We have a mission here at Oracle to add a set of useful built-in tools to the Autonomous Database, to improve the productivity of the various users who interact with it.
These tools provide easy ways to load your data into the database, begin analyzing your data and build powerful Analytic Views, and to gain immediate data insights.
Underpinning all these tools is the catalog. The catalog shines a light on the contents of your autonomous database and its connected assets, providing an easily searchable inventory of all the objects in, or accessible from, your database, including schemas, tables, views, columns, analytic views, packages and procedures, files on cloud object storage, and much more.
In this post, we’re going to take a look at the catalog and how it can be used to understand your data.
Accessing the catalog
To access the catalog and all the other built-in tools for the first time, click the Database Actions link for your autonomous database from the OCI Console:
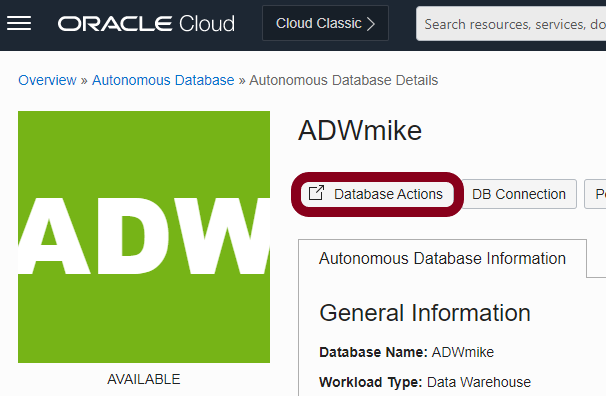
It is a good idea to bookmark this location as it provides access to all the built-in tools for the database.
After logging in as any valid database user, the Database Actions page appears. The catalog can be found under Data Tools on the right hand side of the page:
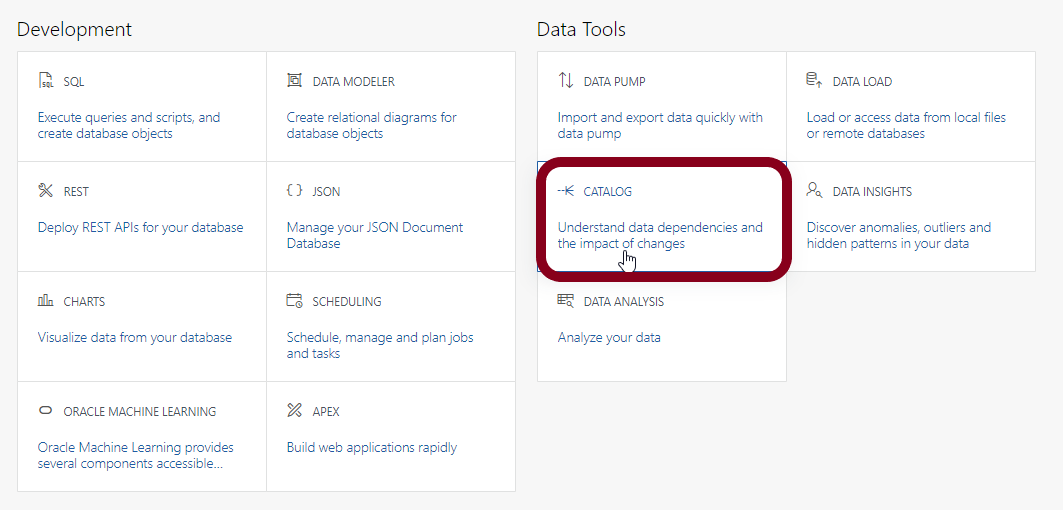
Searching the catalog
The default view of the catalog is of recently updated objects, but we can use the search bar to find a lot more.
