Partitioning is a well-established technique to improve the performance and manageability of database systems by dividing large objects into smaller partitions; any large data warehouse takes advantage of it. This is true for large objects inside the database and objects outside the database, such as data lakes in Object Stores. Oracle introduced partitioned external tables in 18c, and we keep innovating in this area.
In this blog post, I will introduce you to one of the latest great innovations that just rolled out in Autonomous Database, which makes the management of your partitioned tables a breeze.
The traditional way of creating a partitioned external table
Oracle Autonomous Database allows the creation of partitioned external tables through the DBMS_CLOUD API for quite some time. This API simplifies the definition of the external table structure, but it relies on you to provide a lot of table metadata yourself. For example, you have to:
- Specify the list of all columns with datatypes, even for self-describing file formats (such as Parquet, Avro, or ORC).
- Explicitly list all partitions used in this table. For example, in the case when your dataset spans three years and is partitioned by day, you will have more than 1000 partitions, translating into more than 1000 lines of code to define your external table.
- Maintain table definition. If some new data – equivalent to partitions – is added or removed to/from Object Store, your table must be manually adjusted using ADD or DROP PARTITION.
- Value of partitioned column(s) is not in a query results
Let’s just have a quick look at what all of this means for a relatively small partitioned table with an example.
A bunch of sales data-related files landed in my object store, ready for me to analyze in my Autonomous Database. The data is transactional in nature and represents my sales for two years. Let’s see what files I got:
define uri_root = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample' SELECT OBJECT_NAME, BYTES FROM DBMS_CLOUD.LIST_OBJECTS(CREDENTIAL_NAME => 'CRED_OCI', LOCATION_URI => '&uri_root/');

…

It looks like there are 24 files for me to analyze. The data is divided into 24 files, each representing a month’s worth of data. Let’s create a monthly partitioned external table on top of these files, using the traditional DBMS_CLOUD interface:
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_PART_TABLE(
TABLE_NAME => 'sales_old_api',
CREDENTIAL_NAME => 'CRED_OCI',
COLUMN_LIST => '
DAY_ID TIMESTAMP,
GENRE_ID NUMBER(19),
MOVIE_ID NUMBER(19) ,
CUST_ID NUMBER(19),
APP VARCHAR2(4000) ,
DEVICE VARCHAR2(4000) ,
OS VARCHAR2(4000) ,
PAYMENT_METHOD VARCHAR2(4000) ,
LIST_PRICE BINARY_DOUBLE ,
DISCOUNT_TYPE VARCHAR2(4000) ,
DISCOUNT_PERCENT BINARY_DOUBLE ,
ACTUAL_PRICE BINARY_DOUBLE ,
MONTH VARCHAR2(100)',
FORMAT => '{"type":"parquet"}',
PARTITIONING_CLAUSE => 'partition by list (month)
(partition p1 values (''2019-01'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2019-01/custsales-2019-01.parquet''),
partition p2 values (''2019-02'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2019-02/custsales-2019-02.parquet''),
partition p3 values (''2019-03'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2019-03/custsales-2019-03.parquet''),
partition p4 values (''2019-04'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2019-04/custsales-2019-04.parquet''),
partition p5 values (''2019-05'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2019-05/custsales-2019-05.parquet''),
partition p6 values (''2019-06'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2019-06/custsales-2019-06.parquet''),
