Autonomous Database enhances data lake analytics
New Autonomous Database capabilities lower management costs, simplify discovery and enhance performance
Oracle data warehouses have been a mainstay in data architectures for decades. And, for good reason – data warehouses are scalable, highly secure, handle complex queries with high levels of concurrency and are available to a wide range of tools and applications. With that said, data lakes have increasingly become a key part of data platforms. Whereas data warehouses typically house “certified” or curated data – data lakes tend to be more flexible. Data is stored in files in an object store – which you can think of as a limitless, low cost bucket of information. That object store data is accessed by a variety of open source tools from a separate, scale-out compute tier. Each data consumer applies a schema to the source – allowing for its own interpretation of the data. This is a powerful concept – but oftentimes requires a more technical skill set that may not even be available in an organization.
Let’s take a look at a use case. A large scientific research institution performs complicated experiments using extremely sophisticated equipment. The reliability of the control data and the speed at which they can gain insights from it are crucial to the science that takes place. Unplanned repairs are incredibly expensive; each repair requires a multi-week cycle to reset the equipment. The solution is an incredibly advanced IOT solution – utilizing a complex mix of accelerators, detectors that persist and analyze data millions of signals. The logged IoT data is measured in petabytes and captured in the data lake’s object storage. Thousands of cores are used to process that data.
Storing all of that raw data in the data warehouse would be expensive and a challenge to manage. Here, the data lake complements the data warehouse. The control data is transformed and loaded into Autonomous Database – where that recent data is scored with ML models. The research institution uses this information to predict potential maintenance issues – a critical component to managing their projects.
This is just one example. Other data warehouse and data lake integration use cases include:
- Compliance / Archive: Always available, cost effective archive storage and access.
- Extend the data warehouse to data lake: Agilely extend certified warehouse with raw data
- Multi-cloud: Gain access to Amazon and Azure Data Lakes
Delivering a lakehouse on OCI
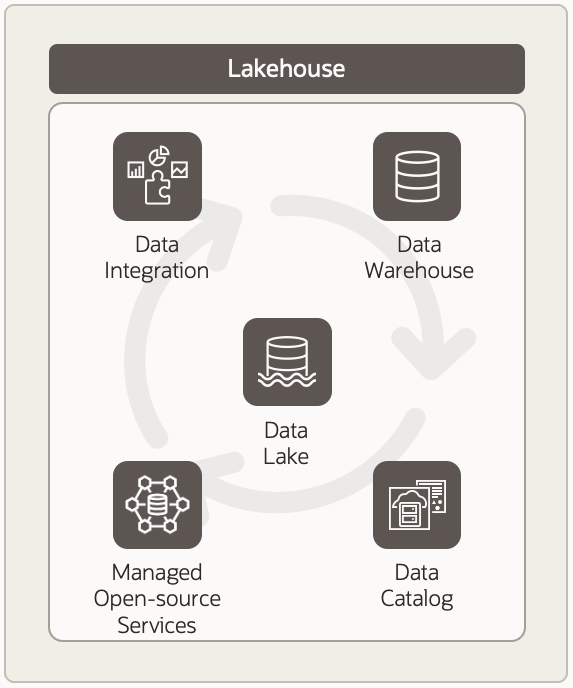
- Data Warehouse: for curated data of known value
- Data Lake: for data that is raw, less well understood, older, or less valuable. Often used for staging prior to loading to data warehouse, archive of older, and a comprehensive repository for training machine learning models
- Managed Open-source Services: support key open-source tools for storage and analysis, incl. Apache Hadoop, Apache Spark and Redis
- Data Integration: data in lakehouse will move between lake, warehouse and open-source analytics environments—depending on need and use case
- Data Catalog: maintains a complete view of all available data for discovery and governance
Let’s take a closer look at three key services that are core pillars to the solution: Autonomous Database, Oracle Object Storage and OCI Data Catalog.
