Autonomous Database Serverless – like all other versions and editions of Oracle Database – has a built-in text search engine, Oracle Text. This is a really powerful feature of the converged database, that people often don’t even realize they have. Want to find a mis-spelled company name? Want to find all comments in a work log that mention ‘failure’ and ‘hardware’? No problem, Oracle Text can do that – and lots more.
You can easily create text indexes on VARCHAR2, CLOB or BLOB columns in the database, and search them using word-based content searches.
Let’s look at a simple, basic example:
create table pangrams (tdata varchar2(80));
insert into pangrams values ('The quick brown fox jumps over the lazy dog');
insert into pangrams values ('Bright vixens jump; dozy fowl quack');
create index pangidx on pangrams(tdata) indextype is ctxsys.context;
select * from pangrams where contains(tdata, 'jump%') > 0;
The ‘jump%’ in our query matches the indexed words ‘jump’ and ‘jumps’, so both rows are returned.
(in case you’re interested, a pangram is a phrase that uses all the letters of the alphabet).
Great – that’s really useful for content searching on text within the database. But what if our data is actually in files on Object Storage, rather than in the database itself? If only Oracle Text could manage to index files as well as just text in the database…
Well, it can do that too! Oracle Text is almost infinitely extendable, and you can plug in your own code at many points. It’s possible to write a “user datastore” procedure that can access files in object storage. But now, we’ve made that much easier for you with a new DBMS_CLOUD procedure, CREATE_EXTERNAL_TEXT_INDEX. We just need to provide a URI for an Object Storage bucket, and it will traverse all the files in that bucket and index the contents of each file. At a preset interval (the default is five minutes) it will check the bucket for new, updated, or deleted files and index, reindex or remove those files as appropriate.
Let’s look at how we do that. If you already have files in Object Storage and a credential to access them, you can skip the next couple of sections and jump straight to Creating the External Text Index.
Adding files to object storage
First we need to create a bucket (akin to a directory) to store our files.
In the OCI Control Panel, from the main menu choose Storage, then under the heading Object Storage and Archive Storage, choose Buckets
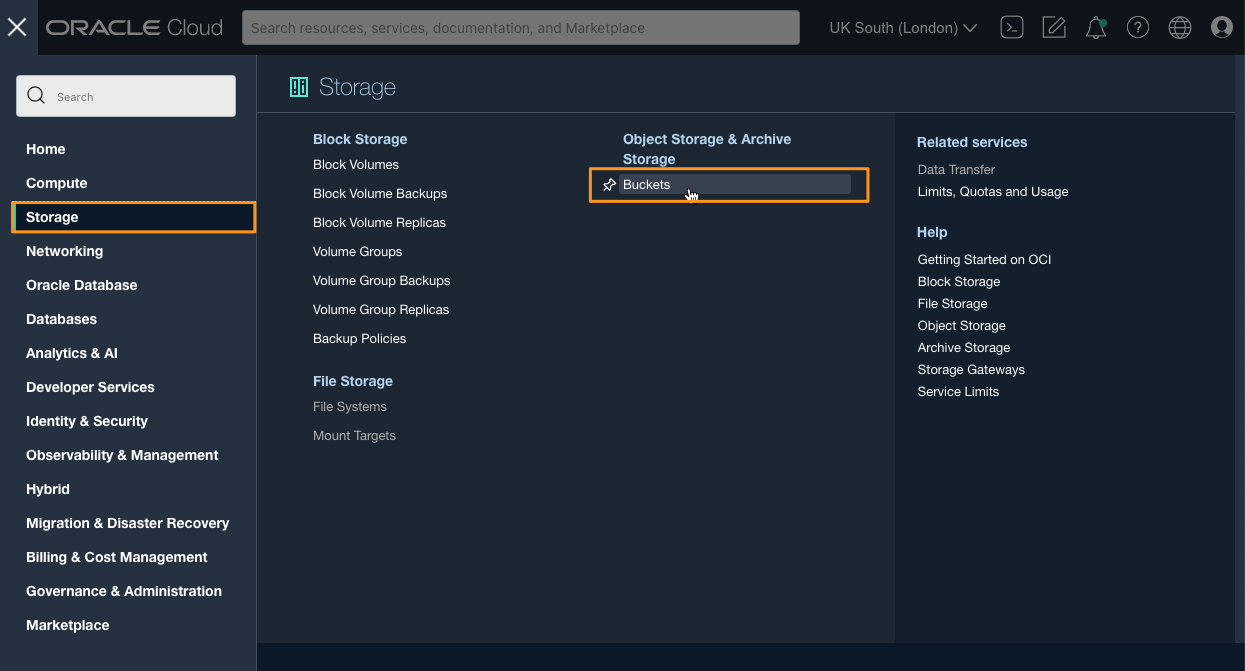
In the buckets section, check that your compartment is set correctly (the root compartment is usually suitable), and click “Create Bucket”. You can choose a name (I chose “mydocs”) or leave it to default. All other fields can be left at their default value. Click “Create”, and then on the next page, click on the name of the bucket you just created.
