When you read this blog, there’s a high chance you know the Oracle relational database. You are familiar with it storing and managing data securely in its proprietary, optimized format. So, what’s the deal with us talking about parquet files suddenly? Well, there are a couple of reasons for processing Parquet with Oracle. You will not only read about some of those reasons but also see why Parquet is a format perfectly suited for being processed by the Oracle database, exclusively or alongside your mission-critical, highly-secured data in the database. Yes, the Oracle database is a great execution platform for Parquet files, whether it’s SQL, PL/SQL, or other supported languages.
Why should you care about external data alongside your database?
There are quite many situations where it’s beneficial and helps the business to use external data exclusively or in addition to the data stored in your database:
- Instantaneous data access: Query your data in its original format when it becomes available before any data manipulation. Some people call this a data lake functionality, and you can read more about this here.
- Keep your source of truth: Access your raw data even after ETL. Whether it’s for data lineage or some post-mortem, you can find a more in-depth discussion here.
- Collaboration: Remove data silos and collaborate using different tools and languages. Here is a little write-up about this topic.
- All your data: Blend Relational and Big Data, as discussed here, and efficiently deal with changing (drifting) schemas, as illustrated here.
I could go on with this list, but you get the idea: Fact is, there are data assets outside your database, so why not use those to your benefit with the best relational database? And with Parquet Files being one of the best options for storing data outside a database, let me introduce Parquet and share some tips on how to build an efficient parquet layout.
What are Parquet Files?
Apache Parquet is a popular columnar file format that stores data efficiently by employing column-wise compression, different encoding strategies, and compression based on data type and stores metadata alongside the data. Generally, the less data you have to read and transfer, the better your query performance and the lower your running costs. And obviously, the smaller the data footprint, the smaller the costs for storing it. Parquet helps us here quite a bit.
Advantages of Parquet Files
Let us walk through the features that Parquet offers to increase the performance of processing external data.
Performance
- Columnar format.
