In keeping with our mission to be an open and interoperable cloud platform, recently we added the ability to use any object store of your choosing that supports AWS S3 compatible URLs, in Autonomous Database on Shared Infrastructure (ADB-S).
While I recommend using Oracle Object Storage since it is fast, affordable and optimized for Oracle Cloud, this feature enables you to load data into or from your ADB instance using object storage options on the market that you may already be using – Wasabi, Google Cloud Object Storage and many more!
For those less familiar with S3 compatibility, it simply means your cloud storage authentication method and APIs are compliant with the AWS standardized S3 interface format. This minimizes any changes required to your existing applications or tools if they are already using S3 compatible keys and URLs. Check your object store’s documentation if you are unaware of its S3 compatibility. The Oracle Object Store provides S3 compatible URLs too, making it easy to switch it in as your underlying object store as your storage needs change!
Below, I present a great example using Wasabi’s object storage to load some data into Autonomous Database using the DBMS_CLOUD package. If you do not have a Wasabi account and would like to follow along, you may sign up for a free Wasabi trial account. I do assume below that you already have an ADB instance created and ready to use. If not, follow this quick workshop for a walkthrough on how to get started from scratch with Autonomous Database.
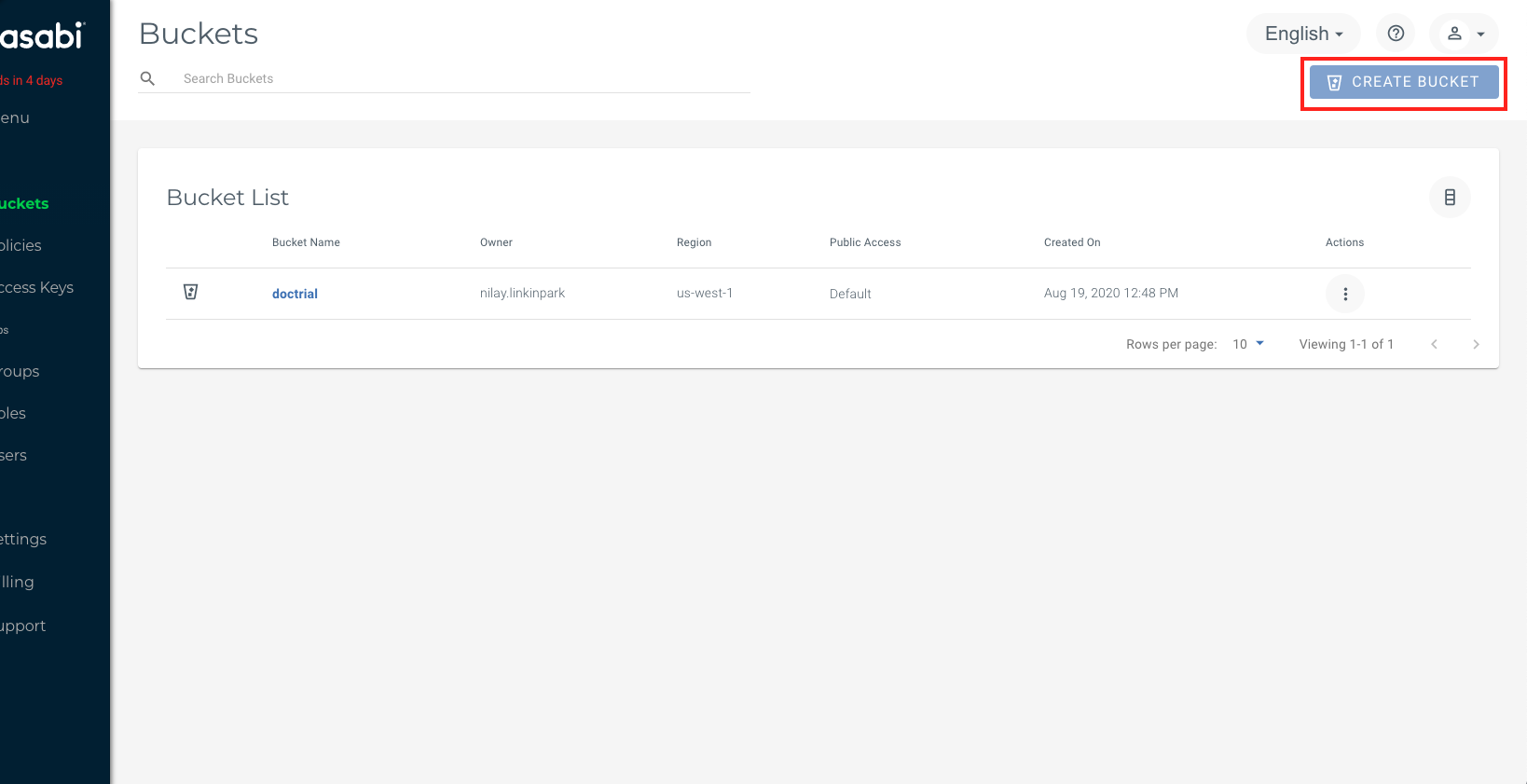
Step 1: Create a bucket in your cloud object store to upload your datafiles
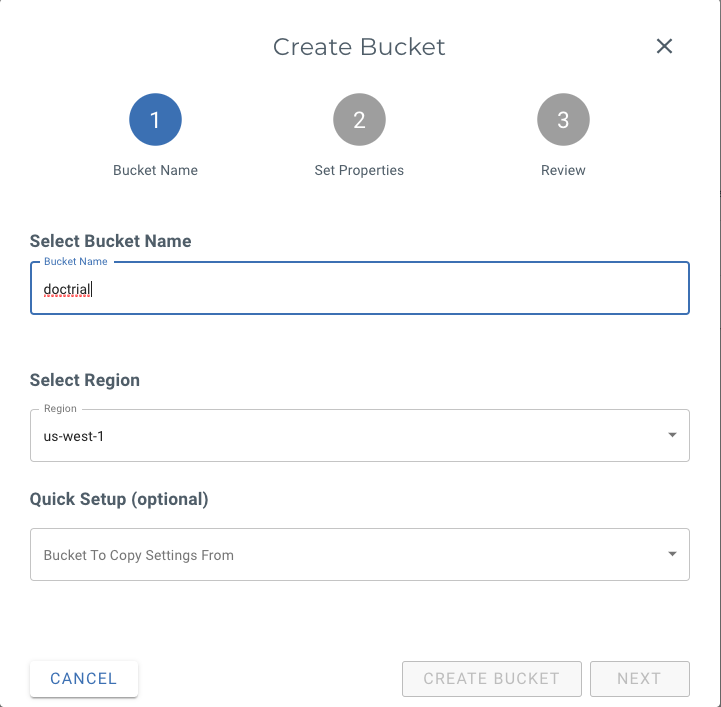
A bucket is simply a container to hold your datafiles (termed as objects). Once you have logged into your Wasabi account, from the left navigation pane, select “Buckets” and hit “Create Bucket”. Here I create a bucket named doctrial in the West region.