Data Catalog – “Spotlight for OCI”
As mentioned earlier, object store is a virtually limitless bucket of files. Simply upload a file and then access it with a choice of tools. The data lake takes a “schema on read” approach; each consuming application interprets the schema for the underlying files as it sees fit.
This flexibility offers amazing agility. But, if the process is not managed properly, it can also lead to a hot mess and confusion about the data. What is the state of the data? What do the files mean? How do the files relate to one another?
OCI Data Catalog is Oracle Cloud’s centralized metadata service that is meant to solve many of these issues; it is the source of truth for Object Store metadata. Consider the following example. Files are captured in object storage in a variety of formats (delimited text, JSON, parquet, avro, orc, etc.):

Data Catalog harvests the object storage to automatically derive entities – which from an Oracle Database perspective are tables. The entities contain columns – and those columns have data types. A single harvest may derive hundreds of entities.
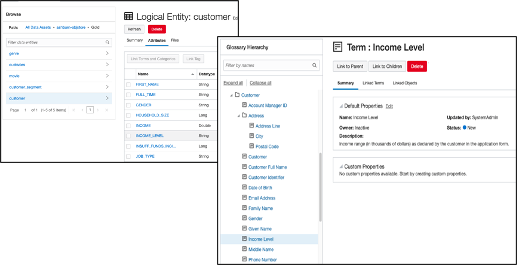
Data owners then associate a business context for that data. Data Catalog manages a glossary of terms and tags that describe data sets. This business context may include the meaning of fields and tables, the date the entity was last updated, a data quality rating, source for the data, etc. This information is incredibly valuable for ad hoc query and analysis. Data sets that may not be suitable for regulatory reporting may be perfectly fine for discovery. Importantly, you must be able to easily find and understand the information you need to gain insights.
Autonomous Database uses centralized Data Catalog metadata
Since its inception, Autonomous Database has had the ability to load data from data lakes and directly query data lakes without loading data. Autonomous Database supports a wide variety of file types across both Oracle Object Storage as well as S3, Azure, GCP and more. Integration with Data Catalog has made managing links to the data lake simple. Autonomous Database is using the same metadata as the other lakehouse services.
Data Catalog shares the meaning of object storage data with Autonomous Database via automatic synchronization:
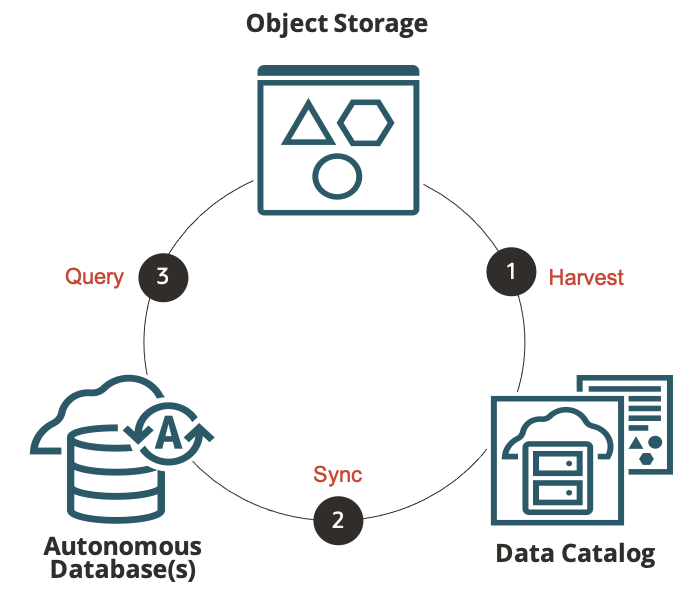
The Data Catalog folders and entities appear in Autonomous Database(s) as fully managed schemas and tables; Data Catalog is the source of truth for these tables. Changes in the Data Catalog metadata are automatically reflected in Autonomous Database – no administrative intervention is required. You can even query the Data Catalog metadata from ADB – using SQL – to better understand the managed data lake tables.
