Update: In addition to local Standbys described below, we now also have cross-region (remote) Standbys available. Read this follow-up post for more detail about cross-region Autonomous Data Guard.
Just over a week ago, you may have heard Larry mention Autonomous Data Guard at the live-streamed Oracle Live event. Today, I am happy to announce this much-awaited disaster recovery (DR) feature in Autonomous Database on Shared Infrastructure (ADB-S).
Autonomous Data Guard (ADG) gives users the ability to enable a standby database for each ADB instance in a just one-click; As always in the Autonomous world – It is completely automated! Note that this is an advanced feature available only in 19c and above ADB instances and not available in the Always-Free tier. If you are still running database version 18c, consider upgrading to 19c in one-click as well.
While ADB already runs on highly available Exadata infrastructure, this feature further protects your business’ data against unforeseen disaster scenarios (think earthquakes, fires, floods, major network outages etc.) by automatically failing over to a standby database when the primary database goes down. Currently, ADB-S supports ADG within the same region (physically separated across Availability Domains) and aims to support ADG across regions later this year.
Before we jump right into using this feature, let’s brush up on some (simplified) disaster recovery terminology as it relates to ADG:
Peer Databases: Two or more databases that are peered (linked and replicated) between each other. They consist of a Primary database and Standby (copy of the primary) databases.
Primary or Source Database: The main database that is actively being used to read from and write to by a user or application.
Standby Database: A replica of the primary database which is constantly and passively refreshing (ie. replicating) data from the primary. This standby database is used in case of failure of the primary. In the case of ADG, we keep this standby on a different physical Exadata machine (in a different Availability Domain in regions that have more than one) for the highest level of protection.
Recovery Point Objective (RPO): An organization’s tolerance for data loss, after which business operations start to get severely impacted, usually expressed in minutes. We want this to be as low as possible.
Recovery Time Object (RTO): An organization’s tolerance for the unavailability (or downtime) of a service after which business operations start to get severely impacted, usually expressed in minutes. We want this to be as low as possible.
Armed with the above knowledge, let’s dive right into using Autonomous Data Guard. You already know how to navigate to your Autonomous Database console in OCI, by clicking on your database name in your list of database instances. As before, you should be using a 19c version database.
Like magic, you now see Autonomous Data Guard as an option on your console. Click the “Enable” button on your console, followed by clicking the “Enable Autonomous Data Guard” confirmation button. (Okay, I lied… It’s 2 clicks, not 1).
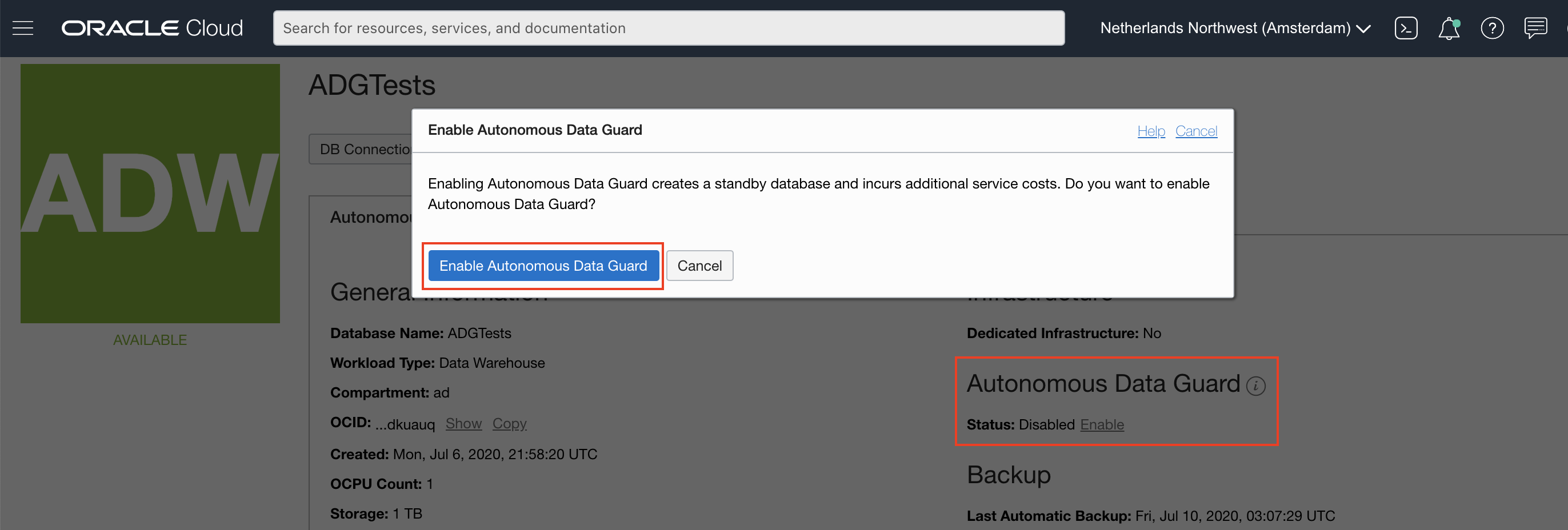
You’re done, that’s all you need to do to protect your database! You will now see your peered standby database in a Provisioning state until it becomes Available; depending on the size of your primary database this may take several minutes. Note that when you switch your standby to make it your primary as described below, you will not need a new wallet – Your existing wallet will continue to work seamlessly!
