Earlier I’ve written about Big Data High Availability in different aspects and I intentionally avoided the Disaster Recovery topic. High Availability answers on the question how system should process in case of failure one of the component (like Name Node or KDC) within one system (like one Hadoop Cluster), Disaster Recovery answers on the question what to do in case if entire system will fail (Hadoop cluster or even Data Center will go down). In this blog, I also would like to talk about backup and how to deal with human mistakes (it’s not particularly DR topics, but quite close). Also, I’d like to introduce few terms. From Wikipedia:
Business Continuity:
Involveskeeping all essential aspects of a business functioning despite significant disruptive events.
Disaster Recovery: (DR)
A set of policies and procedures to enable the recovery or continuation of vital technology infrastructure and systems following a disaster.
Step 1. Protect system from human errors. HDFS snapshots.
HDFS snapshots functionality has been a while in Hadoop portfolio. This is a great way to protect system from human mistakes. There are few simple steps to enable it (full snapshot documentation you could find here).
– go to Cloudera Manager and drill down into the HDFS service:
– then go to the “File Browser” and navigate to the directory, which you would like to protect by snapshots
– click on the “Enable Snapshots” button:
as soon as command finished, you have directory, protected by snapshots!
you may take snapshots on demand:
or you may create a snapshot policy, which will be periodically repeated (it’s recommended).
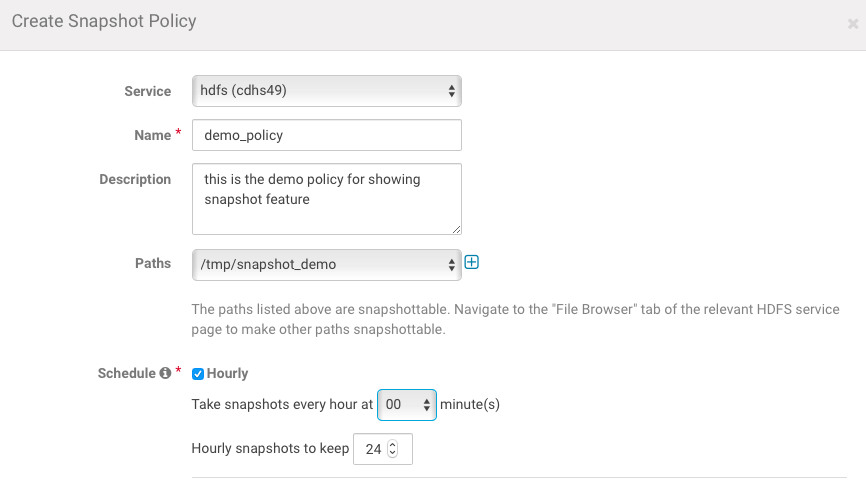
In order to make it work you have to go to a Cloudera Manager -> Backup -> Snapshot Policies:

– Click on the “Create Policy” (Note: you have to enable Snapshots for certain directory before creating policy)
– and fill up the form:
easy, but very powerful. It’s a good time for a demo. Let’s imagine, that we have directory with critical datasets on HDFS:
[root@destination_cluster15 ~]# hadoop fs -ls /tmp/snapshot_demo/
Found 2 items
drwxr-xr-x – bdruser supergroup 0 2019-02-13 14:12 /tmp/snapshot_demo/dir1
drwxr-xr-x – bdruser supergroup 0 2019-02-13 14:12 /tmp/snapshot_demo/dir2
[root@destination_cluster15 ~]# hadoop fs -rm -r -skipTrash /tmp/snapshot_demo/dir1
Deleted /tmp/snapshot_demo/dir1
[root@destination_cluster15 ~]# hadoop fs -ls /tmp/snapshot_demo/
Found 1 items
drwxr-xr-x – bdruser supergroup 0 2019-02-13 14:12 /tmp/snapshot_demo/dir2
fortunately, it’s quite easy to restore state of this dir using snapshots:
– go to a Cloudera Manager -> HDFS -> File Browser
– choose option “Restore from snapshot”:
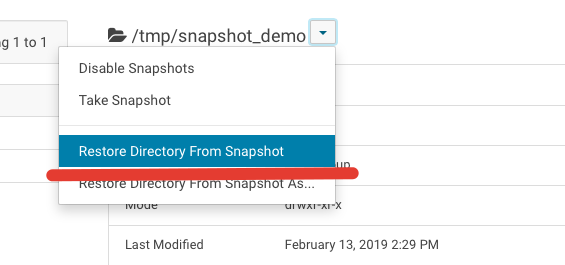
– choose appropriate snapshot and click “Restore”:
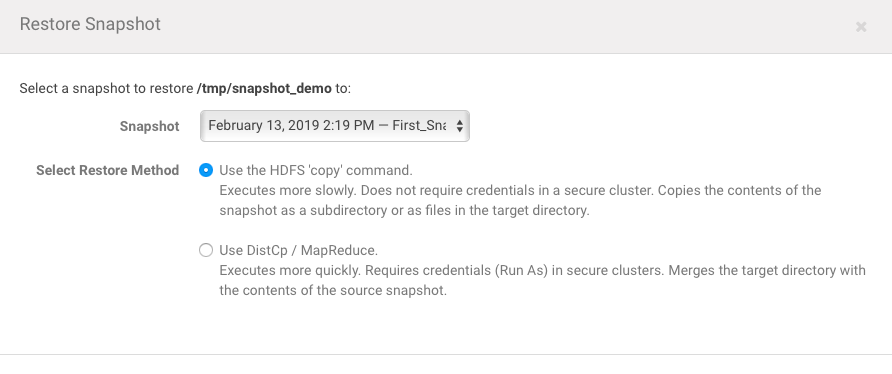
– check what you have:
[root@destination_cluster15 ~]# hadoop fs -ls /tmp/snapshot_demo/
Found 2 items
drwxr-xr-x – hdfs supergroup 0 2019-02-13 14:32 /tmp/snapshot_demo/dir1
drwxr-xr-x – hdfs supergroup 0 2019-02-13 14:32 /tmp/snapshot_demo/dir2
Note: snapshot revert you to the stage where you’ve made it. For example, if you add some directory and then restore to a snapshot, you will not have this directory, which I’ve created after taking snapshot:
[root@destination_cluster15 ~]# hadoop fs -mkdir /tmp/snapshot_demo/dir3
[root@destination_cluster15 ~]# hadoop fs -ls /tmp/snapshot_demo/
Found 3 items
drwxr-xr-x – hdfs supergroup 0 2019-02-13 14:32 /tmp/snapshot_demo/dir1
drwxr-xr-x – hdfs supergroup 0 2019-02-13 14:32 /tmp/snapshot_demo/dir2
drwxr-xr-x – bdruser supergroup 0 2019-02-13 14:35 /tmp/snapshot_demo/dir3
and restore from the early taken snapshot:
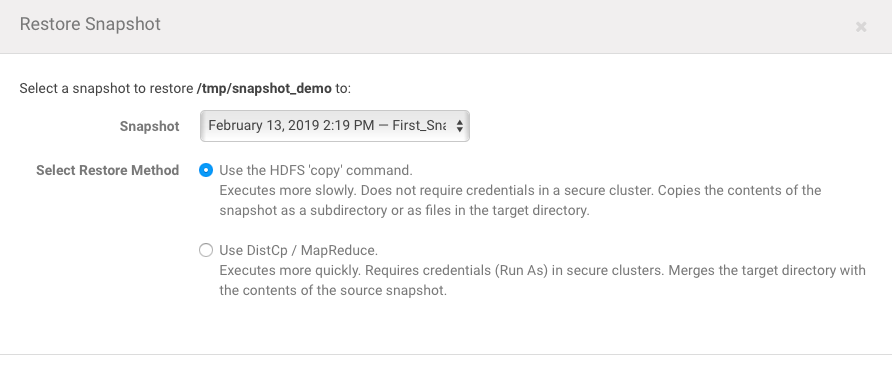
after recovery done:
[root@destination_cluster15 ~]# hadoop fs -ls /tmp/snapshot_demo/
Found 2 items
drwxr-xr-x – hdfs supergroup 0 2019-02-13 14:36 /tmp/snapshot_demo/dir1
drwxr-xr-x – hdfs supergroup 0 2019-02-13 14:36 /tmp/snapshot_demo/dir2
[root@destination_cluster15 ~]# hadoop fs -ls /tmp/snapshot_demo/
Found 2 items
drwxr-xr-x – hdfs supergroup 0 2019-02-13 14:36 /tmp/snapshot_demo/dir1
drwxr-xr-x – hdfs supergroup 0 2019-02-13 14:36 /tmp/snapshot_demo/dir2
[root@destination_cluster15 ~]# hadoop fs -chown yarn:yarn /tmp/snapshot_demo/*
[root@destination_cluster15 ~]# hadoop fs -ls /tmp/snapshot_demo/
Found 2 items
drwxr-xr-x – yarn yarn 0 2019-02-13 14:36 /tmp/snapshot_demo/dir1
drwxr-xr-x – yarn yarn 0 2019-02-13 14:36 /tmp/snapshot_demo/dir2
restore from snapshot and have previous file owner:
[root@destination_cluster15 ~]# hadoop fs -ls /tmp/snapshot_demo/
Found 2 items
drwxr-xr-x – hdfs supergroup 0 2019-02-13 14:38 /tmp/snapshot_demo/dir1
drwxr-xr-x – hdfs supergroup 0 2019-02-13 14:38 /tmp/snapshot_demo/dir2
Conclusion: snapshots is very powerful tool for protect your file system from human mistakes. It stores only delta (changes), so that means that it will not consume many space in case if you don’t delete data frequently.
Step 2.1. Backup data. On-premise backup. NFS Storage.
Backups in Hadoop world is ticklish topic. The reason is time to recovery. How long will it take to bring data back to the production system? Big Data systems tend to be not so expensive and have massive datasets, so it may be easier to have second cluster (details on how to do this coming later in this blog). But if you have some reasons to do backups, you may consider either NFS storage (in case if you want to take backup on-premise in your datacenter) or Object Store (if you want to take backup outside of your data center) in Oracle Cloud Infrastructure (OCI) as an options. In case of NFS storage (like Oracle ZFS), you have to mount your NFS storage at the same directory on every Hadoop node. Like this:
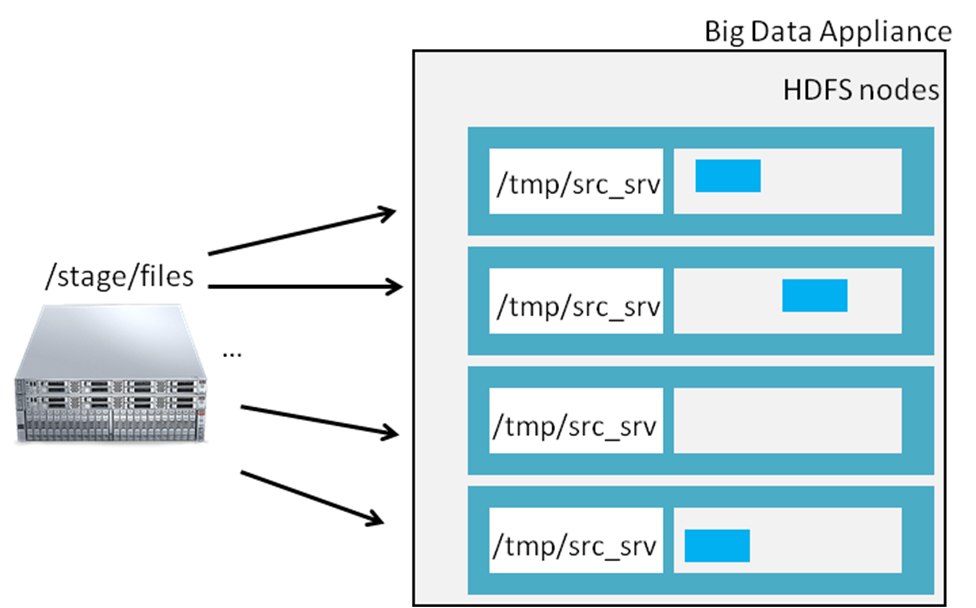
Run on each BDA node:
[root]# mount nfs_storage_ip:/stage/files /tmp/src_srv
Now you have share storage on every server and it means that every single Linux server has the same directory. It allows you to run distcp command (that originally was developed for coping big amount of data between HDFS filesystems). For start parallel copy, just run:
$ hadoop distcp -m 50 -atomic hdfs://nnode:8020/tmp/test_load/* file:///tmp/src_srv/files/;
You will create MapReduce job that will copy from one place (local file system) to HDFS with 50 mappers.