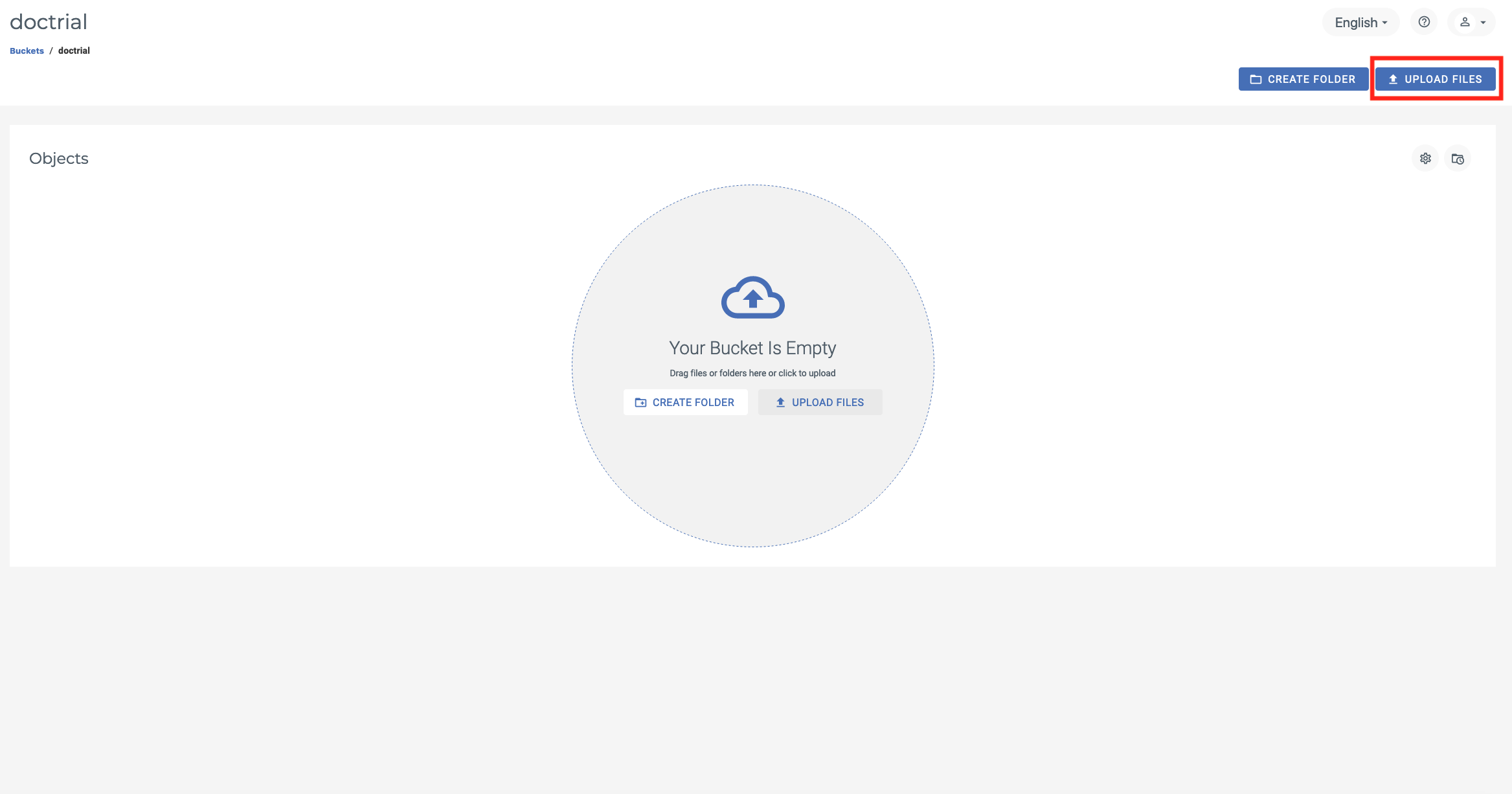
Step 2: Upload datafiles to your object storage bucket
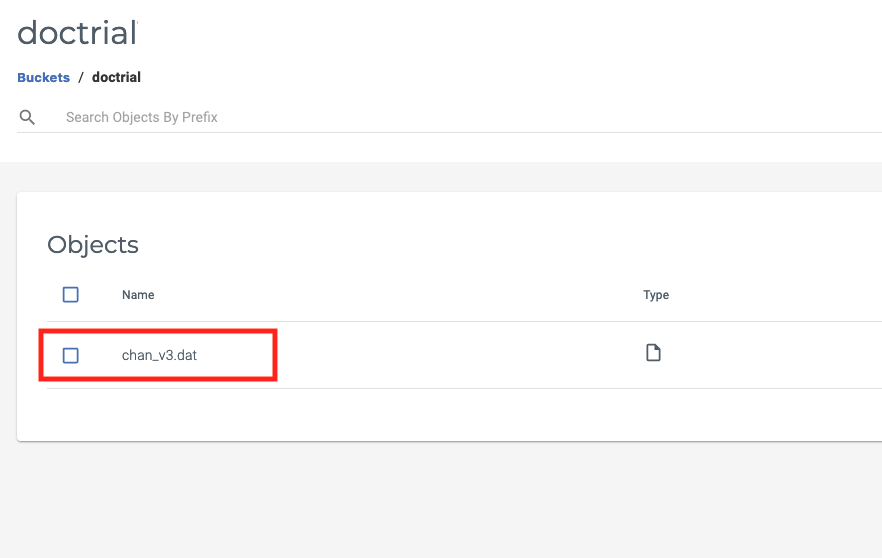
I proceed to upload some data into the object storage bucket we just created. Here, I upload some sales channels data. You may, of course, follow along with your own datafiles; if you would like to follow along with my example download and unzip the chan_v3.dat datafile here.
Step 3: Find or create your file’s S3 compatible URL
Next, let’s find or create our S3 compatible URL to point our database script to. In Wasabi, clicking on the file in the bucket UI opens up a panel displaying the file’s URL which, conveniently, happens to be an S3 compatible URL (notice “s3” as part of the standard sub-domain of the URL).
Some object stores may not be quite as simple, but referring to your object store’s documentation will provide the format for its S3 compatible URL, where you may have to substitute in your region, bucket name and datafile (ie. object) name.
