Occasionally, you may need help analyzing performance irregularities or errant SQL. To help solve the problem, Oracle Support or specialist teams will ask for an extract of the AWR data from the database for the period spanning the issue. For on premise databases, you follow the instructions found here. You do it a little differently with Autonomous Database. Here’s how it’s done:
Before running the extract of the data from the database, you need to get the information used as input parameters to the data extract procedure. In this guide, we will run all the commands from the SQL worksheet in Database Actions; but, they can be run from any other SQL tool like SQLcl, SQLPlus or SQL Developer.
The first thing to do is find a directory for the procedure to write the output file to. Run the following query against your database to list the current directories available in the ADB:
select *
from all_directories;
By default, an Autonomous Database is created with two directories: DATA_PUMP_DIR and SQL_TCB_DIR. You can use these destincation directories or any other directory where you have privileges to write data. You can also create a new directory specifically for this task. If you want to do the latter, you can find how to do that here.
In our case we will use the DATA_PUMP_DIR directory.
The next step is to get the DBID of our database and the beginning and end snap IDs of the range of snapshots to include in the extract. This information can be read from the AWR_PDB_SNAPSHOTS table. You can use the begin_interval_time and end_interval_time for each snapshot to make sure the time range is contained within the snapshot range. I used this query to get those values (replacing the time range).
select dbid,snap_id
from awr_pdb_snapshot
where to_date('2023-09-20 11:02:00','YYYY-MM-DD HH24:MI:SS') between begin_interval_time and end_interval_time
or to_date('2023-09-20 14:02:00','YYYY-MM-DD HH24:MI:SS') between begin_interval_time and end_interval_time
order by snap_id;
The output in my example is:
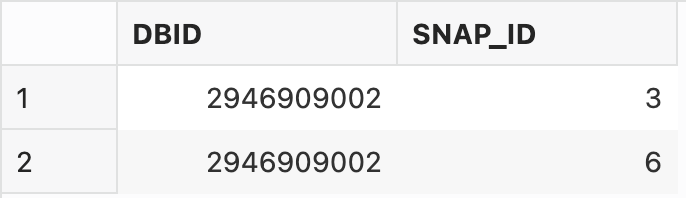
Now that we have all the parameters, let’s run the extract procedure:
begin
/* call PL/SQL routine to extract the data */
dbms_workload_repository.extract(dmpfile => '<filename>',
dmpdir => '<directory to write file to (case sensitive)>',
bid => <begin snapshot id>,
eid => <end snapshot id>,
dbid => <DBID>);
end;
/
Replace:
<filename> with the name without and extension, ie. awrdump
<directory to write file to (case sensitive)> with the directory name, ie. DATA_PUMP_DIR
<begin snapshot id> with the first snap_id in the list if you used the supplied query, ie. 3
<end snapshot id> with the second snap_id in the list if you used the supplied query, ie. 6
<DBID> with the DBID of on the query, ie. 2946909002
This should run for a while depending on the number of snaps in the extract. Once it completed successfully you check that the file has been written to the selected directory. You can do this by running:
SELECT * FROM DBMS_CLOUD.LIST_FILES('<directory name>');
The next step would be to move this file into object storage so it can be shared with the requester. The steps to do this is described in the documentation.
The final step once the credential has been created should be copying the file, which is done by running the following.
BEGIN
DBMS_CLOUD.PUT_OBJECT (
credential_name => '<credential name>'
,object_uri =>'<object storage bucket URI with file name>'
,directory_name =>'<source directory on ADB>'
,file_name =>'<source file name>');
end;
/
Once the file is in an object storage bucket it can be shared by either downloading it or by creating a pre-authenticated request.
