One of the popular new Big Data SQL features is its Query Server. You can think of Query Server as an Oracle Database 18c query engine that uses the Hive metastore to capture table definitions. Data isn’t stored in Query Server; it allows you to access data in Hadoop, NoSQL, Kafka and Object Stores (Oracle Object Store and Amazon S3) using Oracle SQL.
Installation and Configuration
Architecturally, here’s what a Big Data SQL deployment with Query Server looks like:
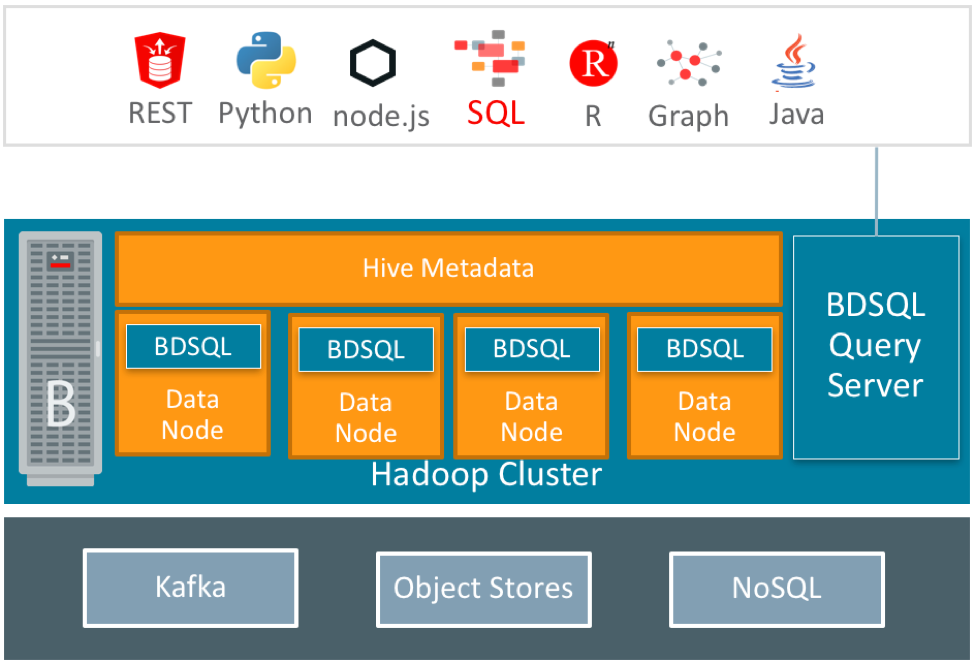
There are two parts to the Big Data SQL deployment:
- Query Server is deployed to an edge node of the cluster (eliminating resource contention with services running on the data nodes)
- “Cells” are deployed to data nodes. These cells are responsible for scanning, filtering and processing of data and returning summarized results to Query Server
Query Server setup is handled by Jaguar – the Big Data SQL install utility. As part of the installation, update the installer configuration file – bds-config.json – to simply specify that you want to use Query Server and the host that it should be deployed to (that host should be a “gateway” server). Also, include the Hive databases that should synchronize with Query Server (here we’re specifying all):
{
“edgedb”: {
"node": “your-host.com",
"enabled": "true"
"sync_hive_db_list": "*"
}
}
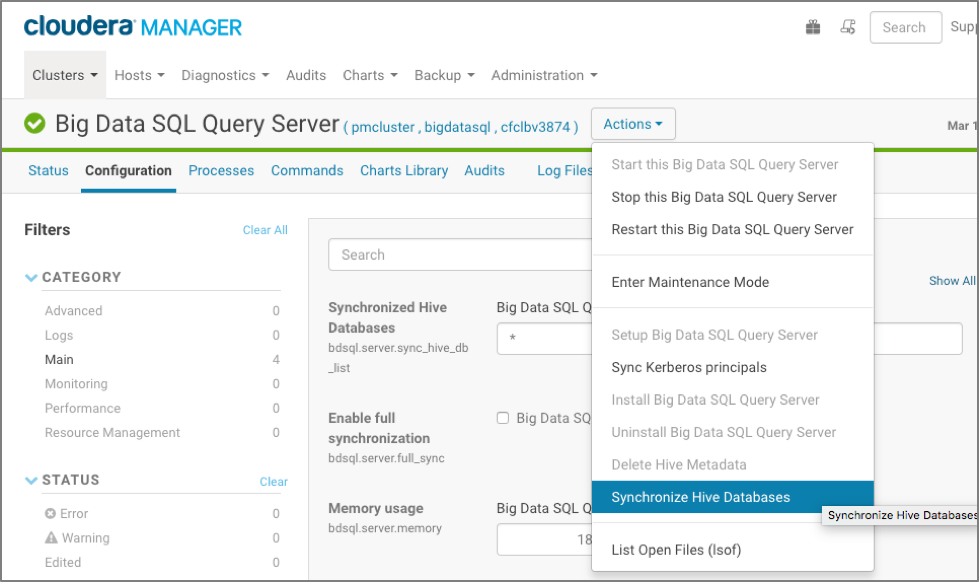
Jaguar will automatically detect the Hive source and the Hadoop cluster security configuration information and configure Query Server appropriately. Hive metadata will be synchronized with Query Server (either full metadata replacement or incremental updates) using the PL/SQL API (dbms_bdsqs.sync_hive_databases) or thru the cluster management framework (see picture of Cloudera Manager below):
For secure clusters, you will log into Query Server using Kerberos – just like you would access other Hadoop cluster services. Similar to Hive metadata, Kerberos principals can be synchronized thru your cluster admin tool (Cloudera Manager or Ambari), Jaguar (jaguar sync_principals) or PL/SQL (DBMS_BDSQS_ADMIN.ADD_KERBEROS_PRINCIPALS and DBMS_BDSQS_ADMIN.DROP_KERBEROS_PRINCIPALS).
Query Your Data
Once your Query Server is deployed, query your data using Oracle SQL. There is a bdsql user that is automatically created and data is accessible thru the bdsqlusr PDB.
sqlplus bdsql@bdsqlusr
You will see schemas defined for all your hive databases – and external tables within those schemas that map to your Hive tables. The full Oracle SQL language is available to you (queries – not inserts/updates/deletes). Authorization will leverage the underlying privileges set up on the Hadoop cluster; there are no authorization rules to replicate.
You can create new external tables using the Big Data SQL drivers:
- ORACLE_HIVE – to leverage tables using hive metadata (note, you probably don’t need to do this b/c the external tables are already available)
- ORACLE_HDFS – to create tables over HDFS data for which there is no hive metadata
- ORACLE_BIGDATA – to create tables over object store sources
Query Server provides a limited use Oracle Database license. This allows you to create external tables over sources – but not internal tables. Although there is nothing physically stopping the creation of tables – you will find that any internal table created will be deleted when the Query Server restarts.
This beauty of query server is that you get to use the powerful Oracle SQL language and mature Oracle Database optimizer. It means that your existing query applications will be able to use Query Server as they would any other Oracle Database. No need to change your queries to support a less rich query engine. Correlate near real-time Kafka data with information captured in your data lake. Apply advanced SQL functions like Pattern Matching and time series analyses to gain insights from all your data – and watch your insights and productivity soar :-).
