Introduction
Oracle Autonomous Database provides everyting you need to quickly, easily, and securely export data from instance and load it into another via Oracle Cloud Infrastructure Object Store. In this post I will walk through an example, using using the database’s built-in capabilities to export data to cloud stores and ADW’s Data Studio tools to load from cloud stores. It’s a very simple process:
- Export data from a query using DBMS_CLOUD.EXPORT_DATA.
- In Data Studio, create a Cloud Store Location that saves this location along with the credentials needed to access the data (if any).
- Create and run a data load job.
Oracle Autonomous Database includes a great collection of tools that can be used to load a wide range of file types from various locations. If you would like an overview, please read my blog post Data Loading Make Easy in Oracle Autonomous Database.
About EXPORT_DATA and Data Studio Data Load Tools
EXPORT_DATA and Data Studio Data Load tool are both included with Autonomous Database. They provide easy and effective means of exporting data to cloud object stores, and accessing that data to create and load tables in Autonomous Datatabase.
DBMS_CLOUD.EXPORT_DATA
The EXPORT_DATA procedure is a simple and efficient method of exporting data from an Oracle table or view to cloud based object storage, such as Oracle Cloud Infrastructure (OCI) Object Store. EXPORT_DATA can export to a variety of formats including CSV, JSON, and XML, and can export to gzip compressed files.
While there are plenty to options to explore, the important characteristics of EXPORT_DATA for this discussion are that it:
- Exports data from a query, allowing you to customize the content of an export.
- Exports using parallel processes to multi-part files. That is, data from each query is exported to multiple files that in aggregate make up one logical file. This allows EXPORT_DATA to run very quickly using multiple processes in parallel.
The corresponding DBMS_CLOUD data loading procedures are able to easily load data from multi-part files using URIs with wildcards.
Data Studio Data Load Tool
Data Studio provides a suite of tools that help you create and load data into tables in the Autonmous Datadata. You can:
- Create and load tables from CSV, Excel and JSON files on your local computer.
- Create Cloud Locations that register Oracle, Amazon S3, Google, and Azure cloud stores.
- Create tables and load CSV, JSON, Parquet, and Avro data files from cloud stores.
- Create external tables that connect to cloud stores for dynamic access to data.
The Data Studio Data Load tools use DBMS_CLOUD to load and connect to data on cloud stores.
Sample Data Used in this Post
For this post, I’ve used Movie Sales Data from the Oracle LiveLabs workshop Load and update Moviestream data in Oracle ADW using Data Tools. I imported the data into a table using methods described in the lab and then exported the data to a bucket on the object store using DBMS_CLOUD.EXPORT_DATA.
Exporting Data to Object Store
Like the original data used by the LiveLab, I export data for each month separately. But unlike the LiveLab where each month is exported to a single file, I used EXPORT_DATA to export each month to a seperate folders containing multi-part files.
I exported using a pre-authenticated request (PAR) with write permission to the bucket, using a prefix. A PAR includes an embedded password, eliminating the need to use a database credential.
An example follows:
BEGIN
dbms_cloud.export_data (
file_uri_list => 'https://objectstorage.uk-london-1.oraclecloud.com/p/dgfs$%C$%S/n/adwc4pm/b/data_library/o/d1705/table=MOVIE_SALES_FACT/partition=APR-2019/APR-2019',
format => '{"type":"CSV","delimiter":",","maxfilesize":536870912,"header":true,"compression":null,"escape":"true","quote":"\""}',
query => 'select * from MOVIE_SALES_FACT WHERE MONTH = ''APR-2019''');
END;
/
Note that you must have EXECUTE priviledge on DBMS_CLOUD to export data.
Data is exported to the movie_sales folder in my data_library bucket. Because I might export multiple tables to this folder, I export this table to the table=MOVIE_SALES_FACT subfolder. Each month is exported to a partition= folder. I use that naming convention to make it easy to understand what tables the files belong to and the content of each individual file. This works out well because the folder structure is self-documenting.
