In the old days, customers had to choose one processing system and put all their data there. This could be a database or a Hadoop distribution. Trying to make these platforms work together was tough, and copying data from one place to another was the usual way to share information. This approach came with many problems, including outdated data, unnecessary storage and CPU use, extra work to keep things running, and a high chance of mistakes.
Delta Sharing Unlocks New Possibilities for Platform Integration
Oracle ADB is a cloud-based form of a well-regarded database. There’s no need to emphasize how robust and powerful the Oracle Database is, given that over three decades of focused development have led to impressive outcomes. With its cloud offering, Oracle has incorporated numerous cutting-edge features, earning it a place among the leading cloud database solutions today. Founded in 2013, Databricks is a popular platform for Spark and machine learning tasks. Interestingly, these two platforms can be operating on separate clouds. However, Delta Sharing gives each platform the capability to access the other’s data across clouds. I’ll illustrate how this works with an example, using Web UIs for a clearer visual explanation.

Scenario: Oracle ADB Accesses Data Shared by Databricks
The process is quite simple:
Step 1. Databricks creates a share and gives Oracle the metadata. There’s no need to copy any data — it’s just a swapping of metadata.
Step 2. Oracle – using the metadata from Databricks, creates an external table (just metadata) on its end.
Step 3. Oracle then queries the external table.
The data stays in Databricks’ storage, eliminating the need for copying (although, bear in mind that network communication could potentially slow things down).

Step 1. Create a Share from Databricks.
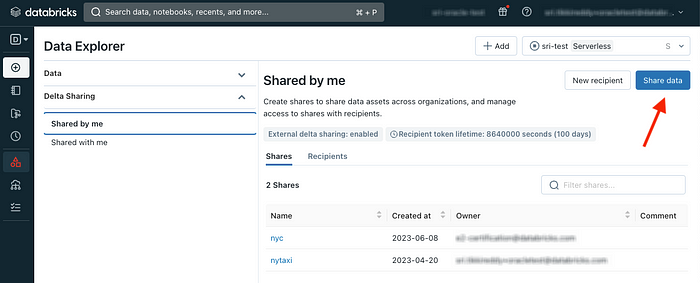
First, Databricks needs to share the data. To do this, just follow a few easy steps. Start by selecting the Delta Sharing submenu under the Data menu, and then click on the ‘Share Data’ button:
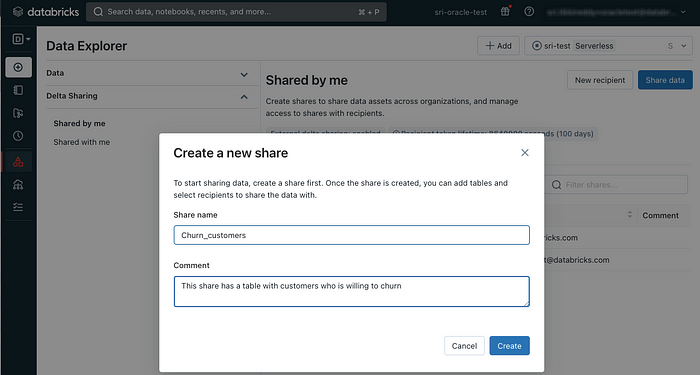
Next, assign a name to the share:
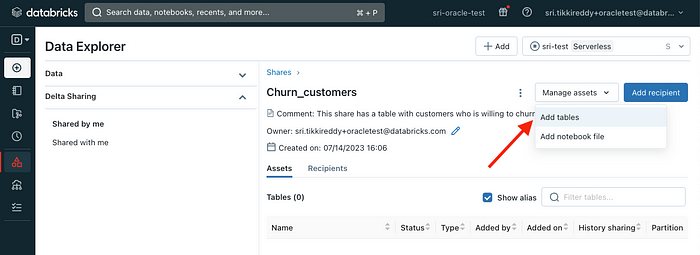
Once the share is set up, you can begin adding tables to it:
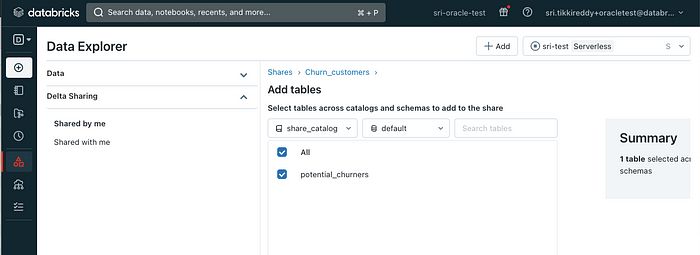
Select a catalog and database to view a list of available tables:
After you’ve added tables to the share, you’ll need to create a named recipient (the party that will use the data):


Now that the recipient is set up, it’s time to send them an activation link. This link leads to a webpage where the user can download their share profile. This is a one-time process that gives them all they need to start using the shared data:
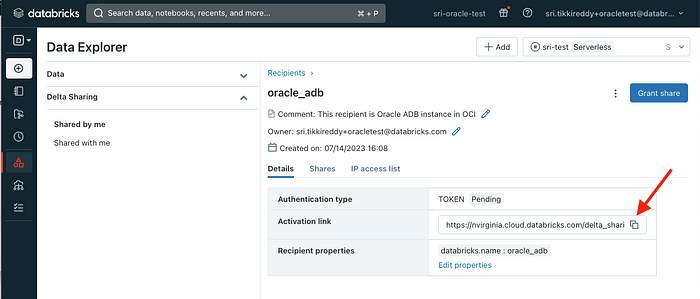
Just copy this URL into your web browser and download the profile:

Step 2. Export Metadata in Oracle and Set Up an External Table Over the Delta Share
Begin with the Database Actions UI and select Data Share:

In the Data Share menu, select “Consume Share”:
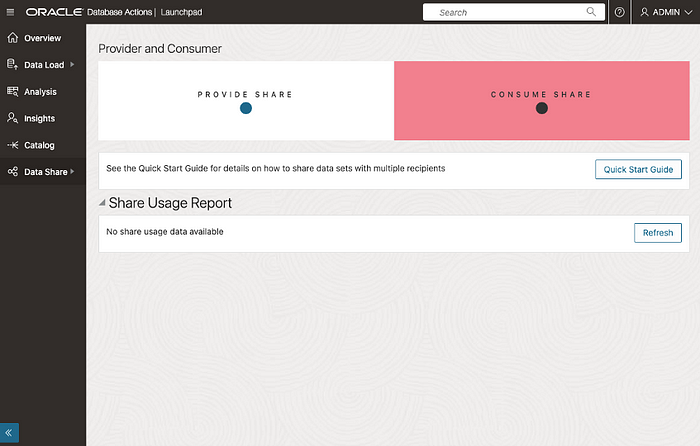
Then, click on the “Subscribe“ button:
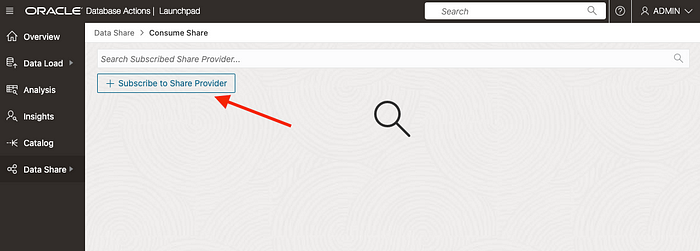
You will be directed to a page where you’ll need to add the config file you downloaded from the link provided in the last step of the sharing process:
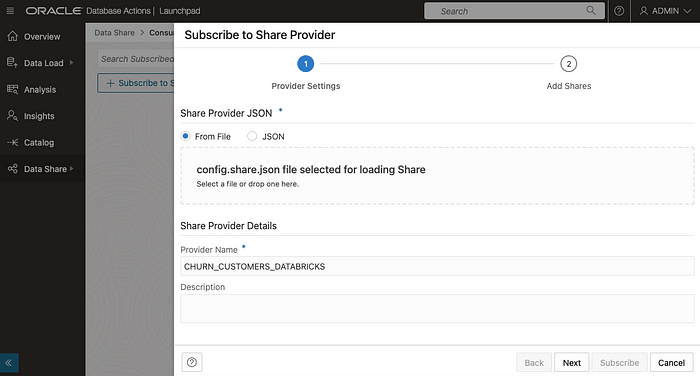
Next, select the share you want to add:
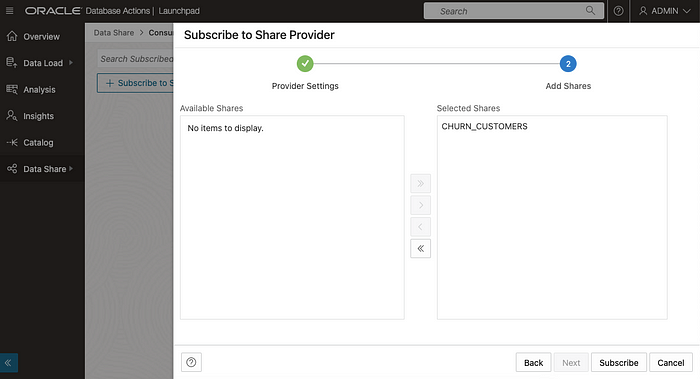
And choose a table within this share:
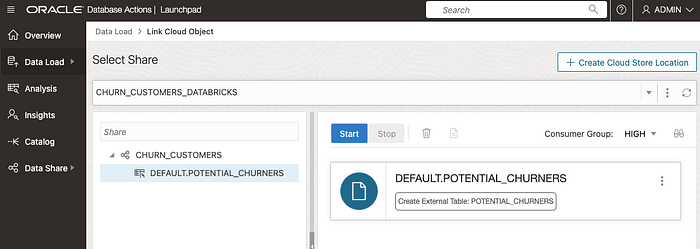
Step 3. Query Databricks Data from Oracle ADB.
You’ll now see a new external table in the Oracle database. You can run a query on it:

Keep in mind, the Oracle ADB external table is connected to the Delta Server endpoint:
CREATE TABLE POTENTIAL_CHURNERS ( CUST_ID NUMBER, WILL_CHURN NUMBER , PROB_CHURN BINARY_DOUBLE ) ORGANIZATION EXTERNAL ( TYPE ORACLE_BIGDATA ACCESS PARAMETERS ( com.oracle.bigdata.credential.name="CHURN_CUSTOMERS_DATABRICKS$SHARE_CRED" com.oracle.bigdata.fileformat=parquet com.oracle.bigdata.access_protocol=delta_sharing ) LOCATION (‘https://nvirginia.cloud.databricks.com/api/2.0/delta-sharing/...#CHURN_CUSTOMERS.DEFAULT.POTENTIAL_CHURNERS') );
Conclusion
In summary, Delta Sharing is a seamlessnew way to share live data between platforms like Oracle ADB and Databricks. Before, data was stuck in one platformsystem and we had to copy it to share it with another platform. Now, with Delta Sharing, these platforms can see each other’s data without the need forany copying.
This method is much better. It avoids old problems like outdated data, unnecessary computer use, and extra work.
We showed an easy example of this process. Databricks shares data, Oracle uses this shared data, and then Oracle can queryask questions of this data. It’s a simple 1–2–3 process.