We can simply type into the search bar, just as you would use any other search engine. For example, we can find all objects containing the string ‘cust’ to find objects related to customers:
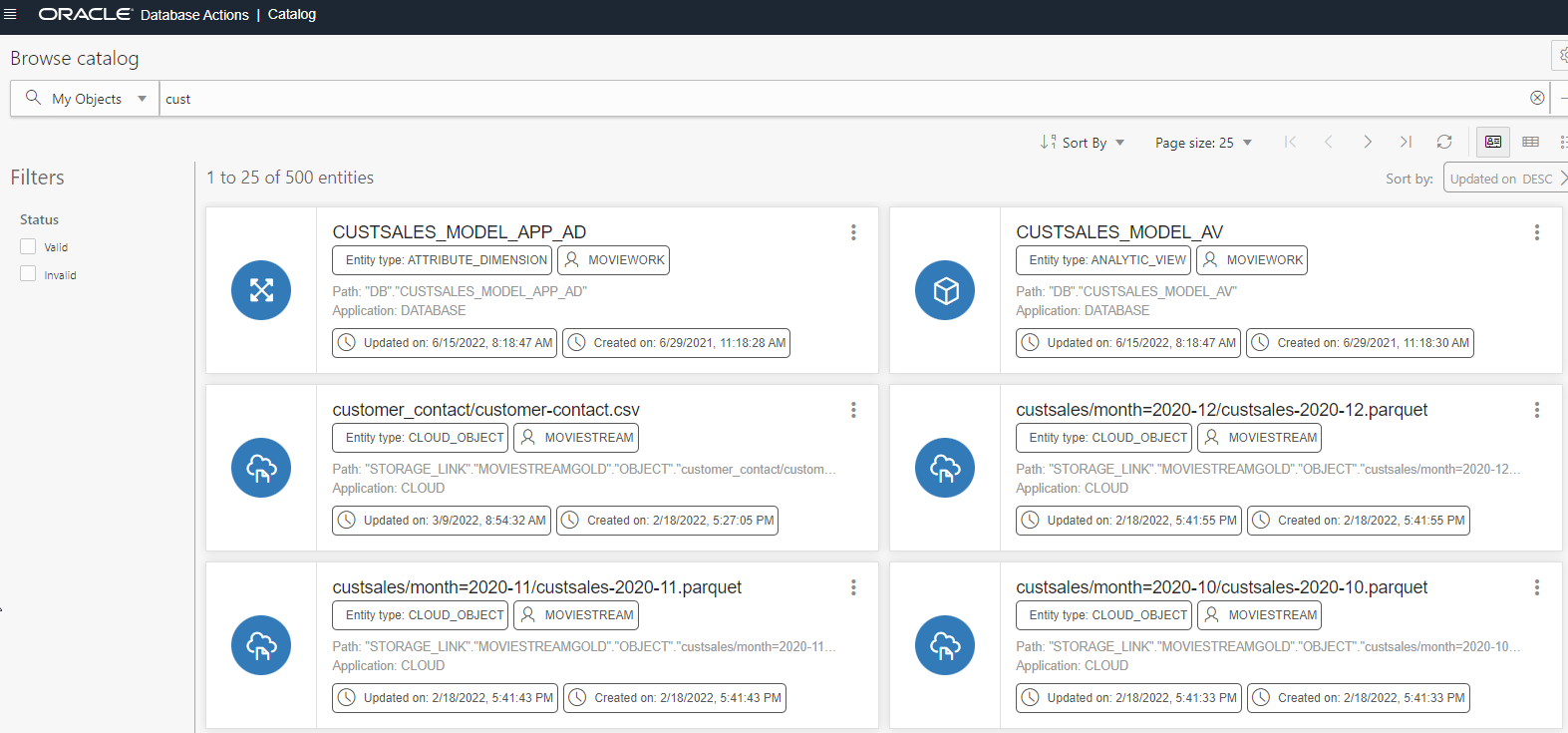
You will notice we do not just see tables and views in the results. The icon on the left of each object in the search results denotes the object type. In the screenshot above, we have an Attribute Dimension of an Analytic View (CUSTSALES_MODEL_APP_AD), the Analytic View itself (CUSTSALES_MODEL_AV), and a number of parquet files in a ‘custsales’ folder on cloud object storage. These files are shown because the database has a cloud storage link set up, so these files are available for us to load into the database, or link to and query from the database.