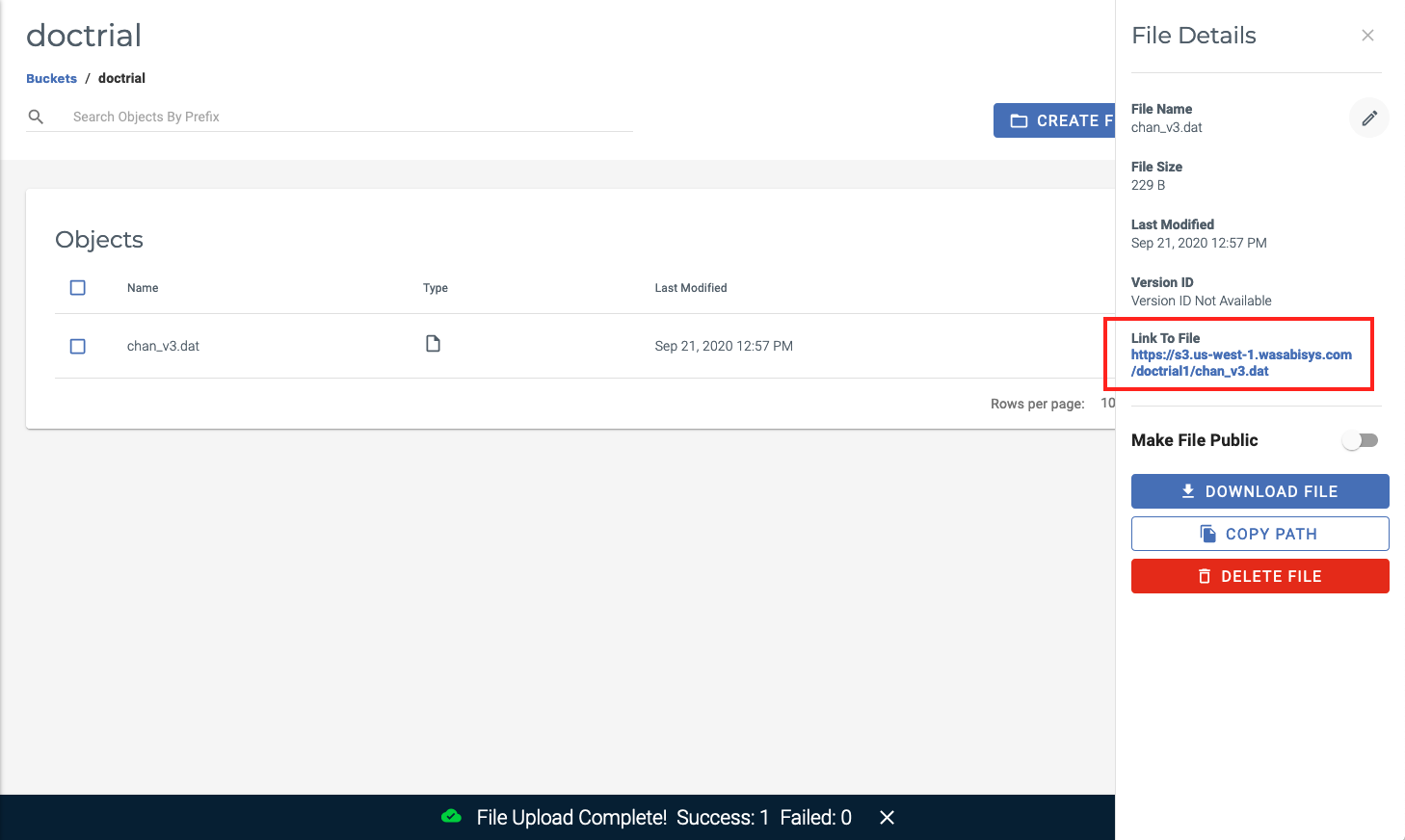
Step 4: Create an S3 Access/Secret key pair for authenticating your ADB Instance
For your ADB instance to be able to talk to your object storage, we must set up authentication between them. To do this you will need to create an access key. In our Wasabi example below, navigate to Access Keys and click “Create New Access Key”.
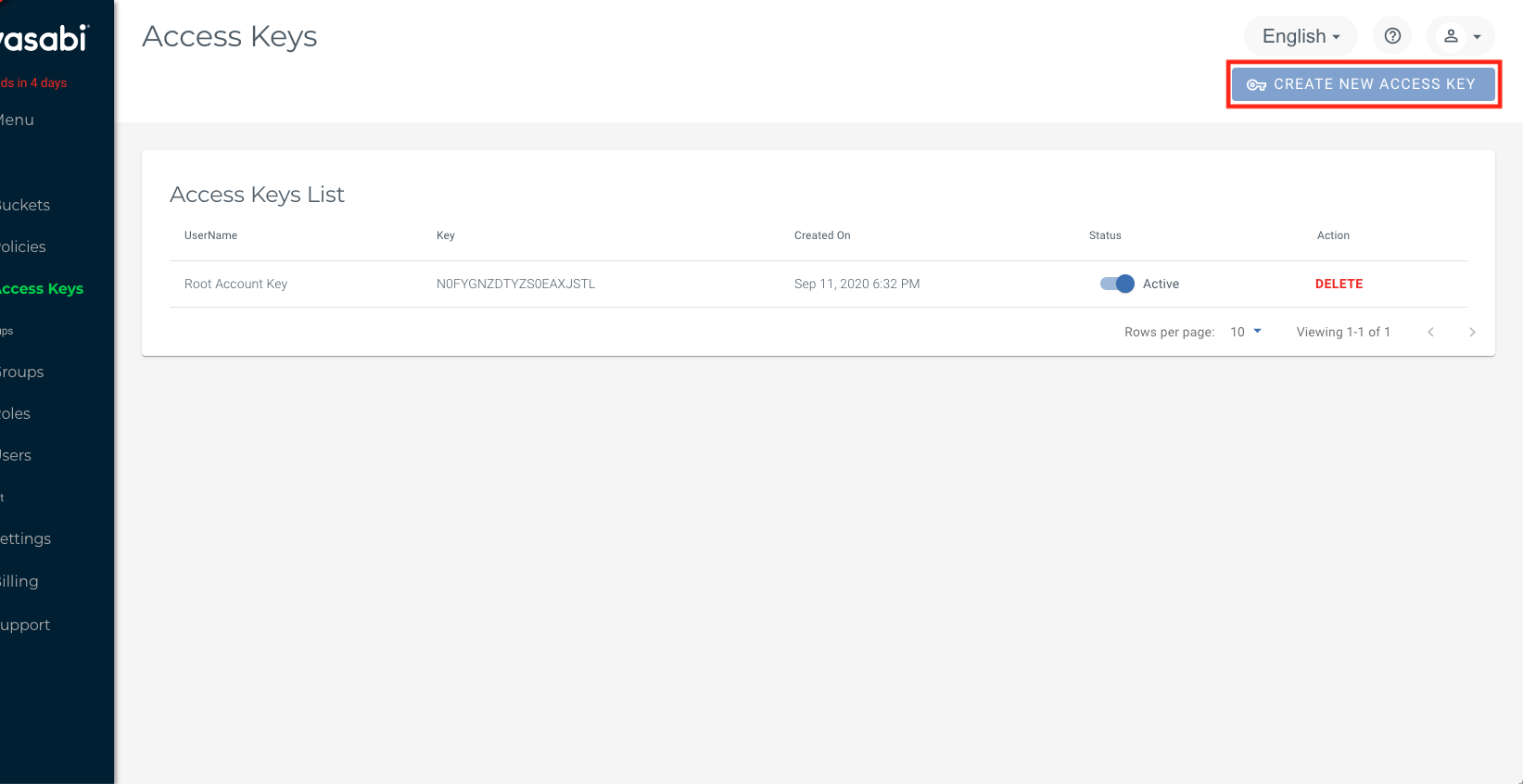
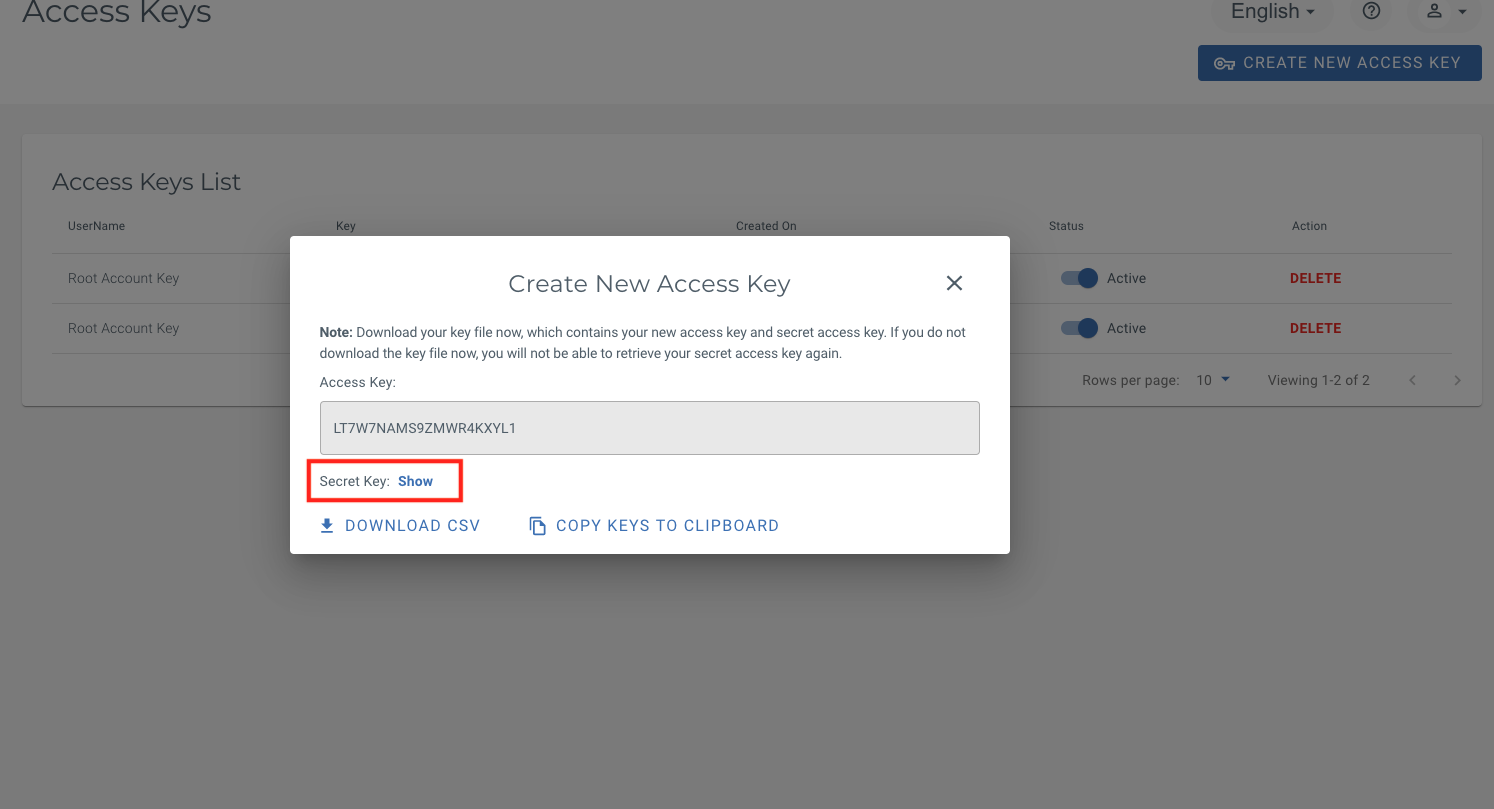
Along with each new Access Key you generate, you will receive a Secret Key. This is a private key that you will be able to see here only once, so note it down somewhere safe and retrievable. We will be using this key pair in our script to load data into ADB.
Note: For security, we always recommend using private buckets (this is the default with most object stores). If you do happen to use a public bucket for non-sensitive data, you may skip the use of keys (as well as the credential creation in the next step).