We can now upload our documents to the bucket. I’m going to upload four documents in various different text or semi-text formats (Text, CSV and JSON). Click the “Upload” button near the bottom of the page, then drag-and-drop your documents, or use the file selector. Finally, click the “Upload” button, and close the panel once all your files are uploaded.
If you want to use the same four files I used, you can get them from these links:
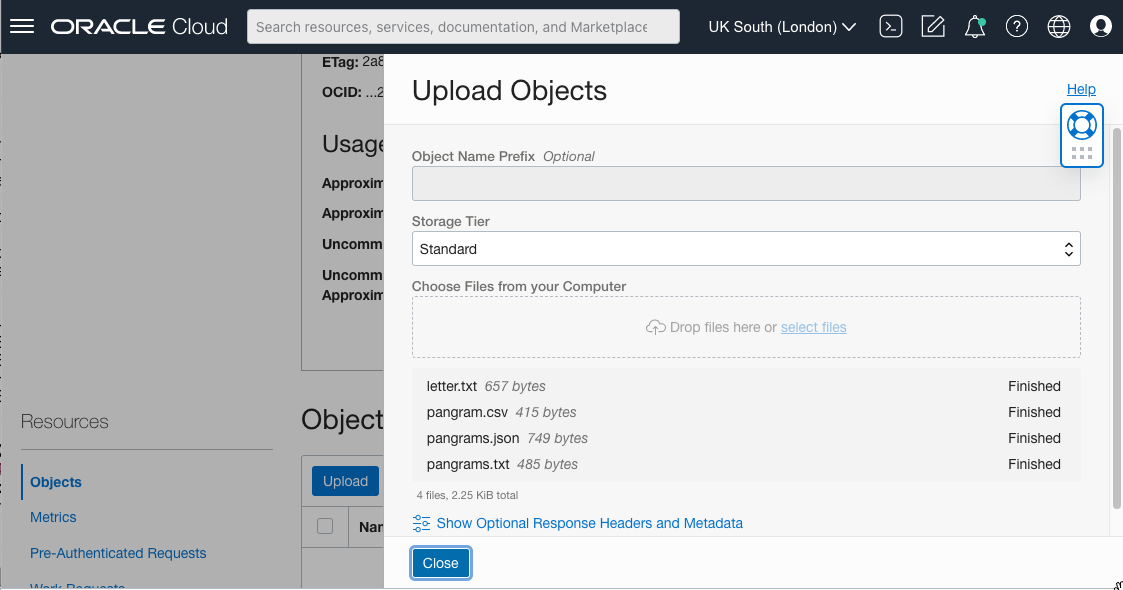
We now need to know the Universal Resource Indentifier (URI) of the bucket. Unfortunately the control panel doesn’t directly show this, so instead click on the three dots to the right of one of the files, and choose “View Object Details”.
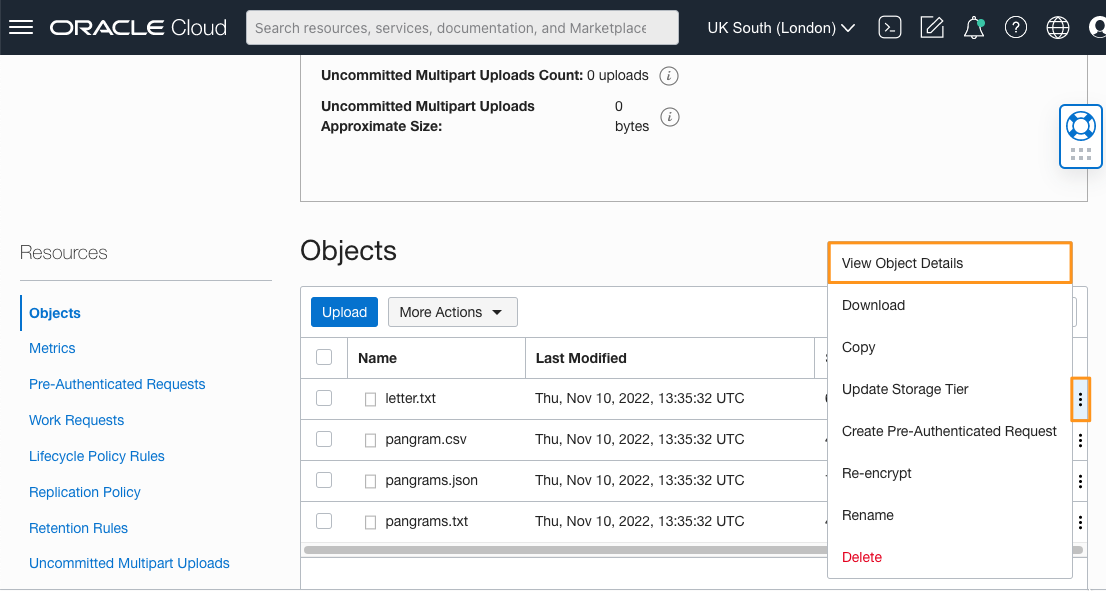
Copy the URL PAth (URI) from this page, and remove the final part representing the file name (for example, “letter.txt”). The rest of the URI is the indentifier for the bucket itself. Save that URI for later use.