Step 2.2. Backup data. Cloud. Object Storage.
Object Store is key element for every cloud provider, oracle is not an exception. Documentation for Oracle Object Storage you could find here.
Object Store provides some benefits, such as:
– Elasticity. Customers don’t have to plan ahead how many space to they need. Need some extra space? Simply load data into Object Store. There is no difference in process to copy 1GB or 1PB of data
– Scalability. It’s infinitely scale. At least theoretically 🙂
– Durability and Availability. Object Store is first class citizen in all Cloud Stories, so all vendors do all their best to maintain 100% availability and durability. If some diet will go down, it shouldn’t worry you. If some node with OSS software will go down, it shouldn’t worry you. As user you have to put data there and read data from Object Store.
– Cost. In a Cloud Object Store is most cost efficient solution.
Nothing comes for free and as downside I may highlight:
– Performance in comparison with HDFS or local block devices. Whenever you read data from Object Store, you read it over the network.
– Inconsistency of performance. You are not alone on object store and obviously under the hood it uses physical disks, which have own throughput. If many users will start to read and write data to/from Object Store, you may get performance which is different with what you use to have a day, week, month ago
– Security. Unlike filesystems Object Store has not file grain permissions policies and customers will need to reorganize and rebuild their security standards and policies.
Before running backup, you will need to configure OCI Object Store in you Hadoop system.
After you config your object storage, you may check the bucket that you’ve intent to copy to:
[root@source_clusternode01 ~]# hadoop fs -ls oci://BDAx7Backup@oraclebigdatadb/
[root@source_clusternode01 ~]# hadoop distcp -Dmapred.job.queue.name=root.oci -Dmapreduce.task.timeout=6000000 -m 240 -skipcrccheck -update -bandwidth 10240 -numListstatusThreads 40 /user/hive/warehouse/parq.db/store_returns oci://BDAx7Backup@oraclebigdatadb/
or ODCP – oracle build tool. You could find more info about ODCP here.
[root@source_clusternode01 ~]# odcp –executor-cores 3 –executor-memory 9 –num-executors 100 hdfs:///user/hive/warehouse/parq.db/store_sales oci://BDAx7Backup@oraclebigdatadb/
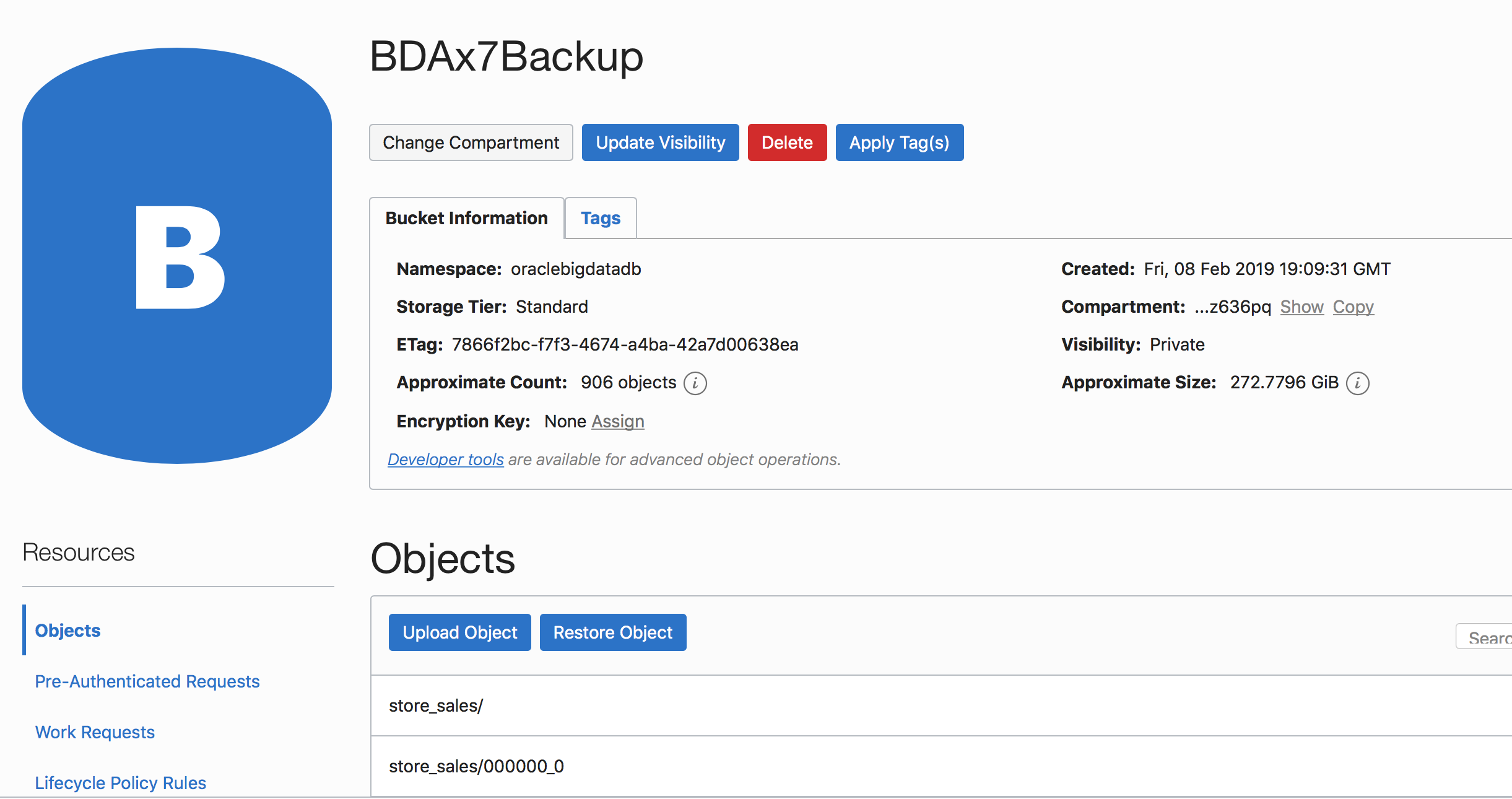
Step 2.3. Backup data. Big Data Appliance metadata.
it’s easies section for me because Oracle support engineers made a huge effort writing support note, which tells customer on how to take backups of metadata. For more details please refer to:
Customer RecommendedHow to Backup Critical Metadata on Oracle Big Data Appliance Prior to Upgrade V2.3.1 and Higher Releases (Doc ID 1623304.1)
Step 2.4. Backup data. MySQL
Separately, I’d like to mention that MySQL backup is very important and you could get familiar with this here:
How to Redirect a MySQL Database Backup on BDA Node 3 to a Different Node on the BDA or on a Client/Edge Server (Doc ID 1926159.1)
Step 3. HDFS Disaster Recovery. Recommended Architecture
Here I’d like to share Oracle recommended architecture for Disaster Recovery setup:
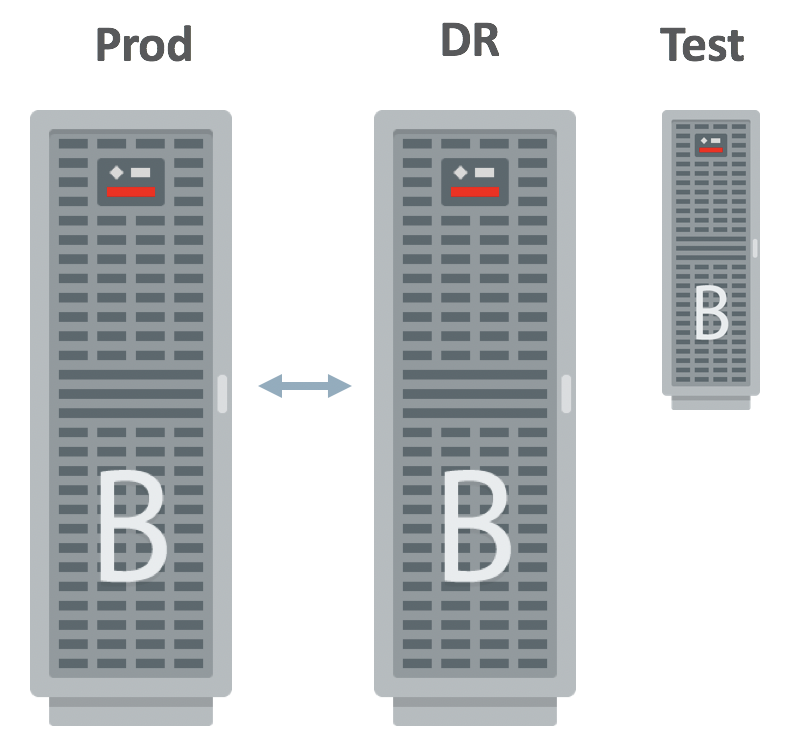
We do recommend to have same Hardware and Software environment for Production and DR environments. If you want to have less powerful nodes on the DR side, you should answer to yourself on the question – what you are going to do in case of disaster? What is going to happen if you will switch all production applications to the DR side. Will it be capable to handle this workload? Also, one very straight recommendation from Oracle is to have small BDA (3-6 nodes) in order to perform tests on it. Here is the rough separation of duties for these three clusters:
Production (Prod):
– Running production workload
Disaster Recovery (DR):
– Same (or almost the same) BDA hardware configuration
– Run non-critical Ad-Hoc queries
– Switch over in case of unplanned (disaster) or planned (upgrade) outages of the prod
Test:
Use small BDA cluster (3-6 nodes) to test different things, such as:
– Upgrade
– Change settings (HDFS, YARN)
– Testing of new engines (add and test Hbase, Flume..)
– Testing integration with other systems (AD, Database)
– Test Dynamic pools
…
Note: for test environment you also consider Oracle cloud offering
Step 3.1 HDFS Disaster Recovery. Big Data Disaster Recovery (BDR).
Now we are approaching most interesting part of the blog. Disaster recovery.
Cloudera offers the tool out of the box, which called Big Data Disaster Recovery (BDR), which allows to Hadoop administrators easily, using web interface create replication policies and schedule the data replication. Let me show the example how to do this replication with BDR. I have two BDA clusters source_cluster and destination_cluster.
under the hood BDR uses special version of distcp, which has many performance and functional optimizations.
