Those who work with big data processing systems would be quite familiar with Parquet, a popular columnar storage format that can store records with nested fields efficiently. Parquet is known for its performant data compression and its ability to handle a wide variety of encoding types.
In this post, I want to introduce you to new functionality in Autonomous Database enabling users to export table data from Autonomous Database (ADB) to your cloud object storage in Parquet format. This export method supports all the cloud object stores supported in Autonomous Database (Oracle Cloud (OCI) Object Storage, AWS S3, Azure Blob Storage etc.), while also supporting the various convenient methods of object storage access including OCI resource principals, AWS Amazon Resource Names (ARN), Azure service principals, or a Google service account for GCP resources.
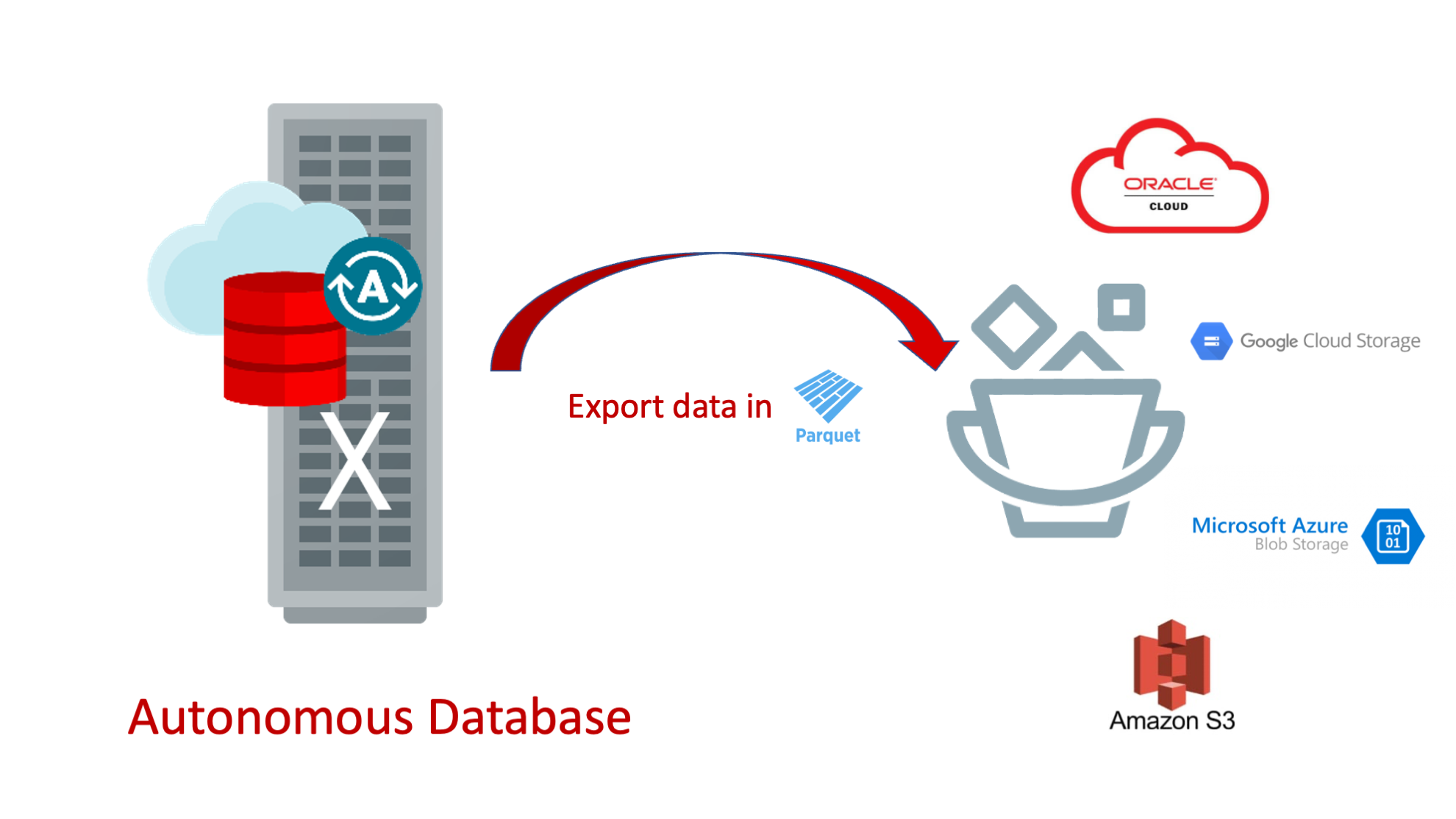
Exporting data from Autonomous Database to object store in Parquet
1. Connect to your Autonomous Database instance. Follow this LiveLab workshop if you are new to ADB and need help creating and connecting to an ADB instance.
2. Create your cloud object storage access credential using DBMS_CLOUD.CREATE_CREDENTIAL. Refer to the CREATE_CREDENTIAL documentation for the right parameter input based on your chosen object store. For Oracle Cloud’s object store, follow this example workshop with detailed steps:
BEGIN DBMS_CLOUD.CREATE_CREDENTIAL( credential_name => 'CRED_NAME', username => 'user1@example.com', password => 'password' ); END; /
Note: This step of creating a credential to access Oracle Cloud Infrastructure Object Store is not required if you enable resource principal credentials.
3. Run DBMS_CLOUD.EXPORT_DATA and specify the format parameter type with the value “parquet” to export the results as parquet files to your object store.
To generate the parquet output files there are two options for the file_uri_list parameter:
- Set the file_uri_list value to the URL for an existing bucket in your object store
- Set the file_uri_list value to the URL for an existing bucket in your object store, and include a file name prefix to use when generating the file names for the exported parquet files.
If you do not include the file name prefix in the file_uri_list, DBMS_CLOUD.EXPORT_DATA supplies a file name prefix. Read the file naming for text output documentation if you would like the details.
If you don’t know how already, learn how to create a bucket here via ADB’s LiveLabs.
Run the following example, replacing in your object store bucket URI and a query over your table of choice, with a file name prefix such as “sales_export” specified in file_uri_list. This example exports all of the data from the query result into the specified object store bucket:
BEGIN
DBMS_CLOUD.EXPORT_DATA(
credential_name => 'CRED_NAME',
file_uri_list => 'https://objectstorage.us-phoenix-1.oraclecloud.com/n/namespace-string/b/bucketname/o/sales_export',
query => 'SELECT * FROM SALE_DEPT',
format => JSON_OBJECT('type' value 'parquet', 'compression' value 'snappy'));
END;
/
For detailed information about the available format parameters you can use with DBMS_CLOUD.EXPORT_DATA, read this page. For exporting other data types (CSV, Text, JSON etc.) as well any limitations with the Parquet format, refer to the topic in the ADB Documentation.
That’s it! You have successfully exported your table data as parquet files on cloud object storage. You can now use these exported files for further analysis or processing with your other applications. For your next read, check out how Alexey’s post about accessing exported parquet files lying in your object store via external tables.
I hope you found this post useful and informative! We welcome questions and feedback, feel free reach out to your favorite Autonomous team here.
Like what I write? Follow me on the Twitter!
