Accessibility Policy
Skip to content
Oracle
Developers Blog
Search
Exit Search Field
Clear Search Field
Menu
CATEGORIES
Archived
Cloud
Community
Back
Community
NetSuite SDN
DevOps
Open Source
Technology
Back
Technology
NetSuite Developers
RELATED CONTENT
Oracle Developers Portal
Oracle Developers on Medium
Oracle Code
Blogs Home
RSS
Developers Blog
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
4
Oracle and DeepLearning.AI Launch New Agent Memory Course for AI ...
Richmond Alake
4 minute read
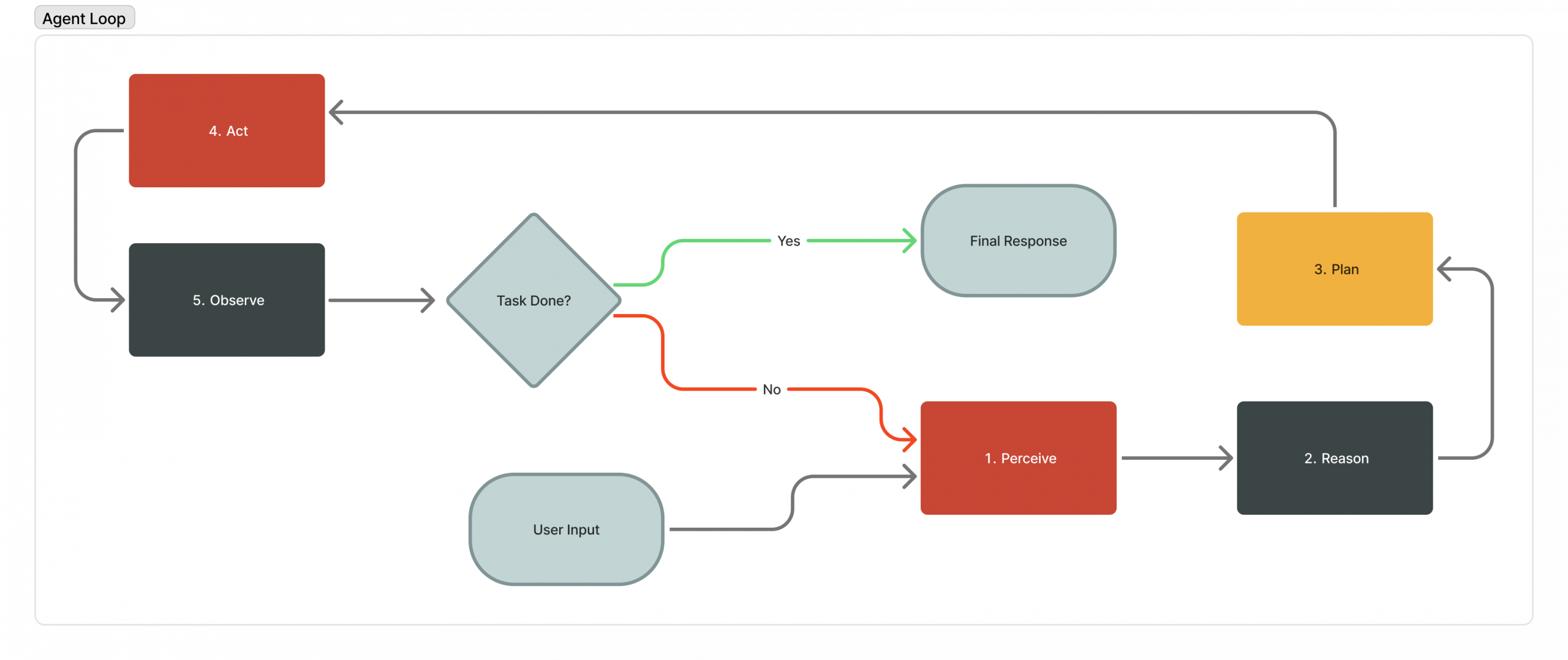
What Is the AI Agent Loop? The Core Architecture Behind Autonomous AI ...
Casius Lee
15 minute read
Agent Reasoning: The Thinking Layer
Nacho Martinez
10 minute read
Build an Ultra-Lightweight, Local-First AI Assistant with Persistent ...
