If you saw last week’s Autonomous Database newsletter you will have noticed that one of the new features that I announced was support for SQL Macros), see here and if you want to sign-up for the Autonomous Database newsletter then see here. Whilst the newsletter included a link to the SQL documentation, I thought it would be useful to write blog post to provides some more insight into how this new feature can make your SQL code both simpler and faster and give you yet another great reason to move your workloads to the cloud. Lets get started…
What is a SQL Macro
It’s a new, simpler way to encapsulate complex processing logic directly within SQL. SQL Macros allow developers to encapsulate complex processing within a new structure called a “macro” which can then be used within SQL statement. Essentially there two types of SQL Macros: SCALAR and TABLE. What’s the difference:
- SCALAR expressions can be used in SELECT list, WHERE/HAVING, GROUP BY/ORDER BY clauses
- TABLE expressions used in a FROM-clause
Why Do We Need SQL Macros When We Have PL/SQL?
In the past, if you wanted to extend the capabilities of SQL, then PL/SQL was the usually the best way to do add additional, more complex processing logic. However, by using PL/SQL this created some underlying complexities at execution time since we needed to keep swapping between the SQL context and the PL/SQL context. This tended to have an impact on performance and most people tried to avoid doing it whenever possible.
Why Is A SQL Macro Better Than A PL/SQL Function?
SQL Macros have an important advantage over ordinary PL/SQL functions in that they make the reusable SQL code completely transparent to the Optimizer – and that brings big benefits! It makes it possible for the optimizer to transform the original code for efficient execution because the underlying query inside the macro function can be merged into outer query. That means there is no context switching between PL/SQL and SQL and the query inside the macro function is now executed under same snapshot as outer query. So we get both simplicity and faster execution.
How Does Autonomous Database Support SQL Macros
As of today, Autonomous Database only supports TABLE macros with support for SCALAR macros coming later. I provided a gentle introduction to SQL Macros at OpenWorld 2019 and you can download the presentation from here: A New Approach To Simplifying Complex SQL. This covers both types of scalar macros so you understand how they can be used today and what you will be able to do shortly when the SCALAR macros are supported.
So what can we do today with a TABLE macro?
Two Types of Table Macros
There are two types of table macros:
1 Parameterized Views: tables used in the query are fixed inside the definition of the macro and arguments are passed in to select all or specific rows from those tables. The “shape” of the queries returned from these table is, in most cases, fixed. The most common use of these parameterized views is when you need to pass in arguments to select a subset of the rows that are then aggregated. The first code example below is a good example where I pass in a specific zip code and get the total sales revenue for that zip code.
2. Polymorphic Views: These are more interesting (at least I find them more interesting) because they have one or more table arguments (of course they can also have scalar valued arguments as well). The passed in tables are used inside the query returned by the macro which gives them a lot flexibility. The second set of code examples below show this type of macro and I can see this being of real interest to DBAs because of the overall flexibility and power it provides to create useful utilities. This is probably going to need a follow-up post at some point.
How Do I Create A Table Macro?
We define a SQL macro using something like the following syntax:
CREATE OR REPLACE FUNCTION total_sales(zip_code VARCHAR2) RETURN VARCHAR2 SQL_MACRO…..
the keyword is ‘SQL_MACRO’ as the return type which is a text string containing SQL that will be substituted into the original statement at execution time. There is a lot that can be done with SQL Macros, simply because they provide so much flexibility, however, my aim here is try and keep things simple just to get us started. Maybe I will go deeper in subsequent blog posts. Let’s create a simple table macro…
My First Table Macro
For our first table macro let’s keep things relatively simple. Suppose I want to have a function that returns the total sales revenue from my fact table SALES for a specific zip code in my CUSTOMERS table. I need to join the two tables together (SALES and CUSTOMERS), find the matching rows and sum the result. In effect, we are creating a paramterized view. The SQL Macro will look like this:
create or replace function total_sales(zip_code varchar2) return varchar2 SQL_MACRO(TABLE) is
begin
return q'{
select cust.cust_postal_code as zip_code,
sum(amount_sold) as revenue
from sh.customers cust, sh.sales s
where cust.cust_postal_code = total_sales.zip_code
and s.cust_id = cust.cust_id
group by cust.cust_postal_code
order by cust.cust_postal_code
}’;
end;
/
essentially I am encapsulating a parameter driven SQL query within a PL/SQL function which is of type SQL MACRO. To execute a query using the macro I do this:
select * from total_sales(‘60332’);
and the output is as follows:
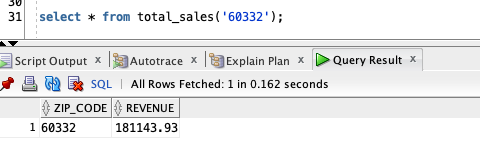
So far so good…the explain plan is very interesting because what you see is not an explain plan for TOTAL_SALES but the SQL within the MACRO which was transparently inserted by the Optimizer…
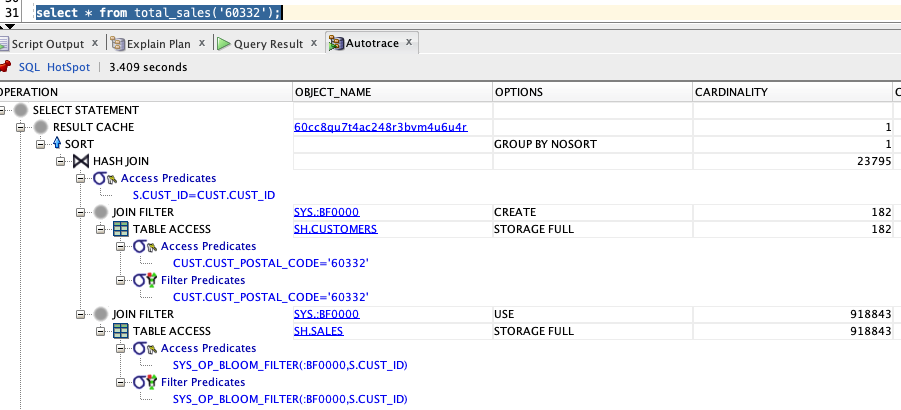
Obviously the SQL statement within the MACRO can be as simple or complex as needed. But this macro only allows you to query the SALES fact table and CUSTOMERS dimension table. What if we want a more dynamic approach where I could pass in any table to my MACRO for processing?
Going A Little Deeper…
In 12c we introduced a new set of keywords to return a subset of rows from a table. Mr Optimizer (aka. Nigel Bayliss) wrote a post about this which you can read here. This allowed you to return the first 10 rows of resultset by using the syntax FETCH FIRST 10 ROWS ONLY. Let’s take this new feature and wrap it up in a TABLE MACRO:
create or replace function keep_n(n_rows number, t DBMS_TF.Table_t)
return varchar2 SQL_MACRO(TABLE) is
begin
return ‘select *
from t
order by 1
fetch first keep_n.n_rows rows only’;
end;
/
this may look complicated but it is relatively simple to explain. The mysterious part for many readers will be the datatype for t which is DBMS_TF.Table_t. Why not simply use a varchar2 string to capture the table name? Because that could lead to SQL injection so we force the input to be a valid table name by enforcing the type via DBMS_TF.Table_t. If you want to learn more about why and how to use DBMS_TF.table_t then I would recommend watching Chris Saxon’s webcast from the recent Developer Live event – “21st Century SQL“.
The above SQL Macro allows me to set the number of rows I want returned from any table and the output is completely dynamic in that all columns in the specified table are returned:
select * from keep_n(10, sh.customers);
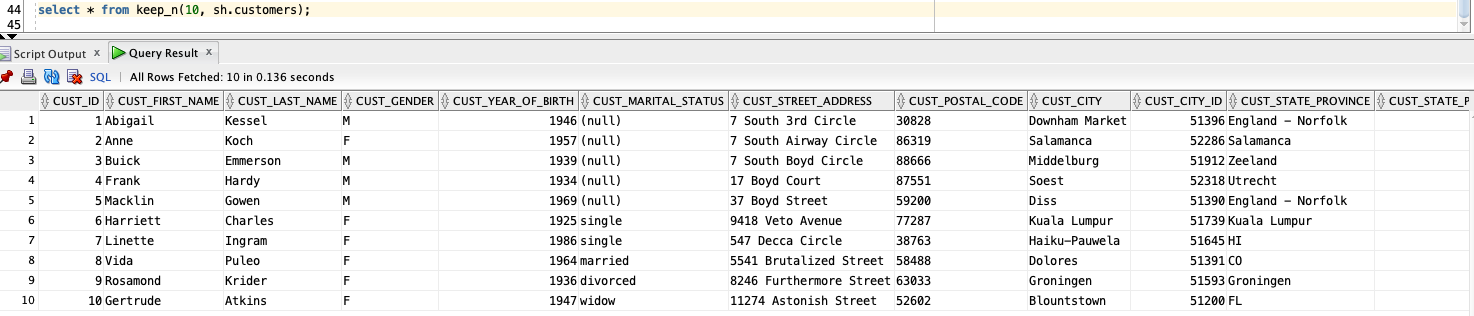
returns the first 10 rows from my table SH.CUSTOMERS. The following statement returns the first 2 rows from my table SH.CHANNELS:
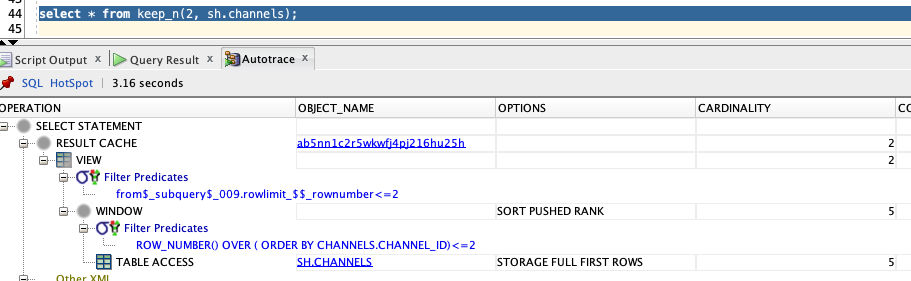
select * from keep_n(2, sh.channels);
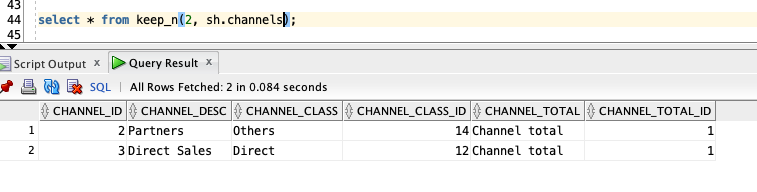
and the explain plan for the above query is transformed by the Optimizer to the actual query inside the macro:
select *
from sh.channels
order by 1
fetch first 2 rows only’;
Going A Even Deeper..