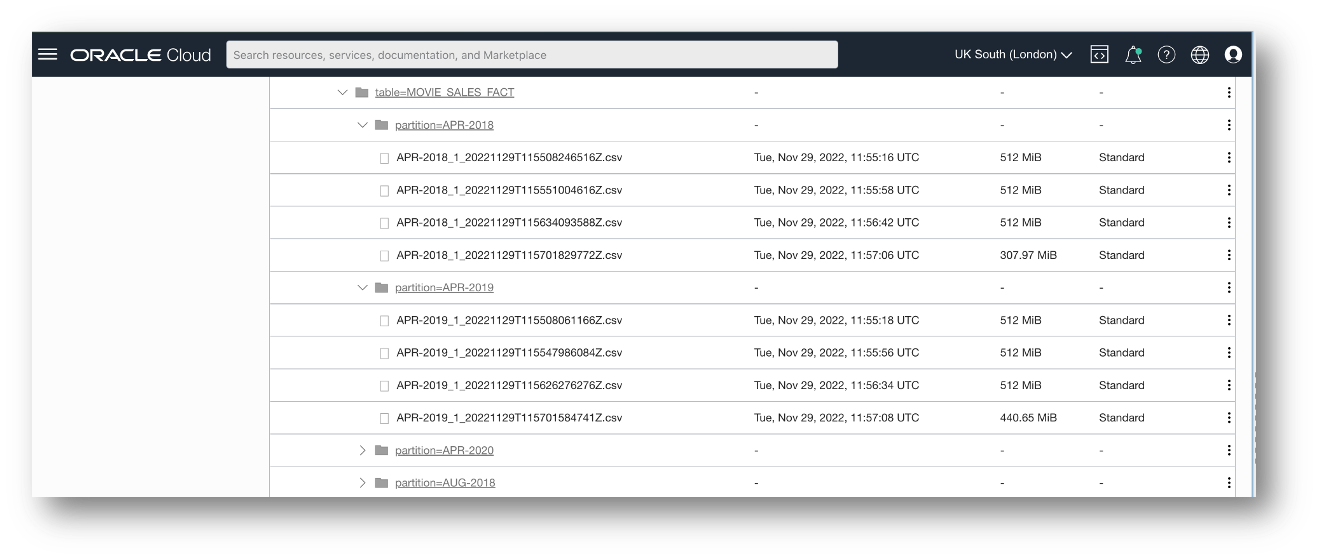
As I mentioned earlier, DBMS_CLOUD.EXPORT_DATA can export queries to multi-part files. There are two advantages to this.
- Queries can be export to files more quickly using parallel processes.
- Each process uses less memory, it less likely to have to wait for available resources to run.
There can be a trade-off between export performance and data loading. Larger tables, with more rows and more columns, might export more quickly when a larger number of smaller files are created, due to increased parallelism and lower memory use for each file. Data loading, however, is typically more efficient when there are a smaller number of files. Some experimentation might be needed to achieve the right balance for your use case.
The smaller the MAXFILESIZE parameter is set to, the more files will be created.. The smallest MAXFILESIZE is 10MB, which is the default value. Note also that the largest MAXFILESIZE is 2GB. The HIGH resource consumer group will usually result in greater parallelisim and a larger number of smaller files.
In my example using the MovieStream SALES_FACT table, the EXPORT_DATA created a total of 5,765 files over the 35 exports (again, one for each month) using the default MAXFILESIZE of 10MB. When MAXFILESIZE was increased to 512MB, the export produced 132 files. Data loading with the smaller number of files was significantly faster, and since the MOVIE_SALES_FACT table is not very large, there was little difference in performance when exporting to a smaller number of large files, as opposed to a large number of small ones.
Creating a New Table and Loading Data
If you don’t have the right tool for the job, you could be correct in thinking that this set of multi-part files will be difficult to load. But with the Data Studio’s Data Load tool it is very easy.