Nacho Martinez
8 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Receive the latest blog updates
Sign up for Developer Newsletter
Recent Posts
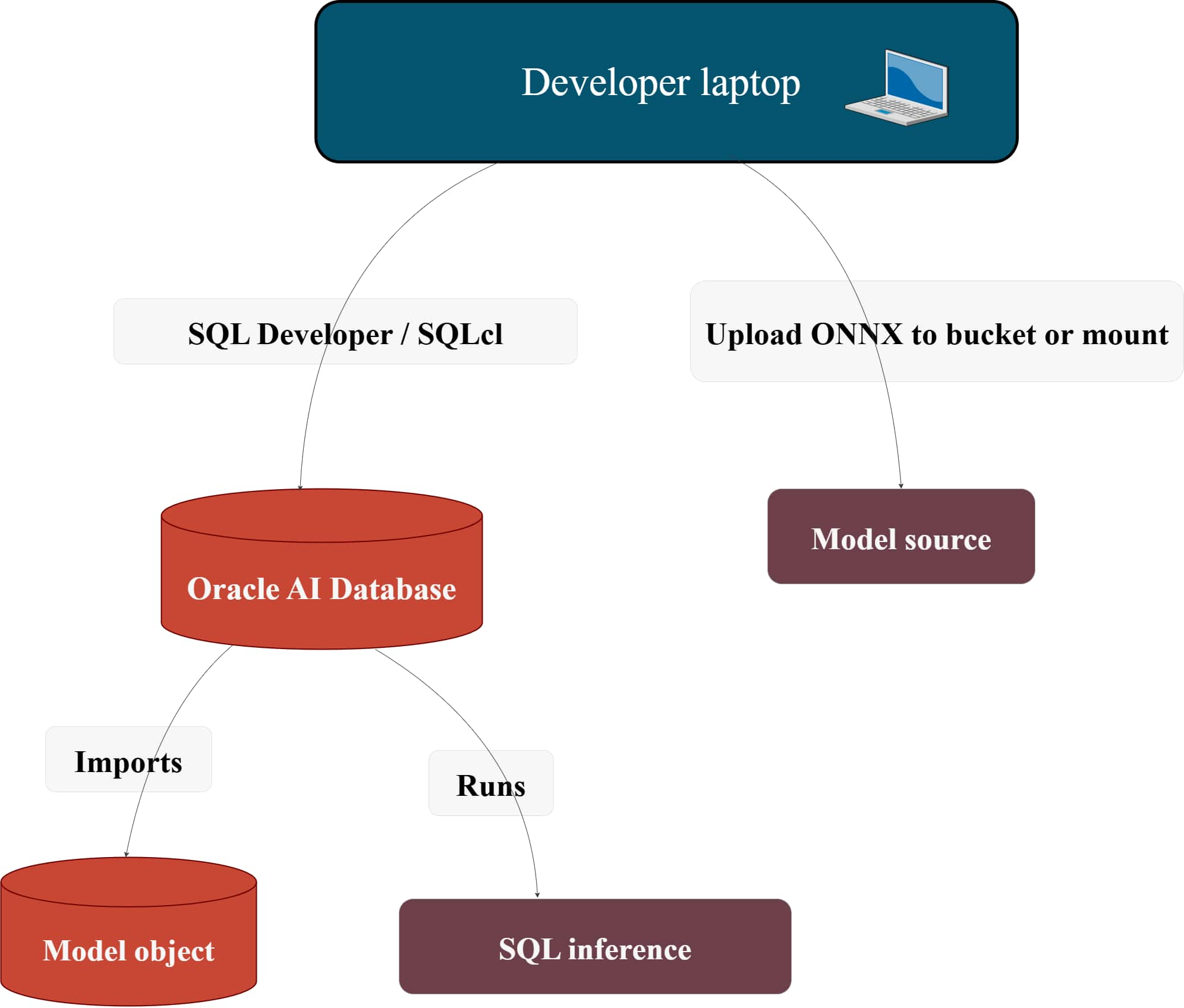
How to Load Embedding Models into Oracle AI Database in 2026
Daniela Pavlenco
13 minute read
SuiteCloud Developer Assistant
Federico Donner
8 minute read
HA App Dev: Architecting for High Availability
Irina Granat
6 minute read
How to fine tune a custom OCI LLM and use it from NetSuite
Wilman Arambillete
11 minute read
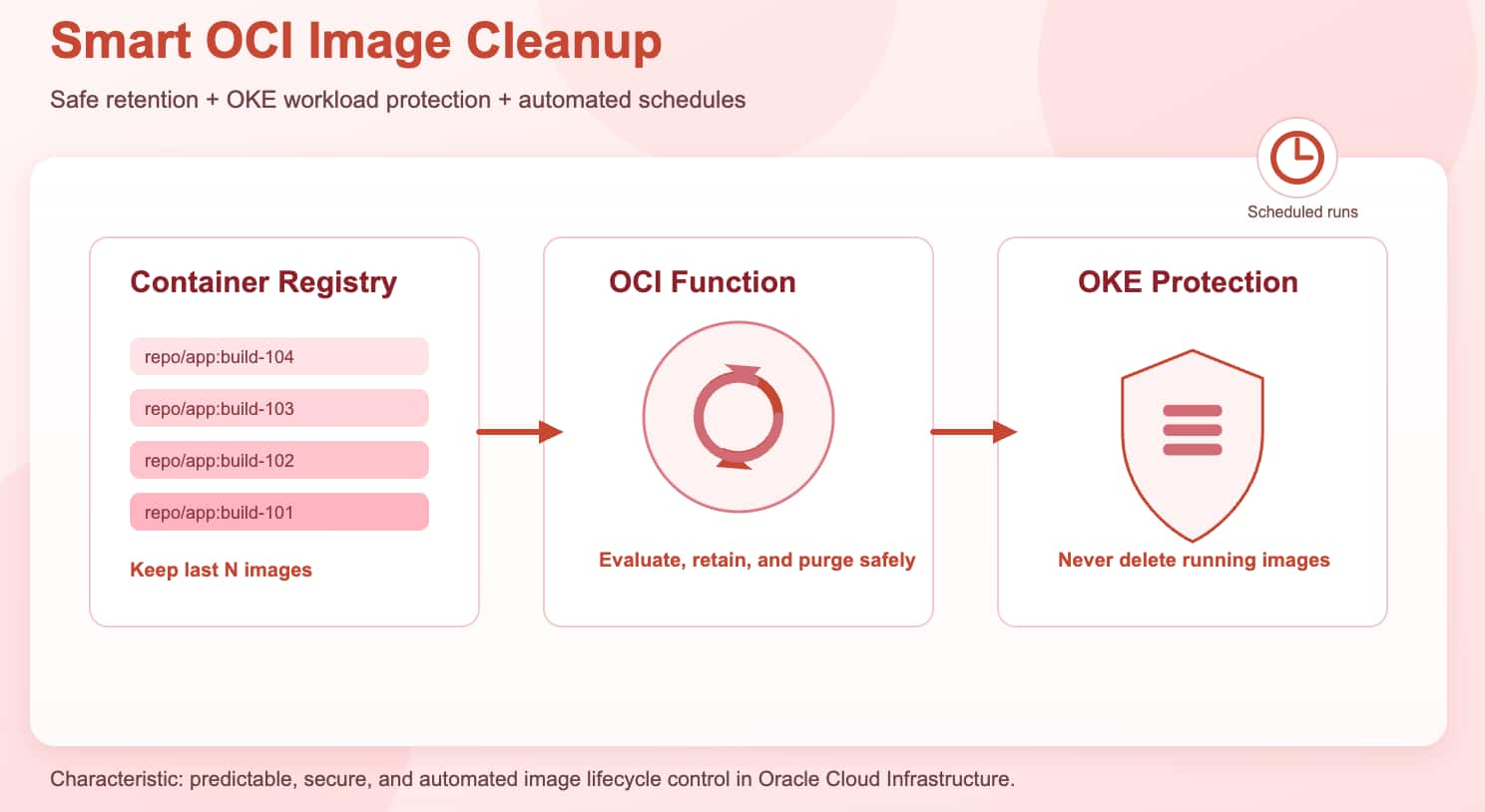
Smart Image Cleanup in OCI Container Registry Using OCI Functions
Joao Tarla
9 minute read
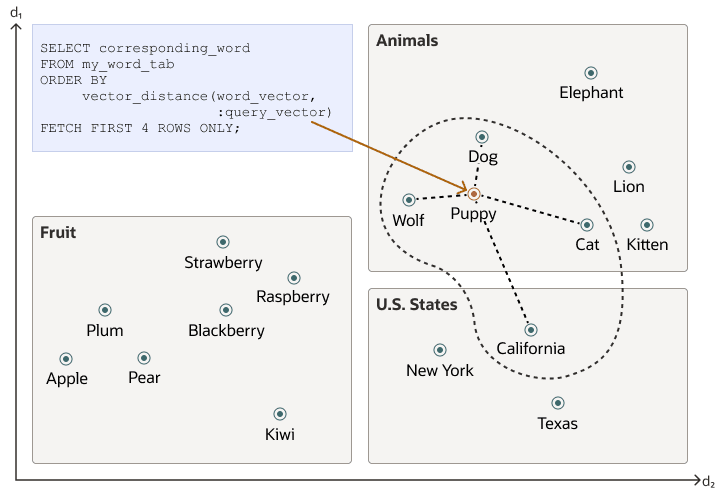
How Do I Store And Query Vector Embeddings?
