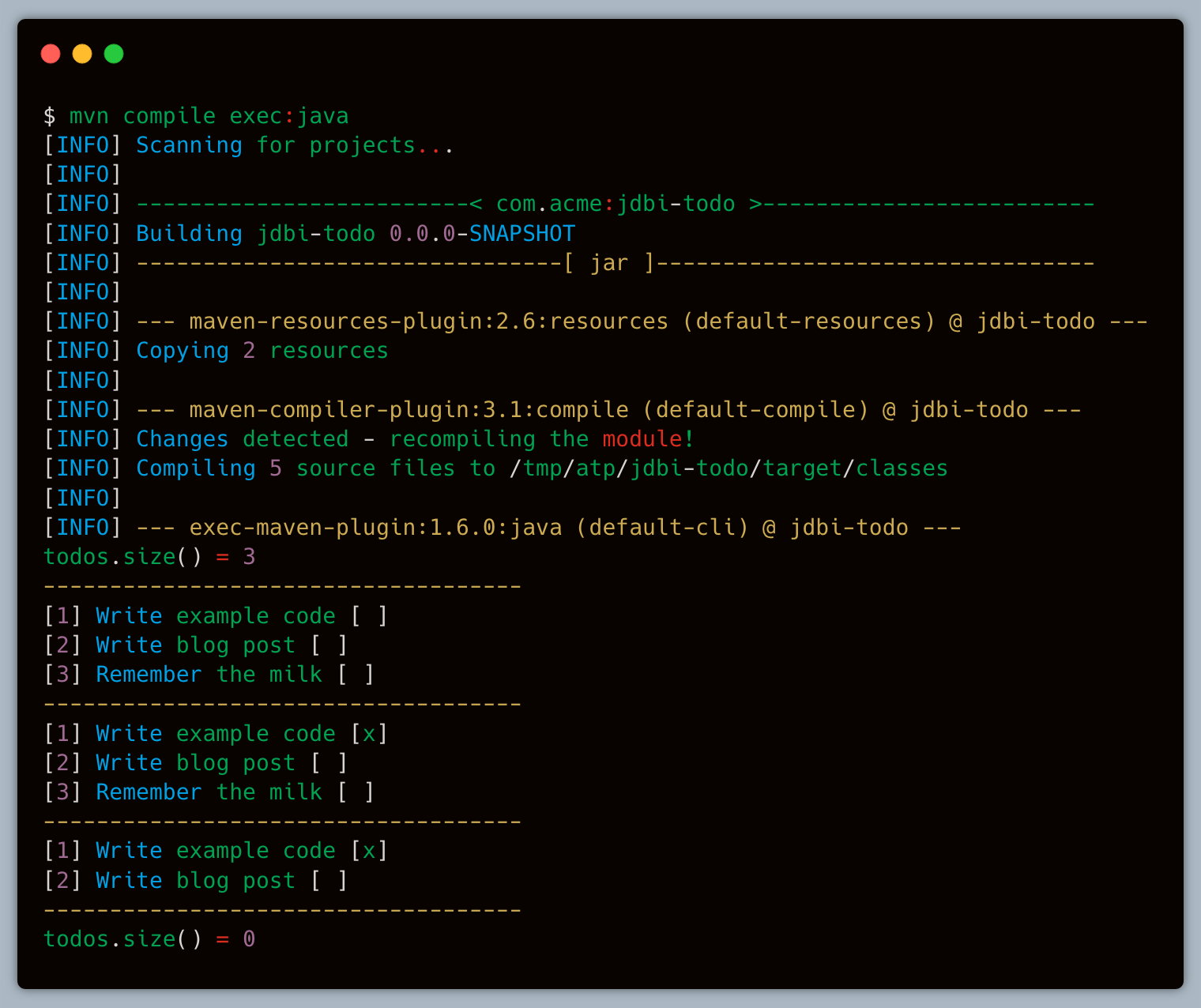
And that’s a short summary of what Jdbi has to offer but it’s by no means all that it offers. Have a look at the documentation, perhaps there’s a feature you like or missed from another persistence library.
Credits
Image by Mario Hagen
