Apache Avro is a common data format in big data solutions. Now, these types of files are easily accessible to Oracle Autonomous Databases.
One of Avro’s key benefits is that it enables efficient data exchange between applications and services. Data storage is compact and efficient – and the file format itself supports schema evolution. It does this by including the schema within each file – with an explanation of the characteristics of each field.
In a previous post about Autonomous Data Warehouse and access parquet, we talked about using a utility called parquet-tools to review parquet files. A similar tool – avro-tools – is available for avro files. Using avro-tools, you can create avro files, extract the schema from a file, convert an avro file to json, and much more (check out the Apache Avro home for details).
A schema file is used to create the avro files. This schema file describes the fields, data types and default values. The schema becomes part of the generated avro file – which allows applications to read the file and understand its contents. Autonomous Database uses this schema to automate table creation. Similar to parquet sources, Autonomous Database will read the schema to create the columns with the appropriate Oracle Database data types. Avro files may include complex types – like arrays, structs, maps and more; Autonomous Database supports Avro files that contain Oracle data types.
Let’s take a look at an example. Below, we have a file – movie.avro – that contains information about movies (thanks to Wikipedia for providing info about the movies). We’ll use the avro-tools utility to extract the schema:
$ avro-tools getschema movie.avro
{
"type" : "record",
"name" : "Movie",
"namespace" : "oracle.avro",
"fields" : [ {
"name" : "movie_id",
"type" : "int",
"default" : 0
}, {
"name" : "title",
"type" : "string",
"default" : ""
}, {
"name" : "year",
"type" : "int",
"default" : 0
}, {
"name" : "budget",
"type" : "int",
"default" : 0
}, {
"name" : "gross",
"type" : "double",
"default" : 0
}, {
"name" : "plot_summary",
"type" : "string",
"default" : ""
} ]
}
The schema is in an easy to read JSON format. Here, we have movie_id, , title, year, budget, gross and plot_summary columns.
The data has been loaded into an Oracle Object Store bucket called movies. The process for making this data available to ADW is identical to the steps for parquet – so check out that post for details. At a high level, you will:
- Create a credential that is used to authorize access to the object store bucket
- Create an external table using dbms_cloud.create_external_table.
- Query the data!
1. Create the credential
begin DBMS_CLOUD.create_credential ( credential_name => 'OBJ_STORE_CRED', username => '<user>', password => '<password>' ) ; end; /
2. Create the table
begin
dbms_cloud.create_external_table (
table_name =>'movies_ext',
credential_name =>'OBJ_STORE_CRED',
file_uri_list =>'https://objectstorage.ca-toronto-1.oraclecloud.com/n/<tenancy>/b/<bucket>/o/*',
format => '{"type":"avro", "schema": "first"}'
);
end;
/
Things got a little easier when specifying the URI list. Instead of transforming the URI into a specific format, you can use the same path that is found in the OCI object browser:
Object Details -> URL Path (accessed from the OCI Console: Oracle Cloud -> Object Storage – “movies” bucket):
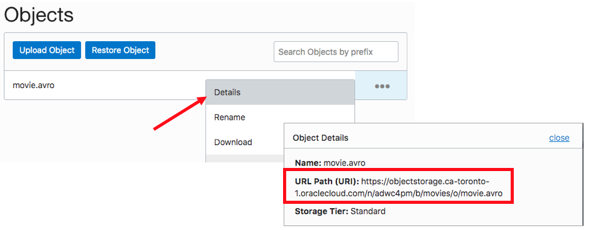
This URL Path was specified in the file-uri-list parameter – although a wildcard was used instead of the specific file name.
Now that the table is created, we can look at its description:
SQL> desc movies_ext Name Null? Type ------------ ----- -------------- MOVIE_ID NUMBER(10) TITLE VARCHAR2(4000) YEAR NUMBER(10) BUDGET NUMBER(10) GROSS BINARY_DOUBLE PLOT_SUMMARY VARCHAR2(4000)
And, run queries against that table:
SQL> select title, year, budget, plot_summary from movies_ext where title like 'High%';

All of this is very similar to parquet – especially from a usability standpoint. With both file formats, the metadata in the file is used to automate the creation of tables. However, there is a significant difference when it comes to processing the data. Parquet is a columnar format that has been optimized for queries. Column projection and predicate pushdown is used to enhance performance by minimizing the amount of data that is scanned and subsequently transferred from the object store to the database. The same is not true for Avro; the entire file will need to be scanned and processed. So, if you will be querying this data frequently – consider alternative storage options and use tools like dbms_cloud.copy_data to easily load the data into Autonomous Database.