partition p7 values (''2019-07'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2019-07/custsales-2019-07.parquet''),
partition p8 values (''2019-08'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2019-08/custsales-2019-08.parquet''),
partition p9 values (''2019-09'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2019-09/custsales-2019-09.parquet''),
partition p10 values (''2019-10'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2019-10/custsales-2019-10.parquet''),
partition p11 values (''2019-11'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2019-11/custsales-2019-11.parquet''),
partition p12 values (''2019-12'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2019-12/custsales-2019-12.parquet''),
partition p13 values (''2020-01'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2020-01/custsales-2020-01.parquet''),
partition p14 values (''2020-02'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2020-02/custsales-2020-02.parquet''),
partition p15 values (''2020-03'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2020-03/custsales-2020-03.parquet''),
partition p16 values (''2020-04'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2020-04/custsales-2020-04.parquet''),
partition p17 values (''2020-05'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2020-05/custsales-2020-05.parquet''),
partition p18 values (''2020-06'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2020-06/custsales-2020-06.parquet''),
partition p19 values (''2020-07'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2020-07/custsales-2020-07.parquet''),
partition p20 values (''2020-08'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2020-08/custsales-2020-08.parquet''),
partition p21 values (''2020-09'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2020-09/custsales-2020-09.parquet''),
partition p22 values (''2020-10'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2020-10/custsales-2020-10.parquet''),
partition p23 values (''2020-11'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2020-11/custsales-2020-11.parquet''),
partition p24 values (''2020-12'') location
( ''https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/month=2020-12/custsales-2020-12.parquet'')
)');
END;
/
That’s quite some code I had to write here, beginning with the column definitions over to the explicit listing of each and every partition. I also have to ensure to get the file-to-partition mapping right in my code. But hey, partitioning promises me drastic performance improvements, so let’s try to query the table and see whether this is true:
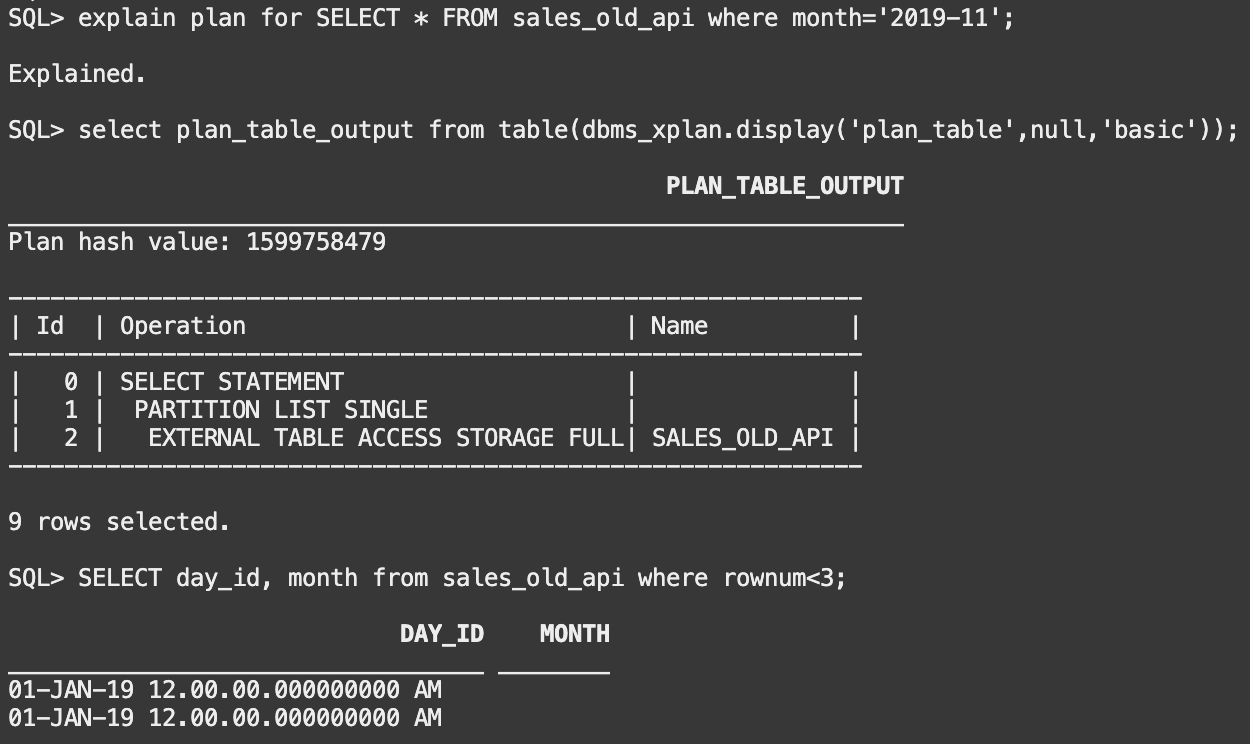
It looks like the predicate in my analytical query was smartly used by the database and pruned down to only the necessary partition to satisfy my request. Mission accomplished, but it was quite cumbersome to get here. And here we have only 24 partitions.
Creating a partitioned external table the new way
Let’s now use the new simplified way to create the same partitioned external table with a fraction of code. And here it is:
BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_PART_TABLE(
TABLE_NAME => 'sales_new_api',
CREDENTIAL_NAME => 'CRED_OCI',
FILE_URI_LIST => 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_namespace/b/moviestream_landing/o/sales_sample/*.parquet',
FORMAT => '{"type":"parquet", "schema": "first","partition_columns":[{"name":"month","type":"varchar2(100)"}]}'
);
END;
/
Yes, the exact same table will be created, with much less code no chance to make a mistake in the partition definition. Also, the column metadata was automatically derived from the underlying self-describing parquet data. What has changed?
- We now derive the column structure for self-describing table formats with partitioned external tables, just like with nonpartitioned external tables.
- The hierarchical nature of the object file storage, together with the additional external table metadata of providing the partition_columns, enables the kernel to build the complete partitioning syntax based on the metadata and the existing files. Our code is exactly the same, whether we will end up with 24 or 1000 partitions!
But is it exactly the same? We can look at the metadata or simply put the new table to the test, just like we did it with the previous one:
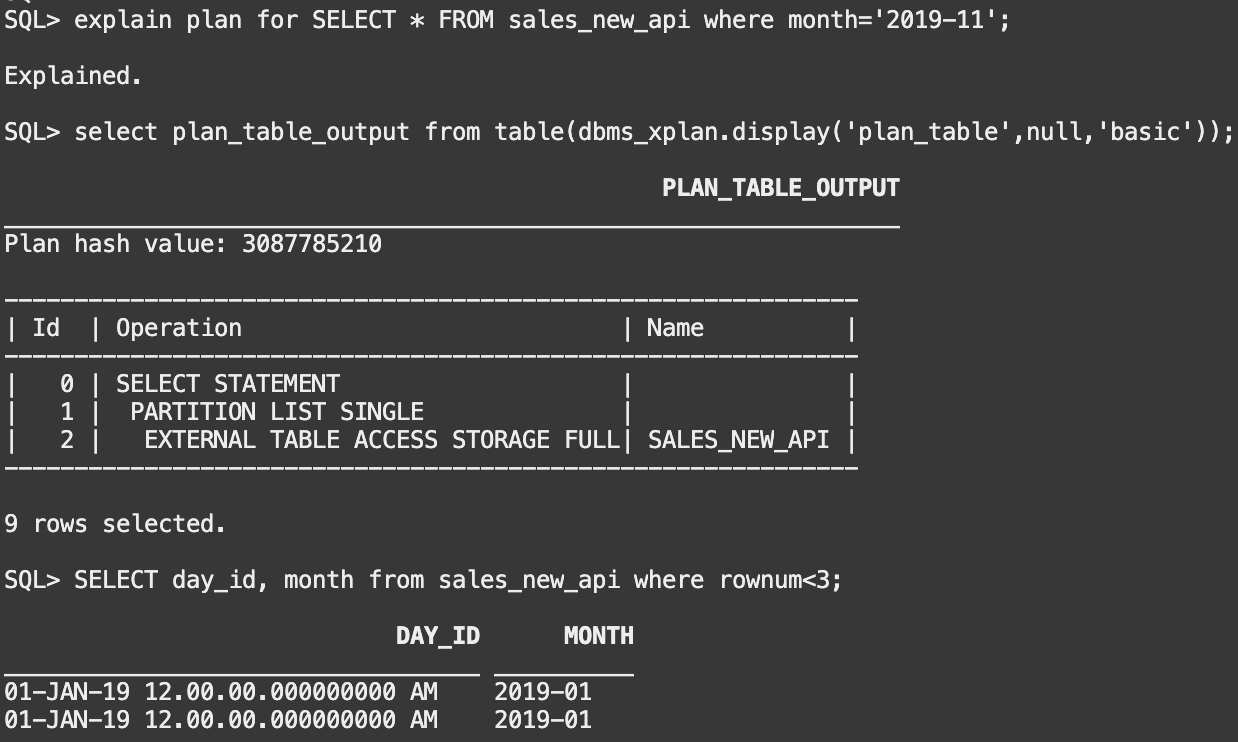
Yep, it all works like a charm. And things are getting even better.
We talked about maintaining tables in case files (partitions) are added or removed to my bucket. To cope with this situation, you do not have to manually sync and adjust your external table definition but simply use another new DBMS_CLOUD interface to do that job for you (the same underlying technique of using the hierarchical object store placement plus the partitioning metadata is used for that, too). If new files are added or removed in the underlying Object Store, you just run the new sync procedure like this:
BEGIN
DBMS_CLOUD.SYNC_EXTERNAL_PART_TABLE (table_name => 'sales_new_api');
END;
/
Isn’t that cool? Yes, it’s manual today, but in a future release, we are planning to automate this as well and add/remove partitions automatically. That’s all for today, folks. But that’s not all we have done for partitioned external tables. Stay tuned and watch out for my next blog that talks about even more cool new stuff.