Refining a search
As we can see, the Catalog search can encompass all objects either resident in, or reachable from, the database, including those in a ‘data lake’ on cloud object storage. This may be many thousands of objects, so we might want to refine our search a little. We can learn how the search works using the type-ahead capabilities including in it. For example, to see all the different objects that may be returned by a search, we can just enter ‘type:’ into the search box and scroll down a little to see a list of all the searchable entity types, and their object icons:
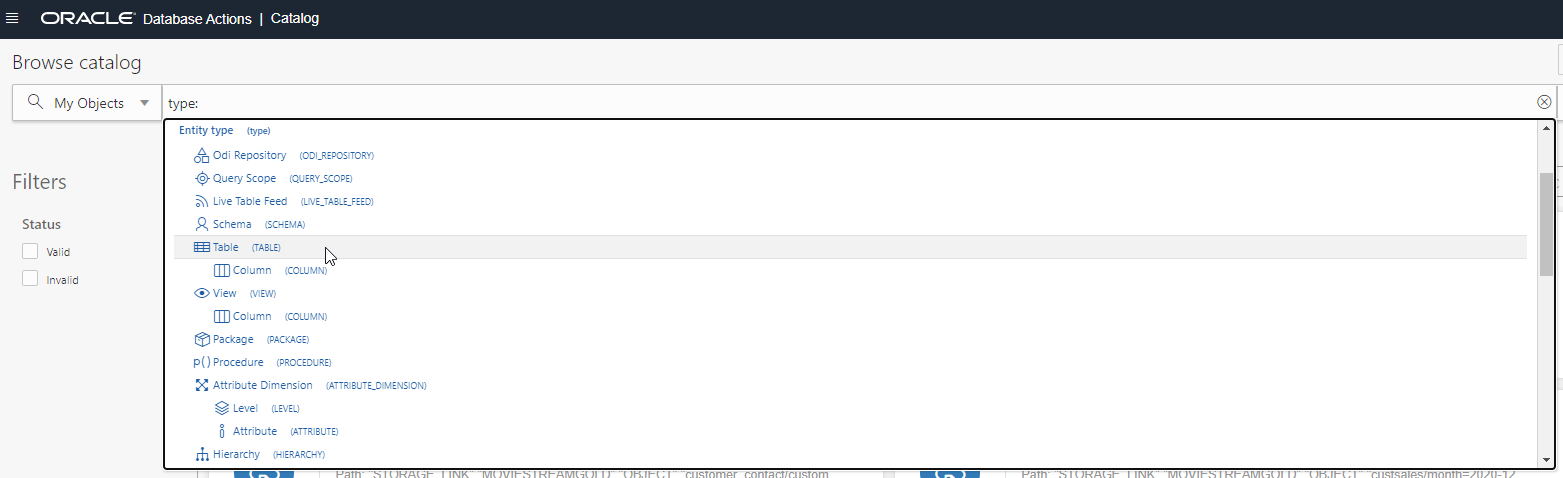
We can then use this to work out how to refine a search. For example, to refine our search on ‘cust’ to return only tables, views and columns containing the string ‘cust’, we can search using ‘type:TABLE,VIEW,COLUMN AND cust’:
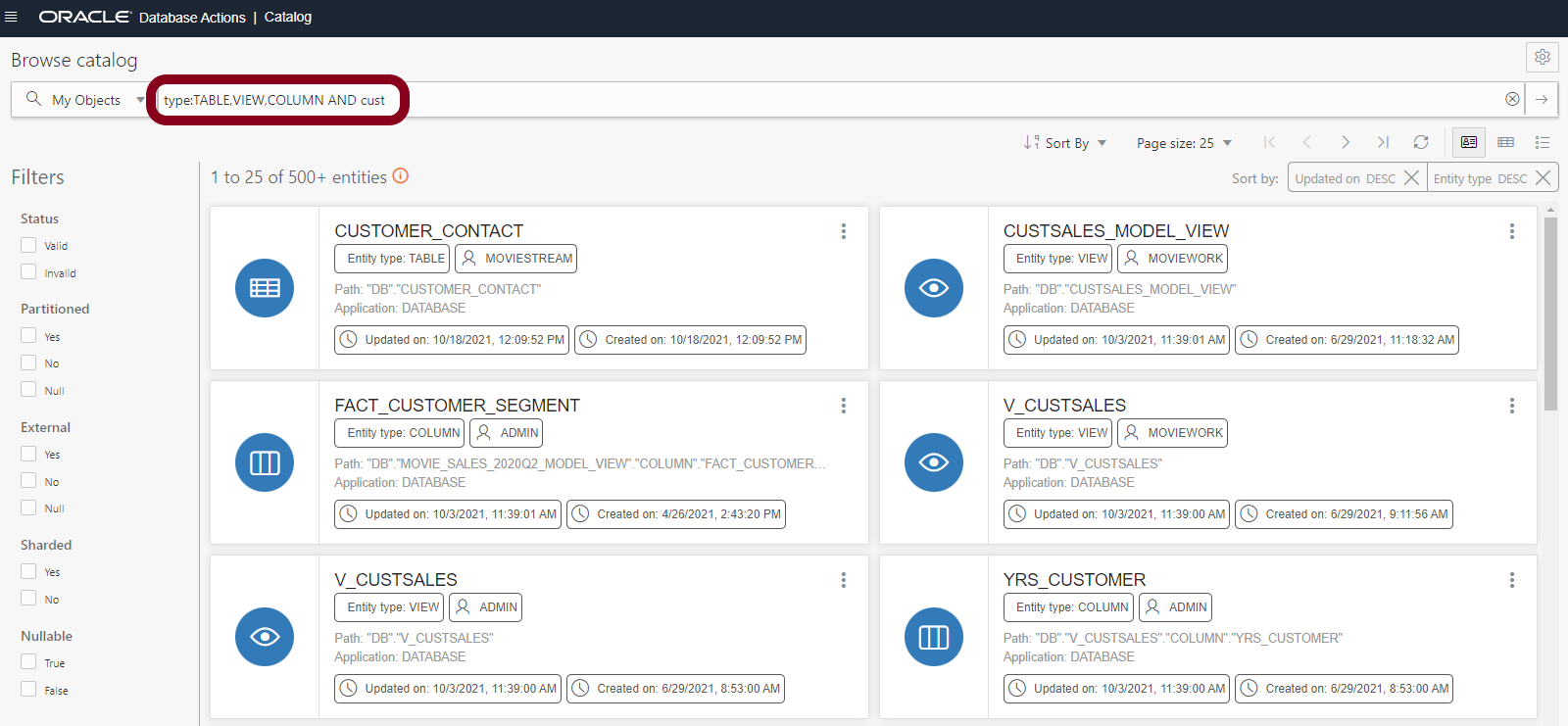
There are many other search options. Try out the sample searches on the right hand side to learn more about the search syntax.
Understanding your data