Everything that follows describes features you will use either in a disaster type scenario, or to test your applications / mid-tiers against your Autonomous Database with ADG,
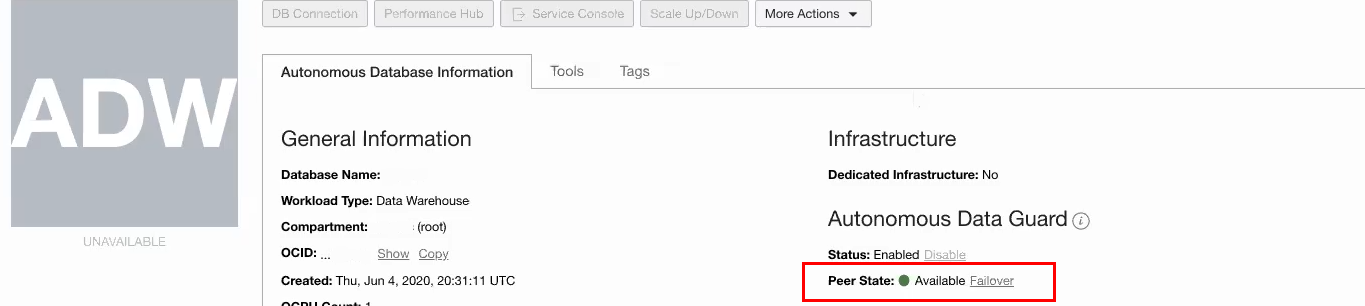
Failover – When your Primary database goes down, you are automatically protected by your Standby database
If a disaster were to occur and your primary database is brought down, you can “Failover” to your standby. A failover is a role change, switching from the primary database to the standby database when the primary is down and Unavailable, while the standby is Available.
-
An Automatic Failover is automatically triggered (no user action needed) by the Autonomous Database when a user is unable to connect to their primary database for a few minutes. Since this is an automated action, we err on the side of caution and allow auto-failovers to succeed only when we can guarantee no data loss will occur.
For automatic failover, RTO is 2 minutes and RPO is 0 minutes. -
In the rare case when your primary is down and Automatic Failover was unsuccessful, the Manual Failover button may be triggered by you, the user. During a manual failover, the system automatically recovers as much as data as possible minimizing any potential data loss; there may be a few seconds or minutes of data loss. You would usually only perform a Manual Failover in a true disaster scenario, accepting the few minutes of potential data loss to ensure getting your database back online as soon as possible.
For manual failover, the RTO is 2 minutes and RPO is 1 minute.
After a failover, a new standby for your primary will automatically be provisioned.