Step 1 – Create a Cloud Location
A Cloud Location is an object created by Data Studio’s Data Load tool. It allows you to save the URL, and if needed, credentials needed to access the URL. I will use a pre-authenticated request, so I will not need a credential.
I could have skipped this step and just pasted the file URL into the Data Load from Cloud Store dialog. Creating the Cloud Location has the advantage of reusability.
First, access the Data Load tools in Data Studio and select the Cloud Locations card.

And choose Add Cloud Store Location.

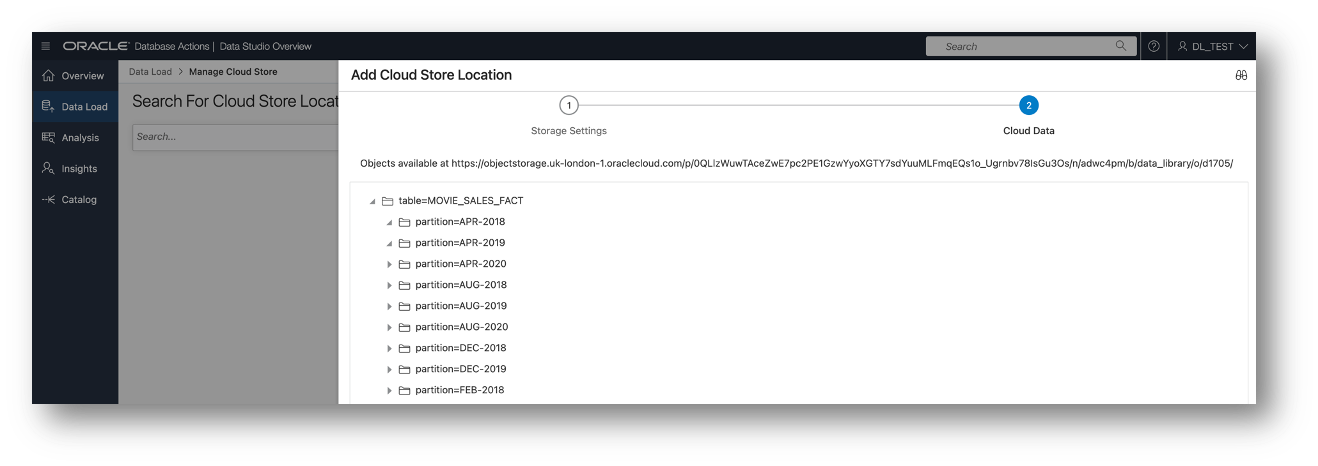
Provide a name for the Cloud Store Location, a description, and the Bucket URI, and choose Public Bucket. Choose Public Bucket for both public buckets and pre-authenticated requests, since neither requires a credential. Then press the Next button.

The tool validates the URI and displays files in the bucket.
Fun facts:
- Pre-authenticated requests have expiration dates. By the time you read this post, this pre-authenticated request will have expired. My data is safe and secure!
- Folders in object store aren’t folders in the same way as you think of them on a PC or Mac OS file system. Folders are just part of the file name. Different tools will display them differently.
Press the Create button to finish the process of creating a Cloud Store Location.
And now we have a new, reusable Cloud Store Location.
