The deployment of a machine learning (ML) model is the final major step in turning data into actionable insights. But this step can face a number of challenges, and addressing those challenges improperly can lead even the strongest models to experience poor or infrequent usage. But by using Oracle Machine Learning (OML) Notebooks in tandem with Application Express (APEX), Oracle Cloud users can rapidly build and train ML models directly on the data present in their database, and also deploy those models so that end-users can interact with and generate model predictions in real time. The OML and APEX services detailed below are both found on Oracle’s Autonomous Data Warehouse (ADW) that is used here as a Data Lake in the Oracle Cloud.
Figure 1 shows the workflow diagram for this model deployment, which can be delivered via SQL and PL/SQL code blocks that are executed inside OML and APEX, which in turn avails this model-deployment mechanism to anyone with standard PL/SQL coding abilities.
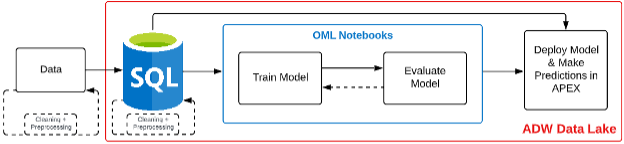
Figure 1: Work flow schematic.
Data Prep & Model Goals
The cleaning and preparation of data are crucial first steps in any data science project, and Figure 1 indicates that this can be done externally prior to the data landing in the ADW Data Lake, or else inside the Data Lake itself using SQL and PL/SQL.
The input data used here tracks historical outcomes for a large number of home loans, and the goal of this effort is to train a machine learning model to predict whether a particular borrower would default on their home loan. That input data includes each borrower’s loan amount, their mortgage balance, debt-to-income ratio, any credit report delinquencies, their credit line age, and related variables. Before model training, the data was split into training and test samples using the ORA_HASH function on the input table, with a view containing 80% of those records for model training, and the remaining 20% set aside for testing.
ML Model Training & Testing
The Oracle Machine Learning (OML) Notebooks allows easy querying of the ADW database, with those query results then used to build and tune ML models using PL/SQL to calls the DBMS_DATA_MINING package. After experimenting with several different ML algorithms, the DBMS_DATA_MINING.CREATE_MODEL2 procedure is used to train a Random Forest composed of 50 trees, since that algorithm proved to be most accurate at predicting whether a particular loan would be defaulted upon. We also note that ADW’s new AutoML feature could instead have been used here to speed up ML model training and tuning, and that tool will be explored at future model deployments.
To assess the ML model’s accuracy, the DBMS_DATA_MINING.APPLY( ) procedure was used to compute a table of predictions for the sample of test records. A PL/SQL code block then compares predictions to actual outcomes, yielding an overall model accuracy of 90%. Additional SQL then allows one to generate the ML model’s confusion matrix (Fig 2), which informs of this binary classifier’s strengths and weakness. Figure 2 shows that this model did a fairly good job of predicting which borrowers always service their loan, with the rightmost column indicating that 4607 out of 164 + 4607, or 97%, of borrowers will be correctly identified by the model as being excellent borrowers, with False to indicate that the borrower does not default on their loan. However the matrix’s left column shows that only 808 out of 381 + 808, or 68%, of borrowers are correctly identified by the model as defaulters. Given these results, putting this particular model into production usage might have some risk, due to the model’s relatively high false-negative rate (ie the model incorrectly predicts that 32% of defaulters will not default). So in a follow-up experiment, we will also use ADW’s new AutoML feature, which will rigorously automate model optimizations by performing feature selection and hyperparameter tuning, and will hopefully reduce the model’s false-negative rate.
|
|
|
ACTUAL VALUES |
|
|
|
|
True (1) |
False (0) |
| PREDICTED VALUES |
True (1) |
808 |
164 |
| False (0) |
381 |
4607 |
|
Figure 2: Model Confusion Matrix
Model Deployment & Usage
After the ML model is successfully trained and validated, it is then made accessible to other end-users via an APEX application whose parsing schema matches the schema on which the ML model was trained on. This application also leverages a custom authentication scheme to restrict model access to only those users with the appropriate permissions. Because the model was built and trained entirely within a common schema, no additional permissions are required for usage.
The deployed ML model is to be used like a calculator, with the user providing the features expected by the ML model that then generates an output prediction, and with APEX staging these inputs and outputs in ADW tables. Additional ADW tables also house all incoming data on new loans that flow into the datalake. A tailored APEX page then queries those tables to populate a form that shows new borrowers’ data, plus an interactive report showing additional facts and model predictions; see Fig. 3 for an animation of this APEX app’s usage.
APEX plus a modest amount of SQL and PL/SQL allows one to customize an interactive report that displays all new loan records plus model predictions of whether a given borrower will default on their loan, as well as the ML model’s self-assessed confidence in its prediction. That report is generated by joining the loans table with the predictions table plus this bit of SQL
PREDICTION(<MODEL_NAME> USING *) AS PREDICTION_TARGET, PREDICTION_PROBABILITY(<MODEL_NAME> USING *) AS PREDICTION_CONFIDENCE
with APEX used to dashboard the results. All of this is triggered when the end-user enter a borrower’s features into the form on the left-hand side of Figure 3, after which the ML model automatically makes its prediction.
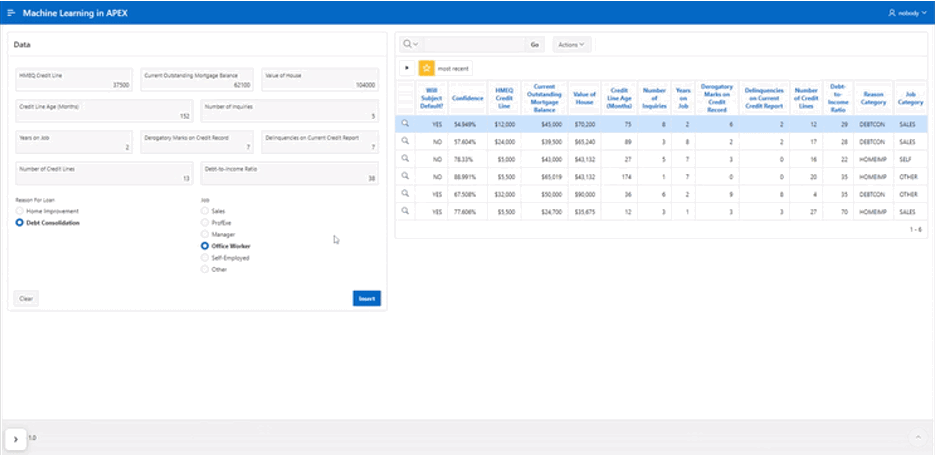
Figure 3: Animation of APEX front-end’s usage.
At a later time, one might also want to retrain that ML model as additional business data becomes available, and that is easily done by rerunning the OML notebooks described above. The revised predictions generated by the updated model can overwrite the old predictions table, or they can be appended to that table if old and new predictions are to be preserved.
Business Impact
As the animation in Figure 3 shows, end-users can operate this APEX application page as one would a calculator; entering new values into the loans table then triggers a call to the ML model which estimates whether the loan applicant is likely to default on their payment at a later date. Using this solution, businesses can utilize existing tools within the Oracle Cloud to train and deploy ML models fairly quickly and easily, with only modest knowledge of SQl and PL/SQL being required. And in cases where the input data requires little to no preparation, engineers can train and deploy a new ML model within minutes to hours.
