Parquet is a file format that is commonly used by the Hadoop ecosystem. Unlike CSV, which may be easy to generate but not necessarily efficient to process, parquet is really a “database” file type. Data is stored in compressed, columnar format and has been designed for efficient data access. It provides predicate pushdown (i.e. extract data based on a filter expression), column pruning and other optimizations.
Autonomous Database now supports querying and loading data from parquet files stored in object stores and takes advantage of these query optimizations. Let’s take a look at how to create a table over a parquet source and then show an example of a data access optimization – column pruning.
We’ll start with a parquet file that was generated from the ADW sample data used for tutorials (download here). This file was created using Hive on Oracle Big Data Cloud Service. To make it a little more interesting, a few other fields from the customer file were added (denormalizing data is fairly common with Hadoop and parquet).
Review the Parquet File
A CSV file can be read by any tool (including the human eye ) – whereas you need a little help with parquet. To see the structure of the file, you can use a tool to parse its contents. Here, we’ll use parquet-tools (I installed it on a Mac using brew – but it can also be installed from github):
$ parquet-tools schema sales_extended.parquet
message hive_schema {
optional int32 prod_id;
optional int32 cust_id;
optional binary time_id (UTF8);
optional int32 channel_id;
optional int32 promo_id;
optional int32 quantity_sold;
optional fixed_len_byte_array(5) amount_sold (DECIMAL(10,2));
optional binary gender (UTF8);
optional binary city (UTF8);
optional binary state_province (UTF8);
optional binary income_level (UTF8);
}
You can see the parquet file’s columns and data types, including prod_id, cust_id, income_level and more. To view the actual contents of the file, we’ll use another option to the parquet-tools utility:
$ parquet-tools head sales_extended.parquet prod_id = 13 cust_id = 987 time_id = 1998-01-10 channel_id = 3 promo_id = 999 quantity_sold = 1 amount_sold = 1232.16 gender = M city = Adelaide state_province = South Australia income_level = K: 250,000 - 299,999 prod_id = 13 cust_id = 1660 time_id = 1998-01-10 channel_id = 3 promo_id = 999 quantity_sold = 1 amount_sold = 1232.16 gender = M city = Dolores state_province = CO income_level = L: 300,000 and above prod_id = 13 cust_id = 1762 time_id = 1998-01-10 channel_id = 3 promo_id = 999 quantity_sold = 1 amount_sold = 1232.16 gender = M city = Cayuga state_province = ND income_level = F: 110,000 - 129,999
The output is truncated – but you can get a sense for the data contained in the file.
Create an ADW Table
We want to make this data available to our data warehouse. ADW makes it really easy to access parquet data stored in object stores using external tables. You don’t need to know the structure of the data (ADW will figure that out by examining the file) – only the location of the data and an auth token that provides access to the source. In this example, the data is stored in an Oracle Cloud Infrastructure Object Store bucket called “tutorial_load_adw”:
Using the DBMS_CLOUD package, we will first create a credential using an auth token that has access to the data:
begin DBMS_CLOUD.create_credential ( credential_name => 'OBJ_STORE_CRED', username => user@oracle.com', password => 'the-password' ) ; end; /
Next, create the external table. Notice, you don’t need to know anything about the structure of the data. Simply point to the file, and ADW will examine its properties and automatically derive the schema:
begin
dbms_cloud.create_external_table (
table_name =>'sales_extended_ext',
credential_name =>'OBJ_STORE_CRED',
file_uri_list =>'https://swiftobjectstorage.<datacenter>.oraclecloud.com/v1/<obj-store-namespace>/<bucket>/sales_extended.parquet',
format => '{"type":"parquet", "schema": "first"}'
);
end;
/
A couple of things to be aware of. First, the URI for the file needs to follow a specific format – and this is well documented here (dbms_cloud ADB documentation ). Here, we’re pointing to a particular file. But, you can also use wildcards (“*” and “?”) or simply list the files using comma separated values.
Second, notice the format parameter. Specify the type of file is “parquet”. Then, you can instruct ADW how to derive the schema (columns and their data types): 1) analyze the schema of the first parquet file that ADW finds in the file_uri_list or 2) analyze all the schemas for all the parquet files found in the file_uri_list. Because these are simply files captured in an object store – there is no guarantee that each file’s metadata is exactly the same. “File1” may contain a field called “address” – while “File2” may be missing that field. Examining each file to derive the columns is a bit more expensive (but it is only run one time) – but may be required if the first file does not contain all the required fields.
The data is now available for query:
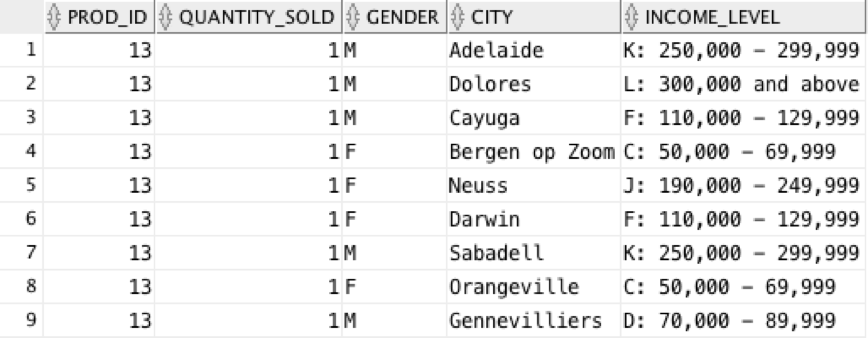
desc sales_extended_ext; Name Null? Type -------------- ----- -------------- PROD_ID NUMBER(10) CUST_ID NUMBER(10) TIME_ID VARCHAR2(4000) CHANNEL_ID NUMBER(10) PROMO_ID NUMBER(10) QUANTITY_SOLD NUMBER(10) AMOUNT_SOLD NUMBER(10,2) GENDER VARCHAR2(4000) CITY VARCHAR2(4000) STATE_PROVINCE VARCHAR2(4000) INCOME_LEVEL VARCHAR2(4000) select prod_id, quantity_sold, gender, city, income_level from sales_extended_ext where rownum < 10;
Query Optimizations with Parquet Files
As mentioned at the beginning of this post, parquet files support column pruning and predicate pushdown. This can drastically reduce the amount of data that is scanned and returned by a query and improve query performance. Let’s take a look at an example of column pruning. This file has 11 columns – but imagine there were 911 columns instead and you were interested in querying only one. Instead of scanning and returning all 911 columns in the file – column pruning will only process the single column that was selected by the query.
Here, we’ll query similar data – one file is delimited text while the other is parquet (interestingly, the parquet file is a superset of the text file – yet is one-fourth the size due to compression). We will vary the number of columns used for each query:
- Query a single parquet column
- Query all parquet columns
- Query a single text column
- Query all the text columns

The above table was captured from the ADW Monitored SQL Activity page. Notice that the I/O bytes for text remains unchanged – regardless of the number of columns processed. The parquet queries on the other hand process the columnar source efficiently – only retrieving the columns that were requested by the query. As a result, the parquet query eliminated nearly 80% of the data stored in the file. Predicate pushdown can have similar results with large data sets – filtering the data returned by the query.
We know that people will want to query this data frequently and will require optimized access. After examining the data, we now know it looks good and will load it into a table using another DBMS_CLOUD procedure – COPY_DATA. First, create the table and load it from the source:
CREATE TABLE SALES_EXTENDED
( PROD_ID NUMBER,
CUST_ID NUMBER,
TIME_ID VARCHAR2(30),
CHANNEL_ID NUMBER,
PROMO_ID NUMBER,
QUANTITY_SOLD NUMBER(10,0),
AMOUNT_SOLD NUMBER(10,2),
GENDER VARCHAR2(1),
CITY VARCHAR2(30),
STATE_PROVINCE VARCHAR2(40),
INCOME_LEVEL VARCHAR2(30)
);
-- Load data
begin
dbms_cloud.copy_data(
table_name => SALES_EXTENDED',
credential_name =>'OBJ_STORE_CRED',
file_uri_list =>'https://swiftobjectstorage.<datacenter>.oraclecloud.com/v1/<obj-store-namespace>/<bucket>/sales_extended.parquet',
format => '{"type":"parquet", "schema": "first"}'
);
end;
/
The data has now been loaded. There is no mapping between source and target columns required; the procedure will do a column name match. If a match is not found, the column will be ignored.
That’s it! ADW can now access the data directly from the object store – providing people the ability to access data as soon as it lands – and then for optimized access load it into the database.