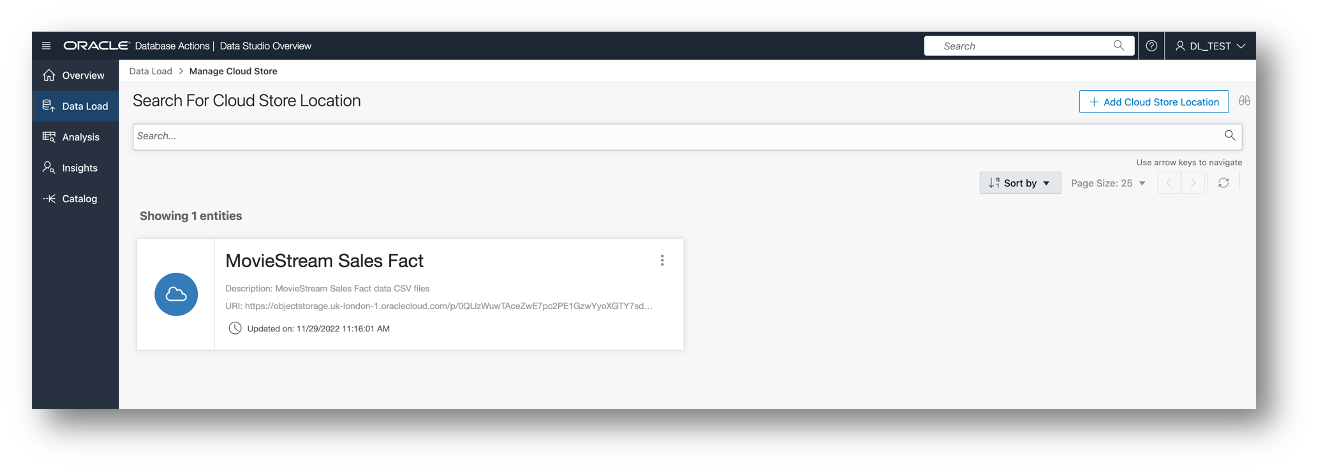
Step 2 – Create a Data Load Job
Steps 1 was easy but surely this will be the hard part, right? All those files in all those folders? No worries, this will be easy also.
Go back to Database Actions (click it at the top) and choose the Data Load card. This time, continue by choosing Load Data, Cloud Store and Next.
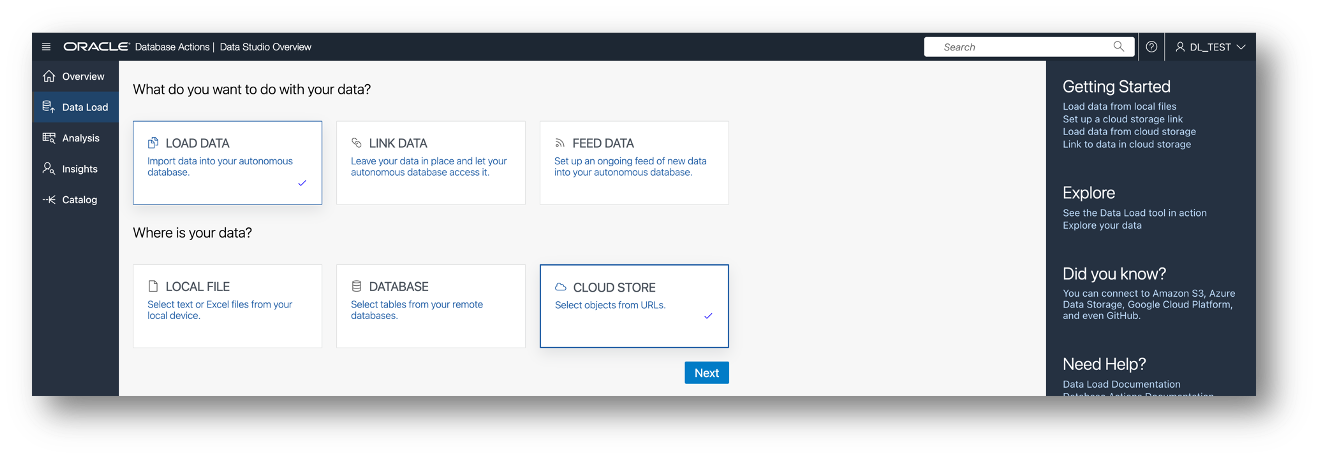
Choose your Cloud Store Location at the top of the screen. The tool will display the content of the cloud store in the navigator tree.
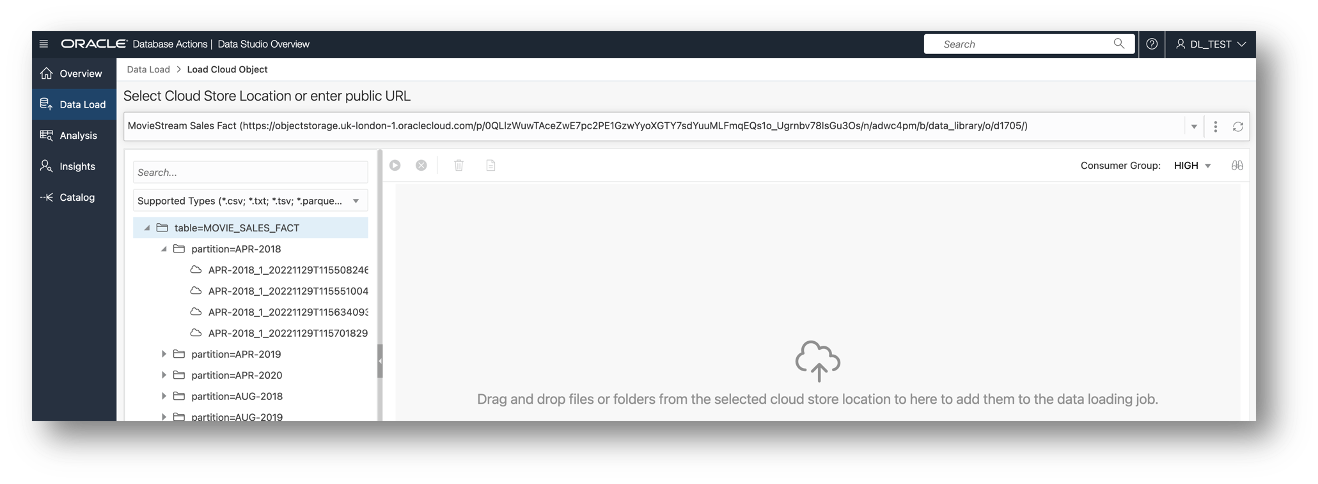
Because I’ve set up the bucket with the top-level folder being for the table MOVIE_SALES_FACT (and thus all the subfolders being data for that table), all I need to do is drag the top-level folder into the ‘cart’ area.
By dragging that folder into the cart area, I’m telling the tool that that these files all belong to the same table. It is very important is that the files within this folder all belong to that table and all have the same format.

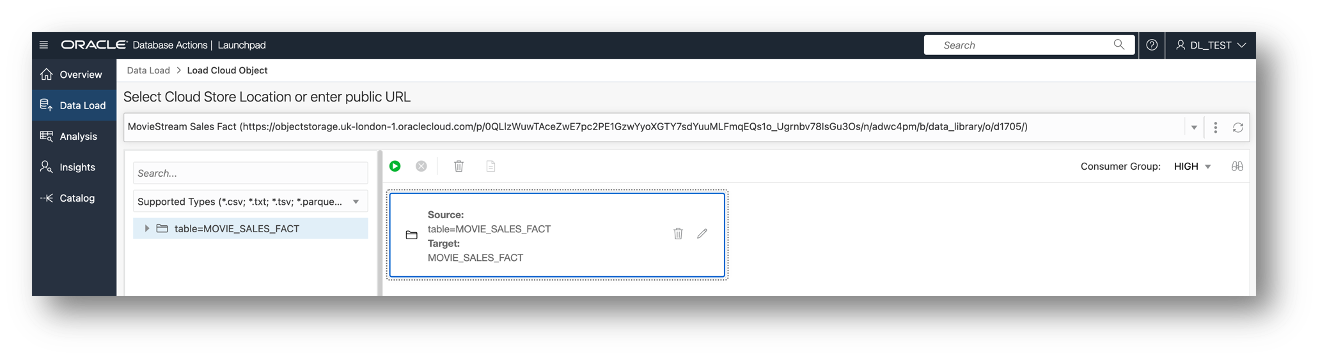
Click on the pencil in the cart to see how the job is set up. You can see that the Data Load tool does a great job at setting up the data load job.

The default action is to create a new table. It uses the selected folder as the table name. I will change the table name to MOVIE_SALES_FACT. I could partition the table by range or list, but I’m not going do that now.
Where the tool really shines is the inspection of the data files and default column mappings. The files have headers, so they are used as the column names.
Pro tip: Easy data loading starts with headers in the export file. DBMS_CLOUD.EXPORT_DATA uses the column names in the query as column headers in the files, making it very easy to provide good names. Simple, unquoted column names and headers are usually the easiest to work.
The Data Load tool has chosen the correct data types for all the columns. Auto has been selected for VARCHAR2 columns. The data loader tool will automatically adjust the column length to a safe size after the data is loaded.
You can choose the File tab on the left to preview data in a file. One file is selected by default. You can choose other files in the drop-down list.

The table does not exist yet, so skip the Table tab. You can view the SQL that will be used to create the table and run the job.

You can copy/paste this into SQL Worksheet and run the SQL as is. In this case, I’ll let the tool run it for me. I’ll close this and run the job by smashing the green button just above the cart. I want the job to run as quickly as possible so I will use the HIGH consumer group, providing the job with the most resources possible.
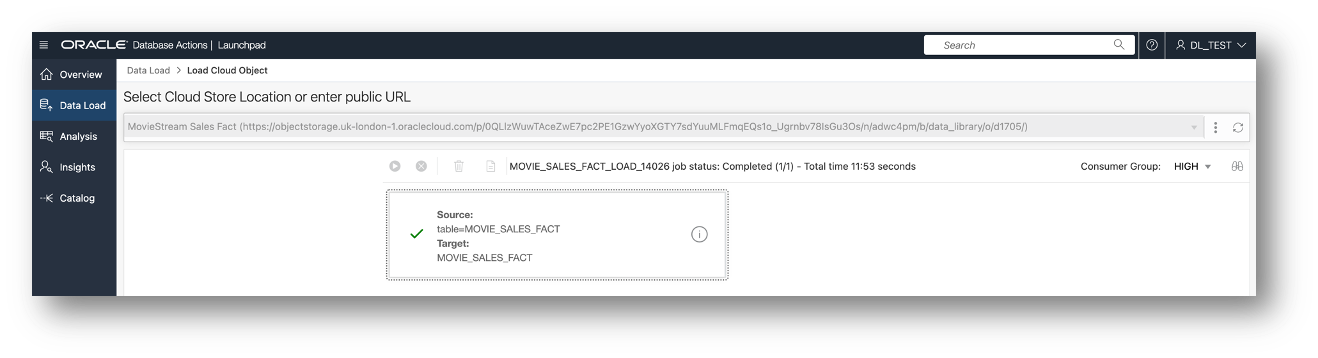
The green check box indicates the job is complete without errors. The length of time it will take on your instance will depend on the available resources and the location of your instances in relation to the bucket. The best performance will be observed when the database and bucket are in the same region.
Cloud Store Location Shortcut
You can combine creating the Cloud Store Location and setting up the data load job into a single step, if credentials are not required, by pasting the URL of the top-level folder into the URL field. From this point on the process is the same. Just drag the folder into the cart area and continue the load process.
Summary
There are many different methods that can be used for loading data from cloud stores into Oracle Autonomous Database. Data Studio’s Data Load tool will likely be the easiest method. It’s all GUI, with no coding. File inspection and automatic data type detection are very effective. The Data Load tool supports a variety of formats (CSV/Text, JSON, Parquet, and Avro) from a variety of locations (Oracle Cloud Store, Amazon S3, and others). And it’s all based on the DBMS_CLOUD package, so it provides great performance.
Learn More About Oracle Autonomous Database
Learn more about Oracle Autonomous Database and its built-in Data Studio at Oracle.com.
Try for Yourself Using LiveLabs
Give the data loading tools a try for yourself by running the Load and Update MoviesStream Data in Oracle ADW using Data Tools workshop.
Watch the Data Loading Tools in Action
Watch my 20 minute Data Loading Deep Dive on YouTube.