Use Oracle SQL to query the data lake
Once the external tables are available, Autonomous Database allows you to query the data lake using Oracle SQL – which means that any tool or application that can query Autonomous Database can now query the data lake as well. A single query can correlate data from both sources.
Not all SQL languages are the same. Autonomous Database offers the most advanced SQL support available – which means easier and faster answers to difficult questions. For example, instead of programming Python or Scala to find patterns in data – use declarative SQL pattern matching to find that answer. No need to write, deploy and debug code – simply run a query, examine the results, and iterate. A powerful SQL language prevents you from falling off a complexity cliff.
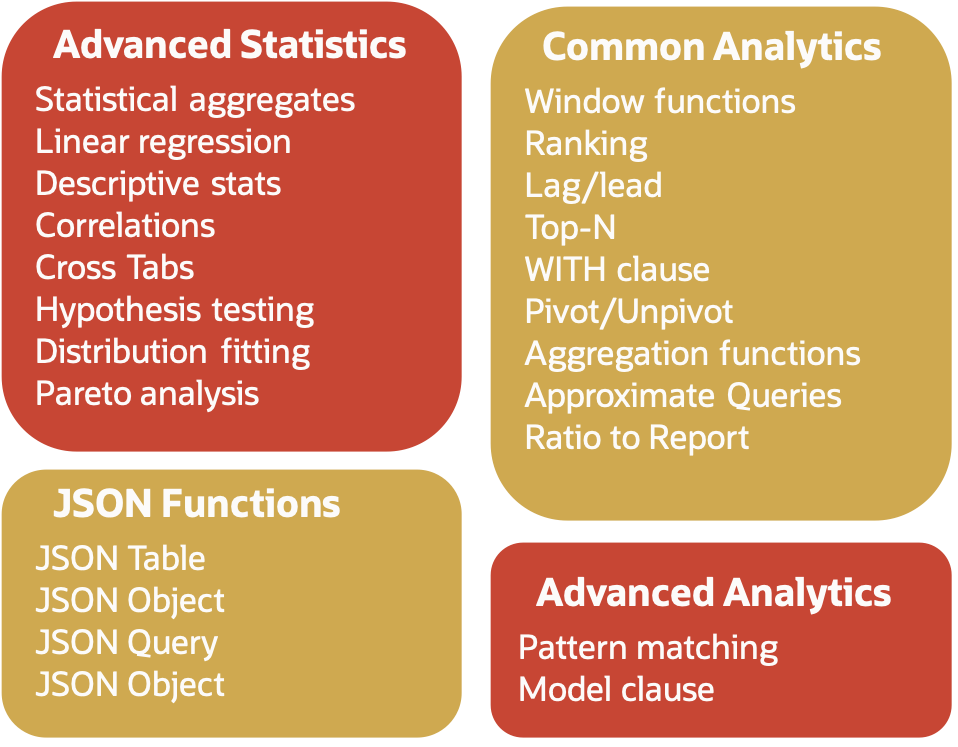
Use Autonomous Database to query the data lake at scale
Autonomous Database delivers scalability and performance through a variety of optimizations. Auto scale deploys additional, specialized object store processing that uses data lake smart scans. Data lake smart scan processing is separate from traditional database processing – minimizing impact on database workloads. Smart scan’s role is to scan, apply functions, filter and aggregate object store sourced data – returning a subset of the data to core database processing. This additional processing is leveraged transparently for the life of the query – and only when necessary.
Data lake smart scan is just one performance optimization. Partitioning, hybrid partitioning (for tables that use both database storage and object storage) and predicate pushdown to Apache Parquet and ORC files minimize data scans – which is critical when analyzing massive data sets. Result cache and materialized views with automatic query rewrite dramatically improve performance for repetitive queries and subqueries.
Summary
Autonomous Database has been significantly enhanced to give transparent access to any data in a data lake by minimizing management, enhancing data discovery and maximizing performance. No new skills are required and your current tools and applications benefit with zero changes – allowing expanded insights with minimal investment.