Create a Cloud Credential
Generate an Auth Token
A cloud credential allows a program or interface to access a protected cloud resource, such as an Object Storage Bucket. There are different ways to create one, but the simplest uses an ‘auth token’.
From the main OCI Control Panel menu, choose Identity & Security, then Users. From the list choose your username. It will most likely be prefixed “oracleidentitycloudservice/” followed by your login email, with “Yes” in the federated column. Do not choose the non-federated ID, which is likely just your email.
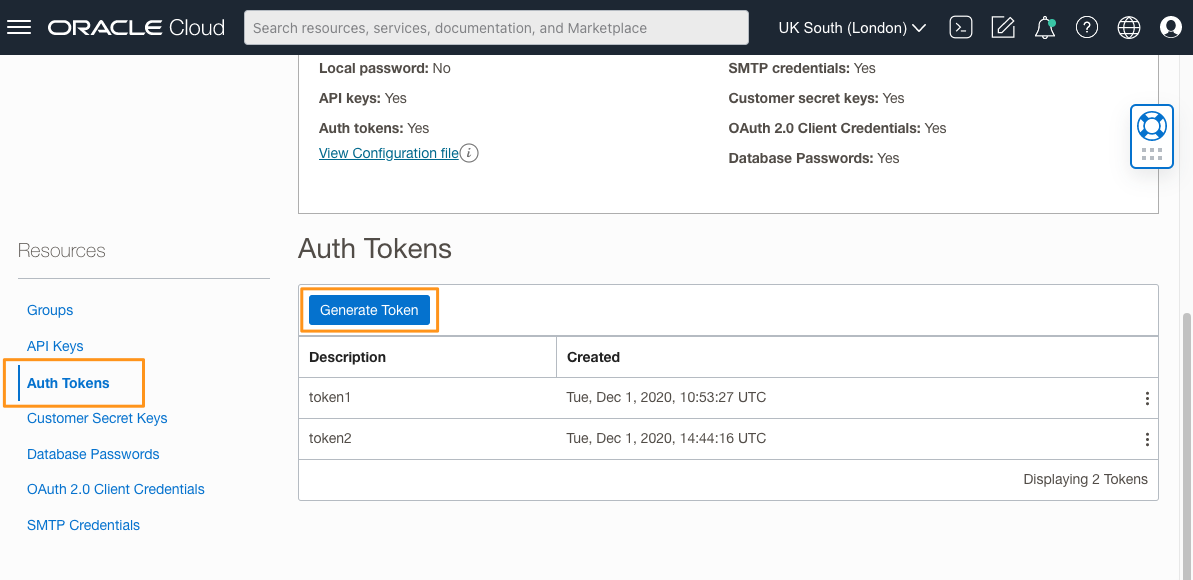
Scroll to the end of the next page and choose Auth Tokens from the menu on the left, then click Generate Token. On the next panel add a description (I just used “My Token”) and click “Generate Token” again. You can then show or copy the token value which will be a short string of apparently random characters. Save this token value for later. Close the panel, and we’re done.
Create the Credential in SQL
This next part expects you to have an Autonomous Database installed. You can use any suitable tool to run the commands, such as Database Actions / SQL, or SQL Developer, or SQLcl.
We need the auth token from the previous step, together with your OCI username. Click on your user (head icon at the top right) to see your username, which usually starts with “oracleidentitycloudservice/“, followed by your email.
We then create a credential thus, using our cloud username for username, and the Auth token for password:
begin
dbms_cloud.create_credential (
credential_name => 'mycredential',
username => 'oracleidentitycloudservice/myname@example.com',
password => 'Xe#eB<y9M<pxqE#_5XYZ'
);
end;
Creating the External Text Index
This section also runs in a SQL tool, such as Database Actions / SQL, or SQL Developer, or SQLcl.
