Data Transforms is a simple to use tool for Autonomous Database users to load and transform data from heterogenous sources to the Autonomous Database. It is based on Oracle Data Integrator and provides a simple interface to integrate data. In this blog post I will show you how to replicate multiple tables with little effort using this tool.
Setting up Data Transforms
Data Transforms is available by deploying Oracle Data Integrator (ODI) Web Edition from OCI Marketplace. For deployment steps, please look at the Oracle LiveLabs for ODI Web Edition. Once deployed, the home screen looks like this.
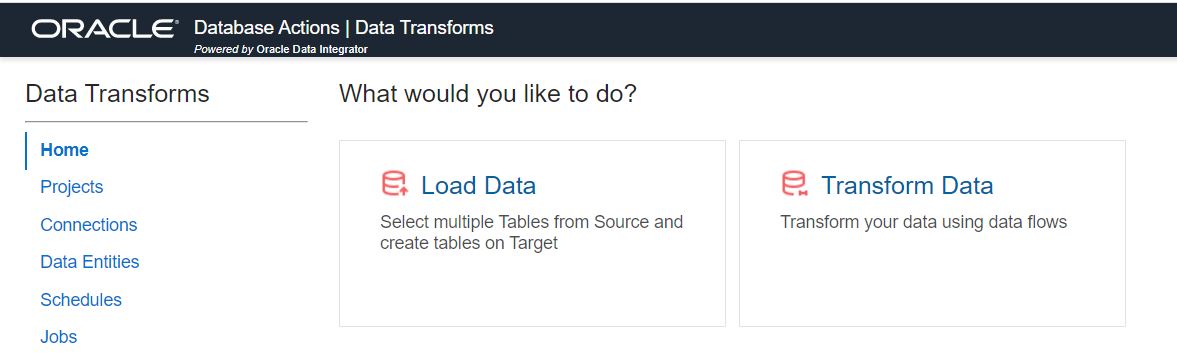
Once deployed, you can then register Data Transforms with your Autonomous Database, so that a Data Transforms card appears in the Data Tools section of the database’s Database Actions page. Clicking on this card invokes the Data Transforms tool.
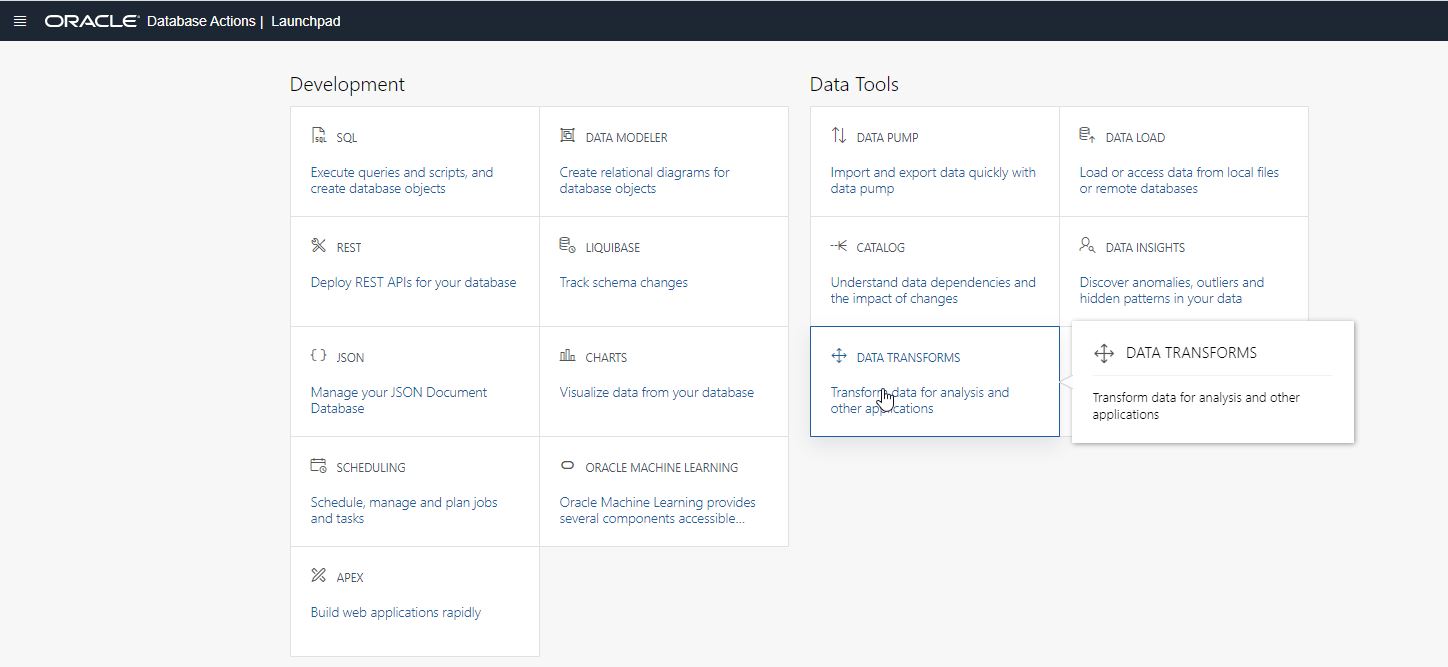
Loading Data from Heterogenous Sources
Data Transforms supports connections to a wide variety of source systems. To load data from any of these systems, we first need to create a connection to the source, and confirm the connection to the Autonomous Database as our target. After that we will use the Data Load wizard to create a data load job. This job can be run on-demand, or scheduled for periodic execution.
Let’s look at the details.
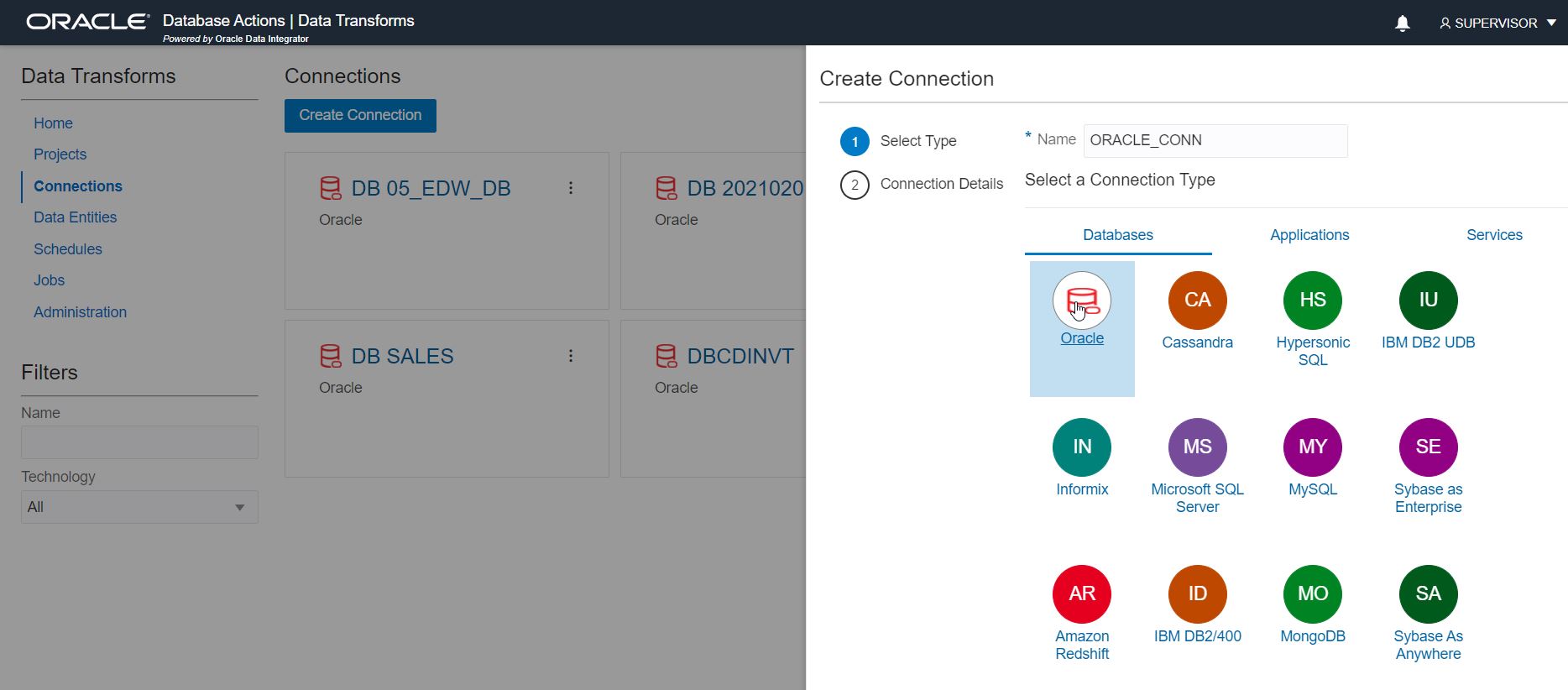
Step 1: Create Connection.
From the left side menu, click on “Connections”. It will show any existing connections, and you can create new connections. The Data Transforms deployment automatically picks up the Autonomous Database connection, but you will need to create a new connection to your source.
Note that new connections are categorized in Databases, Applications and Services categories. Select the appropriate connection type by category, e.g. Database for Oracle, DB2, MS SQL Server etc., or Application for Oracle Sales Cloud, NetSuite etc., and then provide connection parameters (such as user and password). Connection parameters are specific to the connection type. Test it for successful connection and save it.
Note: You can use all database and application connection types in the Data Load wizard, except BICC (BI Cloud Connector). The list is diverse, and you can even add your own custom connectors using 3rd party JDBC drivers if needed.
Note: You can also use GoldenGate for replication by creating a connection in the Services category, but this is a topic for another blog post. For now, we will create a data load job without GoldenGate.
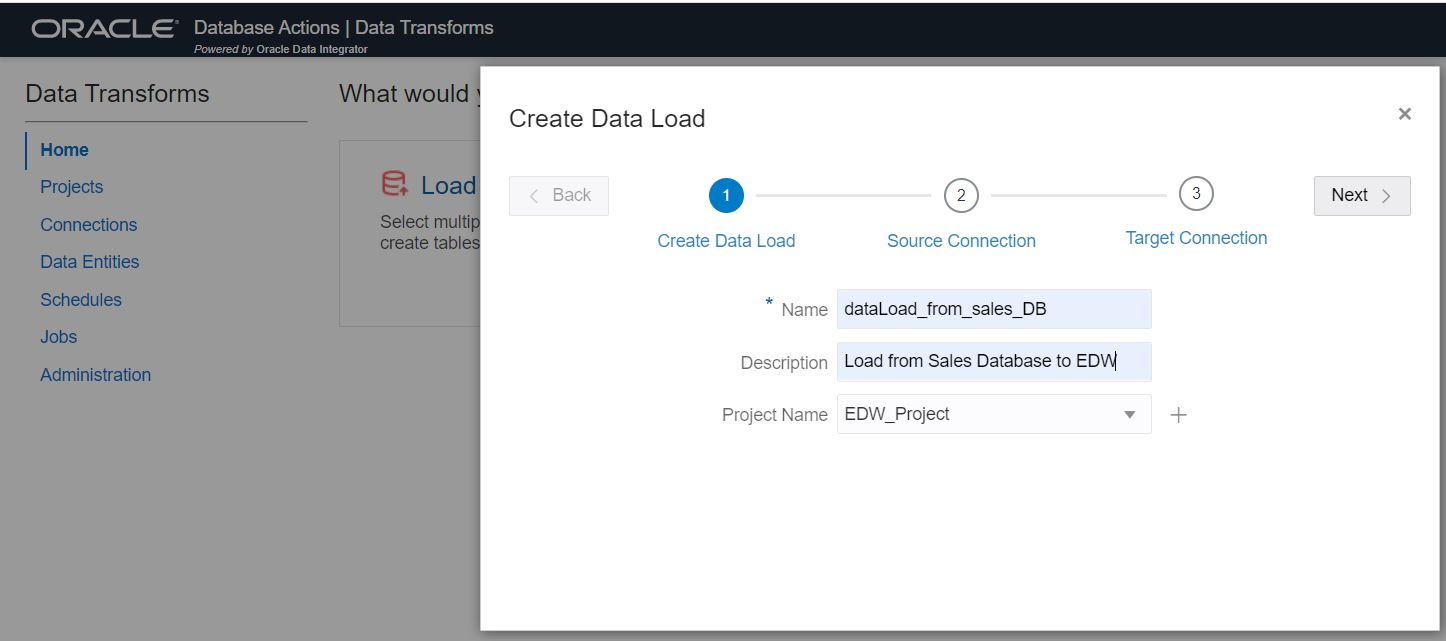
Step 2: Use the Data Load wizard.
From the home screen, click on “Load Data” button. This wizard will guide you through the steps needed to configure the data load job. You can create a new project if you don’t have one already. A project is a collection of integration jobs for better manageability. Click “Next”.
Step 3: Select the source connection and schema.
In this example, we will use a connection called “DB SALES” and the schema “CUST_SALES” as a source containing customer orders data. Click “Next”.
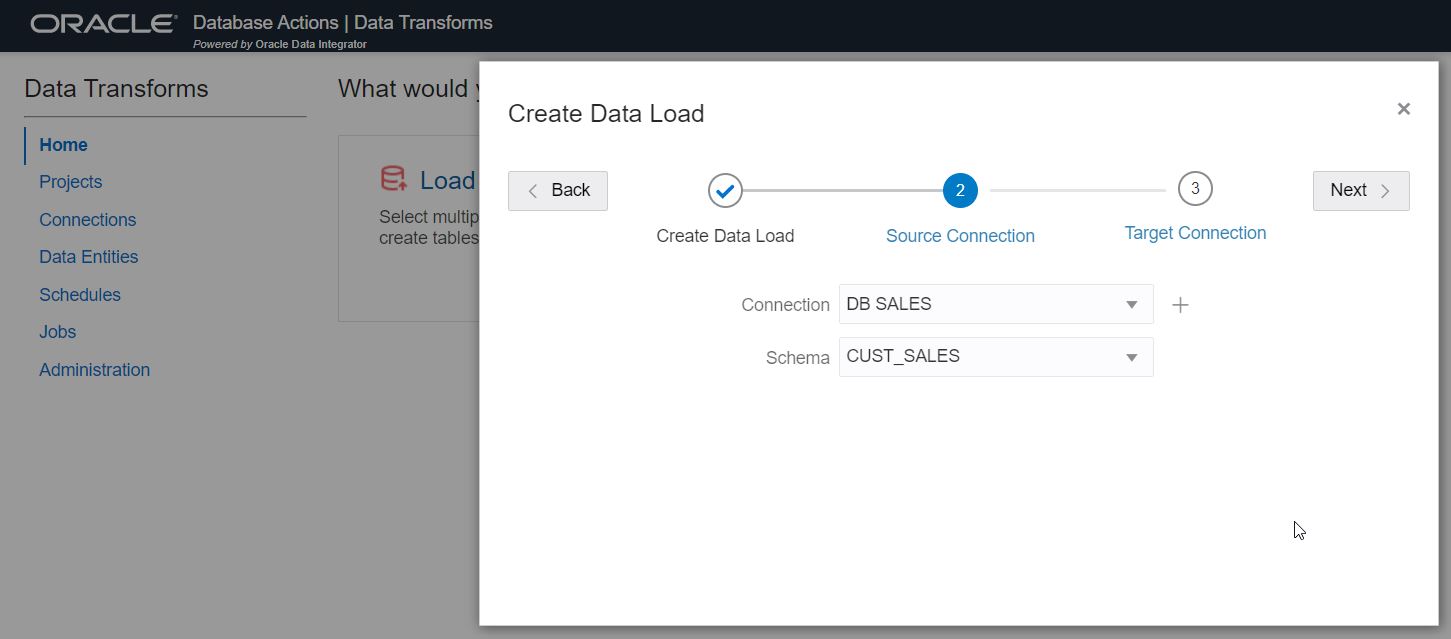
Step 4: Select the target connection and schema.
Next, select your Autonomous Database connection as your target. Below, we are using the connection for “DB 05_EDW_DB” and the schema “SALES_STAGING”. This is where target tables will be created and loaded with data. Click “Next”.
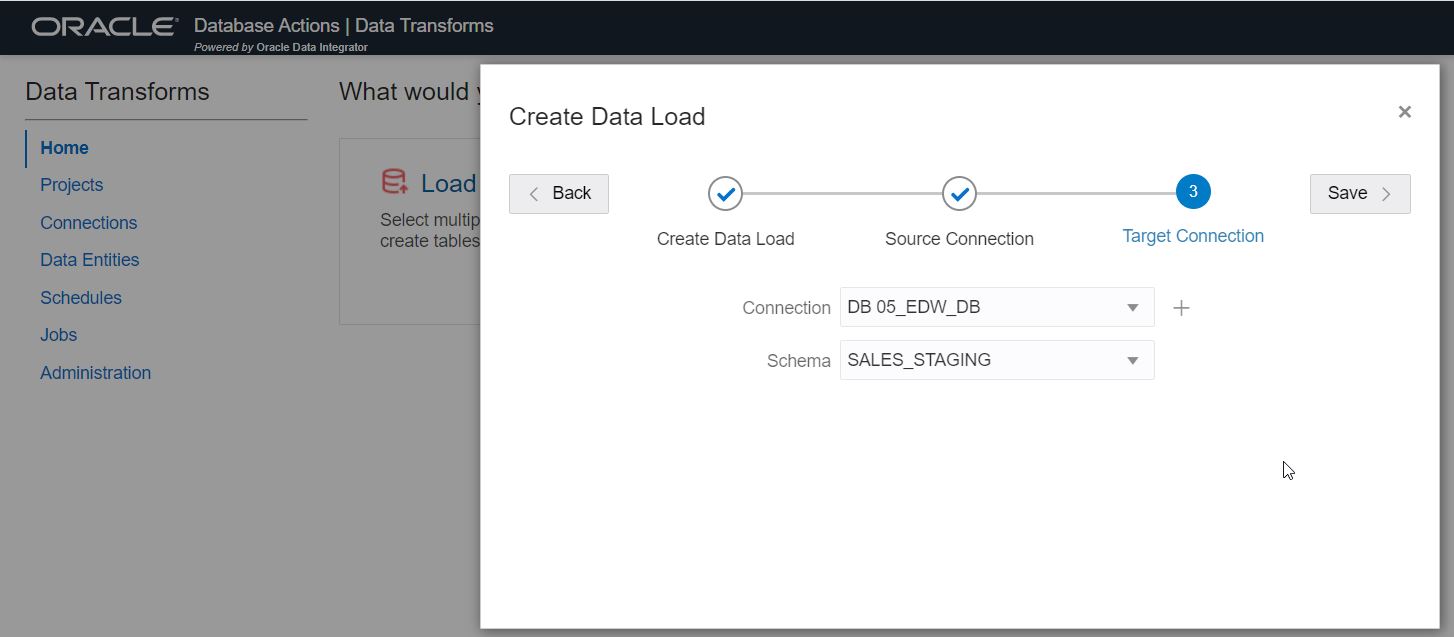
Step 5: Select tables for loading.
Now you can see all the source tables in the source schema. You can select all the tables from the source or select a subset. You can also use the filter on the left side panel to find tables by name.
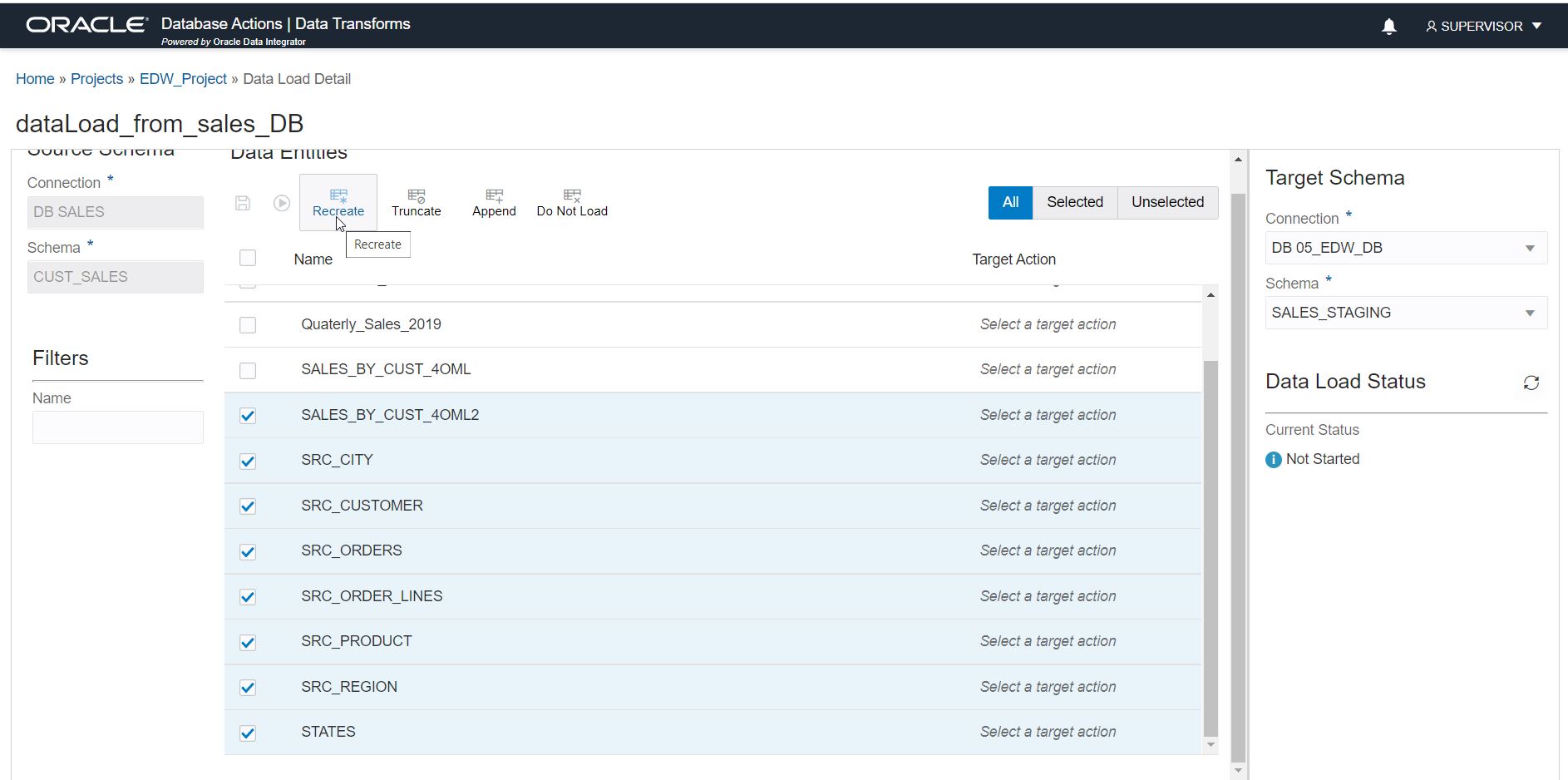
Step 6: Select load action
For each selected table, you can configure the following load actions:
Recreate: The target table will be recreated with the same data definition (DDL) as the source. Use this if your source table’s definition (DDL) can change.
Truncate: The target table will be truncated and repopulated when the load job runs. Use this option to refresh an existing target table.
Append: Data will be appended to the target table.
Do Not Load: Use this to stop loading to a target table which was part of an earlier load process.
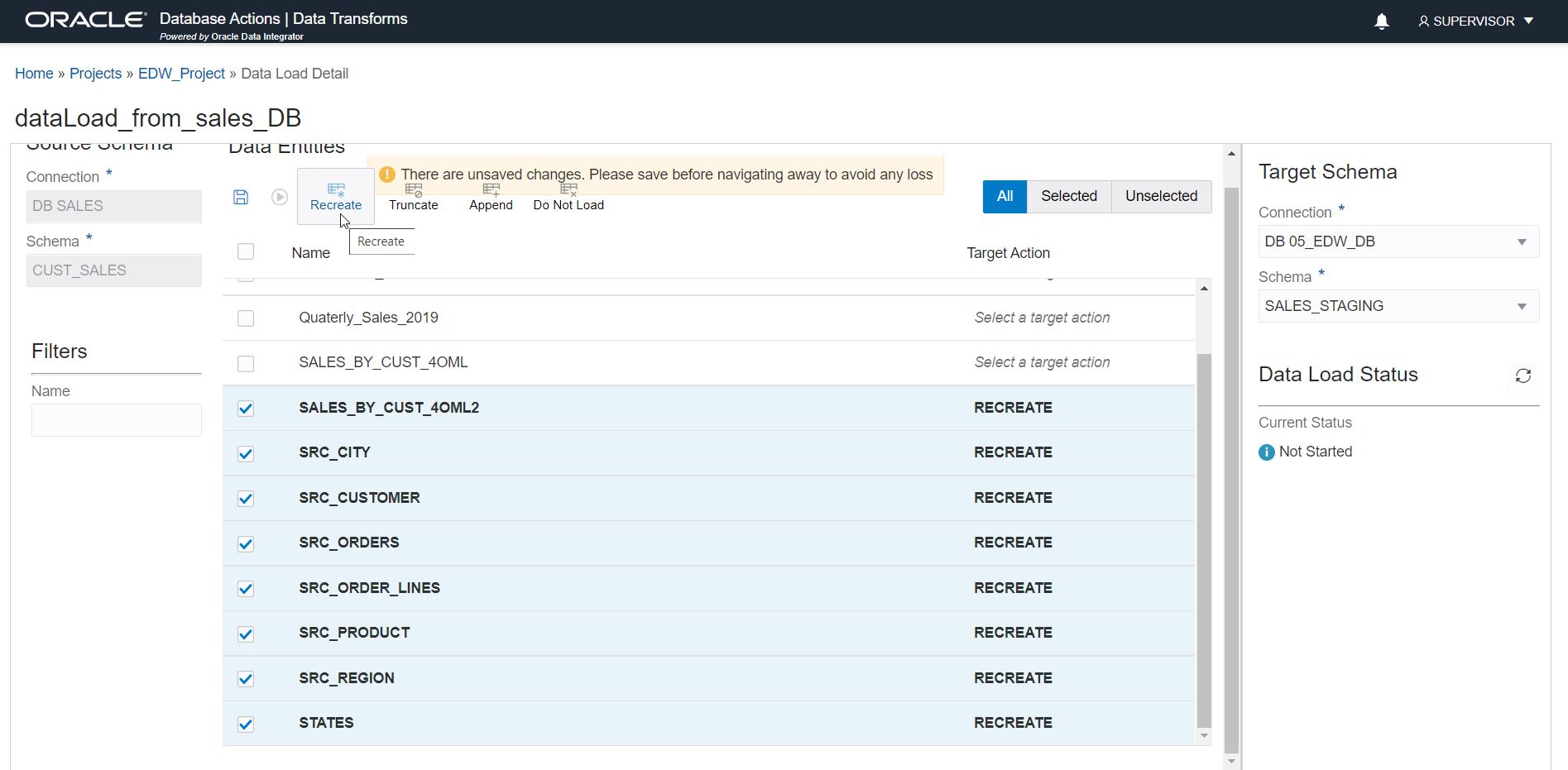
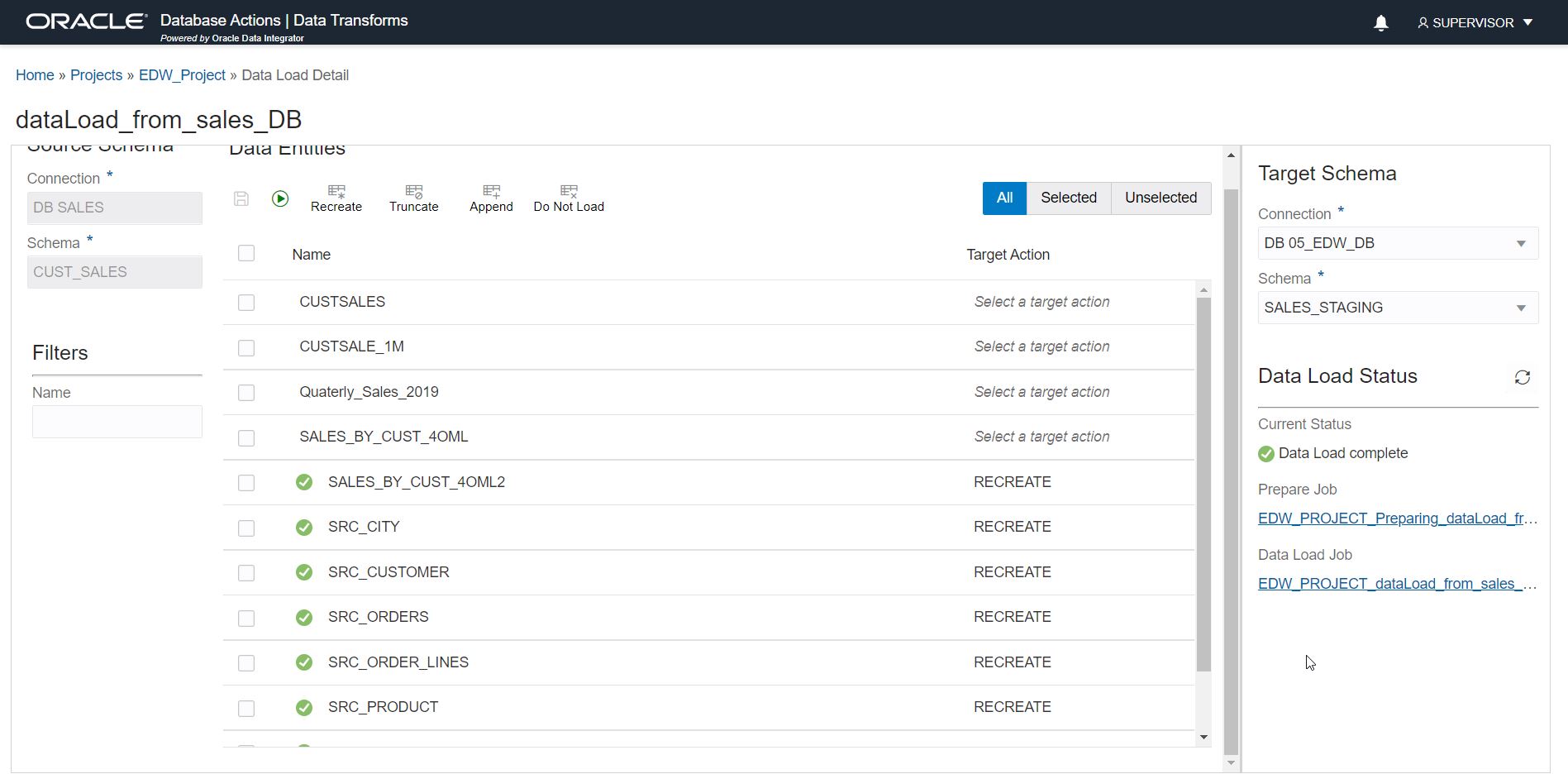
Step 7: Save and execute/schedule
Now the data load job is created. You can either run it right away by clicking on the run button, or use the scheduler from the home menu to execute the job periodically. You can see the job status on the bottom right side. There is also a separate jobs page for the detailed status.
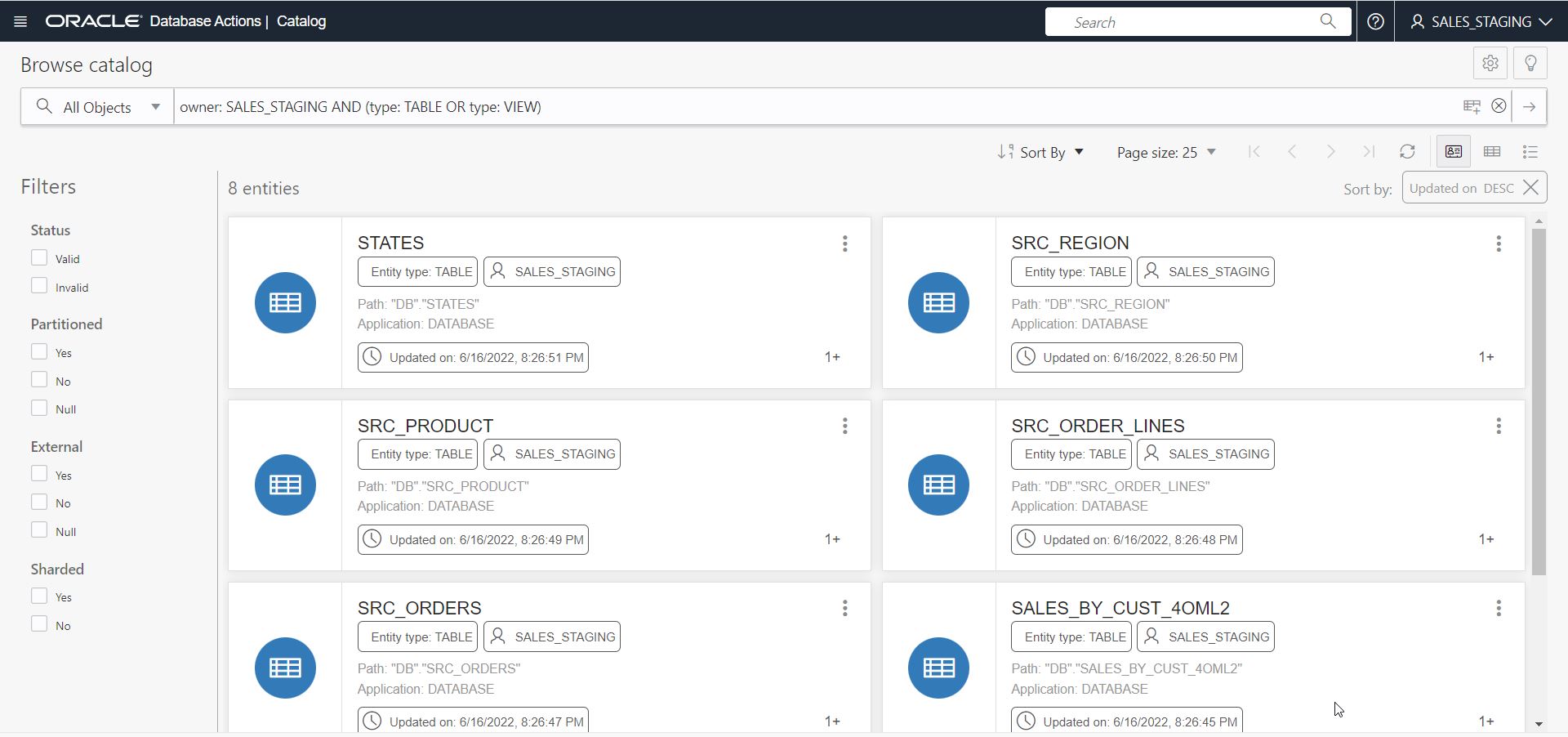
Step 8: Verify loaded tables
After the successful completion of the job, you can check that the target table has been created and populated correctly using your tool of choice. Below, you can see the target tables in the Explore view of Autonomous Database’s Data Tools.
Summary
It is very easy to replicate data from heterogenous databases or applications to an Autonomous Database using the Data Transforms tool. You can also integrate with GoldenGate, in order to model a replication job that first replicates data in batch, then keeps source and target in sync in real-time as source data changes.
Keep in mind that Data Transforms tool is much more than a tool to load data. Using this tool, you can perform complex transformations as well and build complex integration flows easily. Refer to the user guide for this tool to explore these features.