The catalog includes capabilities to help you understand the contents of your data, where the data came from, and where it is used in downstream processing. This understanding is important for many reasons. For example, if you have just loaded some new data into your data warehouse, and you want to use that data in some analytics or data science processes, it is a good idea to check the catalog first, in order to understand the characteristics of the data you have just loaded. You may find that it does not meet all the requirements you have of it, and you may therefore need to prepare the data using Data Transforms or other tools.
You also might be interested in how a set of data that you find in the catalog arrived into the database – for example how it was loaded – and also how it is used in downstream processing, such as in analytic views.
Let’s start by checking over some of the key characteristics of some data we have just loaded into the database.
In this case, we are going to use a table loaded by the ‘Load and update Moviestream data in Oracle ADW using Data Tools Workshop’ on Oracle Live Labs. This loads data from a public bucket of data so you can try this yourself – see Lab 2 of the workshop for the steps to do this. However, these steps are the same for any table.
First, find a table (MOVIE_SALES_FACT in this case) in the catalog by name, and click on it.
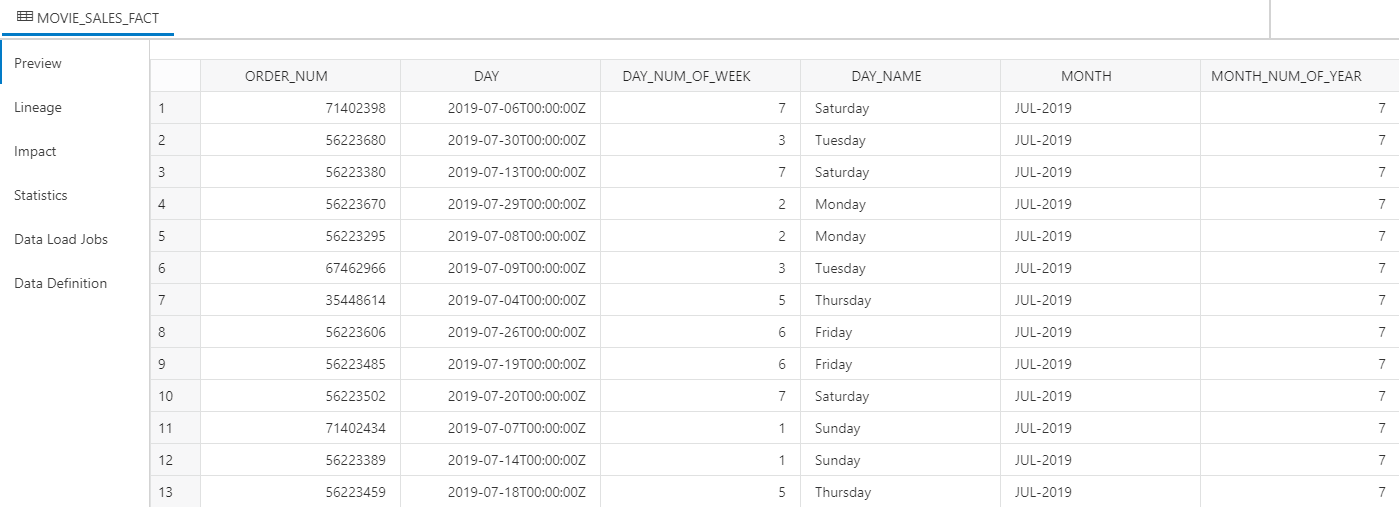
The Preview pane appears, allowing you to sense check that the data appears to have been loaded correctly:
To check the number of rows loaded, and to understand the ranges of the data, switch to the Statistics view:
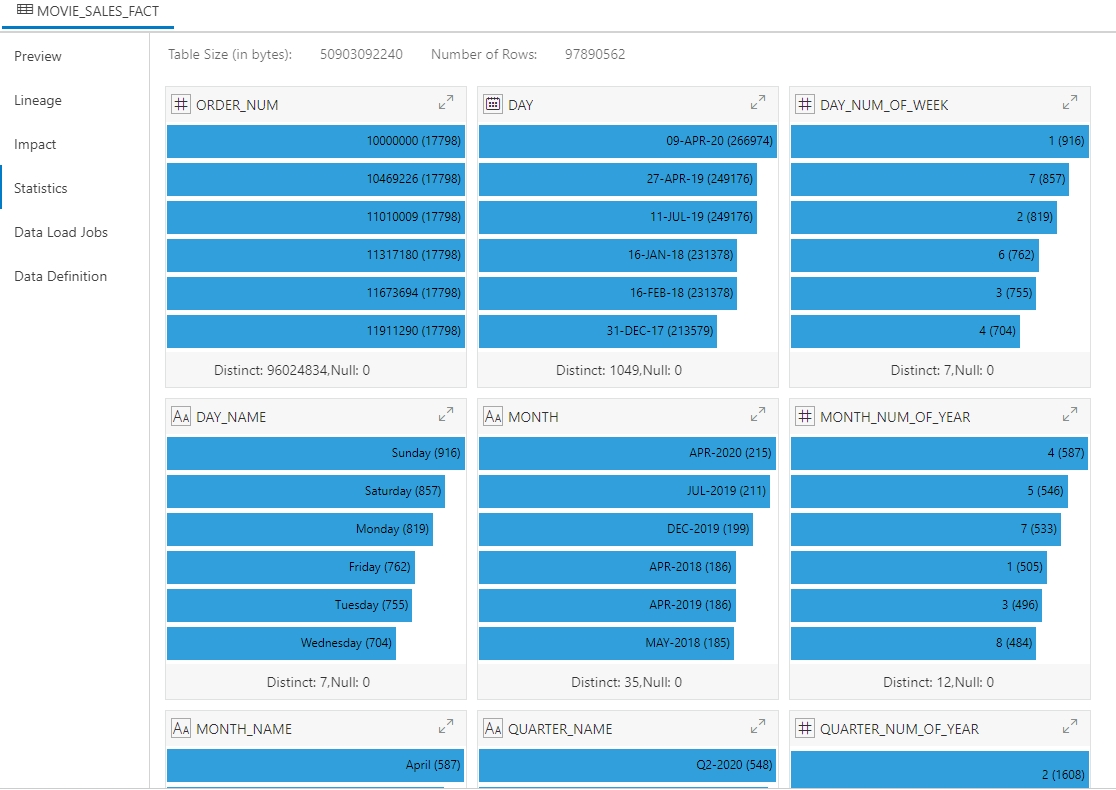
This view is really useful. We can check that the number of rows loaded is the number we expected, and we can look for any data quality issues around completeness, uniqueness, and the correctness of values.
For example, in the data above, we have DAY_NUM_OF_WEEK and DAY_NAME columns, both with 7 distinct values (the days of the week), and we can see that the frequency of occurrence of each value corresponds correctly, e.g. day 1 is Sunday and occurs 916 times, day 7 is Saturday and occurs 857 times, and so on.
Where did that data come from?