We use the procedure CREATE_EXTERNAL_TEXT_INDEX, which takes the following parameters
- credential name : the name of a cloud credential. May be NULL if the bucket and all files withing it are publicly accessible.
- location_uri : the address of our bucket
- index_name : a name that we provide, which will be used to generate a table and index name in the database.
- format : optional, provides index options. A JSON field, it accepts two attributes, refresh_rate, which is the nunber of minutes between refreshes (the default is 5), and binary_files which can take the value true or false. True indicates that you want to index binary files such as PDF or Word documents where the text can be extracted.
So let’s create our index. Substitute in your own bucket URI and credential name (if not “mycredential”).
begin
dbms_cloud.create_external_text_index (
credential_name => 'mycredential',
location_uri => 'https://objectstorage.uk-london-1.oraclecloud.com/n/lrqmxecwz64w/b/mydocs/o/',
index_name => 'mydocs',
format => JSON_OBJECT('refresh_rate' value '1')
);
end;
refresh_rate of 1 (minute) is useful for testing, but may use a lot of resources on a large bucket.
So what has this done? It has created a table called MYDOCS$TXTIDX (the index name we provided, plus “$TXTIDX“). That table contains columns as follows:
- MTIME : the time the file was last crawled
- OBJECT_NAME : the file name
- OBJECT_PATH : the URI to the file in Object Storage
We can query the table with
select * from mydocs$txtidx
with output:
MTIME OBJECT_NAME OBJECT_PATH
------------------------ ------------- -----------------------------------------------------------------------
2022-11-21T15:57:05.889Z letter.txt https://objectstorage.uk-london-1.oraclecloud.com/n/adwc4pm/b/mydocs/o/
2022-11-21T15:57:05.885Z pangram.csv https://objectstorage.uk-london-1.oraclecloud.com/n/adwc4pm/b/mydocs/o/
2022-11-21T15:57:05.894Z pangrams.json https://objectstorage.uk-london-1.oraclecloud.com/n/adwc4pm/b/mydocs/o/
2022-11-21T15:57:05.885Z pangrams.txt https://objectstorage.uk-london-1.oraclecloud.com/n/adwc4pm/b/mydocs/o/
4 rows selected.
Don’t be surprised if the table is empty initially. The process that fetches the documents from the bucket only runs at “refresh_time” intervals, so it may take a few minutes for the rows to appear.
As well as creating that table, it has created a text index on the contents of each file. The text index is on the OBJECT_NAME column, so that’s the column we’ll need to query.
We can do this using a standard CONTAINS query as follows:
select * from mydocs$txtidx where contains (object_name, 'jumps') > 0;
Don’t forget the “> 0” at the end. CONTAINS returns a number which is non-zero if there’s a match for the search expression in the target table.
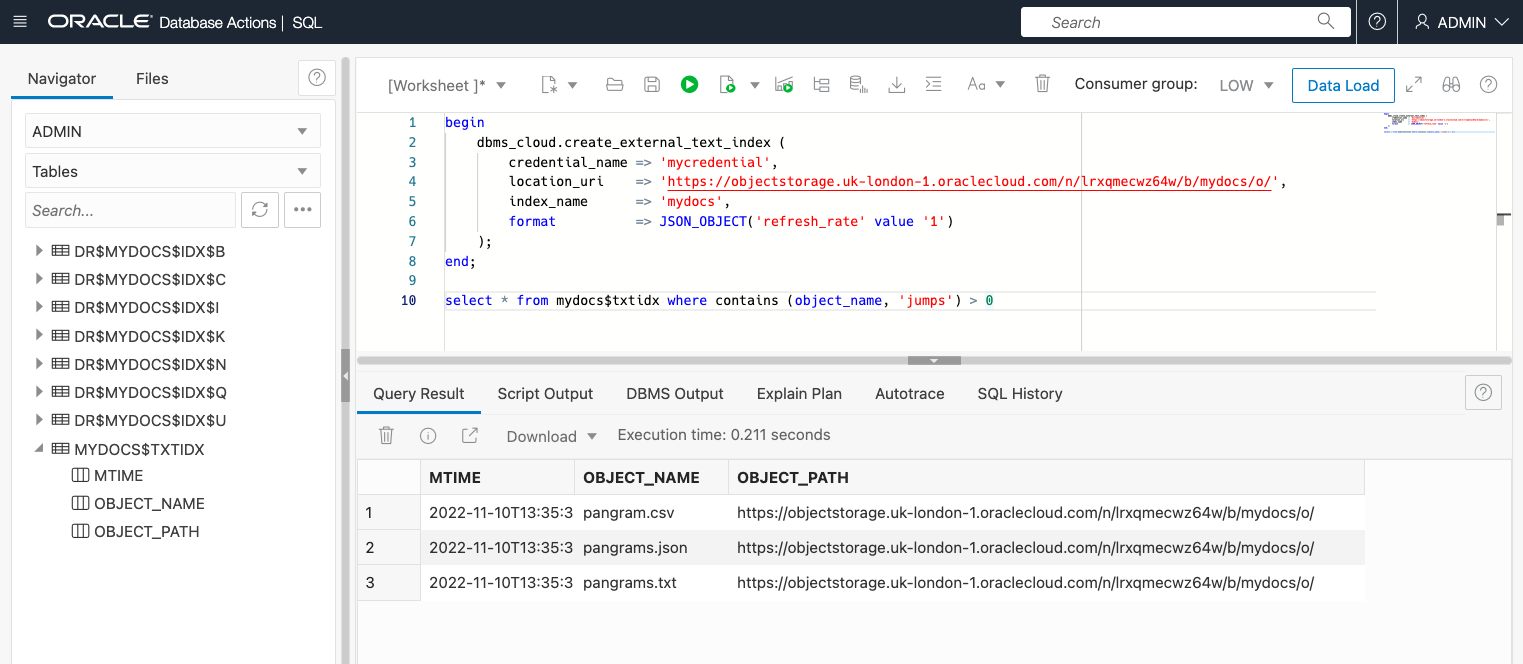
In the screenshot, you can see that that query found three out of my four files.
What kind of queries can I use?