Parquet Files are organized in columns, which means only columns listed in the SQL statement need to be read by compute layer if the processing engine is smart enough to take advantage of this format. Oracle is such a smart engine, and so are Spark or Presto.
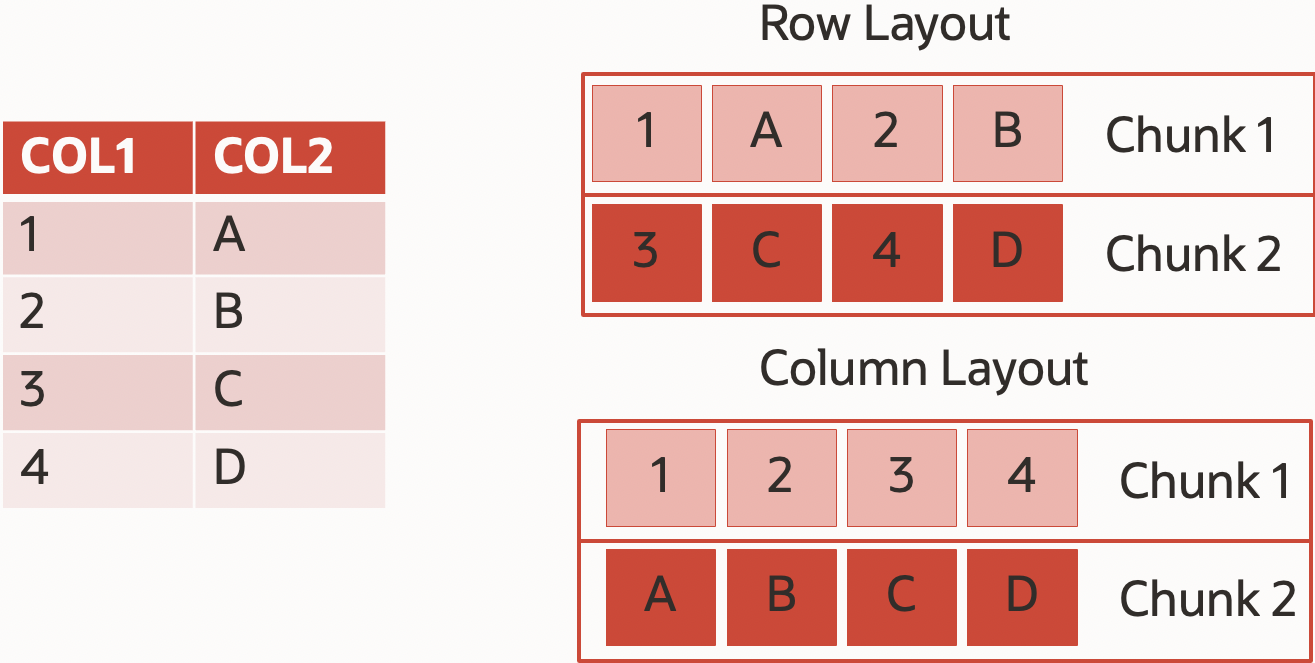
If you need to read a single column from a Parquet file, you only read the corresponding column chunks from all Row Groups. You do not need to read and interpret the full content of all Row Groups. So, if a table has 50 columns and the user runs a query like:
select col_1 from parquet_table where col_50=123;
Only two columns out of 50 will be used. With the I assumption that column sizes are roughly equal, we can say that reader would scan only 4% of the data. But there’s more a smart engine can do.
- Predicate Push Down
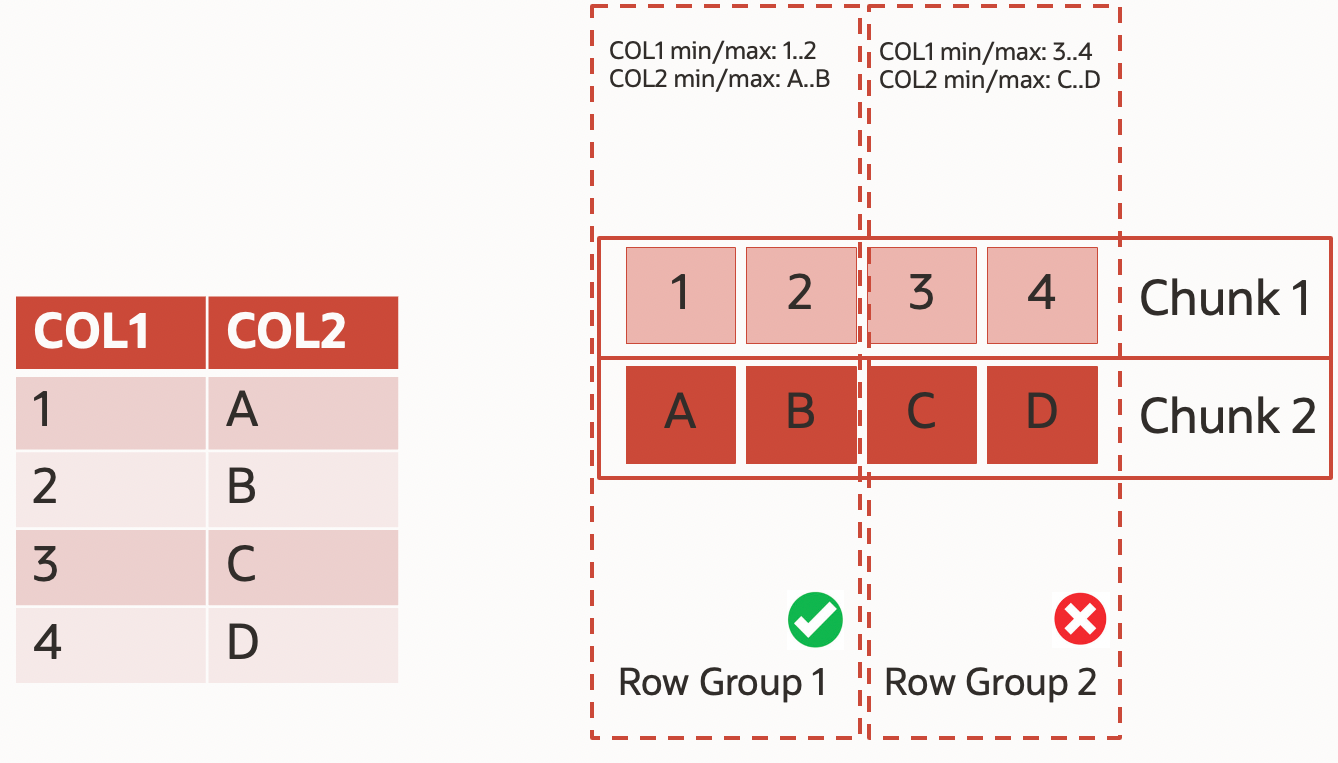
I will not go too deep into the technical details of how Parquet files are organized (for those of you who want, here is the parquet open source standard specification), but each file is divided into chunks (called row groups), and each of those chunks has metadata for each column (min/max value). Row Groups are a way to implement hybrid row/column storage where rows are joint into row groups and within a row group stored by columns. A single Row Group contains data for all columns for some number of rows. This is pretty much exactly what Oracle Hybrid Columnar Compression does as well. A smart reader can use these metadata and skip reading part of the file based on SQL predicates. For example, look at the following query:
select * from my_table where col1=1;
Accessing the file illustrated in the graphic above, this query will only read one row group (because of col1=1 predicate) and will skip scan the second Row Group
Manageability
- Parquet is a self-explaining file format. So, metadata is stitched together with data. It meant that only having a file user could define a table, and nothing extra was required. That’s for example what you do when creating an external table using DBMS_CLOUD in autonomous database.
Economics
- Everything is compressed by default. Also, encoding is used by default in every case, reducing the amount of data on disk out of the box.
- Compression rate. As columnar file format, you usually get good compression ratios for your data.
Parquet is an open, widely adopted format. It has been available for quite some time and has become the default standard for storing data in a columnar format outside your database engine. So whenever your data does not require the security and robustness of being stored, managed, and protected by your database and you have a choice, you should consider storing data in Parquet, compared to other open formats like CSV. I also suggest watching this video, which recaps many of the points discussed above. This blog post also extensively explains the value of Parquet Files
Good practices for Parquet file creation
You may have data in a format other than Parquet, like CSV, and want to consider Parquet for the reasons mentioned earlier. Parquet offers a whole slew of options and settings, so let us look at some of the most basic rules of thumb you should consider when creating Parquet Files:
- Avoid large amounts of small files. There is an overhead when a file is opened. Don’t generate files less than 64MB (ideally 128MB and higher).
- Don’t use very large files. A large file means you have a large metadata footer, which is not optimized for reading. Also, some unpredictable things may happen with encoding, and the dictionary becomes non-efficient, etc. Don’t generate files larger than 64GB, if possible.
- The optimal Row Group size is 128 MB when processing parquet files with an Oracle database. Row Group chunks are the unit of work for the database reader, and large size may create pressure on Oracle database memory (and causing PGA related exceptions). Remember, a Row Group Chunk contains compressed data that must be uncompressed for processing. 128MB is the optimal Row Group size based on our experience, but values between 64MB and 512MB are still acceptable in most cases.
- If you know ahead of time that some column(s) will be actively used as query predicate, order by these column(s). It will allow efficient use of predicate push-down and skip big chunks of data scan.
- If there’s no ordering for performance and you want to optimize your compression benefits, consider ordering by columns with low cardinality (such as age, not customer_id) and let encoding do its job. This is a common approach for archiving data that is not frequently accessed.
- Use some lightweight compression codec (Snappy or ZSTD) to save some space and data transfer volume while not impacting performance.
- Use partitioning. While last on this list, this is the Number One rule of thumb for any type of data warehouse processing.
Page Size is another parameter that matters for some engines, but that one does not matter to Oracle; you can leave it default.
Now it’s time to understand the inner details of a Parquet file, how to generate such files, and how to use them in Oracle.
How to obtain information about Parquet files
Some Parquet file metrics are apparent (such as file size), and others aren’t (such as row group size). But we are interested in better understanding how a Parquet file was built, its insights, and seeing what could be optimized. Let me introduce two alternatives doing so and point out what to look for:
- Python based parquet-tools.
That’s probably the easiest way to get some insight into your Parquet files. When you have Python 3 already in place, then it’s super-easy to install. Just run the following command, and it’s ready to use:
pip3 install parquet-tools
Voila, you got a simple but powerful tool. Just run the “inspect” command to learn how a file has been created, what compression was used, how many columns are there, and how many row groups are.
$ parquet-tools inspect ../yellow_tripdata_2022-02.parquet ############ file meta data ############ created_by: parquet-cpp-arrow version 7.0.0 num_columns: 19 num_rows: 2979431 num_row_groups: 1 format_version: 1.0 serialized_size: 10386 ############ Columns ############ VendorID tpep_pickup_datetime tpep_dropoff_datetime passenger_count trip_distance RatecodeID store_and_fwd_flag PULocationID DOLocationID payment_type fare_amount extra mta_tax tip_amount tolls_amount improvement_surcharge total_amount congestion_surcharge airport_fee ############ Column(VendorID) ############ name: VendorID path: VendorID max_definition_level: 1 max_repetition_level: 0 physical_type: INT64 logical_type: None converted_type (legacy): NONE compression: GZIP (space_saved: 48%) ... ############ Column(airport_fee) ############ name: airport_fee path: airport_fee max_definition_level: 1 max_repetition_level: 0 physical_type: DOUBLE logical_type: None converted_type (legacy): NONE compression: GZIP (space_saved: 59%)
Looking at this example, the most important information here is the number of row groups (just 1), the framework used to create the file (parquet-cpp-arrow), and the compression that is applied for every column (GZIP).
2. Java-based Parquet tool
The Python-based tool is sufficient in most cases, but if you want more detailed information, you can use the Java-based version of parquet-tools.
Assuming you have this tool installed, you use it as follows:
$ java -cp "parquet-cli-1.13.0-SNAPSHOT.jar:dependency/*" org.apache.parquet.cli.Main "$@" meta ../yellow_tripdata_2022-02.parquet
File path: ../yellow_tripdata_2022-02.parquet
Created by: parquet-cpp-arrow version 7.0.0
...
Schema:
message schema {
optional int64 VendorID;
optional int64 tpep_pickup_datetime (TIMESTAMP(MICROS,false));
optional int64 tpep_dropoff_datetime (TIMESTAMP(MICROS,false));
optional double passenger_count;
optional double trip_distance;
optional double RatecodeID;
optional binary store_and_fwd_flag (STRING);
optional int64 PULocationID;
optional int64 DOLocationID;
optional int64 payment_type;
optional double fare_amount;
optional double extra;
optional double mta_tax;
optional double tip_amount;
optional double tolls_amount;
optional double improvement_surcharge;
optional double total_amount;
optional double congestion_surcharge;
optional double airport_fee;
}
Row group 0: count: 2979431 15.31 B records start: 4 total(compressed): 43.491 MB total(uncompressed):76.035 MB
--------------------------------------------------------------------------------
type encodings count avg size nulls min / max
VendorID INT64 G _ R 2979431 0.13 B 0 "1" / "6"
tpep_pickup_datetime INT64 G _ R_ F 2979431 3.72 B 0 "2003-01-01T00:10:06.000000" / "2022-05-24T17:41:50.000000"
tpep_dropoff_datetime INT64 G _ R_ F 2979431 3.81 B 0 "2003-01-01T12:38:59.000000" / "2022-05-24T17:43:27.000000"
passenger_count DOUBLE G _ R 2979431 0.20 B 101738 "-0.0" / "9.0"
trip_distance DOUBLE G _ R 2979431 1.41 B 0 "-0.0" / "348798.53"
RatecodeID DOUBLE G _ R 2979431 0.06 B 101738 "1.0" / "99.0"
store_and_fwd_flag BINARY G _ R 2979431 0.03 B 101738 "N" / "Y"
PULocationID INT64 G _ R 2979431 0.72 B 0 "1" / "265"
DOLocationID INT64 G _ R 2979431 1.02 B 0 "1" / "265"
payment_type INT64 G _ R 2979431 0.15 B 0 "0" / "5"
fare_amount DOUBLE G _ R 2979431 1.04 B 0 "-600.0" / "655.35"
extra DOUBLE G _ R 2979431 0.21 B 0 "-4.5" / "10.3"
mta_tax DOUBLE G _ R 2979431 0.02 B 0 "-0.5" / "3.3"
tip_amount DOUBLE G _ R 2979431 1.09 B 0 "-188.0" / "380.8"
tolls_amount DOUBLE G _ R 2979431 0.09 B 0 "-29.05" / "95.0"
improvement_surcharge DOUBLE G _ R 2979431 0.01 B 0 "-0.3" / "0.3"
total_amount DOUBLE G _ R 2979431 1.46 B 0 "-600.3" / "656.15"
congestion_surcharge DOUBLE G _ R 2979431 0.08 B 101738 "-2.5" / "2.75"
airport_fee DOUBLE G _ R 2979431 0.06 B 101738 "-1.25" / "1.25"
This tool gives a user extensive information for each row group. In the example above, it’s only one Row Group. The Row Group is compressed and takes up 43.491MB of space, and its uncompressed size is 76.035MB. For each column, you will find its data type, the encoding used (picked automatically), the average column size, and its min/max value.
If your file has multiple row groups, it would look similar to the following:
$ java -cp "parquet-cli-1.13.0-SNAPSHOT.jar:dependency/*" org.apache.parquet.cli.Main "$@" meta ../new6RG.parquet
File path: ../new6RG.parquet
Created by: parquet-mr version 1.10.1 (build a89df8f9932b6ef6633d06069e50c9b7970bebd1)
Properties: org.apache.spark.version: 3.0.2
org.apache.spark.sql.parquet.row.metadata: {""type"": "struct", "fields":[{"name": "ID", "type": "decimal(38,10)", "nullable":true," metadata":{}},{"name": "NAME", "type": "string", "nullable":true," metadata":{}},{"name": "SALARY", "type": "decimal(10,2)", "nullable":true," metadata":{}}]}
Schema:
message spark_schema {
optional fixed_len_byte_array(16) ID (DECIMAL(38,10));
optional binary NAME (STRING);
optional int64 SALARY (DECIMAL(10,2));
}
Row group 0: count: 9322349 741.64 B records start: 4 total(compressed): 6.439 GB total(uncompressed):8.892 GB
--------------------------------------------------------------------------------
type encodings count avg size nulls min / max
ID FIXED[16] G _ 9322349 6.99 B 0 "2.0000000000" / "12799999.0000000000"
NAME BINARY G _ 9322349 732.49 B 0 "AAAyHSrNyFnENpSaQFDubUKQG..." / "zzzVBNkZgdPdQFOLUgUDTyiCO..."
SALARY INT64 G _ R 9322349 2.16 B 0 "2000.20" / "8999.85"
Row group 1: count: 3477651 741.66 B records start: 6913786041 total(compressed): 2.402 GB total(uncompressed):3.317 GB
--------------------------------------------------------------------------------
type encodings count avg size nulls min / max
ID FIXED[16] G _ 3477651 6.95 B 0 "1.0000000000" / "12800000.0000000000"
NAME BINARY G _ R_ F 3477651 732.49 B 0 "AAAyHSrNyFnENpSaQFDubUKQG..." / "zzzVBNkZgdPdQFOLUgUDTyiCO..."
SALARY INT64 G _ R 3477651 2.22 B 0 "2000.20" / "8999.85"
This is an example of an unoptimized file, because it has a big rowgroup (6.439 GB compressed and 8.892 GB uncompressed) that will create pressure on the memory. You will need the uncompressed size to identify all individual values. It will also not parallelize well. Only one process can uncompress a compressed object, whether a gzip file on disk or a compressed Row Group of a Parquet file.
How to create Parquet files that work with Oracle Database
There are several ways to generate parquet files, and we spend quite some time playing and experimenting with those. The most common ones we tested with our Oracle Parquet file reader are:
- Parquet Arrow (parquet-cpp-arrow, https://arrow.apache.org/)
- Parquet MR (parquet-mr, https://github.com/apache/parquet-mr)
- Parquet (parquet-cpp, https://github.com/apache/parquet-format)
- Pandas (https://pandas.pydata.org/pandas-docs/version/1.1/reference/api/pandas.DataFrame.to_parquet.html)
If you want to dive into the inner mechanics of how Parquet files are written, I suggest reading the following blog.
How to generate Parquet files using Python
It’s pretty standard that a data source doesn’t produce a Parquet file directly, and an intermediate step is required to convert the source file format (e.g., CSV) into Parquet format. That is a topic for at least one or two more blog posts, and that would be even only focusing on all the services and tools available from Oracle and in the Oracle Cloud. Let me, therefore, just very briefly introduce the most straightforward approach that works well for small to medium-sized files using Python.
Using Python I recommend using PyArrow, which requires the installation of additional libraries. It also requires Python 3.7+ as pre-requirement. On an Oracle Linux8 you use the following commands to install all you need:
sudo dnf module install python39 sudo dnf install python39-pip sudo alternatives --set python3 /usr/bin/python3.9 sudo pip3 install pandas sudo pip3 install pyarrow
In the Python world, there is a well-known package called pandas. This package allows to read csv files and convert them to Parquet file using less than 10 lines of code:
import sys
import pandas as pd
def write_parquet_file():
df = pd.read_csv(sys.argv[1])
# row_group_size is in kBytes
df.to_parquet(sys.argv[2],compression='None',row_group_size=65536, engine="pyarrow")
write_parquet_file()
Put this code in your Python program – e.g. convert_csv.py – and run it on the command line with your csv file name as input and a name for your parquet file as output:
$ python3 convert_csv.py input_file.csv output_file.parquet
It’s as easy as 1-2-3. After running this little program, you can inspect your file using what you learned in this blog. Try it out yourself, I am sure you have csv files.
How to use Parquet Files with Oracle Autonomous Database
After talking about Parquet files a lot, it’s time to come back to the Oracle Database and how to easily access and work with Parquet files as a table in the Oracle Database. Accessing external data from within the database provides business benefits, and Parquet Files are the optimal file storage format.
Now is the time to see how to access external Parquet files and work with its data using the database as a processing engine.
First, we need to make the data accessible to the database. The mechanism of how to do this should not surprise you: External Tables are the way to go. It’s effortless and straightforward to define an external table on top of a Parquet file because it is self-describing and contains the schema information. The database leverages this metadata, so all you have to define is how you want to name the external table and how to access the parquet file(s), which reside in the object store in this example:
begin
dbms_cloud.create_external_table (
table_name =>'sales_external',
credential_name =>'OBJ_STORE_CRED',
file_uri_list =>'https://swiftobjectstorage..oraclecloud.com/v1///sales_extended.parquet',
format => '{"type": "parquet", "schema": "first"}'
);
end;
Alternatively, you can use Database Actions, a Web UI of your Autonomous Database, to do the same in a user-friendly manner. Here is a great blog post on creating your table conveniently with the UI.
After creating the external table, you use it like any other table in your database:
SELECT sum(amount_sold) FROM sales_external WHERE sales_region = ‘SOUTH’
Oracle’s intelligent Parquet reader will use the Parquet metadata, only read the column chunks for columns’ sales_region’ and ‘amount_sold’, and skip all Row Groups that do not contain information about sales_region ‘SOUTH’. There’s a blog from my colleague Marty Gubar who did a fantastic blog about this functionality in more detail, in case you are interested. And there is more to come.
Summary
You have external files containing business value data that you want to explore and use. Parquet files are commonly used and are one of the best possible file formats for intelligent data processing. Oracle takes advantage of all the data processing benefits Parquet offers and continuously invests in improving the interaction between Parquet files and Oracle. You should start benefitting from it today.
There’s more to come
This is admittedly not one of my shorter blog posts, but I still only scratched the surface. Some future blogs will touch on more details of how to generate Parquet files and “other things” related to Oracle and Parquet that are not ready to be spelled out yet. Stay tuned!