Victor-Theodor Macry
11 minute read
How to setup and run a free TeamSpeak 6 server on OCI
Zdenek David
5 minute read
Building Scalable Java Applications with Oracle Globally distributed ...
Sambit Panda
4 minute read
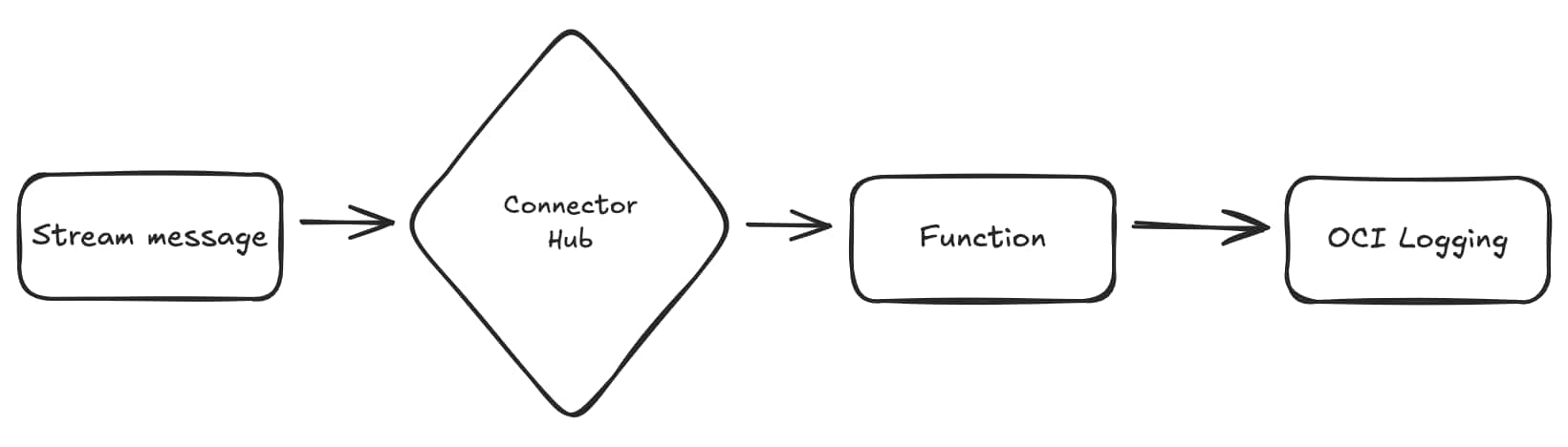
Connect OCI Streams to Functions
Phill Denness
5 minute read
Using Functions with API Gateway