That’s a big topic. Oracle Text provides a rich set of operators. As some basics, you can use AND, OR or NOT between words, and you can use wildcards (“%” and “_”) in the middle or end of a word to match other characters. You can find out more in the Oracle Text Reference Manual.
Searches are case-insenstive, but do remember it’s a word-based index. Searching for ‘quay’ on it’s own will not match ‘Newquay’ or ‘Quayside’. Searching for ‘Newyork’ will not match ‘New York’.
Indexing Public Buckets
Let’s try an even simpler example, indexing files in a public bucket. In that case, we don’t need the credential_name, and can leave it out or set it to NULL. We can even leave it out the format argument (but will need to be aware it could be five minutes before our files are available). We’ll index files from the MOVIE_STREAM public bucket:
begin
dbms_cloud.create_external_text_index (
location_uri => 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/dwcsprod/b/MovieStream/o/',
index_name => 'movies'
);
end;
Now if we do ‘select object_name from movies$txtidx’ we’ll see (after a few minutes):
OBJECT_NAME
--------------------
Countries.csv
Days.csv
Devices.csv
Months.csv
Movie_Sales_2020.csv
5 rows selected.
You can look at the files in the bucket to see what’s in them, or just make a guess:
select object_name from movies$txtidx where contains (object_name, 'europe') > 0;
The output from that will be:
OBJECT_NAME
-------------
Countries.csv
Days.csv
2 rows selected.
What happens when I change files in my bucket?
New files will be indexed automatically. You can see whether the files have been detected by querying the table, e.g. MYDOCS$TXTIDX, but note that there may be a short delay between files appearing in that table and the index being updated.
What sort of files can I index?
As we’ve run it so far, CREATE_EXTERNAL_TEXT_INDEX deals only with textual files. Plain text, HTML, CSV, JSON and XML will all work. Any binary files will be detected and skipped – they won’t appear in the MYDOCS$TXTIDX table and they won’t be indexed.
As well as text files, Oracle Text can handle over 150 different binary document formats, include Office files (Word, Powerpoint, Excell and so on), PDF files, and even archives such as ZIP or TAR files. Such files will be filtered, to use the Oracle Text terminology, and the text will be extracted. In the case of archives, all the files in the archive will be extracted, filtered if necessary, and the text content concatenated for indexing.
To include binary files, we just need to modify our filter parameter appropriately:
format => JSON_OBJECT('refresh_rate' value '1', 'binary_files' value true)
Note there are no quotes around true – it is a JSON keyword, not a string value.
Conclusion and Further Reading
In conclusion, DBMS_CLOUD.CREATE_EXTERNAL_TEXT_INDEX makes it very easy for you to index documents from the Object Store, without having to first load the contents of those documents into the database.
You can find out more about Oracle Text at these links:
- Web: Oracle Text Home Page
- LiveLab: Full Text Indexing in Oracle Database
- Documentation:
