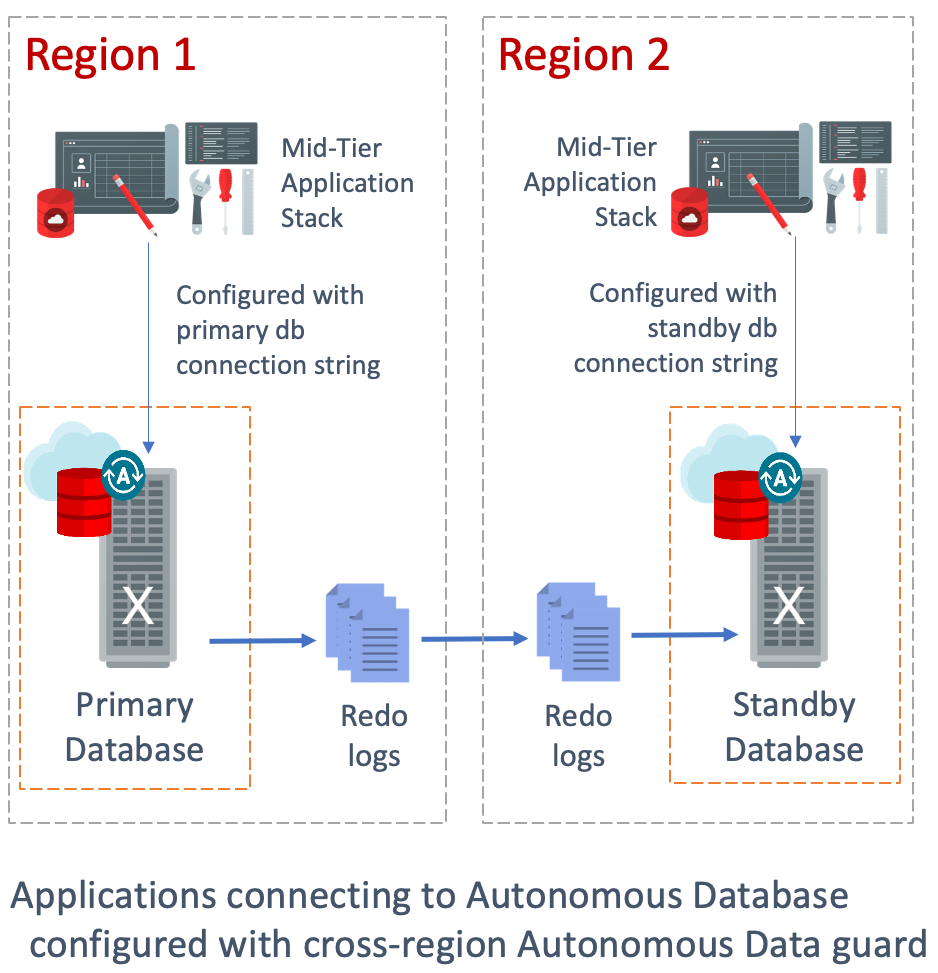
Autonomous Database (ADB) provides highly functional and automated local and cross-region disaster recovery (DR) features with little-to-no configuration required by a user, with the use of Autonomous Data Guard. In this post, I want to steer you and your team towards the simple, recommended method for configuring your mid-tier, application stack to connect ADB with Cross-Region Autonomous Data Guard enabled, for the optimal cross-region resiliency.
In this cross-region DR setup, just as your primary and standby databases lie in different regions, we recommend that you have a primary and secondary mid-tier running in or near the same regions as your databases. This way, when you intend to failover during a disaster, you will failover your entire stack (database and mid-tier) to the remote region.