Step 3.1.1 HDFS Disaster Recovery. Big Data Disaster Recovery (BDR). Network throughput
It’s crucial to understand network throughput between clusters. To measure network throughput you may use any tool convenient for you. I personally prefer iperf. Note: iperf has two modes – UDP and TCP. Use TCP in order to make measurements between servers in context of BDR, because it uses TCP connections. After installation it’s quite easy to run it:
On probation make one machine (let’s say on destination cluster) as server and run iperf in listening mode:
[root@destination_cluster15 ~]# iperf -s
on the source machine run client command, which will send some TCP traffic to server machine for 10 minutes with maximum bandwidth:
[root@source_clusternode01 ~]# iperf -c destination_cluster15 -b 10000m -t 600
I just briefly want to highlight most important steps.
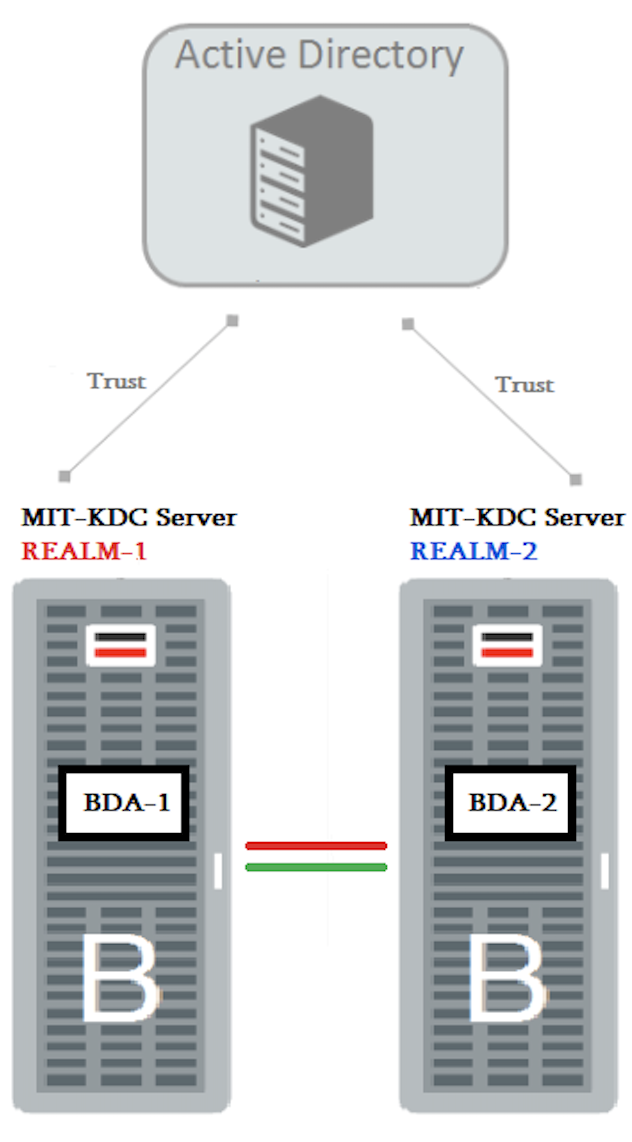
1) On the source cluster go to “Administration -> Settings -> Search for (“KDC Server Host”) and set up hostname for Source KDC. Do the same for “KDC Admin Server Host”. It’s important because when destination cluster comes to the source and ask for KDC it does not read the /etc/krb5.conf as you may think. It read KDC address from this property.
2) Both clusters are in the same domain. It’s quite probable and quite often case. You may conclude this by seen follow error message:
“Peer cluster has domain us.oracle.com and realm ORACLE.TEST but a mapping already exists for this domain us.oracle.com with realm US.ORACLE.COM. Please use hostname(s) instead of domain(s) for realms US.ORACLE.COM and ORACLE.TEST, so there are no conflicting domain to realm mapping.”
it’s easy to fix by adding in /etc/krb5.conf exact names of the hosts under “domain_realm” section:
[domain_realm]
source_clusternode01.us.oracle.com = ORACLE.TEST
source_clusternode02.us.oracle.com = ORACLE.TEST
source_clusternode03.us.oracle.com = ORACLE.TEST
source_clusternode04.us.oracle.com = ORACLE.TEST
source_clusternode05.us.oracle.com = ORACLE.TEST
source_clusternode06.us.oracle.com = ORACLE.TEST
destination_cluster13.us.oracle.com = US.ORACLE.COM
destination_cluster14.us.oracle.com = US.ORACLE.COM
destination_cluster13.us.oracle.com = US.ORACLE.COM
.us.oracle.com = US.ORACLE.COM
us.oracle.com = US.ORACLE.COM
[root@destination_cluster13 ~]# cat /etc/krb5.conf
…
[realms]
US.ORACLE.COM = {
kdc = destination_cluster13.us.oracle.com:88
kdc = destination_cluster14.us.oracle.com:88
admin_server = destination_cluster13.us.oracle.com:749
default_domain = us.oracle.com
}
ORACLE.TEST = {
kdc = source_clusternode01.us.oracle.com
admin_server = source_clusternode01.us.oracle.com
default_domain = us.oracle.com
}
…
try to obtain credentials and explore source Cluster HDFS:
[root@destination_cluster13 ~]# kinit oracle@ORACLE.TEST
Password for oracle@ORACLE.TEST:
[root@destination_cluster13 ~]# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: oracle@ORACLE.TEST
Valid starting Expires Service principal
02/04/19 22:47:42 02/05/19 22:47:42 krbtgt/ORACLE.TEST@ORACLE.TEST
renew until 02/11/19 22:47:42
[root@destination_cluster13 ~]# hadoop fs -ls hdfs://source_clusternode01:8020
19/02/04 22:47:54 WARN security.UserGroupInformation: PriviledgedActionException as:oracle@ORACLE.TEST (auth:KERBEROS) cause:javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Fail to create credential. (63) – No service creds)]
[root@destination_cluster13 ~]# kadmin.local
kadmin.local: addprinc krbtgt/ORACLE.TEST@US.ORACLE.COM
WARNING: no policy specified for krbtgt/ORACLE.TEST@US.ORACLE.COM; defaulting to no policy
Enter password for principal “krbtgt/ORACLE.TEST@US.ORACLE.COM“:
Re-enter password for principal “krbtgt/ORACLE.TEST@US.ORACLE.COM“:
Principal “krbtgt/ORACLE.TEST@US.ORACLE.COM” created.
on the source Cluster:
[root@source_clusternode01 ~]# kadmin.local
kadmin.local: addprinc krbtgt/ORACLE.TEST@US.ORACLE.COM
WARNING: no policy specified for krbtgt/ORACLE.TEST@US.ORACLE.COM; defaulting to no policy
Enter password for principal “krbtgt/ORACLE.TEST@US.ORACLE.COM“:
Re-enter password for principal “krbtgt/ORACLE.TEST@US.ORACLE.COM“:
Principal “krbtgt/ORACLE.TEST@US.ORACLE.COM” created.
[root@destination_cluster13 ~]# hadoop fs -ls hdfs://source_clusternode01:8020
Found 4 items
drwx—— – hbase hbase 0 2019-02-04 22:34 /hbase
drwxr-xr-x – hdfs supergroup 0 2018-03-14 06:46 /sfmta
drwxrwxrwx – hdfs supergroup 0 2018-10-31 15:41 /tmp
drwxr-xr-x – hdfs supergroup 0 2019-01-07 09:30 /user
Bingo! it works. Now we have to do the same on both clusters to allow reverse direction:
19/02/05 02:02:02 INFO util.KerberosName: No auth_to_local rules applied to oracle@US.ORACLE.COM
19/02/05 02:02:03 WARN security.UserGroupInformation: PriviledgedActionException as:oracle@US.ORACLE.COM (auth:KERBEROS) cause:javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Fail to create credential. (63) – No service creds)]
same error and same fix for it. I just simply automate this by running follow commands on the both KDCs:
delprinc -force krbtgt/US.ORACLE.COM@ORACLE.TEST
delprinc -force krbtgt/ORACLE.TEST@US.ORACLE.COM
addprinc -pw “welcome1” krbtgt/US.ORACLE.COM@ORACLE.TEST
addprinc -pw “welcome1” krbtgt/ORACLE.TEST@US.ORACLE.COM
default_principal_flags = +renewable, +forwardable
The next assumption is that your’s Cloudera manager is working over encrypted channel and if you will try to do add source peer, most probably, you’ll get an exception:
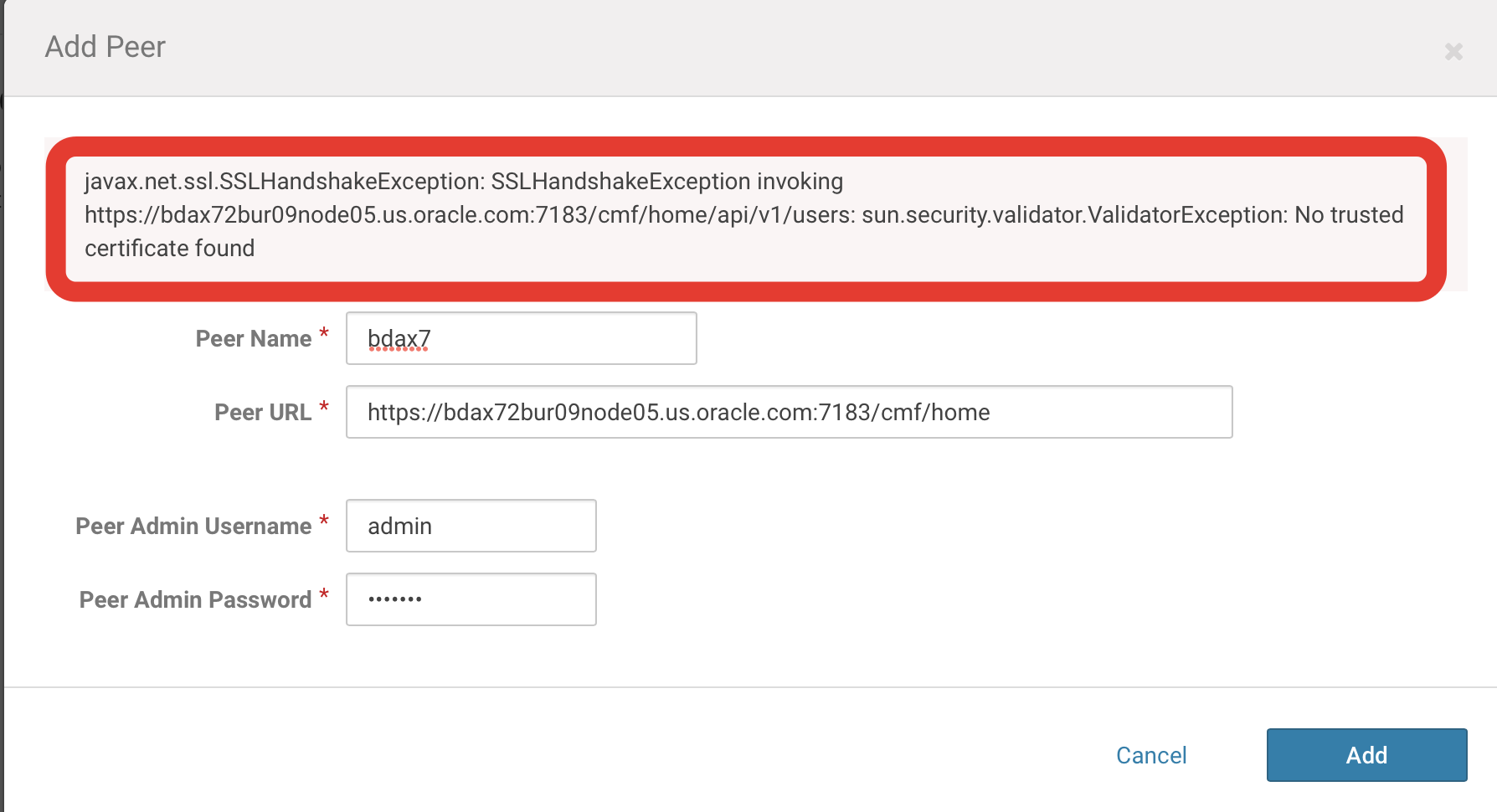
in order to fix this:
a. Check certificate for Cloudera Manager (run this command on the destination cluster):
[root@destination_cluster13 ~]# openssl s_client -connect source_clusternode05.us.oracle.com:7183
CONNECTED(00000003)
depth=0 C = , ST = , L = , O = , OU = , CN = source_clusternode05.us.oracle.com
verify error:num=18:self signed certificate
verify return:1
depth=0 C = , ST = , L = , O = , OU = , CN = source_clusternode05.us.oracle.com
verify return:1
—
Certificate chain
0 s:/C=/ST=/L=/O=/OU=/CN=source_clusternode05.us.oracle.com
i:/C=/ST=/L=/O=/OU=/CN=source_clusternode05.us.oracle.com
—
Server certificate
—–BEGIN CERTIFICATE—–
MIIDYTCCAkmgAwIBAgIEP5N+XDANBgkqhkiG9w0BAQsFADBhMQkwBwYDVQQGEwAx
CTAHBgNVBAgTADEJMAcGA1UEBxMAMQkwBwYDVQQKEwAxCTAHBgNVBAsTADEoMCYG
A1UEAxMfYmRheDcyYnVyMDlub2RlMDUudXMub3JhY2xlLmNvbTAeFw0xODA3MTYw
MzEwNDVaFw0zODA0MDIwMzEwNDVaMGExCTAHBgNVBAYTADEJMAcGA1UECBMAMQkw
BwYDVQQHEwAxCTAHBgNVBAoTADEJMAcGA1UECxMAMSgwJgYDVQQDEx9iZGF4NzJi
dXIwOW5vZGUwNS51cy5vcmFjbGUuY29tMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8A
MIIBCgKCAQEAkLwi9lAsbiWPVUpQNAjtGE5Z3pJOExtJMSuvnj02FC6tq6I09iJ0
MsTu6+Keowv5CUlhfxTy1FD19ZhX3G7OEynhlnnhJ+yjprYzwRDhMHUg1LtqWib/
osHR1QfcDfLsByBKO0WsLBxCz/+OVm8ZR+KV/AeZ5UcIsvzIRZB4V5tWP9jziha4
3upQ7BpSvQhd++eFb4wgtiBsI8X70099ZI8ctFpmPjxtYHQSGRGdoZZJnHtPY4IL
Vp0088p+HeLMcanxW7CSkBZFn9nHgC5Qa7kmLN4EHhjwVfPCD+luR/k8itH2JFw0
Ub+lCOjSSMpERlLL8fCnETBc2nWCHNQqzwIDAQABoyEwHzAdBgNVHQ4EFgQUkhJo
0ejCveCcbdoW4+nNX8DjdX8wDQYJKoZIhvcNAQELBQADggEBAHPBse45lW7TwSTq
Lj05YwrRsKROFGcybpmIlUssFMxoojys2a6sLYrPJIZ1ucTrVNDspUZDm3WL6eHC
HF7AOiX4/4bQZv4bCbKqj4rkSDmt39BV+QnuXzRDzqAxad+Me51tisaVuJhRiZkt
AkOQfAo1WYvPpD6fnsNU24Tt9OZ7HMCspMZtYYV/aw9YdX614dI+mj2yniYRNR0q
zsOmQNJTu4b+vO+0vgzoqtMqNVV8Jc26M5h/ggXVzQ/nf3fmP4f8I018TgYJ5rXx
Kurb5CL4cg5DuZnQ4zFiTtPn3q5+3NTWx4A58GJKcJMHe/UhdcNvKLA1aPFZfkIO
/RCqvkY=
—–END CERTIFICATE—–
b. Go to the source cluster and find a file which has this certificate (run this command on the source cluster):
[root@source_clusternode05 ~]# grep -iRl “MIIDYTCCAkmgAwIBAgIEP5N+XDANBgkqhkiG9w0BAQsFADBhMQkwBwYDVQQGEwAx” /opt/cloudera/security/|grep “cert”
/opt/cloudera/security/x509/node.cert
/opt/cloudera/security/x509/ssl.cacerts.pem
[root@source_clusternode05 ~]# dcli -C “md5sum /opt/cloudera/security/x509/node.cert”
192.168.8.170: cc68d7f5375e3346d312961684d728c0 /opt/cloudera/security/x509/node.cert
192.168.8.171: 9259bb0102a1775b164ce56cf438ed0e /opt/cloudera/security/x509/node.cert
192.168.8.172: 496fd4e12bdbfc7c6aab35d970429a72 /opt/cloudera/security/x509/node.cert
192.168.8.173: 8637b8cfb5db843059c7a0aeb53071ec /opt/cloudera/security/x509/node.cert
192.168.8.174: 4aabab50c256e3ed2f96f22a81bf13ca /opt/cloudera/security/x509/node.cert
192.168.8.175: b50c2e40d04a026fad89da42bb2b7c6a /opt/cloudera/security/x509/node.cert
[root@source_clusternode05 ~]#
[root@source_clusternode05 ~]# dcli -C cp /opt/cloudera/security/x509/node.cert /opt/cloudera/security/x509/node_’`hostname`’.cert
e. Check the new names (run this command on the source cluster):
[root@source_clusternode05 ~]# dcli -C “ls /opt/cloudera/security/x509/node_*.cert”
192.168.8.170: /opt/cloudera/security/x509/node_source_clusternode01.us.oracle.com.cert
192.168.8.171: /opt/cloudera/security/x509/node_source_clusternode02.us.oracle.com.cert
192.168.8.172: /opt/cloudera/security/x509/node_source_clusternode03.us.oracle.com.cert
192.168.8.173: /opt/cloudera/security/x509/node_source_clusternode04.us.oracle.com.cert
192.168.8.174: /opt/cloudera/security/x509/node_source_clusternode05.us.oracle.com.cert
192.168.8.175: /opt/cloudera/security/x509/node_source_clusternode06.us.oracle.com.cert
f. Pull those certificates from source cluster to one node of the destination cluster (run this command on the destination cluster):
[root@destination_cluster13 ~]# for i in {1..6}; do export NODE_NAME=source_clusternode0$i.us.oracle.com; scp root@$NODE_NAME:/opt/cloudera/security/x509/node_$NODE_NAME.cert /opt/cloudera/security/jks/node_$NODE_NAME.cert; done;
g. propagate it on the all nodes of the destination cluster (run this command on the destination cluster):
[root@destination_cluster13 ~]# for i in {4..5}; do scp /opt/cloudera/security/jks/node_bda*.cert root@destination_cluster1$i:/opt/cloudera/security/jks; done;
[root@destination_cluster13 ~]# bdacli getinfo cluster_https_truststore_path
Enter the admin user for CM (press enter for admin):
Enter the admin password for CM:
/opt/cloudera/security/jks/cdhs49.truststore
[root@destination_cluster13 ~]# bdacli getinfo cluster_https_truststore_password
Enter the admin user for CM (press enter for admin):
Enter the admin password for CM:
dl126jfwt1XOGUlNz1jsAzmrn1ojSnymjn8WaA7emPlo5BnXuSCMtWmLdFZrLwJN
i. and add them environment variables on all hosts of the destination cluster (run this command on the destination cluster):
[root@destination_cluster13 ~]# export TRUSTORE_PASSWORD=dl126jfwt1XOGUlNz1jsAzmrn1ojSnymjn8WaA7emPlo5BnXuSCMtWmLdFZrLwJN
[root@destination_cluster13 ~]# export TRUSTORE_FILE=/opt/cloudera/security/jks/cdhs49.truststore
j. now we are ready to copy add certificates to the destination clusters trustore (run this command on the destination cluster) do this on all hosts of the destination cluster:
[root@destination_cluster13 ~]# for i in {1..6}; do export NODE_NAME=export NODE_NAME=source_clusternode0$i.us.oracle.com; keytool -import -noprompt -alias $NODE_NAME -file /opt/cloudera/security/jks/node_$NODE_NAME.cert -keystore $TRUSTORE_FILE -storepass $TRUSTORE_PASSWORD; done;
Certificate was added to keystore
Certificate was added to keystore
Certificate was added to keystore
Certificate was added to keystore
Certificate was added to keystore
[root@destination_cluster13 ~]# keytool -list -keystore $TRUSTORE_FILE -storepass $TRUSTORE_PASSWORD
Keystore type: jks
Keystore provider: SUN
Your keystore contains 9 entries
destination_cluster14.us.oracle.com, May 30, 2018, trustedCertEntry,
Certificate fingerprint (SHA1): B3:F9:70:30:77:DE:92:E0:A3:20:6E:B3:96:91:74:8E:A9:DC:DF:52
source_clusternode02.us.oracle.com, Feb 1, 2019, trustedCertEntry,
Certificate fingerprint (SHA1): 3F:6E:B9:34:E8:F9:0B:FF:CF:9A:4A:77:09:61:E9:07:BF:17:A0:F1
source_clusternode05.us.oracle.com, Feb 1, 2019, trustedCertEntry,
Certificate fingerprint (SHA1): C5:F0:DB:93:84:FA:7D:9C:B4:C9:24:19:6F:B3:08:13:DF:B9:D4:E6
destination_cluster15.us.oracle.com, May 30, 2018, trustedCertEntry,
Certificate fingerprint (SHA1): EC:42:B8:B0:3B:25:70:EF:EF:15:DD:E6:AA:5C:81:DF:FD:A2:EB:6C
source_clusternode03.us.oracle.com, Feb 1, 2019, trustedCertEntry,
Certificate fingerprint (SHA1): 35:E1:07:F0:ED:D5:42:51:48:CB:91:D3:4B:9B:B0:EF:97:99:87:4F
source_clusternode06.us.oracle.com, Feb 1, 2019, trustedCertEntry,
Certificate fingerprint (SHA1): 16:8E:DF:71:76:C8:F0:D3:E3:DF:DA:B2:EC:D5:66:83:83:F0:7D:97
destination_cluster13.us.oracle.com, May 30, 2018, trustedCertEntry,
Certificate fingerprint (SHA1): 76:C4:8E:82:3C:16:2D:7E:C9:39:64:F4:FC:B8:24:40:CD:08:F8:A9
source_clusternode01.us.oracle.com, Feb 1, 2019, trustedCertEntry,
Certificate fingerprint (SHA1): 26:89:C2:2B:E3:B8:8D:46:41:C6:C0:B6:52:D2:C4:B8:51:23:57:D2
source_clusternode04.us.oracle.com, Feb 1, 2019, trustedCertEntry,
Certificate fingerprint (SHA1): CB:98:23:1F:C0:65:7E:06:40:C4:0C:5E:C3:A9:78:F3:9D:E8:02:9E
[root@destination_cluster13 ~]#
l. now do the same on the others node of destination cluster
On the destination cluster you will need to configure replication peer.
[root@destination_cluster15 ~]# dcli -C “useradd bdruser -u 2000”
[root@destination_cluster15 ~]# dcli -C “groupadd supergroup -g 2000”
[root@destination_cluster15 ~]# dcli -C “usermod -g supergroup bdruser”
[root@destination_cluster15 ~]# hdfs groups bdruser
bdruser : supergroup
Step 3.1.6 HDFS Disaster Recovery. Big Data Disaster Recovery (BDR). Create separate job for encrypted zones
It’s possible to copy data from encrypted zone, but there is the trick with it. If you will try to do this, you will find the error in the BDR logs:
java.io.IOException: Checksum mismatch between hdfs://distcpSourceNS/tmp/EZ/parq.db/customer/000001_0 and hdfs://cdhs49-ns/tmp/EZ/parq.db/customer/.distcp.tmp.4101922333172283041
Fortunately, this problem could easily be solved. You just need to skip calculating checksums for Encrypted Zones:
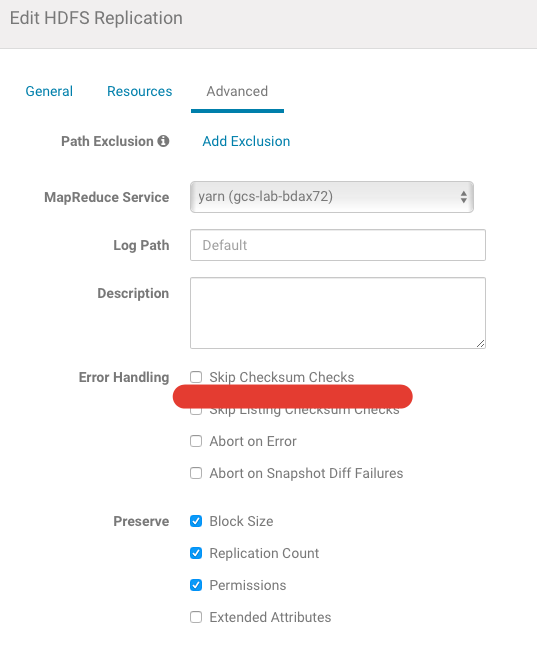
This is a good practice to create separate Job to copy data from encrypted zones and exclude directories with Encryption from general backup job.
Example. You have some directory, which you want to exclude (/tmp/excltest/bad) from common copy job. For do this, you need go to “Advanced” settings and add “Path Exclusion”:
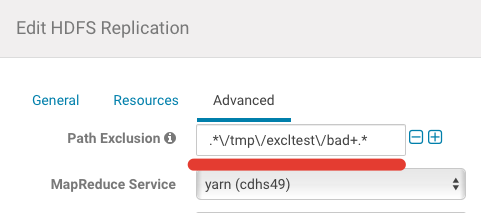
In my example you need to put .*\/tmp\/excltest\/bad+.*
you may this regexp it by creating follow directory structure and add Path Exclusion.
[root@source_clusternode05 ~]# hadoop fs -mkdir /tmp/excltest/
[root@source_clusternode05 ~]# hadoop fs -mkdir /tmp/excltest/good1
[root@source_clusternode05 ~]# hadoop fs -mkdir /tmp/excltest/good2
[root@source_clusternode05 ~]# hadoop fs -mkdir /tmp/excltest/bad
Note: it maybe quite hard to create and validate regular expression (this is Java), for this purposes you may use this on-line resource.
Step 3.1.7 HDFS Disaster Recovery. Big Data Disaster Recovery (BDR). Enable Snapshots on the Source Cluster
Replication without snapshots may fail. Distcp automatically created snapshot before coping.
Some replications, especially those that require a long time to finish, can fail because source files are modified during the replication process. You can prevent such failures by using Snapshots in conjunction with Replication. This use of snapshots is automatic with CDH versions 5.0 and higher. To take advantage of this, you must enable the relevant directories for snapshots (also called making the directory snapshottable). When the replication job runs, it checks to see whether the specified source directory is snapshottable. Before replicating any files, the replication job creates point-in-time snapshots of these directories and uses them as the source for file copies.
What happens when you copy data with out snapshots. test case:
1) Start coping (decent amount of data)
2) in the middle of the copy process, delete from the source files
3) get an error:

ERROR distcp.DistCp: Job failed to copy 443 files/dirs. Please check Copy Status.csv file or Error Status.csv file for error messages
INFO distcp.DistCp: Used diff: false
WARN distcp.SnapshotMgr: No snapshottable directories have found. Reason: either run-as-user does not have permissions to get snapshottable directories or source path is not snapshottable.
ERROR org.apache.hadoop.ipc.RemoteException(java.io.FileNotFoundException): File does not exist: /bdax7_4/store_sales/000003_0
to overcome this do:
1) On the source go to CM -> HDFS -> File Browser, pick right directory and click on:
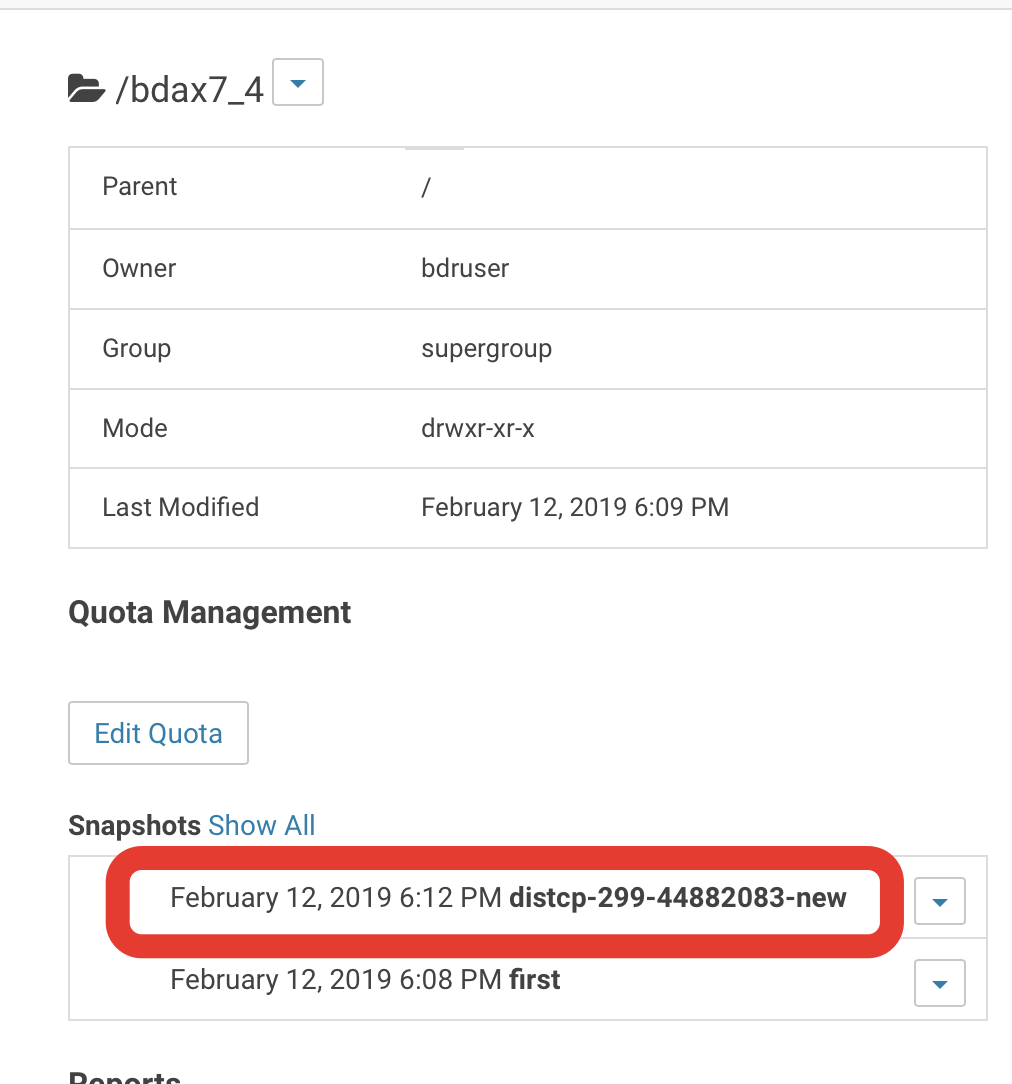
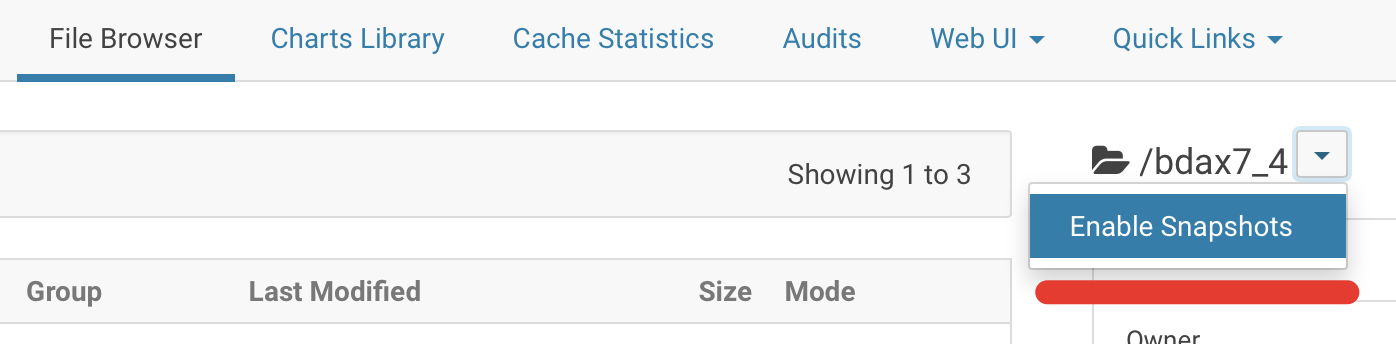 2) after this when you will run the job, it automatically will take a snapshot and will copy from it:
2) after this when you will run the job, it automatically will take a snapshot and will copy from it:
3) if you will delete data, your copy job will finish it from the snapshot that it took. Note, you can’t delete entire directory, but you could delete all files from it:
[root@destination_cluster15 ~]# hadoop fs -rm -r -skipTrash /bdax7_4
rm: The directory /bdax7_4 cannot be deleted since /bdax7_4 is snapshottable and already has snapshots
[root@destination_cluster15 ~]# hadoop fs -rm -r -skipTrash /bdax7_4/*
Deleted /bdax7_4/new1.file
Deleted /bdax7_4/store_sales
Deleted /bdax7_4/test.file
[root@destination_cluster15 ~]# hadoop fs -ls /bdax7_4
[root@destination_cluster15 ~]#
4) copy is successfully completed!
Step 3.1.8 HDFS Disaster Recovery. Big Data Disaster Recovery (BDR). Rebalancing data
HDFS tries to keep data evenly distributed across all nodes in a cluster. But after intensive write it maybe useful to run rebalance.
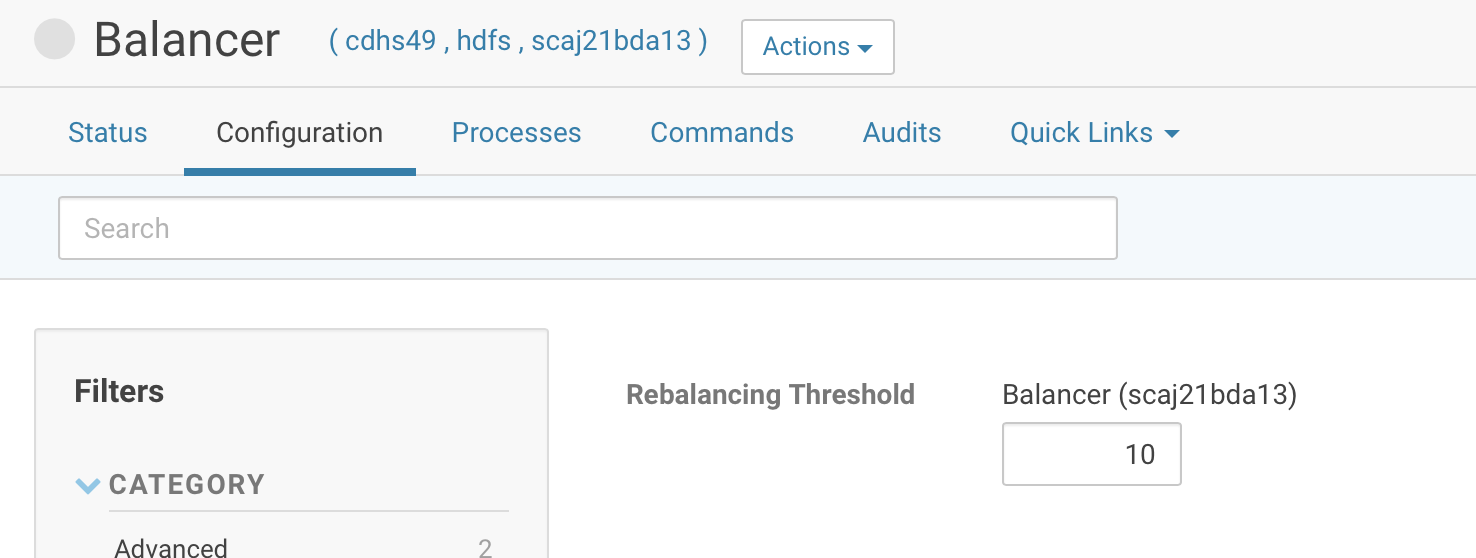
Default rebalancing threshold is 10%, which is a bit high. It make sense to change “Rebalancing Threshold” from 10 to 2 (Cloudera Manager -> HDFS -> Instances -> Balancer -> configuration)
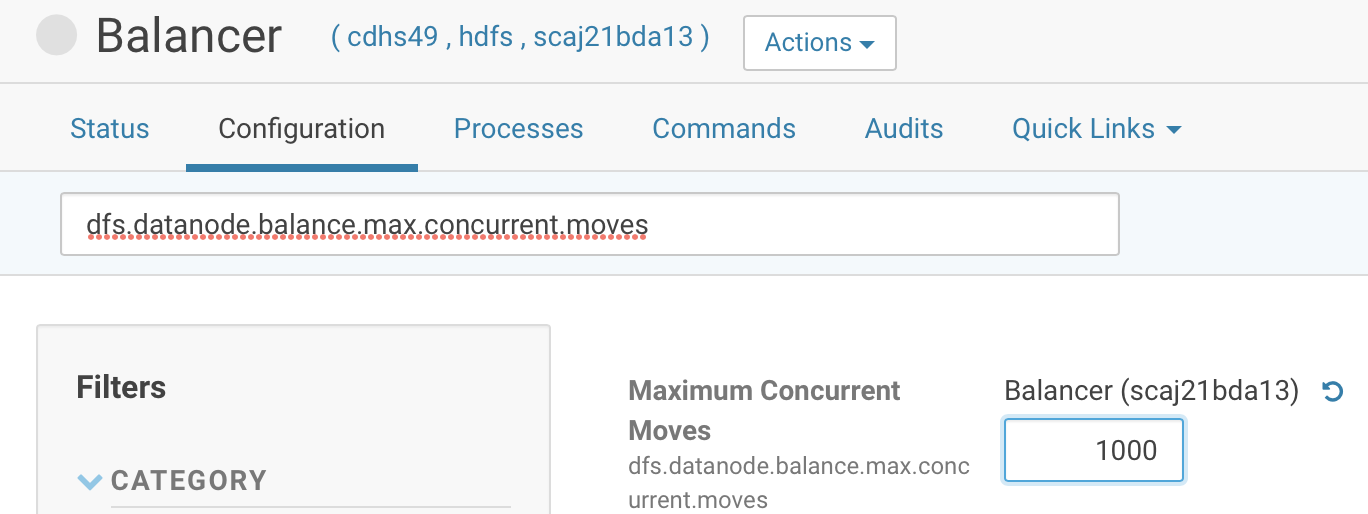
also, in order to speed up rebalance speed, we could increase value of “dfs.datanode.balance.max.concurrent.moves” from 10 to 1000 (Number of block moves to permit in parallel).
After make this changes, save it and run rebalancing:
 In case of heavily used clusters for reading/writing/deleting HDFS data we may hit disbalance within one node (when data unevenly distributed across multiple disks within one node). Here is the Cloudera Blog about it. Shortly, we have to go to “Cloudera Manager – > HDFS -> Configuration -> HDFS Service Advanced Configuration Snippet (Safety Valve) for hdfs-site.xml” and add dfs.disk.balancer.enabled as a name and true as the value.
In case of heavily used clusters for reading/writing/deleting HDFS data we may hit disbalance within one node (when data unevenly distributed across multiple disks within one node). Here is the Cloudera Blog about it. Shortly, we have to go to “Cloudera Manager – > HDFS -> Configuration -> HDFS Service Advanced Configuration Snippet (Safety Valve) for hdfs-site.xml” and add dfs.disk.balancer.enabled as a name and true as the value.
Sometimes, you may have real data skew problem, which could easily be fixed by running rebalance:
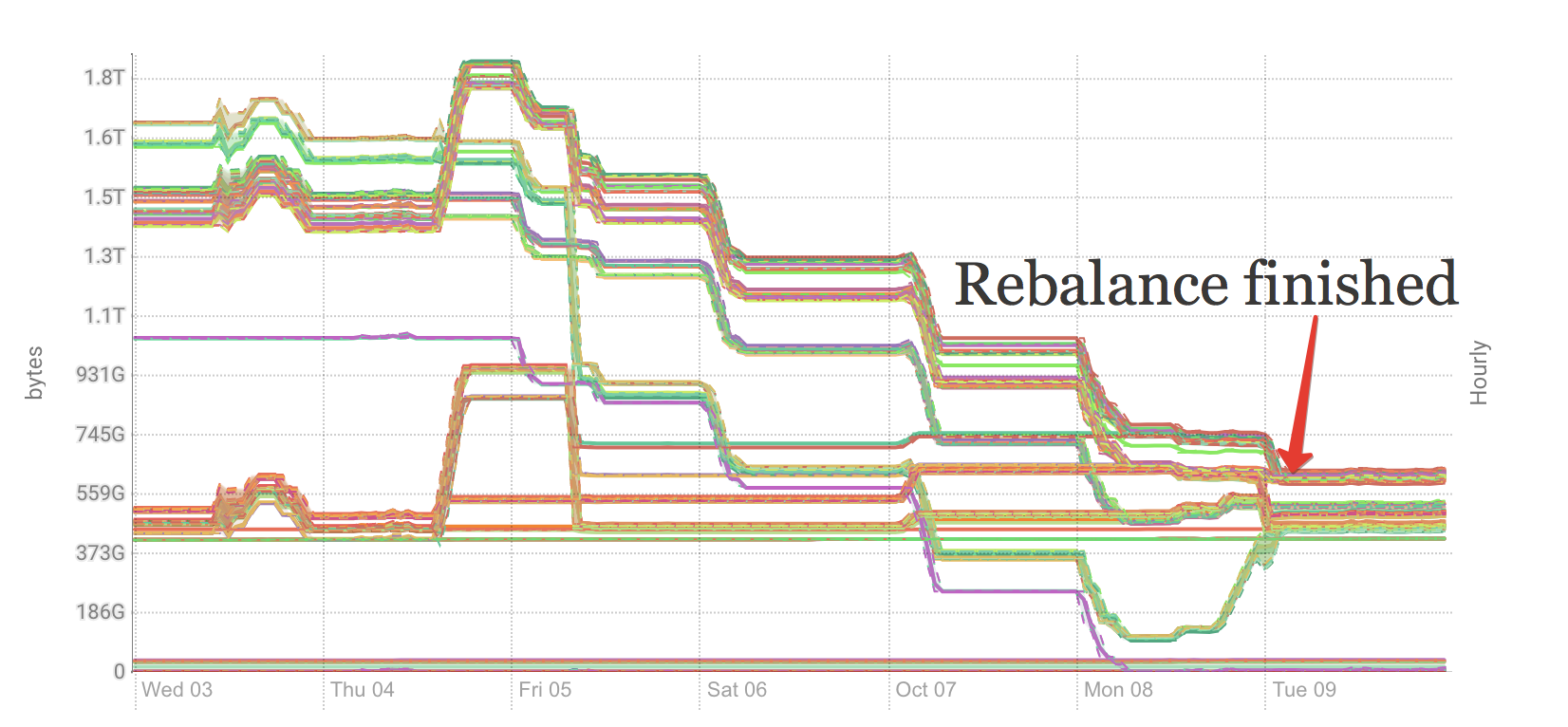
Note: If you want to visualize data distribution, you could check this tool developed at CERN.
Step 3.1.9 HDFS Disaster Recovery. Big Data Disaster Recovery (BDR). Hive
There is also some option for coping Hive Metadata and as well as actual Data.
Note: if you would like to copy some particular database schema you need to specify it in the copy wizard as well as specify regular expression which tables you want to copy ([\w].+ for all tables).
For example, this replication policy will copy all tables from database “parq”.
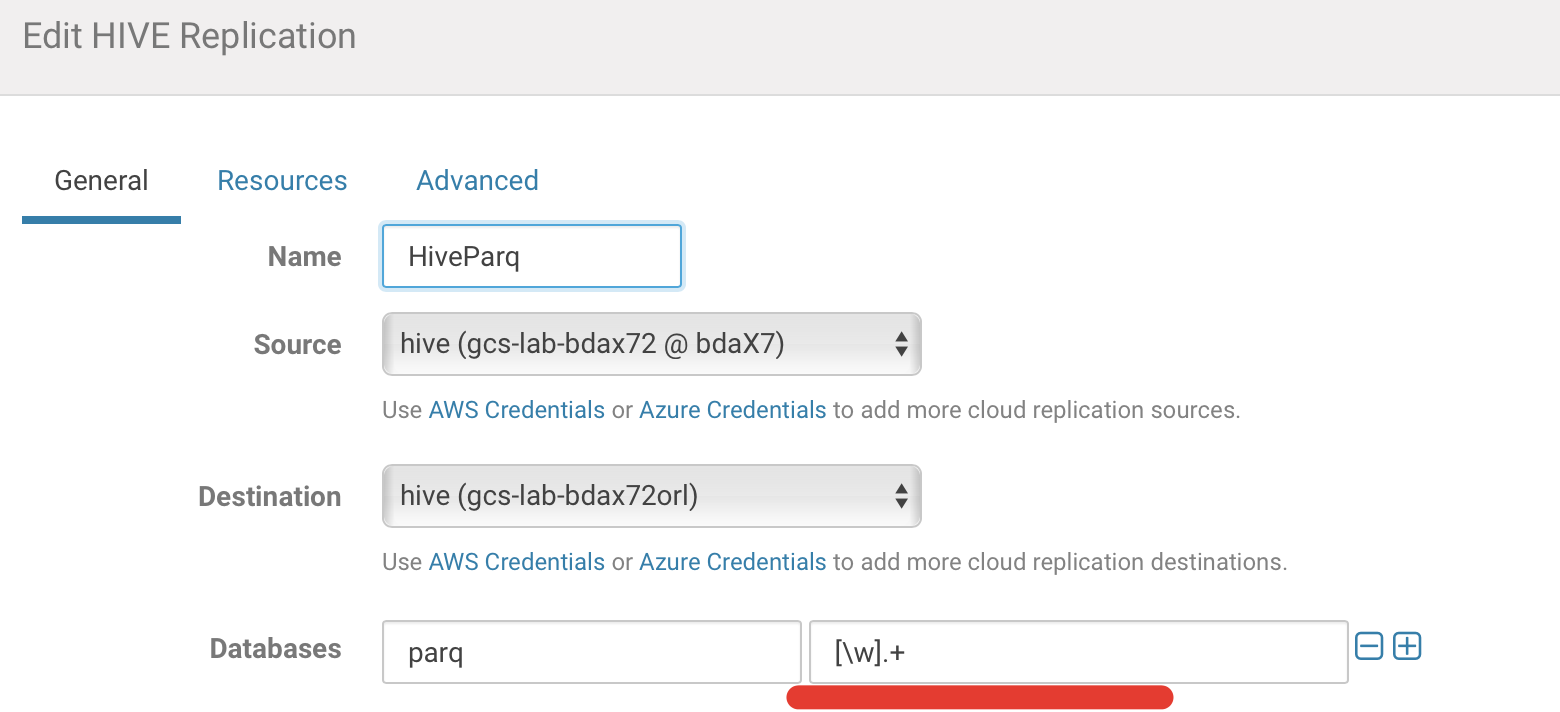 if you will leave it blank, you will not copy anything. More examples of regular expression you could find here.
if you will leave it blank, you will not copy anything. More examples of regular expression you could find here.
3.1.10 HDFS Disaster Recovery. Big Data Disaster Recovery (BDR). Sentry
Sentry is the default authorization mechanism in Cloudera and you may want to replicate authorization rules on the second cluster. Unfortunately, there is no any mechanism embedded into BDR and you have to come with own solution.
Note: you have to configure Sentry in certain way to make it work with BDR. Please refer here to get more details.
Step 3.1.11 HDFS Disaster Recovery. Big Data Disaster Recovery (BDR). Advantages and Disadvantages of BDR
Generally speaking, I could to recommend use BDR as long as it meet your needs and requirements. Here is a brief summary of advantages and disadvantages of BDR.
Advantages (+):
– It’s available out of the box, no need to install
– It’s free of charge
– It’s relative easy to configure and start working with basic examples
Disadvantages (-):
– It’s not real-time tool. User have to schedule batch jobs, which will run every time period
– There is no transparent way to fail over. In case of failing of primary side, uses have to manually switch over their applications into the new cluster
– BDR (distcp under the cover) is MapReduce job, which takes significant resources.
– Because of previous one and because of MR nature in case of coping one big file it will not be parallelized (will be copied in one thread)
– Hive changes not fully replicated (drop tables have to be backup manually)
– In case of replication big number of files (or Hive table with big number of partitions) it takes long time to finish. I can say that it’s near to impossible to replicate directory if it has around 1 million objects (files/directories)
– It’s only Cloudera to Cloudera or Cloudera to Object Store copy. No way copy to Hortonworks (but after merging this companies it’s not a huge problem anymore)
Step 3.2 HDFS Disaster Recovery. Wandisco
If you met one of the challenges, that I’ve explained before, it make sense to take a look not the alternative solution called Wandisco.
Step 3.2.1 HDFS Disaster Recovery. Wandisco. Edge (proxy) node
In case of Wandisco you will need to prepare some proxy nodes on the source and destination side. We do recommend to use one of the Big Data Appliance node and here you may refer to MOS note, which will guide you on how to make one of the node available for been proxy node:
How to Remove Non-Critical Nodes from a BDA Cluster (Doc ID 2244458.1)
Step 3.2.2 HDFS Disaster Recovery. Wandisco. Installation
WANdisco Fusion is enterprise class software. It requires careful environment requirements gathering for the installation, especially with multi-homed networking as in Oracle BDA. Once the environment is fully understood, care must be taken in completing the installation screens by following the documentation closely.
Note: if you have some clusters which you want deal by BDR and they don’t have Wandisco fusion software, you have to install Fusion client on it
Step 3.2.3 HDFS Disaster Recovery. Wandisco. Architecture
For my tests I’ve used two Big Data Appliances (Starter Rack – 6 nodes). Wandisco required to install their software on the edge nodes and I’ve converted Node06 into the Edge node for Wandisco purposes. Final architecture looks like this:
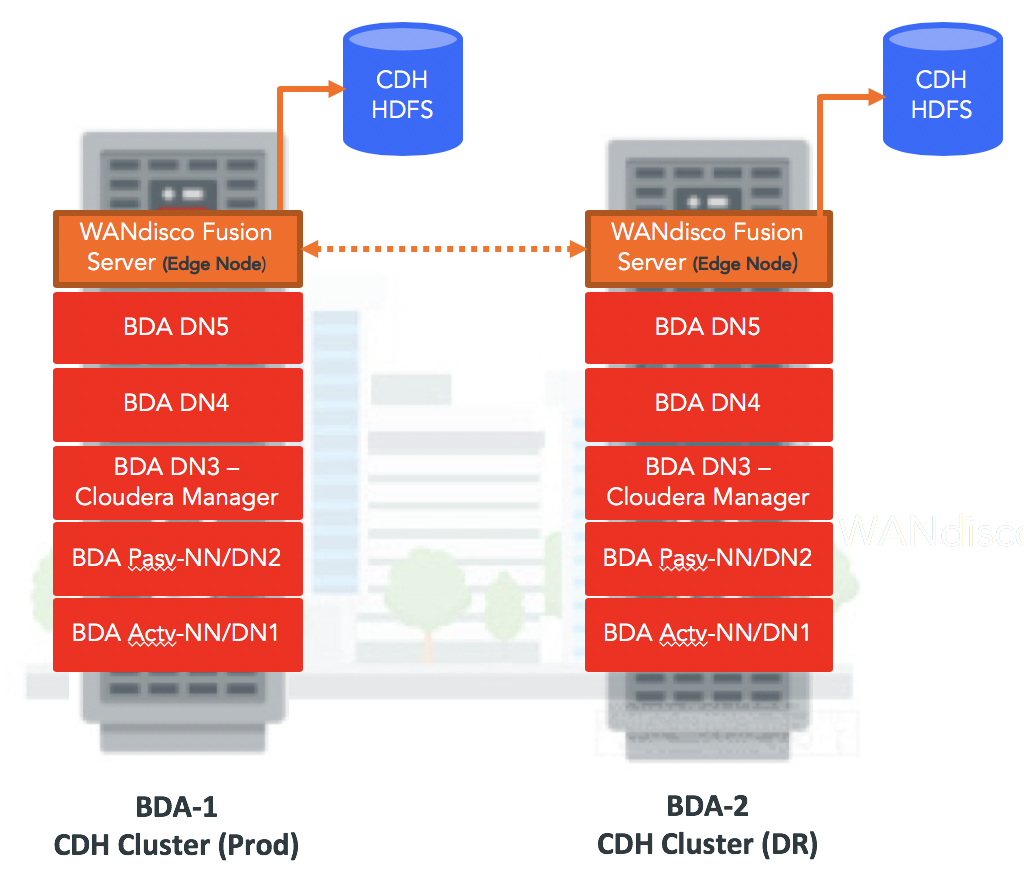
Step 3.2.4 HDFS Disaster Recovery. Wandisco. Replication by example
Here I’d like to show how you have to set up replication between two clusters. You need to install Wandisco fusion software on both clusters. As soon as you install fusion on the second (DR) cluster you need to do Induction (peering) with the first (Prod) cluster. As a result of installation, you have WebUI for Wandisco Fusion (it’s recommended to be installed in on the Edge Node), you have to go there and setup replication rules.
 go to replication bookmark and click on “create” button:
go to replication bookmark and click on “create” button:
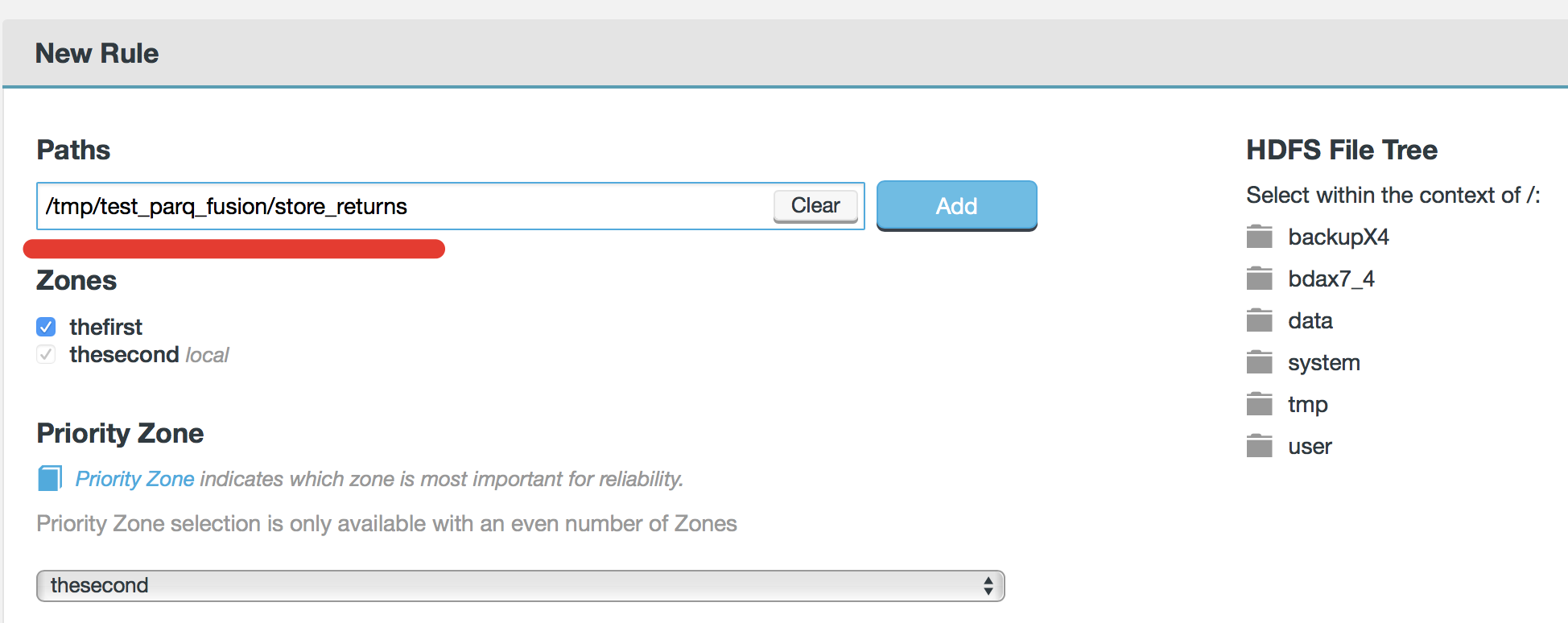
 after this specify path, which you would like to replicate and choose source of truth:
after this specify path, which you would like to replicate and choose source of truth:
after this click on “make consistent” button to kick-off replication:
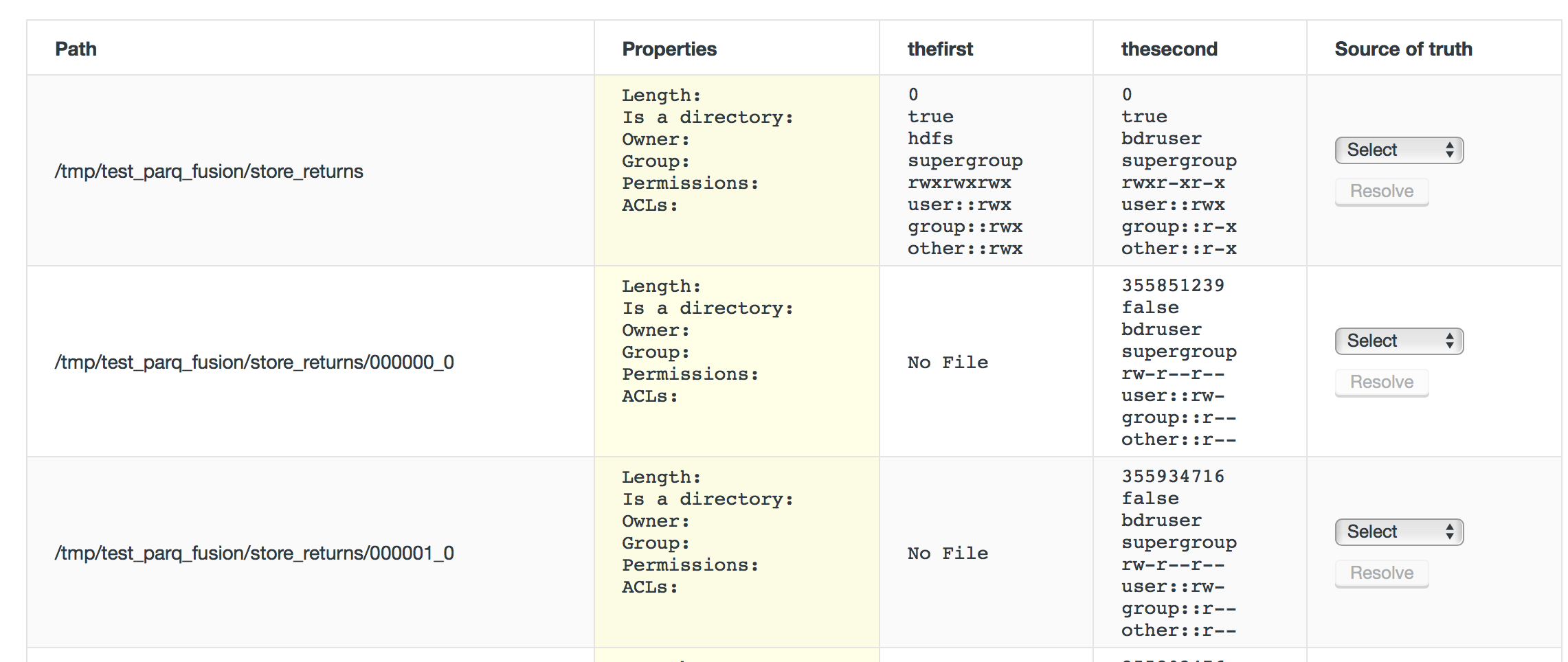
 you could monitor list of the files and permissions which is not replicated yet:
you could monitor list of the files and permissions which is not replicated yet:
and you could monitor performance of the replication in real time:
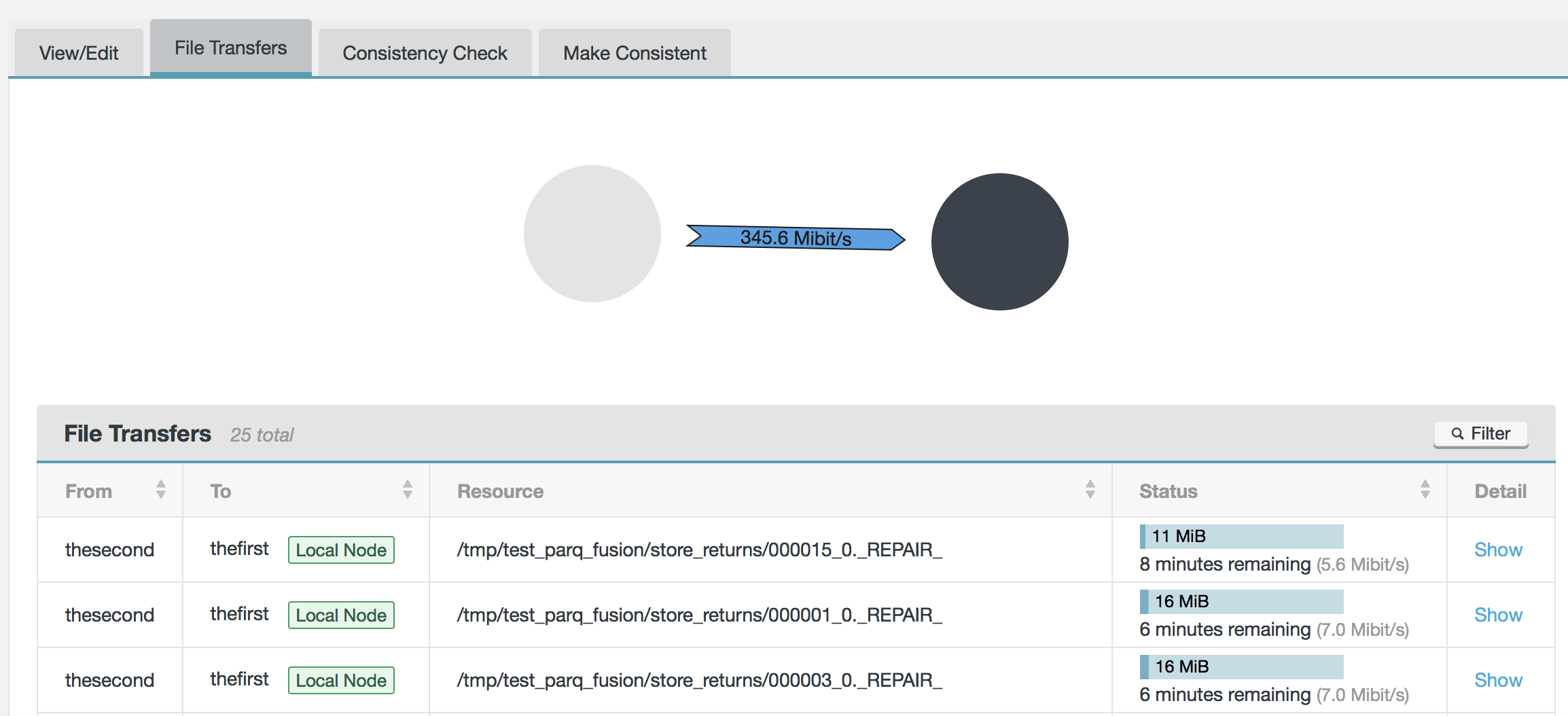 on the destination cluster you may see files, which not been replicated yet (metadata only) with prefix “_REPAIR_”
on the destination cluster you may see files, which not been replicated yet (metadata only) with prefix “_REPAIR_”