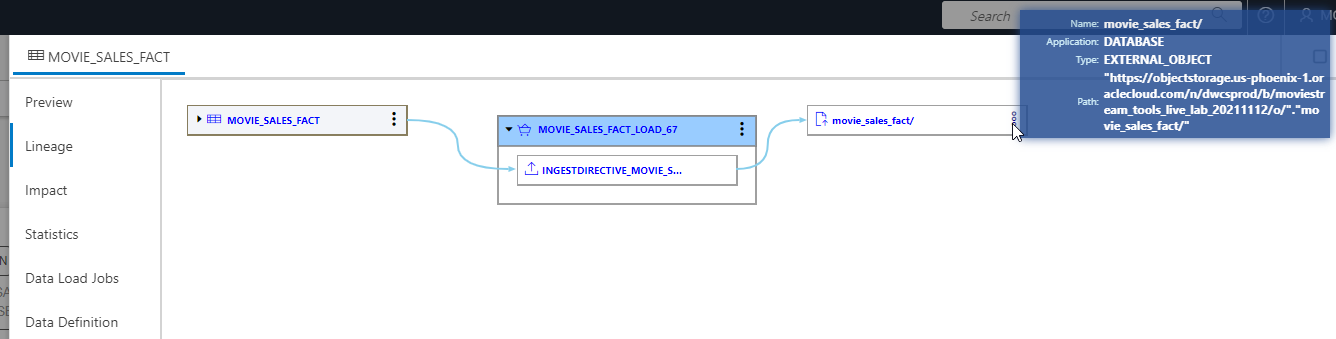
We just loaded this MOVIE_SALES_FACT table, so chances are we can remember where it comes from – a folder in a bucket on Oracle Cloud Infrastructure object storage. But imagine another user finding this data in the catalog. For them it could be essential to know the origins of the data in the table. To see this, click the Lineage option. This shows the table on the left with the data load job that loaded it in the middle, and the folder of files in connected cloud storage on the right hand side. If I hover over that folder, I can see the exact URL where the files came from.
Where is that data going?
For the most efficient and consistent data analysis, the autonomous database can construct analytic views over base tables. Analytic views provide a prepared and performance-optimized way of querying data using simple SQL, with dimension hierarchies, measures and calculations that are prepared by and run in the database, so that they will always be consistent, regardless of your choice of analytics application.
The Data Analysis tool of the database can be used to construct such views, but importantly, the catalog is aware of how the views are created.
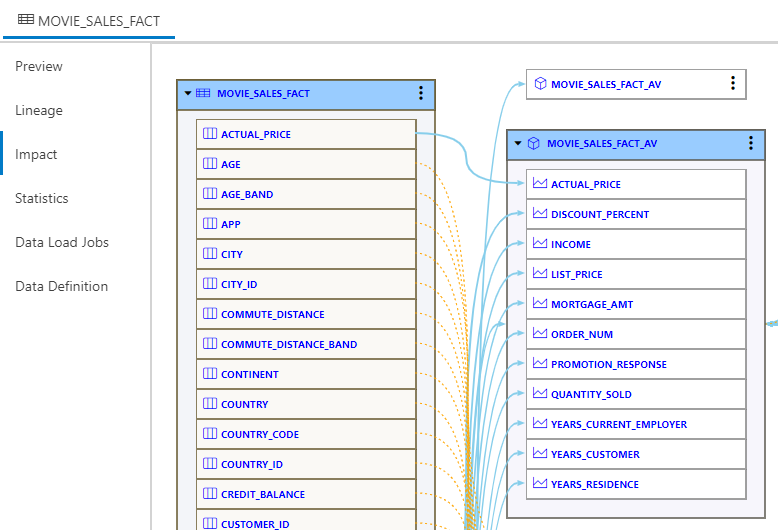
If I construct an analytic view from the MOVIE_SALES_FACT table, I can then use the Impact view of the catalog to understand the use of columns in the view, and that a change to this table may impact its use in downstream processing:
What about the OCI Data Catalog?
The autonomous database’s catalog provides an inventory of assets in, or connected to, a single autonomous database.
The OCI Data Catalog provides a broader view of data assets in the Oracle cloud and beyond. It harvests metadata from a range of connected systems, including Oracle and non-Oracle databases, files on object storage, message streams and more.
Look out for an update in the near future that will allow you to connect the OCI Data Catalog to your autonomous database so that you can find files and other assets that the OCI Data Catalog already knows about, and load or link them into the autonomous database.
Conclusion
The autonomous database catalog provides an ideal accompaniment to an enterprise data lake or data warehouse that is centred on the autonomous database, providing a richer and broader inventory of data assets than the data dictionary. Use it to discover new data sets, understand their contents and where they come from, and as a starting point for data preparation and analysis.
Learn More
To learn more about the autonomous database’s built-in tools, take a look at the documentation, or try out one of the following live labs:
Important tools for anyone using the autonomous database
Load and update Moviestream data in Oracle ADW using Data Tools