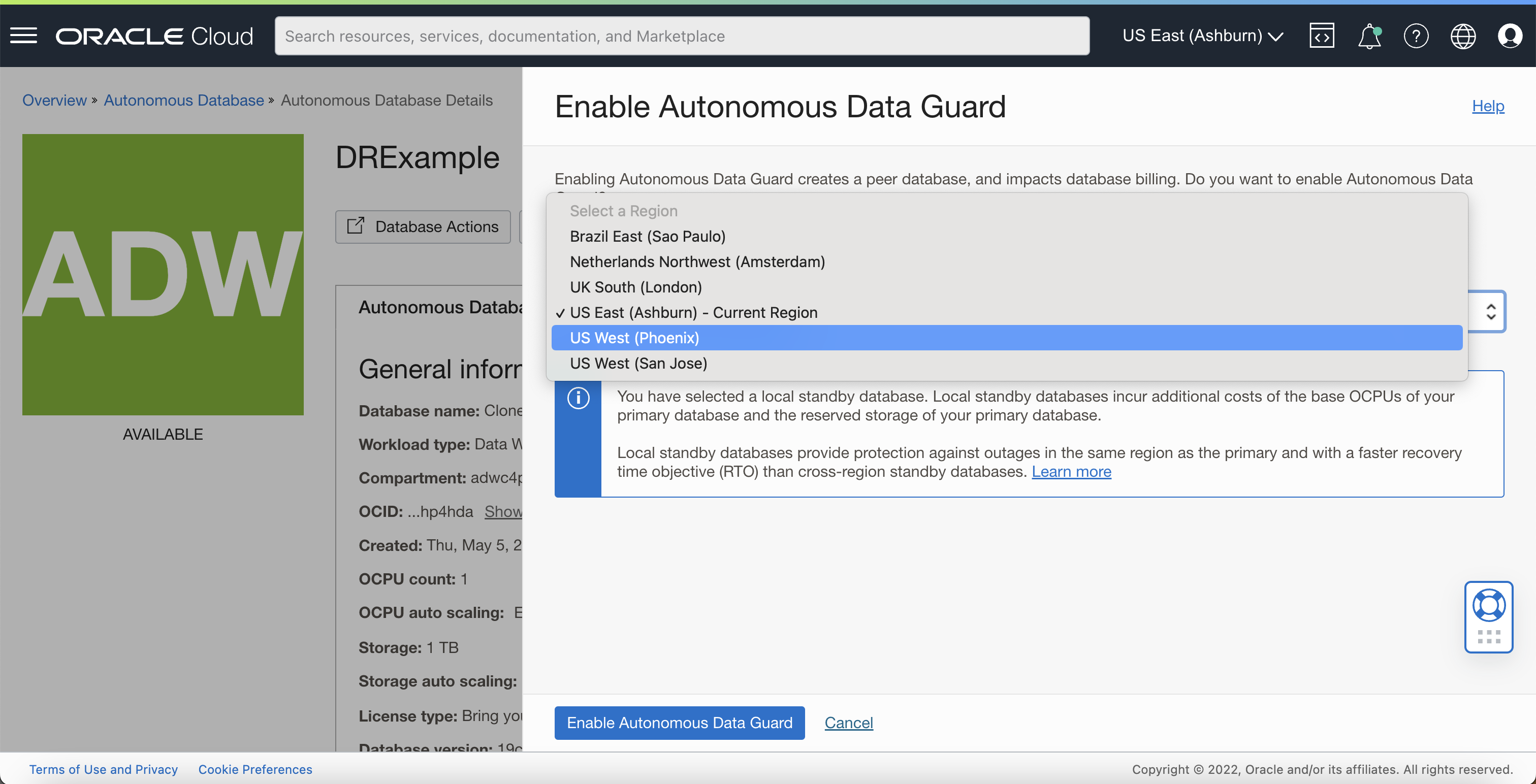
Step 1: Enable Cross-Region Autonomous Data Guard in ADB
If you haven’t already, go to your database console and click “Enable” within the Autonomous Data Guard section. Select a remote region (ie. not the current region you are in). If your database uses access control lists (ACLs) or private endpoints, configure those here for your ADG Standby database too.
In this example, our Primary database is in the US East (Ashburn) region, and the Standby is in US West (Phoenix) region.
Step 2: Configure your mid-tier application stack in the source region with the co-located database connection string or wallet
As mentioned above, a good disaster recovery architecture involves placing your primary and secondary mid-tiers in the same or nearby regions as your primary and standby databases.
Once you have set up your mid-tier in each region, continuing with our Ashburn – Phoenix example, navigate to your Primary (Ashburn) database and click “DB Connection”.
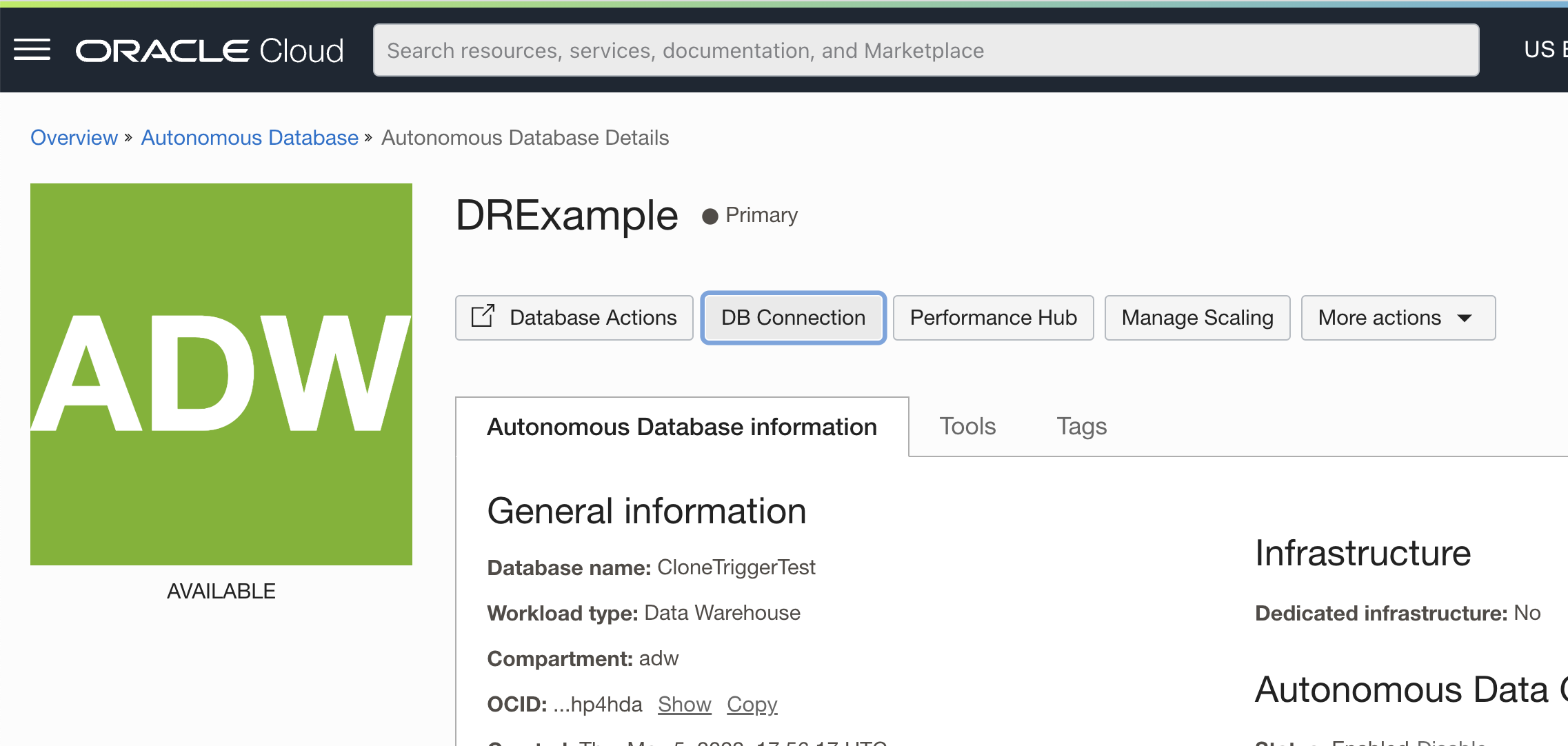
Under DB Connection, you can scroll down to find your connection string to use to connect to the database without a wallet or you may download the wallet to connect to the Primary database. Note that the connection string for the Primary database contains only the Primary database’s hostname. Configure your application lying in the primary region to use this wallet or connection string to connect to the Primary database.
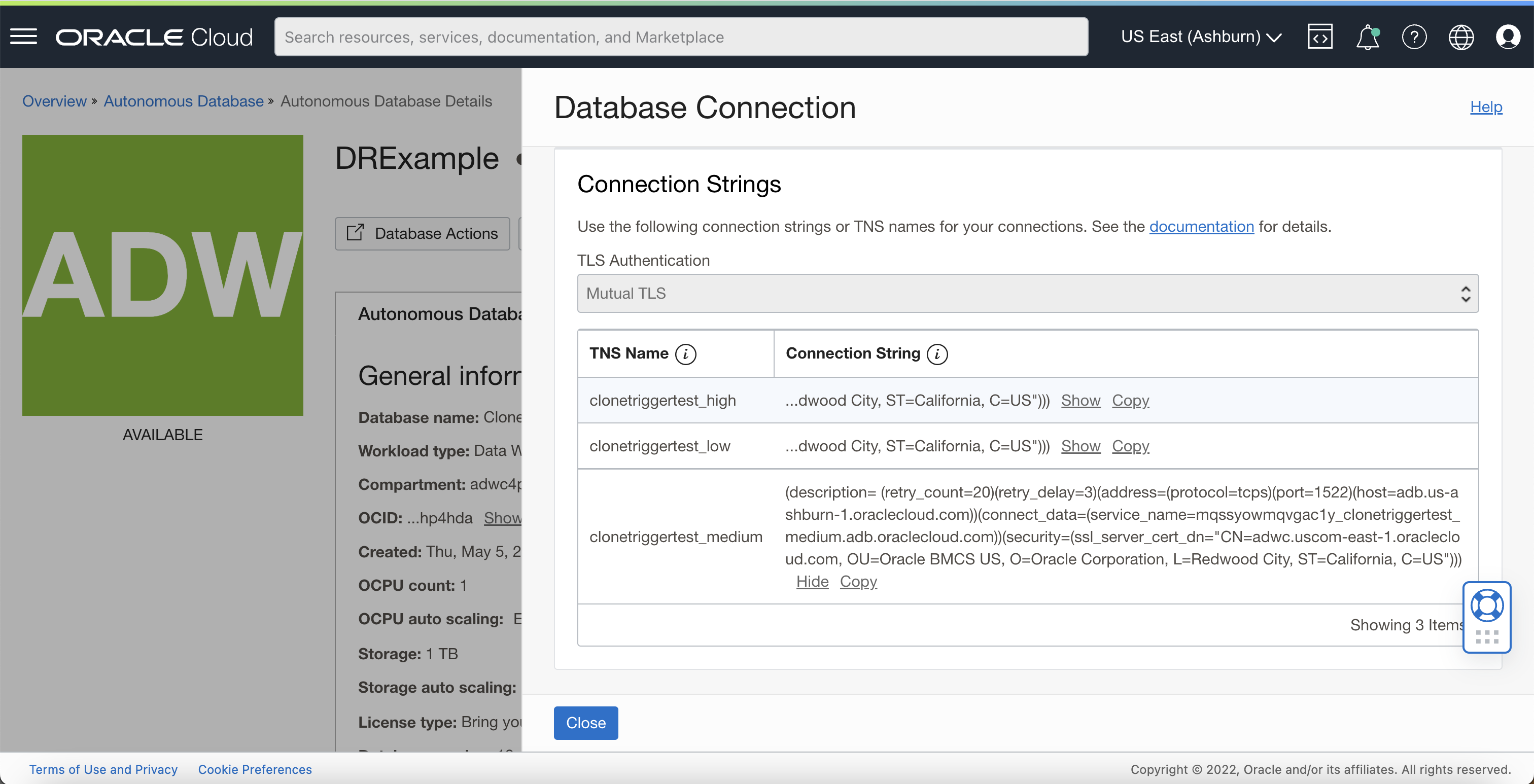
Step 3: Configure your mid-tier application stack in the remote region with the co-located remote database connection string or wallet
You will now perform a similar step to Step 2 on the remote (ie. secondary) region. Navigate to the remote Standby database and click DB Connection. Once again, scroll down to copy the connection string or download the wallet for your Standby database, which will contain the Standby database’s hostname.
Configure your remote mid-tier application with this Standby’s connection string or wallet.
Step 4: During testing or a true disaster, switchover / failover your complete stack
When testing your disaster recovery setup, or if a disaster were to actually occur and you find your primary region completely down, switchover / failover your complete stack to the remote region – Both ADB and your mid-tier applications. Since your application in the remote region is configured with the connection string of the database in the remote region, there will be no additional lag or delay in your application due to cross-regional connection or data transfer, and will minimize any lag experienced by your users.
Note: A switchover will only succeed if the database can guarantee zero data loss, while a failover can have upto a maximum of 1 minute of data loss.
We no longer provide both the primary and standby database hostnames in a single connection string or wallet, since that isn’t recommended for DR – It introduces connection retry delays and simply slows the system down. However, if your application tier does still need a single connection string to be able to connect to either the Primary or Remote databases after a failover, you may manually construct a single connection string containing both database hostnames as described with an example in our documentation here.
I hope this post presents you with the right basic philosophy for planning out your disaster recovery strategy. Have a look at more details about Autonomous Data Guard in the documentation. As always, please reach out to your contact at Oracle or us on Twitter or Stack Overflow for any help you may need!
Like what I write? Follow me on the Twitter!