Step 5: Create a credential in your database instance
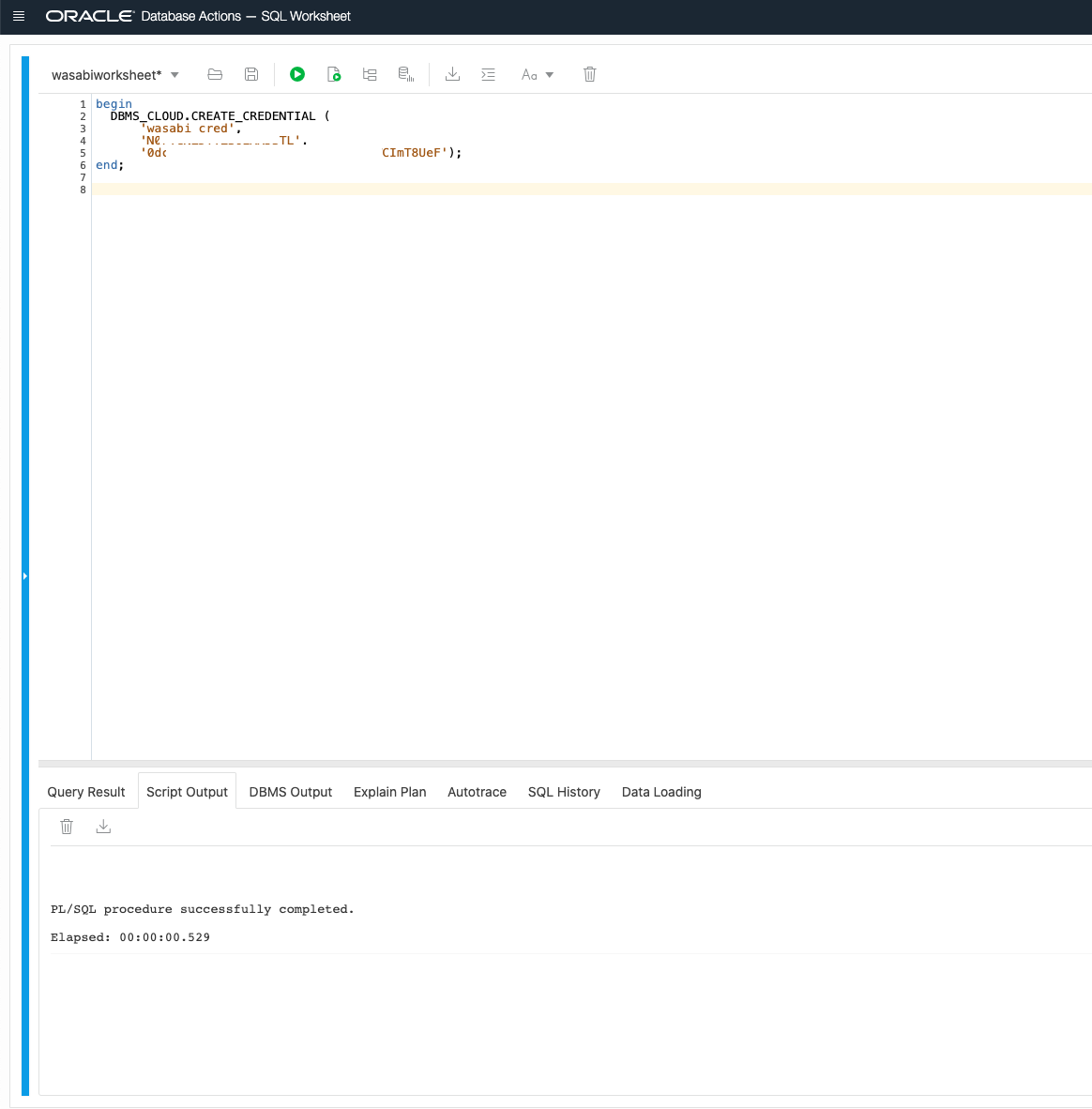
Now that your object store and data are set up, let us switch from the Wasabi console to our Autonomous Database. We jump right into our SQL Developer Web worksheet to run scripts on our database (you may use the desktop version of SQL Developer or your PL/SQL tool of choice connected to your database). I run the following script to create a credential named “wasabi_cred”, which your ADB instance will use to authenticate itself while connecting to the object store.
begin
DBMS_CLOUD.CREATE_CREDENTIAL (
'wasabi_cred',
'<Paste your object store access key here>',
'<Paste your object store secret key here>');
end;
Step 6: Create table and copy data into it from your object store
With the necessary credential created, I now create a table with the structure that I know matches my channels dataset.
CREATE TABLE channels (
channel_id NUMBER(6) NOT NULL,
channel_desc VARCHAR2(20) NOT NULL,
channel_class VARCHAR2(20) NOT NULL,
channel_class_id NUMBER(6) NOT NULL,
channel_total VARCHAR2(13) NOT NULL,
channel_total_id NUMBER(6) NOT NULL);
Next comes what we are all here for – I run this script which uses the DBMS_CLOUD package to copy the data from my datafile (object) lying in my object store into my database. You will copy your object’s URL we created in Step 3 into the “file_uri_list” parameter, and your credential and table names, if you used names different than the scripts above. To recap, the credential “wasabi_cred” we created in Step 5, using our keys, is what authenticates your database to access the object storage bucket.