Phill Denness
10 minute read
Oracle AI Database Operator for Kubernetes v2.0.0
Kuassi Mensah
3 minute read
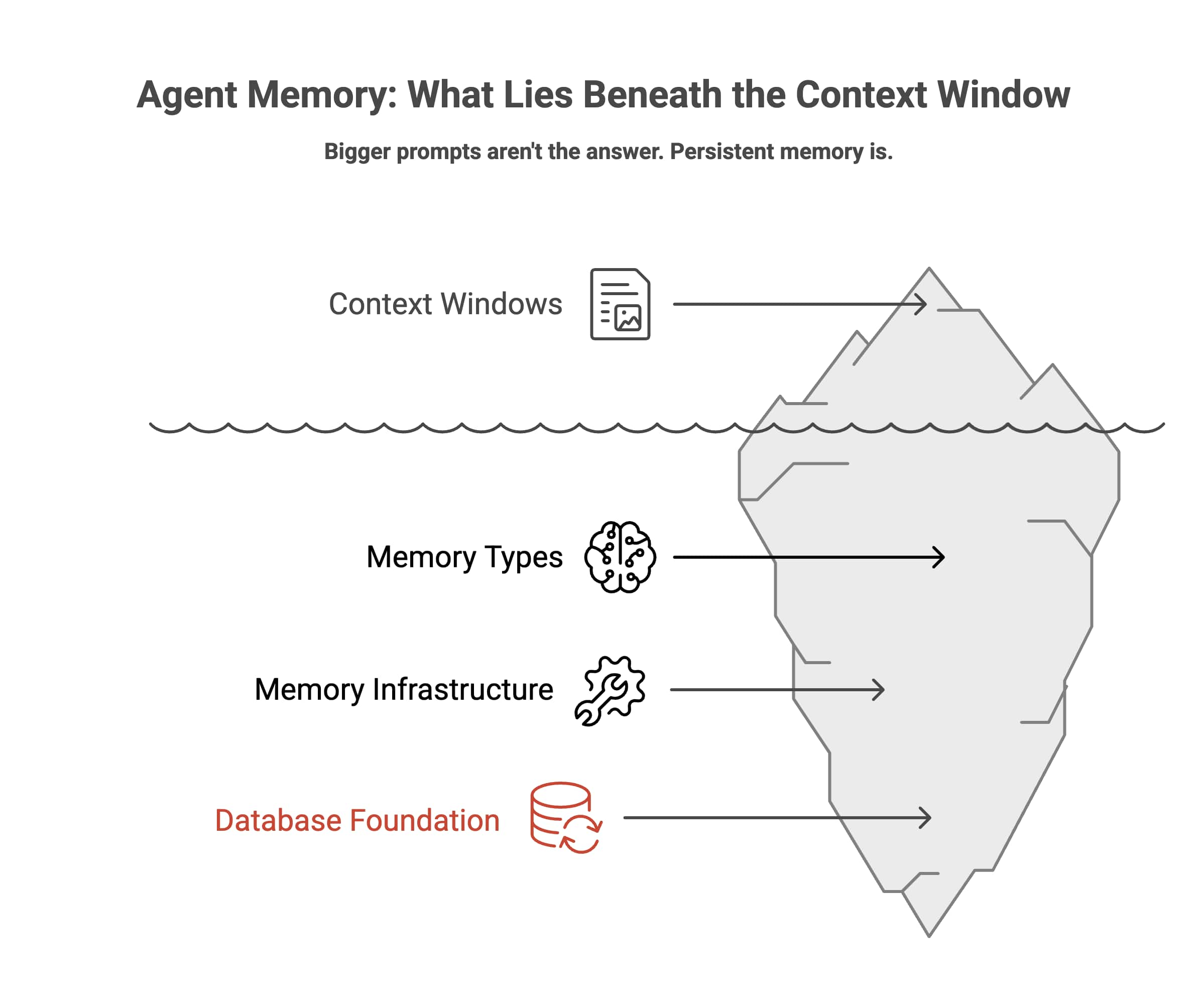
Agent Memory: Why Your AI Has Amnesia and How to Fix It
Casius Lee
16 minute read
View more
Receive the latest blog updates
Sign up for Developer Newsletter
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers