Security is a very important aspect of many projects and you must not underestimate it, Hadoop security is very complex and consist of many components, it’s better to enable one by one security features. Before starting the explanation of different security options, I’ll share some materials that will help you to get familiar with the foundation of algorithms and technologies that underpin many security features in Hadoop.
Before you begin
First of all, I recommend that you watch this excellent video series, which explains how asymmetric key works and how RSA algorithm works (this is the basis for SSL/TLS). Then, read this this blog about TLS/SSL principals.
Also, if you mix up terms such as Active Directory, LDAP, OpenLDAP and so, it will be useful to check this page.
After you get familiar with the concepts, you can concentrate on the implementation scenarios with Hadoop.
Security building blocks
There are few building blocks of secure system:
– Authentication. Answers on questions who you are. It’s like a passport validation. For example, if someone says that he is Bill Smith, he should prove this (pass Authentication) with certain document (like a passport)
– Authorization. After passing Authentication, user could be trusted (we checked his passport and make sure that he is Bill Smith) and next question to be asked – what this user allowed to do on the cluster (usually cluster shared between multiple users and multiple groups and not each dataset should be available for everyone)? This is Authorization
– Encryption in motion. Hadoop is distributed system and definitely there is data movement (over the network) happens. This traffic could be intercepted. To prevent this we have to encrypt it. This called encryption in motion
– Encryption at REST. Data stored on hard disks and and some privileged user (like root) may have access to this disks and read any directories, including those that store Hadoop data. Also, disks could be physically stolen and mounted on any machine for future access. To protect you data from such kind of vulnerability, you have to encrypt data. This called encryption at REST
– Audit. Sometimes data breach is happens and only one what you can do it’s define the channel of this breach. For this you have to use Audit tools
Step1. Authentication in Hadoop. Motivation
By design, Hadoop doesn’t have any security. So, if you spin up a cluster – by default it’s insecure. It assumes a level of trust; and assumes that only trusted users have access to the cluster. In HDFS, files and folders have permissions – similar to Linux – and users access files based on access control lists – or ACLs. See the diagram below that highlights different access paths into the cluster: shell/CLI, JDBC, and tools like Hue.
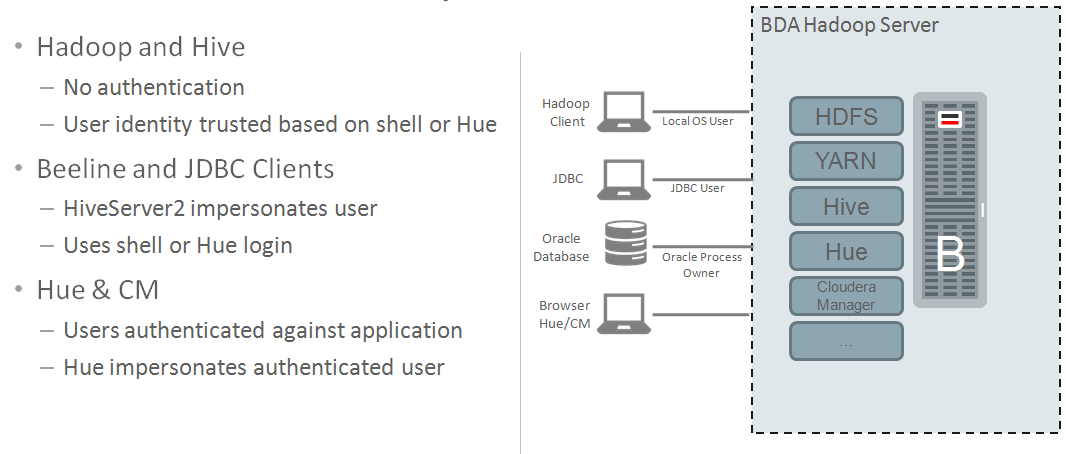
As you can see below, each file/folder has access privileges assigned. The oracle user is the owner of the items – and other users can access the items based on the access control definition (e.g. -rw-r–r– means that Oracle can read/write to the file, users in the oinstall group can read the file, and the rest of the world can also read the file).
$ hadoop fs -ls
Found 57 items
drwxr-xr-x – oracle hadoop 0 2017-05-25 15:20 binTest
drwxr-xr-x – oracle hadoop 0 2017-05-30 14:04 clustJobJune
drwxr-xr-x – oracle hadoop 0 2017-05-26 11:47 exercise0
drwxr-xr-x – oracle hadoop 0 2017-05-22 16:07 hierarchyIndex
drwxr-xr-x – oracle hadoop 0 2017-05-22 16:15 hierarchyIndexWithCities
drwxr-xr-x – oracle hadoop 0 2017-05-22 16:46 hive_examples
…

Additionally, accessing data thru tools like Hive are also completely open. The user that is passed as part of the JDBC connection will be used for data authorization. Note, you can specify any(!) user that you want – there is no authentication! So, all data in Hive is open for query. If you care about the data, then this is a real problem.
Step1. Authentication in Hadoop. Edge node
Instead of enabling connectivity from any client, a Edge node (you may think of it like client node) created that users log into it and has access to the cluster. Access to a Hadoop cluster is prohibited from other servers rather than this Edge node.
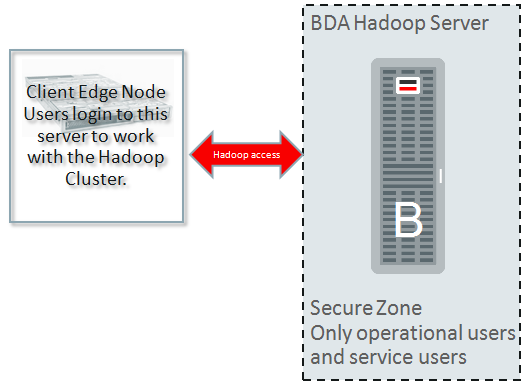
Edge node is used for:
– Run jobs and interact with the Hadoop Cluster
– Run all gateway services of Hadoop components
Because a user logged into this edge node and did not have the ability to alter his or her identity, the identity can be trusted. This means that HDFS ACLs now have some meaning
– User identity established on edge node
– Connect only thru known access paths and hosts
Note: in HDFS there is feature extended ACL, which allow to have extended security lists, so you could grant permissions outside of the group.
$ hadoop fs -mkdir /user/oracle/test_dir
$ hdfs dfs -getfacl /user/oracle/test_dir
# file: /user/oracle/test_dir
# owner: oracle
# group: hadoop
user::rwx
group::r-x
other::r-x
$ hdfs dfs -setfacl -m user:ben:rw- /user/oracle/test_dir
$ hdfs dfs -getfacl /user/oracle/test_dir
# file: /user/oracle/test_dir
# owner: oracle
# group: hadoop
user::rwx
user:ben:rw-
group::r-x
mask::rwx
other::r-x
Challenge: JDBC is still insecure
– User identified in JDBC connect string not authenticated
Here is the example how I can use beeline tool from cli for work on behalf of “superuser” who may do whatever he wants on the cluster:
$ beeline
…
beeline> !connect jdbc:hive2://localhost:10000/default;
…
Enter username for jdbc:hive2://localhost:10000/default;: superuser
Enter password for jdbc:hive2://localhost:10000/default;: *
…
0: jdbc:hive2://localhost:10000/default> select current_user();
…
+————+–+
| _c0 |
+————+–+
| superuser |
+————+–+
To ensure that identities are trusted, we need to introduce a capability that you probably use all the time and didn’t even know it: Kerberos.
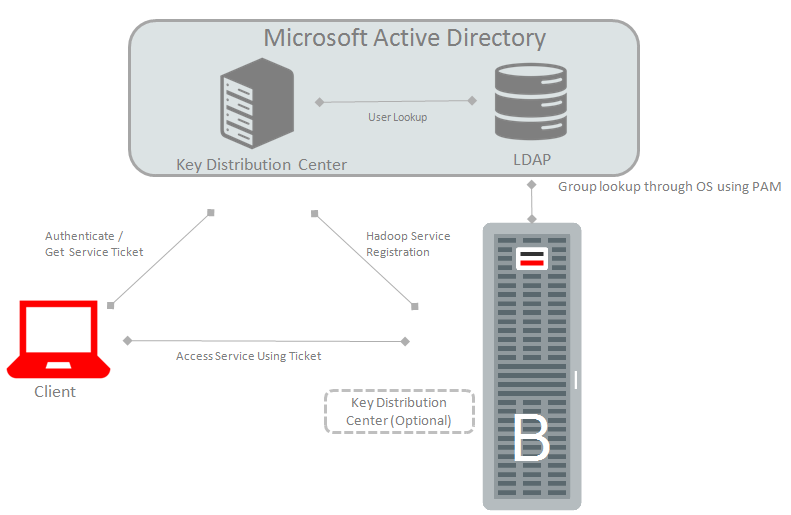
Step1. Authentication in Hadoop. Kerberos
Kerberos ensures that both users and services are authenticated. Kerberos is *the* authentication mechanism for Hadoop deployments:
Before interacting with cluster user have to obtain Kerberos ticket (think of it like a passport).
 The two most common ways to use Kerberos with Oracle Big Data Appliance is using it with:
The two most common ways to use Kerberos with Oracle Big Data Appliance is using it with:
a) Active Directory Kerberos
b) MIT Kerberos.
On the Oracle support site you will find the step by step instruction for enabling both of this configuration. Check for “BDA V4.2 and Higher Active Directory Kerberos Install and Upgrade Frequently Asked Questions (FAQ) (Doc ID 2013585.1)” for the Active Directory implementation and “Instructions to Enable Kerberos on Oracle Big Data Appliance with Mammoth V3.1/V4.* Release (Doc ID 1919445.1)” for MIT Kerberos. Oracle recommends using MIT local Kerberos for system services like HDFS, YARN and AD Kerberos for the human users (like user John Smith). Also, if you want to set up trusted relationships between them (to make possible for AD users work with Cluster), you have to follow support note “How to Set up a Cross-Realm Trust to Configure a BDA MIT Kerberos Enabled Cluster with Active Directory on BDA V4.5 and Higher (Doc ID 2198152.1)”.
Note: Big Data Appliance greatly simplifies the implementation of highly available Kerberos deployment on a Hadoop cluster. You do not need to do the manual setup (and should not) of Kerberos settings. Use tools, which is provided by BDA.
Using MOS 1919445.1 I’ve enabled MIT Kerberos on my BDA cluster.
So, what has been changed in my daily life with Hadoop cluster?
First of all, I’m trying to list files in HDFS:
# id
uid=0(root) gid=0(root) groups=0(root) context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
# hadoop fs -ls /
…
Caused by: java.io.IOException: javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)]
…
Oops… seems something is missing. I can not access the data in HDFS – “No valid credentials provided”. In order to gain access to HDFS, I must first obtain a Kerberos ticket:
# kinit oracle/scajvm1bda01.vm.oracle.com
kinit: Client not found in Kerberos database while getting initial credentials
Still not able to access HDFS! That’s because the user principal must be added to the Key Distribution Center – or KDC. As the Kerberos admin, add the principal:
# kadmin.local -q “addprinc oracle/scajvm1bda01.vm.oracle.com”
Now, I can successfully obtain the Kerberos ticket:
# kinit oracle/scajvm1bda01.vm.oracle.com
Password for oracle@ORACLE.TEST:
Practical Tip: Use keytab files
Here we go! I’m ready to work with my Hadoop cluster. But I don’t want to enter the password every single time when I obtaining the ticket (this is important for services as well). For this, I need to create keytab file.
# kadmin.local
kadmin.local: xst -norandkey -k oracle.scajvm1bda01.vm.oracle.com.keytab oracle/scajvm1bda01.vm.oracle.com
# kinit -kt oracle.scajvm1bda01.vm.oracle.com.keytab oracle/scajvm1bda01.vm.oracle.com
# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: oracle/scajvm1bda01.vm.oracle.com@ORALCE.TEST
Valid starting Expires Service principal
07/28/17 12:59:28 07/29/17 12:59:28 krbtgt/ORALCE.TEST@ORALCE.TEST
renew until 08/04/17 12:59:28
# hadoop fs -ls /user/
Found 7 items
drwx—— – hdfs supergroup 0 2017-07-27 18:21 /user/hdfs
drwxrwxrwx – mapred hadoop 0 2017-07-27 00:32 /user/history
drwxr-xr-x – hive supergroup 0 2017-07-27 00:33 /user/hive
drwxrwxr-x – hue hue 0 2017-07-27 00:32 /user/hue
drwxr-xr-x – oozie hadoop 0 2017-07-27 00:34 /user/oozie
drwxr-xr-x – oracle hadoop 0 2017-07-27 18:57 /user/oracle
drwxr-x–x – spark spark 0 2017-07-27 00:34 /user/spark
# hadoop fs -ls /user/oracle
Found 4 items
drwx—— – oracle hadoop 0 2017-07-27 19:00 /user/oracle/.Trash
drwxr-xr-x – oracle hadoop 0 2017-07-27 18:54 /user/oracle/.sparkStaging
drwx—— – oracle hadoop 0 2017-07-27 18:57 /user/oracle/.staging
drwxr-xr-x – oracle hadoop 0 2017-07-27 18:57 /user/oracle/oozie-oozi
# hadoop fs -ls /user/spark
ls: Permission denied: user=oracle, access=READ_EXECUTE, inode=”/user/spark”:spark:spark:drwxr-x–x
WARNING: please keep in mind that you have to keep it in a safe directory and set permissions carefully on it (because anyone who can read it can impersonate them).
It’s interesting to note, that if you work on Hadoop servers, you already have many keytab files and for example, if you want to get an HDFS tickets you may easily do this. For getting the list of the principals for certain keytab file just run:
# klist -ket `find / -name hdfs.keytab -printf “%T+\t%p\n” | sort|tail -1|cut -f 2`
and for obtaining the ticket, run:
# kinit -kt `find / -name hdfs.keytab -printf “%T+\t%p\n” | sort|tail -1|cut -f 2` hdfs/`hostname`
Practical Tip: Debug kinit
To debug kinit, you should export Linux environment variable KRB5_TRACE=/dev/stdout. Here is an example:
$ kinit -kt /opt/kafka/security/testuser.keytab testuser@BDACLOUDSERVICE.ORACLE.COM
$ export KRB5_TRACE=/dev/stdout
$ kinit -kt /opt/kafka/security/testuser.keytab testuser@BDACLOUDSERVICE.ORACLE.COM
[88092] 1529001733.290407: Getting initial credentials for testuser@BDACLOUDSERVICE.ORACLE.COM
[88092] 1529001733.292692: Looked up etypes in keytab: aes256-cts, aes128-cts, des3-cbc-sha1, rc4-hmac, des-hmac-sha1, des, des-cbc-crc
[88092] 1529001733.292734: Sending request (230 bytes) to BDACLOUDSERVICE.ORACLE.COM
[88092] 1529001733.292863: Resolving hostname cfclbv3870.us2.oraclecloud.com
[88092] 1529001733.293130: Sending initial UDP request to dgram 10.196.64.44:88
[88092] 1529001733.293587: Received answer from dgram 10.196.64.44:88
[88092] 1529001733.293663: Response was not from master KDC
[88092] 1529001733.293732: Processing preauth types: 19
[88092] 1529001733.293773: Selected etype info: etype aes256-cts, salt “(null)”, params “”
[88092] 1529001733.293802: Produced preauth for next request: (empty)
[88092] 1529001733.293830: Salt derived from principal: BDACLOUDSERVICE.ORACLE.COMtestuser
[88092] 1529001733.293857: Getting AS key, salt “BDACLOUDSERVICE.ORACLE.COMtestuser”, params “”
[88092] 1529001733.293958: Retrieving testuser@BDACLOUDSERVICE.ORACLE.COM from FILE:/opt/kafka/security/testuser.keytab (vno 0, enctype aes256-cts) with result: 0/Success
[88092] 1529001733.294013: AS key obtained from gak_fct: aes256-cts/7606
[88092] 1529001733.294095: Decrypted AS reply; session key is: aes256-cts/D28B
[88092] 1529001733.294214: FAST negotiation: available
[88092] 1529001733.294264: Initializing FILE:/tmp/krb5cc_1001 with default princ testuser@BDACLOUDSERVICE.ORACLE.COM
[88092] 1529001733.294408: Removing testuser@BDACLOUDSERVICE.ORACLE.COM -> krbtgt/BDACLOUDSERVICE.ORACLE.COM@BDACLOUDSERVICE.ORACLE.COM from FILE:/tmp/krb5cc_1001
[88092] 1529001733.294450: Storing testuser@BDACLOUDSERVICE.ORACLE.COM -> krbtgt/BDACLOUDSERVICE.ORACLE.COM@BDACLOUDSERVICE.ORACLE.COM in FILE:/tmp/krb5cc_1001
[88092] 1529001733.294534: Storing config in FILE:/tmp/krb5cc_1001 for krbtgt/BDACLOUDSERVICE.ORACLE.COM@BDACLOUDSERVICE.ORACLE.COM: fast_avail: yes
[88092] 1529001733.294584: Removing testuser@BDACLOUDSERVICE.ORACLE.COM -> krb5_ccache_conf_data/fast_avail/krbtgt\/BDACLOUDSERVICE.ORACLE.COM\@BDACLOUDSERVICE.ORACLE.COM@X-CACHECONF: from FILE:/tmp/krb5cc_1001
[88092] 1529001733.294618: Storing testuser@BDACLOUDSERVICE.ORACLE.COM -> krb5_ccache_conf_data/fast_avail/krbtgt\/BDACLOUDSERVICE.ORACLE.COM\@BDACLOUDSERVICE.ORACLE.COM@X-CACHECONF: in FILE:/tm/krb5cc_1001
Practical Tip: Obtaining Kerberos Ticket without acsess to KDC
In my expirience it could be a cases when client machine could not acsess KDC directy, but need to work with Kerberos protected resources. Here is workaround for it. First go to machine which has acsess to KDC and generate cache ticket:
$ cp /etc/krb5.conf /tmp/TMP_TICKET_CACHE/krb5.conf
$ export KRB5_CONFIG=/tmp/TMP_TICKET_CACHE/krb5.conf
$ export KRB5CCNAME=DIR:/tmp/TMP_TICKET_CACHE/
$ kinit oracle
Password for oracle@BDACLOUDSERVICE.ORACLE.COM:
afilanov:ssh afilanov$ scp -i id_rsa_new.dat opc@cfclbv3872.us2.oraclecloud.com:/tmp/TMP_TICKET_CACHE/* /tmp/
Enter passphrase for key ‘id_rsa_new.dat’:
krb5.conf 100% 795 12.3KB/s 00:00
primary 100% 10 0.2KB/s 00:00
tkt0kVvY6 100% 874 13.6KB/s 00:00
afilanov:ssh afilanov$
rename ticket cache file and check that current user has it:
afilanov:ssh afilanov$ export KRB5_CONFIG=/tmp/krb5.conf
afilanov:ssh afilanov$ export KRB5CCNAME=/tmp/tkt0kVvY6
afilanov:ssh afilanov$ klist
Credentials cache: FILE:/tmp/tkt0kVvY6
Principal: oracle@BDACLOUDSERVICE.ORACLE.COM
Issued Expires Principal
Jun 18 09:33:10 2018 Jun 19 09:33:10 2018 krbtgt/BDACLOUDSERVICE.ORACLE.COM@BDACLOUDSERVICE.ORACLE.COM
afilanov:ssh afilanov$
Step1. Authentication in Hadoop. Integration MIT Kerberos with Active Directory
It is quite common that companies use the Active Directory server to manage users and groups and want to provide them access to the secure Hadoop cluster accordingly their roles and permissions. For example, I have my corporate login afilnov and I want to work with Hadoop cluster as afilanov.
For doing this you have to build trusted relationships between Active Directory and MIT KDC on BDA. All details you could find in the MOS: “How to Set up a Cross-Realm Trust to Configure a BDA MIT Kerberos Enabled Cluster with Active Directory on BDA V4.5 and Higher (Doc ID 2198152.1)”, but here I’ll show a quick example how it works.
First, I will log in to the Active Directory server and configure the trusted relationships with my BDA KDC:
C:\Users\Administrator> netdom trust ORALCE.TEST /Domain:BDA.COM /add /realm /passwordt:welcome1
C:\Users\Administrator> ksetup /SetEncTypeAttr ORALCE.TEST AES256-CTS-HMAC-SHA1-96
After this I’m going to create user in AD:
I skipped all explanations here because you may find all details in MOS and here I just wanted to show that I create a user on AD (not on Hadoop) side. On the KDC side you have to create one more principal as well:
# kadmin.local
Authenticating as principal hdfs/admin@ORALCE.TEST with password.
kadmin.local: addprinc -e “aes256-cts:normal” krbtgt/ORALCE.TEST@BDA.COM
# direction from MIT to AD
After this we are ready to use our corporate login/password to work with Hadoop on behalf of this user:
# kinit afilanov@BDA.COM
Password for afilanov@BDA.COM:
# hadoop fs -put file.txt /tmp/
# hadoop fs -ls /tmp/file.txt
-rw-r–r– 3 afilanov supergroup 5 2017-08-08 18:00 /tmp/file.txt
Step1. Authentication in Hadoop. SSSD integration
Well, now we can obtain a Kerberos ticket and work with Hadoop as a certain user. It’s important to note that on the OS we can be logged in as any user (e.g. we could be login as root and work with Hadoop cluster as a user from AD), here an example:
# kinit afilanov@BDA.COM
Password for afilanov@BDA.COM:
# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: afilanov@BDA.COM
Valid starting Expires Service principal
09/04/17 17:29:24 09/05/17 03:29:16 krbtgt/BDA.COM@BDA.COM
renew until 09/11/17 17:29:24
# id
uid=0(root) gid=0(root) groups=0(root) context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
Guidelines for Active Directory Organizational Unit Setup Required for BDA 4.9 and Higher SSSD Setup (Doc ID 2289768.1)
and
How to Set up an SSSD on BDA V4.9 and Higher (Doc ID 2298831.1)
After you pass all steps listed there you may use AD user/password for login to the Linux servers of your Hadoop cluster. Here is the example:
# id
uid=0(root) gid=0(root) groups=0(root) context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
# ssh afilanov@$(hostname)
afilanov@scajvm1bda01.vm.oracle.com’s password:
Last login: Fri Sep 1 20:16:37 2017 from scajvm1bda01.vm.oracle.com
$ id
uid=825201368(afilanov) gid=825200513(domain users) groups=825200513(domain users) context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
Step2. Authorization in Hadoop. Sentry
Another one powerful capability of Hadoop in the security field is role-based access for hive queries. In the Cloudera distribution, it is managed by Sentry. Kerberos is required for Sentry installation. As many things on Big Data Appliance installation of Sentry automated and could be done within one command:
# bdacli enable sentry
and follow the tools guide. More information you could find in MOS “How to Add or Remove Sentry on Oracle Big Data Appliance v4.2 or Higher with bdacli (Doc ID 2052733.1)”.
After you enable Sentry, you can now create and enable Sentry policies. I want to mention, that in Sentry there is strict hierarchy; users always belongs to groups, groups have some roles, and roles have some privileges. And, you have to follow this hierarchy. You can’t assign some privileges directly to the user or group.

I will show how to setup this policies with HUE. For this test case I’m going to create test data and load it in HDFS:
# echo “1, Finance, Bob,100000”>> emp.file
# echo “2, Marketing, John,70000”>> emp.file
# hadoop fs -mkdir /tmp/emp_table/; hadoop fs -put emp.file /tmp/emp_table/
After creating the file, I log in into Hive and create an external table (for power users) and view with a restricted set of the columns(for limited users):
hive> create external table emp(id int,division string, name string, salary int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’ location “/tmp/emp_table”;
hive> create view emp_limited as select division, name from emp;
After I have data in my cluster, I’m going to create test users across all nodes in the cluster (or, if I’m using AD – create the users/groups there):
# dcli -C “useradd limited_user”
# dcli -C “groupadd limited_grp”
# dcli -C “usermod -g limited_grp limited_user”
# dcli -C “useradd power_user”
# dcli -C “groupadd power_grp”
# dcli -C “usermod -g power_grp power_user”
Now, let’s use user-friendly HUE graphical interface. First, go to the Security bookmark and find that we have two objects and don’t have any security rules there:
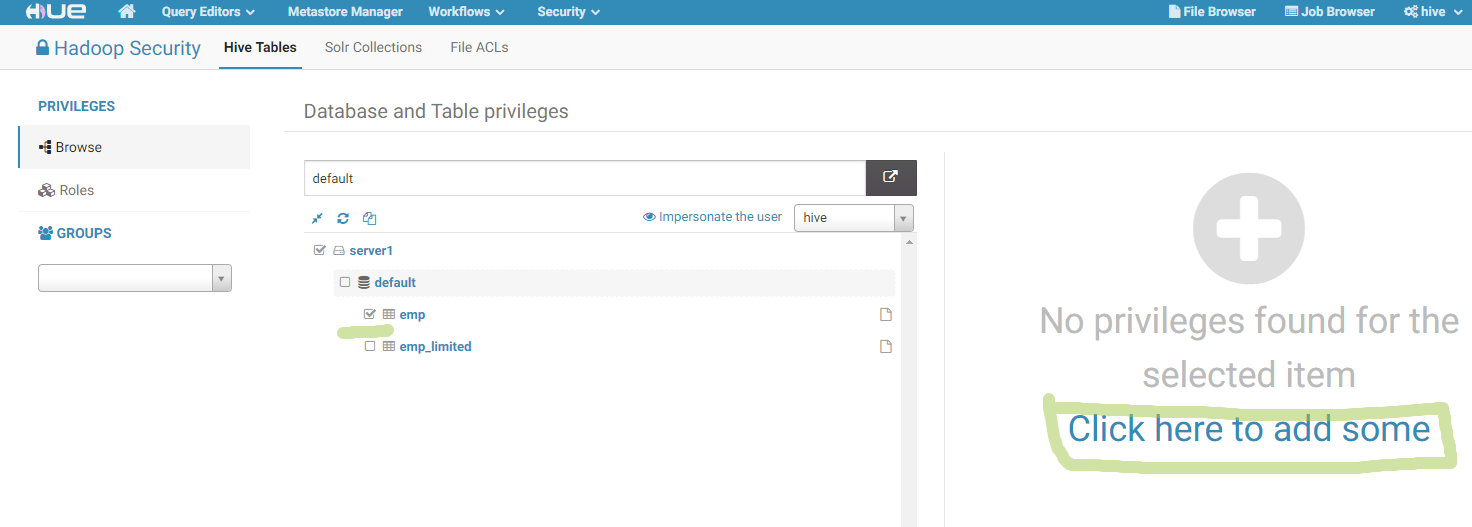
After this I clicked on the “Add policy” link and created policy for power user, which allows it to read the “emp” table:
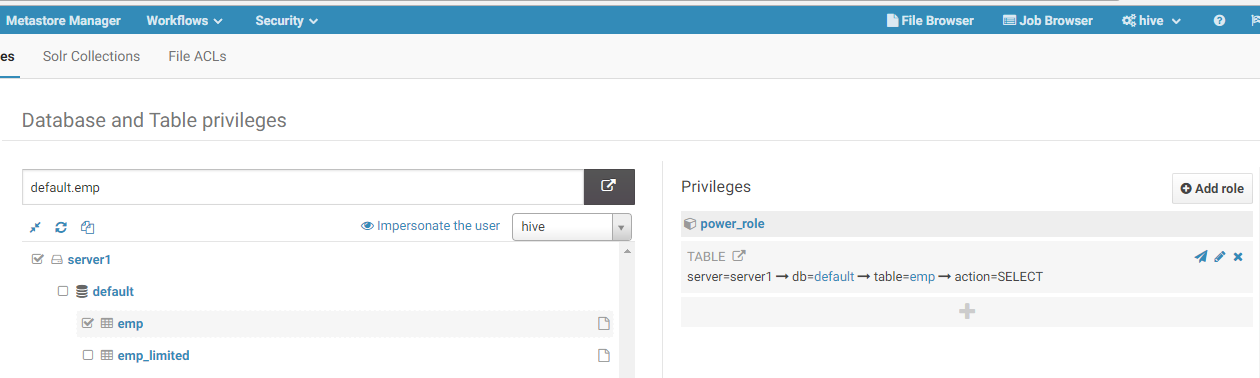
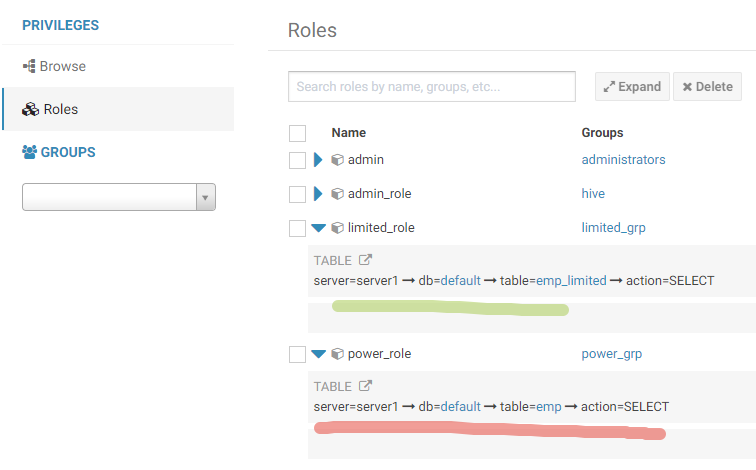
After this I did the same for limited_user, but allowed it to read only emp_limited view. Here is my roles with policies:
Now I log in as “limited_user” and ask to show the list of the tables:
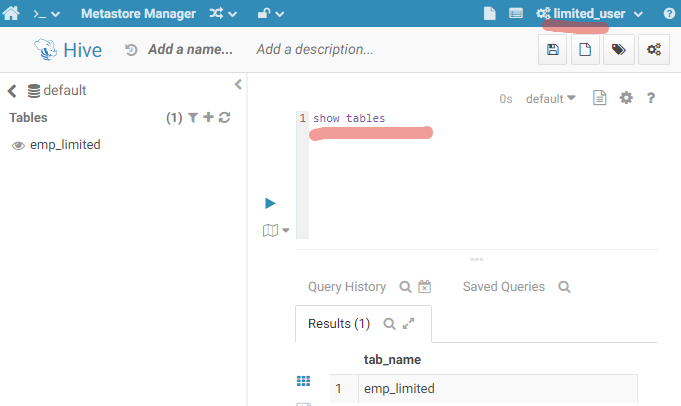
Only emp_limited is available. Let’s query it:
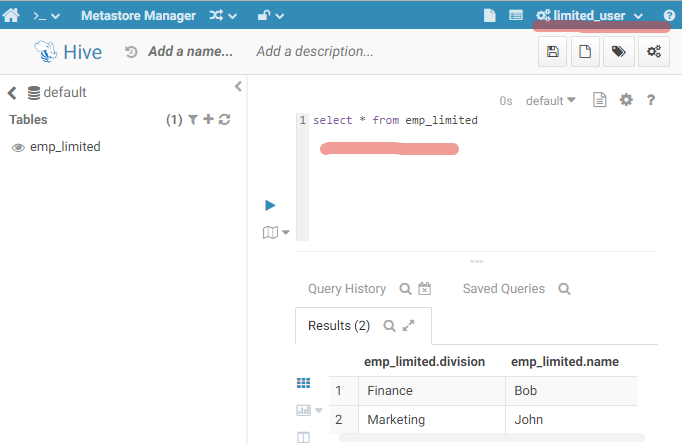
Perfect. I don’t have table “emp” in the list of my tables, but let’s imagine that I do know the name and want to query it.

My attempt failed, because of lack of priviliges.
This highlighted table level granularity, but Sentry allows you to restrict access to certain columns. I’m going to reconfig power_role and allow it to select all columns except “salary”:
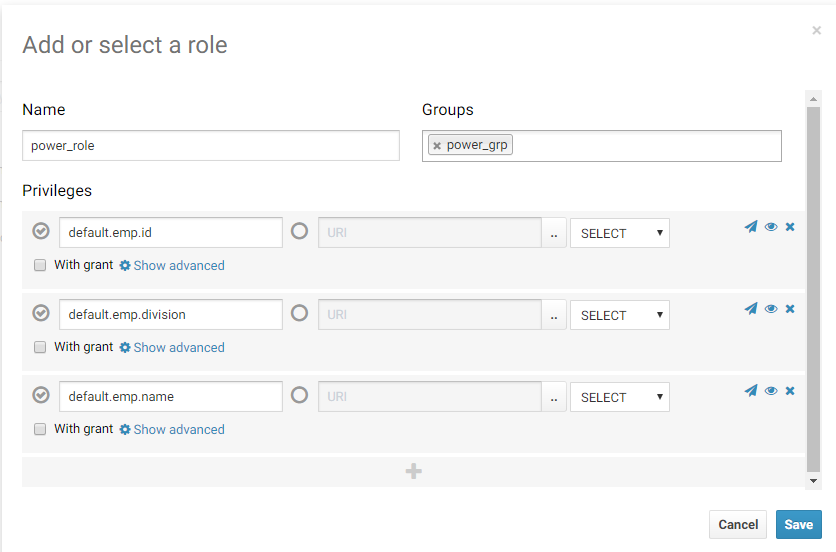
After this I running test queries with and without salary column in where predicate:
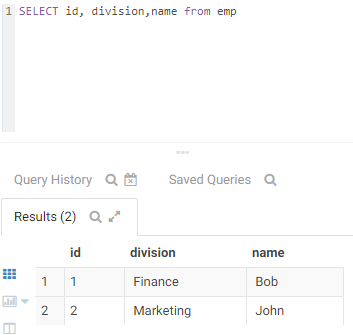
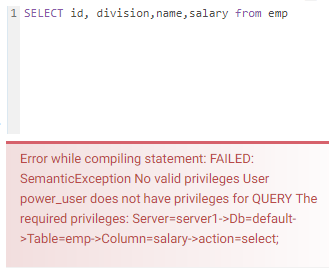
Here we go! If I list “salary” in the select statement my query fails because of lack of privileges.
Practical Tip: Useful Sentry commands
Alternatively, you may use beeline cli to view and manage sentry roles. Below, I’ll show how to manage privileges with beeline cli. First, I obtain a Kerberos ticket for the hive user and login into hive cli (“hive” is the admin) after this drop role and create it again. Assign to it some privileges and link this role with some group. After this login as limited_user, who belongs to limited_grp and check the permissions:
# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: hive/scajvm1bda04.vm.oracle.com@ORALCE.TEST
# beeline
beeline> !connect jdbc:hive2://scajvm1bda04.vm.oracle.com:10000/default;ssl=true;sslTrustStore=/opt/cloudera/security/jks/scajvm.truststore;trustStorePassword=Hh1SDy8wMyKpoz25vgIB7fMwjJkkaLtA6FR4SzW1bULVs9dKhgVNQwvaoRy1GVbN;principal=hive/scajvm1bda04.vm.oracle.com@ORALCE.TEST;
…
// Check which roles sentry has
0: jdbc:hive2://scajvm1bda04.vm.oracle.com:10> SHOW ROLES;
…
+—————+–+
| role |
+—————+–+
| limited_role |
| admin |
| power_role |
| admin_role |
+—————+–+
4 rows selected (0.146 seconds)
// Check which role has current session
jdbc:hive2://scajvm1bda04.vm.oracle.com:10> SHOW CURRENT ROLES;
…
+————-+–+
| role |
+————-+–+
| admin_role |
+————-+–+
// drop role
0: jdbc:hive2://scajvm1bda04.vm.oracle.com:10> drop role limited_role;
…
// create this role again
0: jdbc:hive2://scajvm1bda04.vm.oracle.com:10> create role limited_role;
…
// give a grant to the newly created role
0: jdbc:hive2://scajvm1bda04.vm.oracle.com:10> grant select on emp_limited to role limited_role;
…
// link role and the group
0: jdbc:hive2://scajvm1bda04.vm.oracle.com:10> grant role limited_role to group limited_grp;
…
0: jdbc:hive2://scajvm1bda04.vm.oracle.com:10> !exit
// obtain ticket for limited_user
# kinit limited_user
Password for limited_user@ORALCE.TEST:
# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: limited_user@ORALCE.TEST
// check groups for this user
# hdfs groups limited_user
limited_user : limited_grp
# beeline
…
beeline> !connect jdbc:hive2://scajvm1bda04.vm.oracle.com:10000/default;ssl=true;sslTrustStore=/opt/cloudera/security/jks/scajvm.truststore;trustStorePassword=Hh1SDy8wMyKpoz25vgIB7fMwjJkkaLtA6FR4SzW1bULVs9dKhgVNQwvaoRy1GVbN;principal=hive/scajvm1bda04.vm.oracle.com@ORALCE.TEST;
…
0: jdbc:hive2://scajvm1bda04.vm.oracle.com:10> show current roles;
…
+—————+–+
| role |
+—————+–+
| limited_role |
+—————+–+
// Check my privilegies
0: jdbc:hive2://scajvm1bda04.vm.oracle.com:10> show grant role limited_role;
+———–+————–+————+———+—————–+—————–+————+—————+——————-+———-+–+
| database | table | partition | column | principal_name | principal_type | privilege | grant_option | grant_time | grantor |
+———–+————–+————+———+—————–+—————–+————+—————+——————-+———-+–+
| default | emp_limited | | | limited_role | ROLE | select | false | 1502250173482000 | — |
+———–+————–+————+———+—————–+—————–+————+—————+——————-+———-+–+
// try to select table which I’ve not permied to query
0: jdbc:hive2://scajvm1bda04.vm.oracle.com:10> select * from emp;
Error: Error while compiling statement: FAILED: SemanticException No valid privileges
User limited_user does not have privileges for QUERY
The required privileges: Server=server1->Db=default->Table=emp->Column=division->action=select; (state=42000,code=40000)
// select query which we allowed to query
0: jdbc:hive2://scajvm1bda04.vm.oracle.com:10> select * from emp_limited;
…
+———————–+——————-+–+
| emp_limited.division | emp_limited.name |
+———————–+——————-+–+
| Finance | Bob |
| Marketing | John |
+———————–+——————-+–+
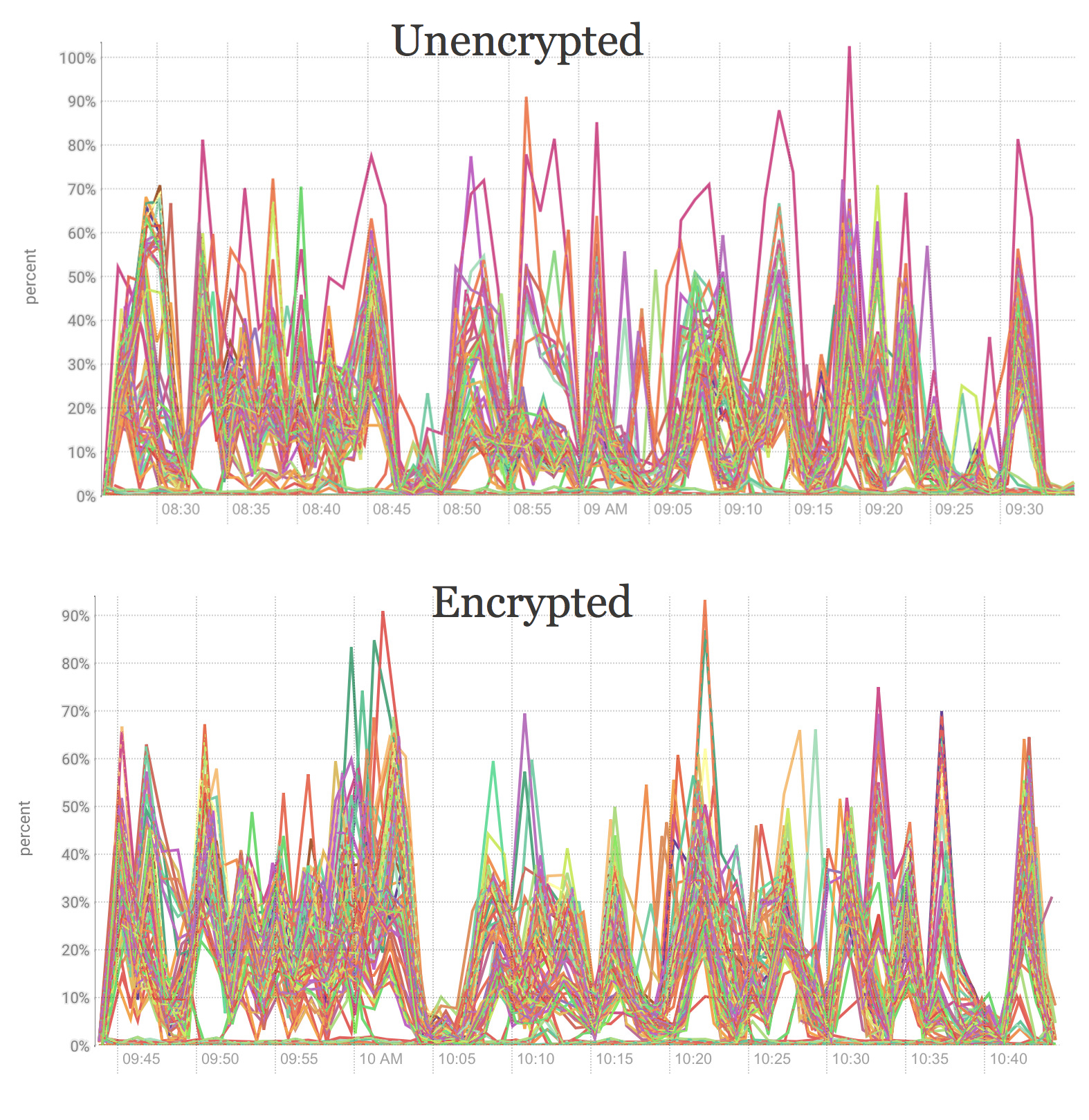
Another important aspect of security is network encryption. For example, even if you protect access to the servers, somebody may listen to the network between the cluster and client and intercept network packets for future analysis.
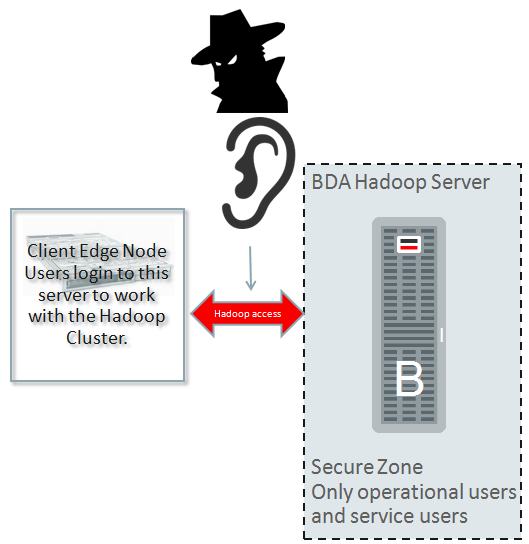
Here is an example how it could be hacked (note: my cluster already Kerberized).
Intruder server:
# tcpdump -XX -i eth3 > tcpdump.file
————————————
Client machine
# echo “encrypt your data” > test.file
# hadoop fs -put test.file /tmp/
————————————
Intruder server:
# less tcpdump.file |grep -B 1 data
0x0060: 0034 ff48 2a65 6e63 7279 7074 2079 6f75 .4.H*encrypt.you
0x0070: 7220 6461 7461 0a r.data.
# hadoop jar hadoop-mapreduce-examples.jar teragen 100000000 /teraInput
…
# hadoop jar hadoop-mapreduce-examples.jar terasort /teraInput /teraOutput
…
Both jobs took 3.7 minutes. Remember it for now. Fortunately, Oracle Big Data Appliance provides an easy way for enabling network encryption with bdacli. You can set it up it with one command:
# bdacli enable hdfs_encrypted_data_transport
…
You will need to answer some questions about your specific cluster configs, such as Cloudera Manager admin password and OS passwords. After finishing the command, I ran performance test again:
# hadoop jar hadoop-mapreduce-examples.jar teragen 100000000 /teraInput
…
# hadoop jar hadoop-mapreduce-examples.jar terasort /teraInput /teraOutput
…
and now I took 4.5 and 4.2 minutes respectively. The jobs perform a bit more slowly, but it is worth it.
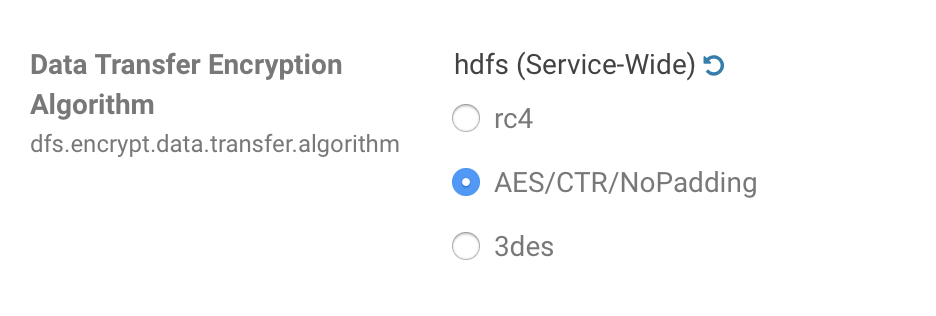
For improved performance of transferring encrypted data, we may use an advantage of Intel embedded instructions and change encryption algorithm (go to Cloudera Manager -> HDFS -> Configuration -> dfs.encrypt.data.transfer.algorithm -> AES/CTR/NoPadding):
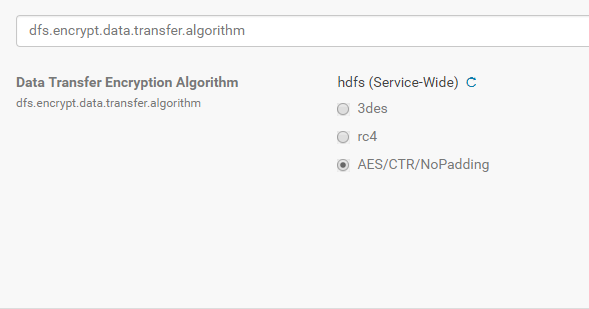

Another vulnerability is network interception during the shuffle (step between Map and Reduce operation) and communication between clients. To prevent this vulnerability, you have to encrypt shuffle traffic. BDA again has an easy solution: run bdacli enable hadoop_network_encryption command.
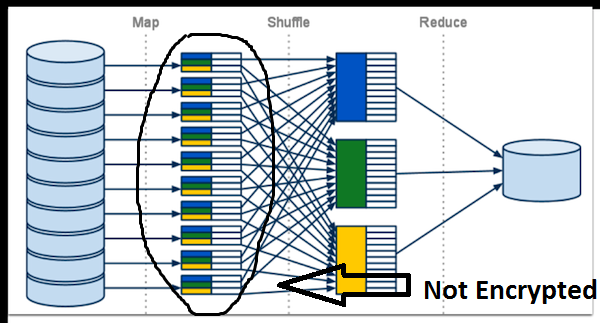
Now we will encrypt intermediate files, generated after shuffle step:
# bdacli enable hadoop_network_encryption
…
Like in the previous example, simply answer a few questions the encryption will be enabled. Let’s check performance numbers again:
# hadoop jar hadoop-mapreduce-examples.jar teragen 100000000 /teraInput
…
# hadoop jar hadoop-mapreduce-examples.jar terasort /teraInput /teraOutput
…
we have 5.1 minute and 4.4 minutes respectively. A bit slower, but it is important in order to keep data safe.
Conclusion:
- Network encryption prevents intruders from capturing data in flight
- Network encryption degrades your overall performance. However, this degradation shouldn’t stop you from enabling it because it’s very important from a security perspective
Step4. Encryption at Rest. HDFS transparent encryption
All right, now we protected the cluster from external unauthorized access (by enabling Kerberos), encrypted network communication between the cluster and clients, encrypted intermediate files, but we still have vulnerabilities. If a user gets access to the cluster’s server, he or she could read the data (despite on ACL). Let me give you an example.
Some ordinary user put sensitive information in the file and put it on HDFS:
# echo “sensetive information here” > test.file
# hadoop fs -put test.file /tmp/test.file
Intruder knows the file name and wants to get the content of it (sensitive information)
# hdfs fsck /tmp/test.file -locations -files -blocks
…
0. BP-421546782-192.168.254.66-1501133071977:blk_1073747034_6210 len=27 Live_repl=3 …
# find / -name “blk_1073747034*”
/u02/hadoop/dfs/current/BP-421546782-192.168.254.66-1501133071977/current/finalized/subdir0/subdir20/blk_1073747034_6210.meta
/u02/hadoop/dfs/current/BP-421546782-192.168.254.66-1501133071977/current/finalized/subdir0/subdir20/blk_1073747034
# cat /u02/hadoop/dfs/current/BP-421546782-192.168.254.66-1501133071977/current/finalized/subdir0/subdir20/blk_1073747034
sensetive information here
The hacker found the blocks that store the data and then reviewed the physical files at the OS level. It was so easy to do. What can you do to prevent this? The answer is to use HDFS encryption.
Again, BDA has a single command to do enable HDFS transparent encryption: bdacli enable hdfs_transparent_encryption. You may find more details in MOS “How to Enable/Disable HDFS Transparent Encryption on Oracle Big Data Appliance V4.4 with bdacli (Doc ID 2111343.1)”.
I’d like to note, that Cloudera has great blogpost about HDFS transparent encryption and I would recommend you to read it. So, after encryption had been enabled, I’ll repeat my previous test case. Prior to running the test, we will create an encryption zone and copy files into that zone.
// obtain hdfs kerberos ticket for working with cluster on behalf of hdfs user
# kinit -kt `find / -name hdfs.keytab -printf “%T+\t%p\n” | sort|tail -1|cut -f 2` hdfs/`hostname`
// create directory, which will be our security zone in future
# hadoop fs -mkdir /tmp/EZ/
// create key in Key Trustee Server
# hadoop key create myKey
// create encrypted zone, using key created earlier
# hdfs crypto -createZone -keyName myKey -path /tmp/EZ
// make Oracle owner of this directory
# hadoop fs -chown oracle:oracle /tmp/EZ
// Switch user to oracle
# kinit -kt oracle.scajvm1bda01.vm.oracle.com.keytab oracle/scajvm1bda01.vm.oracle.com
// Load file in encrypted zone
# hadoop fs -put test.file /tmp/EZ/
// define physical location of the file on the Linus FS
# hadoop fsck /tmp/EZ/test.file -blocks -files -locations
…
0. BP-421546782-192.168.254.66-1501133071977:blk_1073747527_6703
…
[root@scajvm1bda01 ~]# find / -name blk_1073747527*
/u02/hadoop/dfs/current/BP-421546782-192.168.254.66-1501133071977/current/finalized/subdir0/subdir22/blk_1073747527_6703.meta
/u02/hadoop/dfs/current/BP-421546782-192.168.254.66-1501133071977/current/finalized/subdir0/subdir22/blk_1073747527
// trying to read the file
[root@scajvm1bda01 ~]# cat /u02/hadoop/dfs/current/BP-421546782-192.168.254.66-1501133071977/current/finalized/subdir0/subdir22/blk_1073747527
▒i#▒▒C▒x▒1▒U▒l▒▒▒[
Bingo! The file is encrypted and the person who attempted to access the data can only see a series of nonsensical bytes.
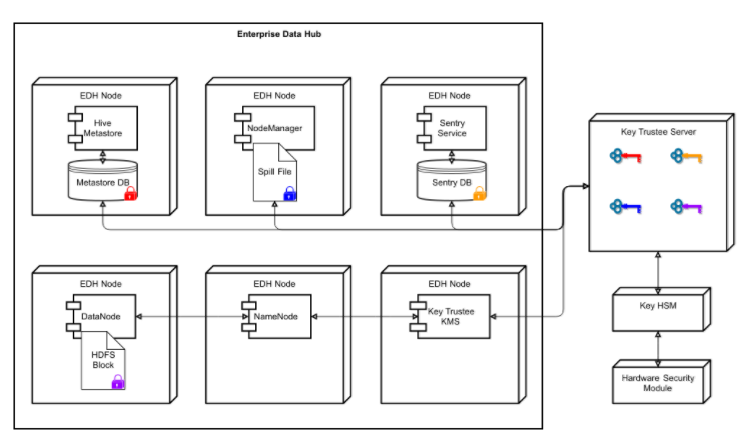
Now let me tell couple words how encryption works. There are a few types of keys (screenshots I took from Cloudera’s blog):
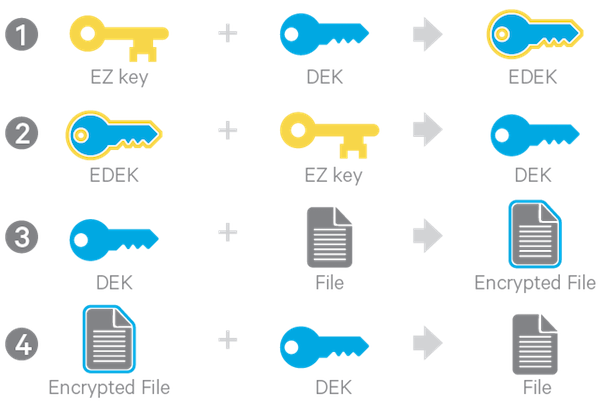
1) Encryption Zone key. You may encrypt files in a certain directory using some unique key. This directory called Encryption Zone (EZ) and a key called EZ key. This approach maybe quite useful, when you share Hadoop cluster among different divisions within the same company. This key stored in KMS (Key Managment Server). KMS handles generating encryption keys (EZ and DEK), also it communicates with key server and decrypts EDEK.
2) Encrypted data encryption keys (EDEK) is an attribute of the files, which stored in Name Node.
3) DEK is not persistent, you compute it on the fly from EDEK and EZ.
Here is the flow of how to client write data to the encrypted HDFS.
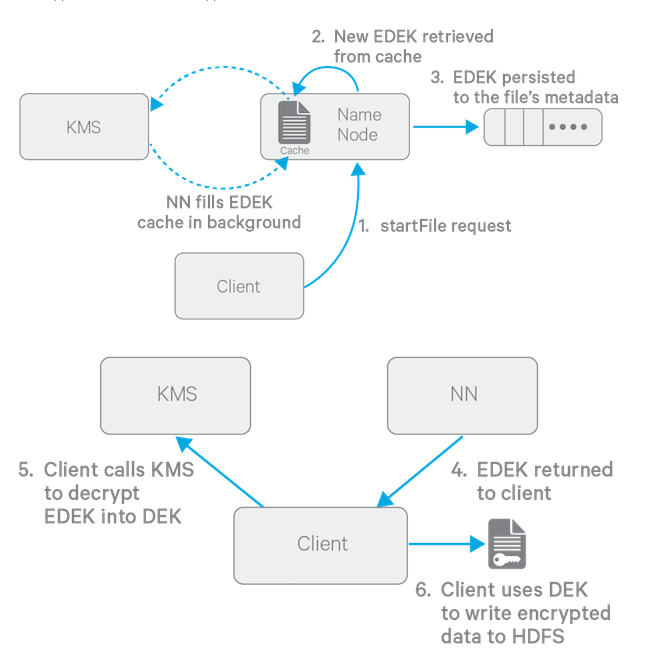
I took the explanation of this from Hadoop Security book:
1) The HDFS client calls create() to write to the new file.
2) The NameNode requests the KMS to create a new EDEK using the EZK-id/version.
3) The KMS generates a new DEK.
4) The KMS retrieves the EZK from the key server.
5) The KMS encrypts the DEK, resulting in the EDEK.
6) The KMS provides the EDEK to the NameNode.
7) The NameNode persists the EDEK as an extended attribute for the file metadata.
8) The NameNode provides the EDEK to the HDFS client.
9) The HDFS client provides the EDEK to the KMS, requesting the DEK.
10) The KMS requests the EZK from the key server.
11) The KMS decrypts the EDEK using the EZK.
12) The KMS provides the DEK to the HDFS client.
13) The HDFS client encrypts data using the DEK.
14) The HDFS client writes the encrypted data blocks to HDFS
for data reading you will follow this steps:
1) The HDFS client calls open() to read a file.
2) The NameNode provides the EDEK to the client.
3) The HDFS client passes the EDEK and EZK-id/version to the KMS.
4) The KMS requests the EZK from the key server.
5) The KMS decrypts the EDEK using the EZK.
6) The KMS provides the DEK to the HDFS client.
7) The HDFS client reads the encrypted data blocks, decrypting them with the DEK.
I’d like to highlight again, that all these steps are completely transparent and the end user doesn’t feel any difference while working with HDFS.
Tip: Key Trustee Server and Key Trustee KMS
For those of you who are just starting to work with HDFS data encryption – the terms Key Trustee Server and KMS maybe a bit confusing. Which component do you need to use and for what purpose? From Cloudera’s documentation:
Key Trustee Server is an enterprise-grade virtual safe-deposit box that stores and manages cryptographic keys. With Key Trustee Server, encryption keys are separated from the encrypted data, ensuring that sensitive data is protected in the event that unauthorized users gain access to the storage media.
Key Trustee KMS – for HDFS Transparent Encryption, Cloudera provides Key Trustee KMS, a customized Key Management Server. The KMS service is a proxy that interfaces with a backing key store on behalf of HDFS daemons and clients. Both the backing key store and the KMS implement the Hadoop KeyProvider client API. Encryption and decryption of EDEKs happen entirely on the KMS. More importantly, the client requesting creation or decryption of an EDEK never handles the EDEK’s encryption key (that is, the encryption zone key).
This picture (again from cloudera’s documentation) shows that KMS is intermediate service in between Name Node and Key Trustee Server:
Practical Tip: HDFS transparent encryption Linux operations
// For get list of the keys you may use:
# hadoop key list
Listing keys for KeyProvider: org.apache.hadoop.crypto.key.kms.LoadBalancingKMSClientProvider@5386659f
myKey
//For get list of encryprion zones use:
# hdfs crypto -listZones
/tmp/EZ myKey
// For encrypt existing data you need to copy it:
# hadoop distcp /user/dir /encryption_zone
Step5. Audit. Cloudera Navigator
Auditing tracks who does what on the cluster – making it easy to identify improper attempts to access. Fortunately, Cloudera provides easy and efficient way to do so, it’s called Cloudera Navigator.
Cloudera Navigator is included with BDA and Big Data Cloud Service. It is accessible thru Cloudera Manager:
After this you may use “admin” password from Cloudera Manager. After logon you may choose “Audit” section.
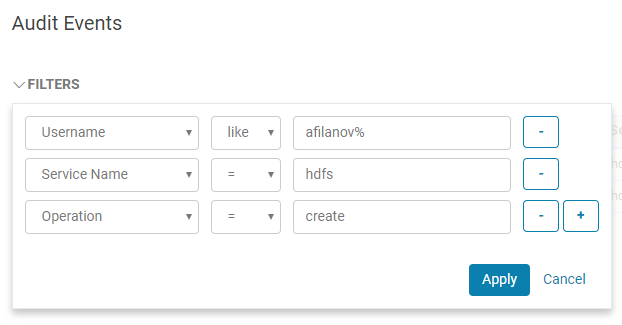
Where you may create different Audit reports. Like “which files user afilanov created on HDFS for a last hour”:

Step6. User management and tools in Hadoop. Group Mapping
HDFS is filesystem and as we discussed earlier it has ACL for managing file permissions.
As you know those three magic numbers define access rules for owner-group-others. But how to understand which group belong my user? There are two types of user group lookup – LDAP based and UnixShell based. In Cloudera Manager it defined through hadoop.security.group.mapping parameter:

for check a list of the groups for certain user from Linux console, just run:
$ hdfs groups hive
hive : hive oinstall hadoop
Step6. User management and tools in Hadoop. Connect to the hive from the bash console
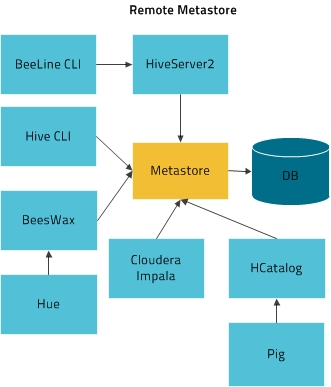
The two most common ways of connecting to the hive from the shell are the 1) hive cli and 2) beeline. The first is deprecated as it bypasses the security in HiveServer2; it communicates directly with the metastore. Therefore, beeline is the recommended; it communicates with HiveServer2 – enabling authorization rules to engage.
Hive cli tool is big back door for the security and it’s highly recommended to disable it. To accomplish this, you need to configure hive properly. You may use hadoop.proxyuser.hive.groups parameter to allow only the users belong to the group specified in the proxy list to connect to the metastore (the application components) and as consequence, a user that does not belong to these group and run the hive cli will not connect to the metastore. Go to the Cloudera Manager -> Hive -> Configuration -> in search bar type “hadoop.proxyuser.hive.groups” and add hive, Impala and hue users:
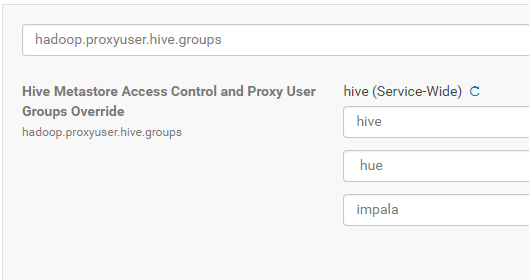
Restart hive server. You will be able to connect to the hive cli only as a privileged user (belongs to hive, hue, Impala groups).
# kinit -kt hive.keytab hive/scajvm1bda04.vm.oracle.com
# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: hive/scajvm1bda04.vm.oracle.com@ORALCE.TEST
…
# hive
…
hive> show tables;
OK
emp
emp_limited
Time taken: 1.045 seconds, Fetched: 2 row(s)
hive> exit;
# kinit afilanov@BDA.COM
Password for afilanov@BDA.COM:
# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: afilanov@BDA.COM
…
# hive
…
hive> show tables;
FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.transport.TTransportException: java.net.SocketException: Connection reset
hive>
Great, now we locked old hive cli and now it’s a good time to use new modern beeline console. So, for running beeline, you need to invoke beeline from cli and put following connection string:
beeline> !connect jdbc:hive2://<FQDN to HS2>:10000/default;principal=hive/<FQDN to HS2>@<YOUR REALM>;
For example:
# beeline
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Beeline version 1.1.0-cdh5.11.1 by Apache Hive
beeline> !connect jdbc:hive2://scajvm1bda04.vm.oracle.com:10000/default;principal=hive/scajvm1bda04.vm.oracle.com@ORALCE.TEST;
Note: before the connect to beeline you must obtain the Kerberos ticket that is used to confirm your identity.
# kinit afilanov@BDA.COM
Password for afilanov@BDA.COM:
# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: afilanov@BDA.COM
Valid starting Expires Service principal
08/14/17 04:53:27 08/14/17 14:53:17 krbtgt/BDA.COM@BDA.COM
renew until 08/21/17 04:53:27
Note, that you may have SSL/TLS encryption (Oracle recommends to have it). You may check it, by running:
$ openssl s_client -debug -connect node03.us2.oraclecloud.com:10000
if you don’t have TLS/SSL encryption for Hive, you could enable it, by running:
[root@node01 ~]# bdacli enable hadoop_network_encryption
If you enable hive TLS/SSL encryption (for ensuring integrity and confidence between your client and server connection) you need to use quite a tricky authentification with beeline. You have to use SSL Trust Store file and trust Store Password. When a client connects to a server and that server sends a public certificate across to the client to begin the encrypted connection the client must determine if it ‘trusts’ the server’s certificate. In order to do this, it checks the server’s certificate against a list of things it’s been configured to trust called a trust store
You may find it with Cloudera Manager REST API:
# curl -X GET -u “admin:admin1” -k -i https://<Cloudera Manager Host>:7183/api/v15/cm/config
…
“name” : “TRUSTSTORE_PASSWORD”,
“value” : “Hh1SDy8wMyKpoz25vgIB7fMwjJkkaLtA6FR4SzW1bULVs9dKhgVNQwvaoRy1GVbN”
},{
“name” : “TRUSTSTORE_PATH”,
“value” : “/opt/cloudera/security/jks/scajvm.truststore”
}
Alternatively, you may use bdacli tool on BDA:
# bdacli getinfo cluster_https_truststore_password
# bdacli getinfo cluster_https_truststore_path
Now you know trustee password and trrustee path. If you doubt that it matches, you could try to take a look on the trustore file content:
afilanov-mac:~ afilanov$ keytool -list -keystore testbdcs.truststore
Enter keystore password:
Keystore type: JKS
Keystore provider: SUN
Your keystore contains 5 entries
cfclbv3874.us2.oraclecloud.com, Apr 13, 2018, trustedCertEntry,
Certificate fingerprint (SHA1): F0:5D:28:36:99:67:FB:C0:B1:D5:B3:75:DF:D6:51:9B:DF:EB:3E:3A
cfclbv3871.us2.oraclecloud.com, Apr 13, 2018, trustedCertEntry,
Certificate fingerprint (SHA1): AF:3A:20:90:04:0A:27:B5:BD:DF:83:32:C7:4A:AF:AF:C4:97:E1:30
cfclbv3873.us2.oraclecloud.com, Apr 13, 2018, trustedCertEntry,
Certificate fingerprint (SHA1): 30:09:B9:A8:79:D7:F4:02:3F:72:8C:05:F1:A4:BF:04:9B:8B:78:CA
cfclbv3870.us2.oraclecloud.com, Apr 13, 2018, trustedCertEntry,
Certificate fingerprint (SHA1): EA:F0:38:1E:BB:89:E2:05:38:CA:F2:FB:4D:41:82:75:BE:5D:F7:88
cfclbv3872.us2.oraclecloud.com, Apr 13, 2018, trustedCertEntry,
Certificate fingerprint (SHA1): C5:7D:F2:FA:96:8C:AB:4A:D2:03:02:DA:D3:F5:0C:7C:45:8E:26:E7
# beeline
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Beeline version 1.1.0-cdh5.11.1 by Apache Hive
beeline> !connect jdbc:hive2://scajvm1bda04.vm.oracle.com:10000/default;ssl=true;sslTrustStore=/opt/cloudera/security/jks/scajvm.truststore;trustStorePassword=Hh1SDy8wMyKpoz25vgIB7fMwjJkkaLtA6FR4SzW1bULVs9dKhgVNQwvaoRy1GVbN;principal=hive/scajvm1bda04.vm.oracle.com@ORALCE.TEST;
Please note, that trustore is the public key and it’s not a big secret; it generally is not a problem to use it in scripts and share. Also, alternatively, if you don’t want to use so long connection string all the time, you could just put truststore credentials in Linux environment:
# export HADOOP_OPTS=”-Djavax.net.ssl.trustStore=/opt/cloudera/security/jks/scajvm.truststore -Djavax.net.ssl.trustStorePassword=Hh1SDy8wMyKpoz25vgIB7fMwjJkkaLtA6FR4SzW1bULVs9dKhgVNQwvaoRy1GVbN”
# beeline
…
beeline> !connect jdbc:hive2://scajvm1bda04.vm.oracle.com:10000/default;ssl=true;principal=hive/scajvm1bda04.vm.oracle.com@ORALCE.TEST;
you may also automate all steps above by scripting them:
$ cat beeline.login
#!/bin/bash
export CMUSR=admin
export CMPWD=admin_password
tspass=`bdacli getinfo cluster_https_truststore_password`
tspath=`bdacli getinfo cluster_https_truststore_path`
domain=`bdacli getinfo cluster_domain_name`
realm=`bdacli getinfo cluster_kerberos_realm`
hivenode=`json-select –jpx=HIVE_NODE /opt/oracle/bda/install/state/config.json`
set +o histexpand
echo “!connect jdbc:hive2://$hivenode:10000/default;ssl=true;sslTrustStore=$tspath;trustStorePassword=$tspass;principal=hive/$hivenode@$realm”
beeline -u “jdbc:hive2://$hivenode:10000/default;ssl=true;sslTrustStore=$tspath;trustStorePassword=$tspass;principal=hive/$hivenode@$realm”
$ ./beeline.login
Note: if you are using HiveServer2 balancer, you should specify host with the balancer as principal.
Step6. User management and tools in Hadoop. HUE and LDAP authentification.
One more interesting thing which you could do with your Active Directory (or any other LDAP implementation) is integrate HUE and LDAP and use LDAP passwords for authenticate your users in HUE.
Before doing this you have to enable TLSv1 in your Java settings on the HUE server. Here is detailed MOS note how to do this.
Search: Disables TLSv1 by Default For Cloudera Manager/Hue/And in System-Wide Java Configurations (Doc ID 2250841.1)
After this, you may want to watch these youtube videos to understand how easy is to do this integration.
Authenticate Hue with LDAP and Search Bind or Authenticate Hue with LDAP and Direct Bind. It’s really not too hard. Potentially, you may need to define your base_dn and here is the good article about how to do this. Next you may need the bind user for make the first connection and import all other users (here is the explanation from Cloudera Manager: Distinguished name of the user to bind as. This is used to connect to LDAP/AD for searching user and group information. This may be left blank if the LDAP server supports anonymous binds.). For this purposes I used my AD account afilanov.
After this I have to login to the HUE using afilanov login/password:
Then click on the user name and choose “Manage Users”.
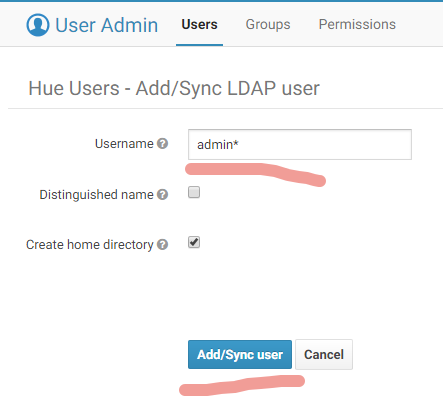
Add/Sync LDAP users:

Optionally, you may put the Username pattern and click Sync:
Here we go! Now we have list of the LDAP users imported into HUE:
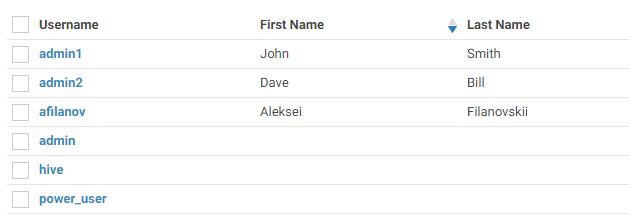
and now we could use any of this accounts to log in into HUE:
Appendix A. Performance impact of HDFS Transparent Encryption.
As we all saw in this post HDFS transparent encryption is the good way to protect your data. But Many you users, remembering that nothing is free, are curious, how expensive it is. Let’s make a test and after enabling HDFS transparent encryption, run the test case to measure performance degradation.
First of all we will need to create encrypted Zone (as HDFS user):
# kinit -kt `find / -name hdfs.keytab -printf “%T+\t%p\n” | sort|tail -1|cut -f 2` hdfs/`hostname`
# hadoop key create myKey
# hadoop fs -mkdir /tmp/EZ/
# hdfs crypto -createZone -keyName myKey -path /tmp/EZ/
# hadoop fs -chown oracle:oracle /tmp/EZ
# hadoop distcp -m 200 -skipcrccheck -update /user/hive/warehouse/parq.db /tmp/EZ/parq_encrypted.db
#!/bin/bash
rm -f tableNames.txt
rm -f HiveTableDDL.txt
hive -e “use $1; show tables;” > tableNames.txt
wait
cat tableNames.txt |while read LINE
do
hive -e “use $1;show create table $LINE” >>HiveTableDDL.txt
echo -e “\n” >> HiveTableDDL.txt
done
rm -f tableNames.txt
echo “Table DDL generated”
# cat export_hive.sh
#!/bin/bash
EXPORT_DIR=/tmp/export
EXPORT_DB=parq
HiveTables=$(hive -e “use $EXPORT_DB;show tables;” 2>/dev/null | egrep -v “WARN|^$|^Logging|^OK|^Time\ taken”)
hdfs dfs -mkdir -p $EXPORT_DB 2>/dev/null
for Table in $HiveTables
do
hive -e “EXPORT TABLE $EXPORT_DB.$Table TO ‘$EXPORT_DIR/$EXPORT_DB.db/$Table’;”
done
# cat import_hive.sh
#!/bin/bash
EXPORT_DIR=/tmp/export
IMPORT_DIR=/tmp/EZ
EXPORT_DB=parq
IMPORT_DB=parq_encrypted
HDFS_NAMESPACE=hdfs://lab-bda-ns
HiveTables=$(hive -e “use $EXPORT_DB;show tables;” 2>/dev/null | egrep -v “WARN|^$|^Logging|^OK|^Time\ taken”)
hdfs dfs -mkdir -p $EXPORT_DB 2>/dev/null
for Table in $HiveTables
do
echo “IMPORT EXTERNAL TABLE $IMPORT_DB.$Table from ‘$HDFS_NAMESPACE$EXPORT_DIR/$EXPORT_DB.db/$Table’ LOCATION ‘$HDFS_NAMESPACE$IMPORT_DIR/$IMPORT_DB.db/$Table’;”
hive -e “IMPORT EXTERNAL TABLE $IMPORT_DB.$Table from ‘$HDFS_NAMESPACE$EXPORT_DIR/$EXPORT_DB.db/$Table’ LOCATION ‘$HDFS_NAMESPACE$IMPORT_DIR/$IMPORT_DB.db/$Table’;”
done
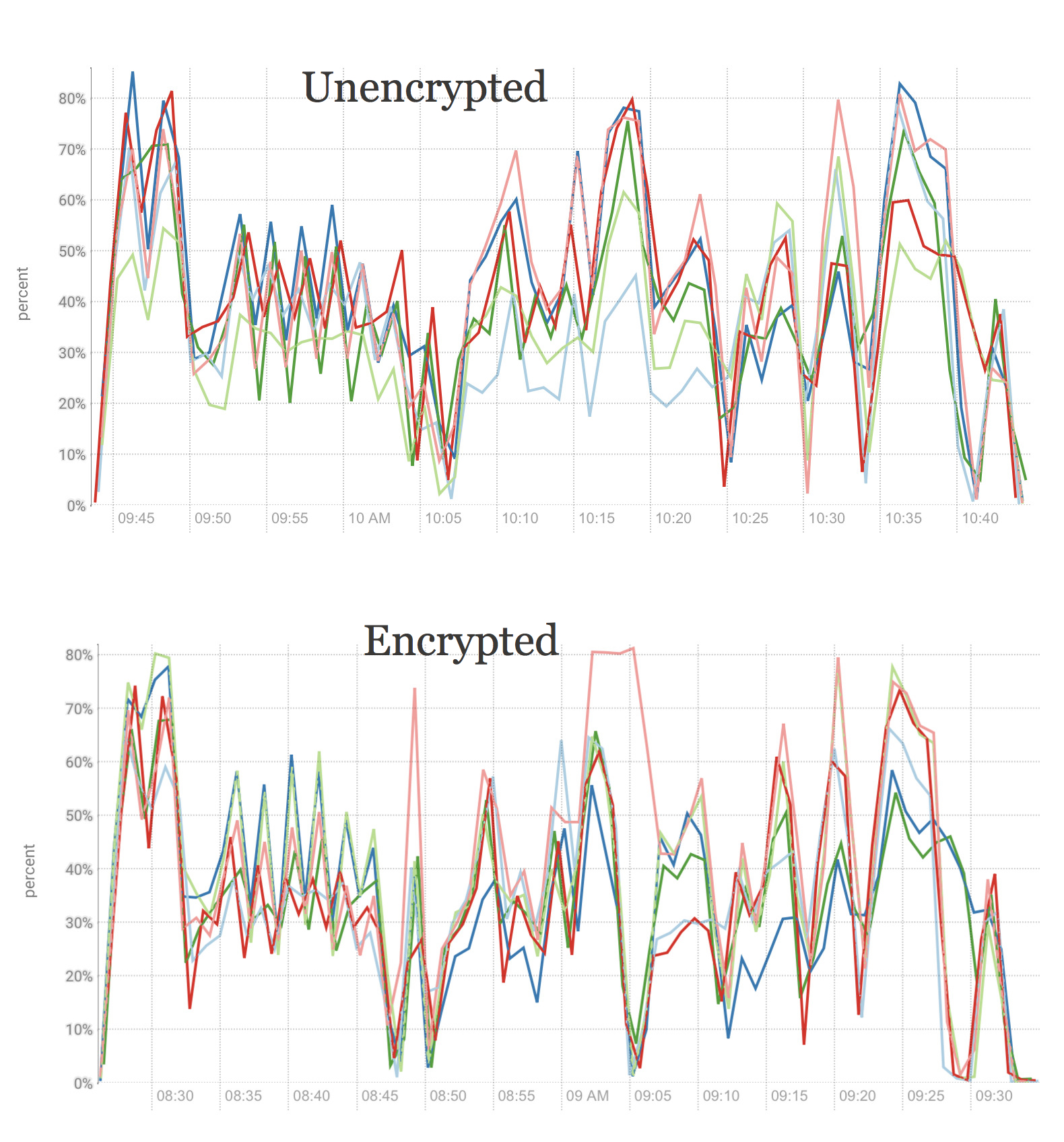
1) Have mammoth install the Key Trustee servers on the BDA cluster and manage
How to Enable HDFS Transparent Encryption with Key Trustee Servers Set Up on the BDA on Oracle Big Data Appliance V4.5 and Higher with bdacli (Doc ID 2166648.1)
2) Have the customer install the Key Trustee servers on his own servers and configure mammoth to point to them
How to Enable HDFS Transparent Encryption with Key Trustee Servers Set Up off the BDA on Oracle Big Data Appliance V4.4 and Higher with bdacli (Doc ID 2111343.1)
Both ways are fully supported but the second method offers a higher level of security (because the keys are stored on different servers from HDFS) and so we recommend the second method.