What if we wanted to extend our table macro to return a random sample of rows from any table? That’s a very simple thing to do with a macro! We just need to tweak the FETCH syntax to use PERCENT ROWS and insert an order by clause that uses the DBMS_RANDOM function. Now the macro looks like this…
CREATE OR REPLACE FUNCTION row_sampler(t DBMS_TF.Table_t, pct number DEFAULT 5) RETURN VARCHAR2 SQL_MACRO(TABLE)
AS
BEGIN
RETURN q'{SELECT *
FROM t
order by dbms_random.value
fetch first row_sampler.pct percent rows only}’;
END;
/
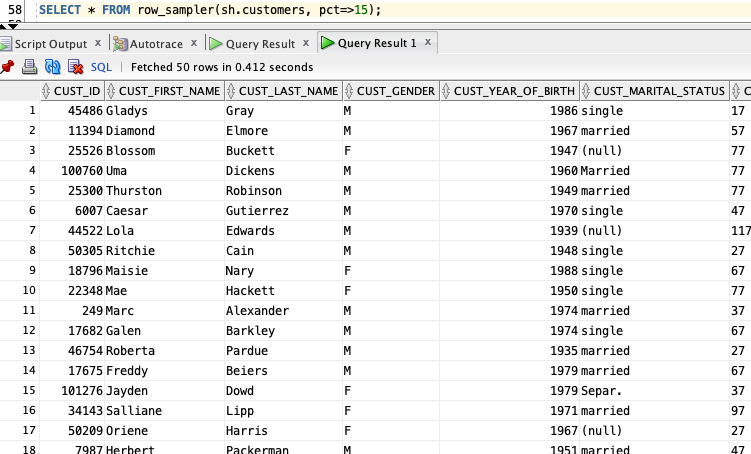
which allows me to randomly sample 15% of rows from my CUSTOMERS table:
SELECT * FROM row_sampler(sh.customers, pct=>15);
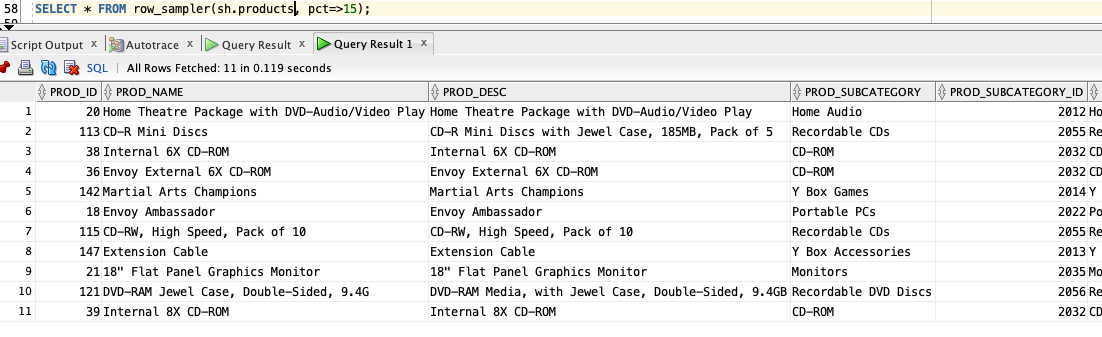
or my PRODUCTS table:
SELECT * FROM row_sampler(sh.products, pct=>15);
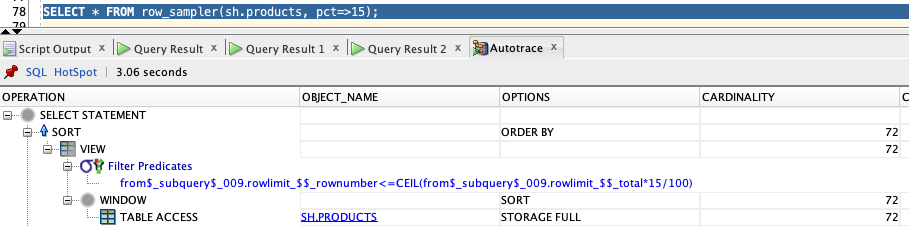
and again the explain looks as if we had written the the SQL statement in full as:
SELECT *
FROM sh.products
ORDER BY dbms_random.value
FETCH FIRST 15 percent rows only
Conclusion
Hopefully this has given you a little bit of a peek into the exciting new world of SQL Macros. This new feature is extremely powerful and I would recommend watching Chris Saxon’s video from the recent Developer Live event – “21st Century SQL” – for more information on how to use SQL Macros with other features such as SQL pattern matching (MATCH_RECOGNIZE). Don’t forget to take a look at the documentation, see here.
LiveSQL will shortly be updated to the same patchset release as Autonomous Database and once that happens then I will start posting some code samples that you test and play with on that platform. Don’t forget you can always sign up for a 100% free account to run your own Autonomous Database: https://www.oracle.com/cloud/free/
Have fun with SQL Macros!