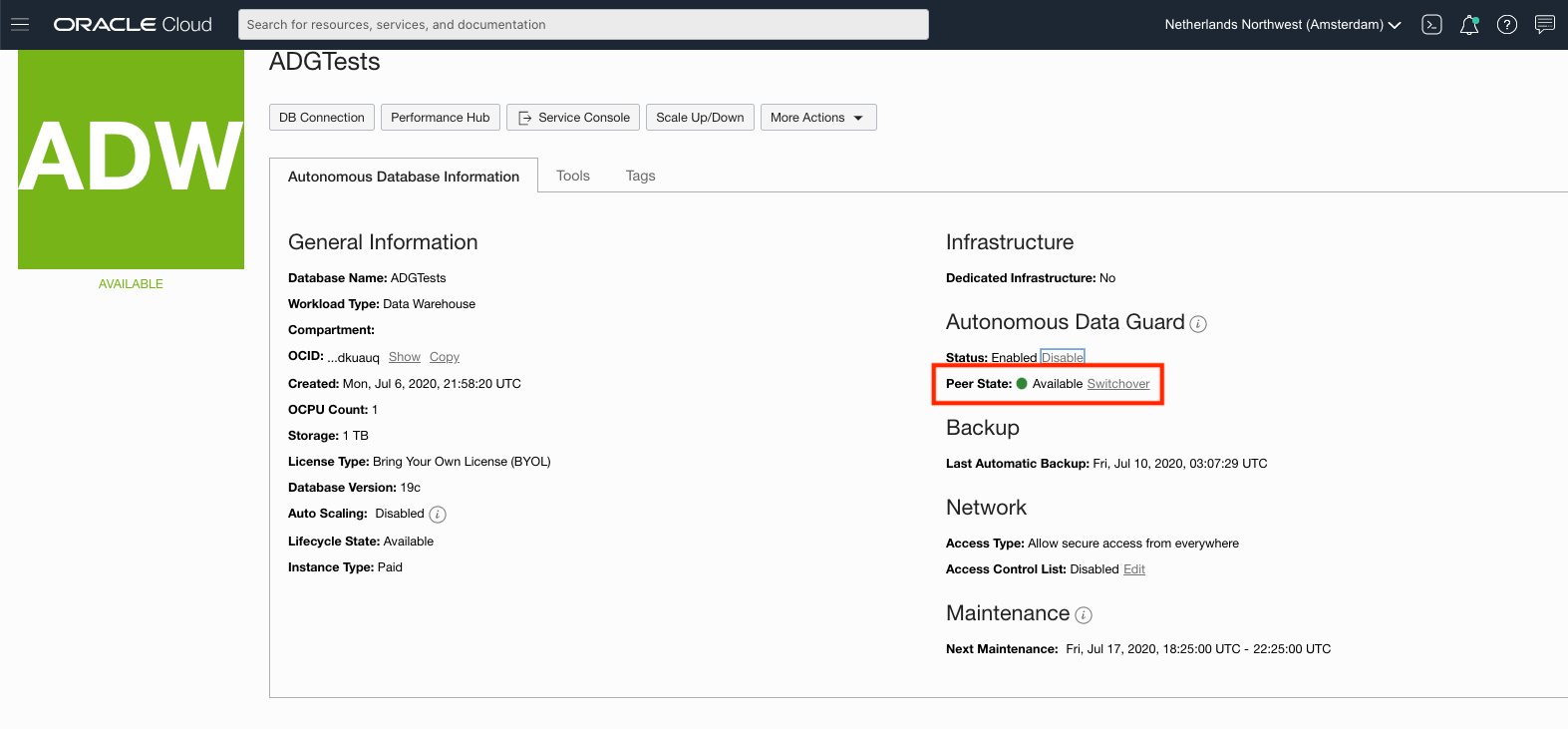
Switchover – Test your applications with Autonomous Data Guard when both databases are healthy
When your standby is provisioned, you will see a “Switchover” option on the console while your primary and standby databases are both healthy (ie. in the Available or Stopped states). Clicking the Switchover button performs a role change switching from the primary database to the standby database, which may take a couple of minutes, with no data loss guaranteed.
You would usually perform a Switchover to test your applications against this role change behaviour of the primary.
We talked above about the buttons on the UI console. Of course, as with the rest of Oracle’s cloud platform, there are Autonomous Database APIs for all actions including Switchover and Failover that can be called at any time. You may also subscribe to Events to be notified of your standby’s operations.
Wrapping Up
While we ideated over Autonomous Data Guard, our primary focus has been that it should just work, with nothing for a user to do. My hope is that every user with a production database out there takes advantage of this simplicity and is able to further minimize their business’ operational downtime and data loss. For all the details about Autonomous Data Guard features please refer to the official documentation and for updated pricing refer to the service description.
Stay tuned for Part 2 of this post later this year, once we are ready to announce Autonomous Data Guard across regions!