begin
dbms_cloud.copy_data(
table_name =>'CHANNELS',
credential_name =>'wasabi_cred',
file_uri_list =>'https://s3.us-west-1.wasabisys.com/doctrial/chan_v3.dat',
format => json_object('ignoremissingcolumns' value 'true', 'removequotes' value 'true')
);
end;
Finito
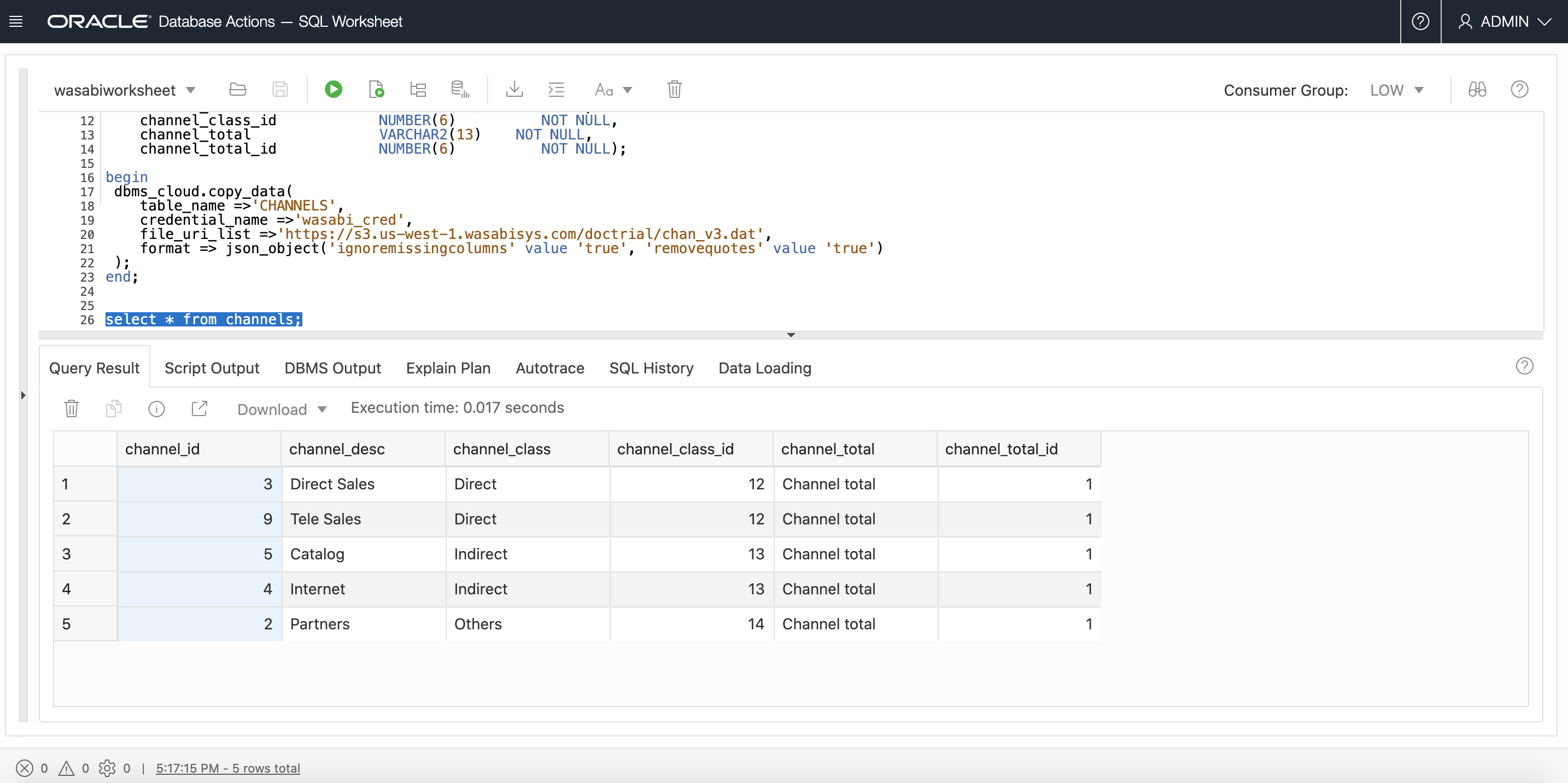
And just like that, we’re done! Having successfully run the “copy_data” script above, your data has been copied from your object store into your database and can now be queried, transformed or analyzed. You may also use this method to create external tables over your object store, if you prefer to query your data directly, without physically moving it into your database. As always, refer to the ADB documentation for more details.
This new functionality provides excellent flexibility when it comes to your object storage options that work with Autonomous Database!
select * from channels;
Like what I write? Follow me on the Twitter! 🐦
