Indexes are used extensively in OLTP databases as they are capable of efficiently supporting a wide variety of access paths to the data stored in relational tables, via index key lookups or range scans. Therefore, it is very common to find a large number of indexes being created on a single table to support a multitude of access paths for OLTP applications and workloads. This causes indexes to
contribute a greater share to the overall storage of the database when compared to the size of the base table itself.
With previous solutions, as discussed in Part 1 and Part 2 of the Index Compression blog series, index entries, with many duplicate keys, can be compressed making it possible to reduce both the storage overhead and the access overhead for large index range scans or fast full scans. Compression can be very beneficial when the prefix columns of an index are repeated many times within a leaf block. However, if the leading columns are very selective or if there are not many repeated values for the prefix columns, then index prefix compression or Advanced Index Compression LOW may not be the best solutions.
New with Oracle Database 12c Release 2 on Oracle Cloud, Oracle has introduced Advanced Index Compression HIGH, geared towards dramatically improving index compression ratios. Advanced Index Compression (which includes both LOW and HIGH levels) is part of the Advanced Compression option and aims at achieving much higher compression ratios and, at the same time, automating
index compression.
The following graph shows sample compression ratios for two datasets using Advanced Index Compression. Along with substantially reducing the storage footprint for the indexes, these workloads also saw substantial improvement in the system performance.
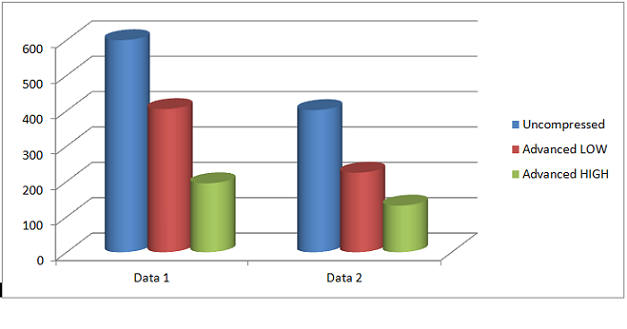
Advanced Index Compression HIGH introduces many additional compression techniques, which improves the compression ratios significantly while still providing efficient OLTP access. It stores the index key entries in Compression Units (a concept similar to Hybrid Columnar Compression), utilizing more complex compression algorithms on a potentially larger number of index keys to achieve higher levels of compression.
There are many similarities for Advanced Index Compression HIGH with both Advanced Row Compression and Hybrid Columnar Compression. A few of the important ones to
note are:
1. Just as with Hybrid Columnar Compression, Advanced Index Compression HIGH uses more complex compression algorithms and techniques to achieve higher compression ratios.
2. Advanced Index Compression HIGH uses a concept similar to internal threshold, used by Advanced Row Compression, to trigger recompression of the data block. Newly inserted data is buffered uncompressed in the block and compressed as the block fullness approaches this internal threshold. This is done to amortize the compression cost over multiple DML operations (inserts). With indexes, this internal threshold is geared towards avoiding index block splits and alleviating the need to allocate additional leaf blocks to the index structure.
3. Every index block can contain a compressed region and a non-compressed region. The compressed index keys are stored in the compressed region (Compression Unit), while the newly inserted keys are stored in the non-compressed region.
4. Advanced Index Compression HIGH supports row level locking and full concurrency as with Advanced Row Compression (or Hybrid Columnar Compression with Row Level Locking enabled).
Some of the compression techniques used with Advanced Index Compression HIGH include (but are not limited to):
– Intra-column Prefix Replacement
Intra-column prefix compression exploits the fact that, as a result of index rows being sorted in key order, there is a high likelihood that a prefix of each keymatches the corresponding prefix of the preceding key even at sub key column level. Replacing the matching prefixes from each row with a reference to the corresponding symbol gives good compression benefits. Additionally, if the
cardinality of the symbol table indexes is low, and a large number of index keys have a matching prefix, bit encoding the symbol table references can further improve compression benefits.
– Length Byte Compression
It is very common to find a large number of rows in an index with short column lengths. Thus, it is possible to encode these lengths in less than a byte (as with the uncompressed and prefix compressed index) and hence save space. Additionally, if all key columns in the block have the same length, the block level fixed length can be stored.
– Duplicate Key Removal
If the index block has a large number of duplicates, it is possible to realize significant space savings by storing the key exactly once followed by a list of ROWIDs associated with the key in sorted order. Intra-column prefix compression can then be applied on top of this transformed representation to further compress the now unique set of keys.
– ROWID List Compression
ROWID List Compression is an independent transformation that takes the set of ROWIDs for each unique index key and represents them in a compressed form, ensuring that the compressed ROWID representation is logically maintained in the ROWID order to allow for efficient ROWID based lookup.
– Row Directory Compression
The general idea behind Row Directory Compression is to layout the compressed rows contiguously in the increasing offset order within each 256 byte region of the index block, which enables maintaining a base offset (once per 256 bytes) and a relative 1 byte offset per compressed row.
– Flag and Lock Byte Compression
Generally speaking, the index rows are not locked and the flags are similar for all the rows in the index block. These lock and flag bytes on disk can be represented more efficiently provided it is possible to access and modify them. Any modification to the flag or lock bytes requires these to be uncompressed.
Not every compression technique is applicable to every index. The decision on which compression algorithms are applicable to an index is made real-time and can differ from index-to-index and block-to-block. The net result is generally better compression ratios, but at the potential cost of slightly higher CPU resource utilization both to maintain the index structure and index access. The CPU overhead is kept minimal by using techniques such as buffering large numbers of rows before triggering compression to amortize the compression overhead, turning off compression on a block after the compression gains drop significantly, the ability to access compressed index keys and selectively decompressing only the keys needed etc.
Advanced Index Compression can be enabled easily by specifying the COMPRESS option for indexes. New indexes can be automatically created as compressed, or the existing indexes can be rebuilt compressed.
CREATE INDEX idxname ON tabname(col1, col2, col3) COMPRESS ADVANCED HIGH;
Advanced Index Compression HIGH works well on all supported indexes, including the ones that were not good candidates for Advanced Index Compression LOW or prefix key compression. Creating an index using Advanced Index Compression HIGH reduces the size of all unique and non-unique indexes while still providing efficient access to the indexes.
For partitioned indexes, you can specify the compression clause for the entire index or on a partition-by-partition basis. So you can choose to have some index partitions compressed, while others are not.
The following example shows a mixture of compression attributes on the partitioned indexes:
CREATE INDEX my_test_idx ON test(a, b) COMPRESS
ADVANCED HIGH local
(PARTITION p1 COMPRESS
ADVANCED LOW,
PARTITION p2 COMPRESS,
PARTITION p3,
PARTITION p4 NOCOMPRESS);
The following example shows advanced Index Compression HIGH support on partitions where the parent index is not compressed:
CREATE INDEX my_test_idx ON test(a, b) NOCOMPRESS local
(PARTITION p1 COMPRESS ADVANCED HIGH,
PARTITION p2 COMPRESS ADVANCED HIGH,
PARTITION p3);
The current release of Advanced Index Compression (both for LOW and HIGH levels) has the following limitations:
· Advanced Index Compression is not supported on Bitmap Indexes
· You cannot compress your Index Organized Tables (IOTs) with Advanced Index Compression
· You cannot compress your Functional Indexes with Advanced Index Compression
You may also want to check out Richard Foote’s blog on Advanced Index Compression. Jonathan Lewis also gives a great example on how index compression can help with
overall database storage and performance.
