As the only truly converged database, Oracle Autonomous Database (ADB) allows users to work with data of different kinds, including external data. Object Stores are the de-facto standard for storing data outside of the database in Cloud environments, so I’m happy to remind you of existing functionality and to talk about new features recently introduced in ADB.
Problem
While databases are well designed for data stored inside, data outside the database is less structured and not always as easy to find and deal with. For example, you can query the data dictionary to find a table by name patterns, so you’d like to do the same for external data. Or you want to smartly leverage the hierarchical information of stored files for both optimized access and leverage information about where the data is stored externally as additional data attributes.
The good news is that Oracle has a solution for all these challenges. I’ll break down the solution in a few logical steps and explain it below
Step 1. Authentication – create credentials
You must authenticate yourself from within the database and set the credentials to access the Object Store. You can do it in two ways:
a. Create a user credential object. This blog explains in detail how to do this.
b. Use resource principals. This is well covered in another blog.
Going forward, I will use resource principal for authentication.
Step 2. Look for objects matching a specific name pattern
With resource principals, your database got access to specific buckets in your cloud tenancy so that you can look for the files of interest. Using DBMS_CLOUD, you can list and filter the content of your bucket, for example:
define uri_root = 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/my_tenancy/b/moviestream_landing/o';
SELECT OBJECT_NAME, BYTES
FROM
DBMS_CLOUD.LIST_OBJECTS(CREDENTIAL_NAME => 'OCI$RESOURCE_PRINCIPAL',
LOCATION_URI => '&uri_root/');
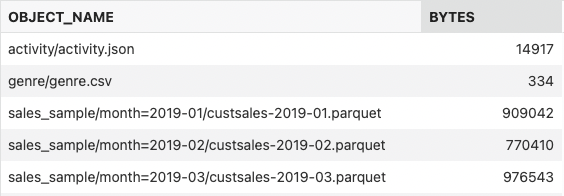
You can find several files in the Object Store matching your search pattern. Of course, you could use the Web UI or SDK to do the same, but with DBMS_CLOUD, you never have to leave the database to find your files of interest.
Step 3. Create an external table on top of Object Store data
Now that I found my files of interest, I want to access the external data and do some data analysis. I did that in the following blog post where I created a partitioned external table on top of my customer sales data. Looking at the data is now as easy as looking at an internal table:
select * from SALES_SAMPLE;

You can see a column “MONTH” in the result set, although when you look at the external data files, you will not find this information stored in it. So, where is it coming from? Well, this column does not physically exist in the files, but it is stored in the location of the files: the information about the “MONTH” is derived from the Object Store file URI, as you can see in the Object Store listing:
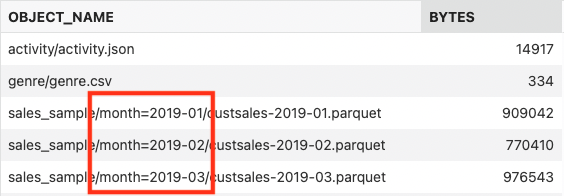
Step 4. Use new virtual columns to get object store details
How does Oracle do this? The answer is simple: we added new virtual columns “file$name” and “file$path” for every external data file and use this information to derive the MONTH information in the example above automatically in the case of partitioned external tables with a predefined URI pattern. You can also use these new virtual columns explicitly for other purposes. For example, when loading data, you can tell exactly which file provided a specific row in your result set or which region or bucket the data was coming from. Below is a simple example demonstrating this behavior:
select
file$name,
file$path,
s.*
from DCAT$IAD_TEST_PREFIX.SALES_SAMPLE SAMPLE(0.001) s;

As you can see, working with external data is not hard, and providing a logical link between external data location, the data content and using it together is the next step in making this everyday exercise easier than ever before.
You want to learn more? Then the Oracle documentation is your friend, or just ask me anything in the comments section.