[root@dstclusterNode01 ~]# hadoop fs -ls /tmp/test_parq_fusion/store_returns/
19/03/26 22:48:38 INFO client.FusionUriUtils: fs.fusion.check.underlyingFs: [true], URI: [hdfs://gcs-lab-bdax72orl-ns], useFusionForURI: [true]
19/03/26 22:48:38 INFO client.FusionCommonFactory: Initialized FusionHdfs with URI: hdfs://gcs-lab-bdax72orl-ns, FileSystem: DFS[DFSClient[clientName=DFSClient_NONMAPREDUCE_142575995_1, ugi=hdfs/dstclusterNode01.us.oracle.com@US.ORACLE (auth:KERBEROS)]], instance: 1429351083, version: 2.12.4.3
Found 26 items
drwxrwxrwx – hdfs supergroup 0 2019-03-26 18:29 /tmp/test_parq_fusion/store_returns/.fusion
-rw-r–r– 3 hdfs supergroup 0 2019-03-26 22:48 /tmp/test_parq_fusion/store_returns/000000_0._REPAIR_
-rw-r–r– 3 hdfs supergroup 0 2019-03-26 22:48 /tmp/test_parq_fusion/store_returns/000001_0._REPAIR_
-rw-r–r– 3 hdfs supergroup 0 2019-03-26 22:48 /tmp/test_parq_fusion/store_returns/000002_0._REPAIR_
-rw-r–r– 3 hdfs supergroup 0 2019-03-26 22:48 /tmp/test_parq_fusion/store_returns/000003_0._REPAIR_
if you put some file on one of the side, it will appear automatically on the other side (no action required)
Step 3.2.5 HDFS Disaster Recovery. Wandisco. Hive
The Fusion Plugin for Live Hive enables WANdisco Fusion to replicate Hive’s metastore, allowing WANdisco Fusion to maintain a replicated instance of Hive’s metadata and, in future, support Hive deployments that are distributed between data centers.
The Fusion Plugin for Live Hive extends WANdisco Fusion by replicating Apache Hive metadata. With it, WANdisco Fusion maintains a Live Data environment including Hive content, so that applications can access, use, and modify a consistent view of data everywhere, spanning platforms and locations, even at petabyte scale. WANdisco Fusion ensures the availability and accessibility of critical data everywhere.
Here you could find more details.
Step 3.2.6 HDFS Disaster Recovery. Wandisco. Sentry
Use the Fusion Plugin for Live Sentry to extend the WANdisco Fusion server with the ability to replicate policies among Apache Sentry Policy Provider instances. Coordinate activities that modify Sentry policy definitions among multiple instances of the Sentry Policy Provider across separate clusters to maintain common policy enforcement in each cluster. The Fusion Plugin for Live Sentry uses WANdisco Fusion for coordination and replication.
Here you could find more details.
Step 3.2.7 HDFS Disaster Recovery. Wandisco. Advantages and Disadvantages
Talking about Wandisco disadvantages I have to say that it was very hard to install it. Wandisco folks promised that it will be enhanced in a future, but time will show.
Advantages (+):
– It’s realtime. You just load data into the one cluster and another cluster immediately pick up the changes
– it’s Active-Active replication. You could load data in both clusters and data-sync will be done automatically
– Sentry policies replication
– Use less resources than BDR
– Easy to manage replication policies by WebUI
– Wandisco supports cross Hadoop distros replication
– Wandisco is multiple endpoint (or multi-target) replication. A replication rule isn’t limited to just source and target (e.g. Prod, DR, Object Store)
Disadvantages (-):
– A common trade-off for additional features can often be additional complexity during installation. This is the case with WANdisco Fusion
– it costs extra money (BDR is free)
– It requires special Hadoop client. As consequence if you want to replicate data with BDR on some remote clusters, you need to install Wandisco Fusion Hadoop client on it
Step 3.3 HDFS Disaster Recovery. Conclusion
I’ll leave it to customer to decide which replication approach is better, I’d just say that it’s good approach start with Big Data Disaster Recovery (because it’s free and ready to use out of the box) and if customer will have some challenges with it try Wandisco software.
Step 4.1 HBase Disaster Recovery
in this blog post I’ve focused on the HDFS and Hive data replication. If you want to replicate HBase on the remote cluster, all details on how to do this you could find here.
Step 5.1 Kafka Disaster Recovery
Kafka is another place where users may store the data and want to replicate it. Cloudera recommends to use Mirror Maker in order to do this.
Step 6.1 Kudu Disaster Recovery
There is another option available for customers to store their data – Kudu. As of today (03/01/2019) Kudu doesn’t have solution to replicate data on the Disaster Recovery side.
Step 7.1 Solr Disaster Recovery
Solr or Cloudera search is another one engine to store data. You may get familiar with DR best practices, by reading this blog from Cloudera.
