Got a little busy there with all the comments on the Netezza posting, but now we’re back into some of the outstanding topics. This post is the next one on discussing some of the ODTUG session questions (see this post).
One of the questions was about the use of partitioning and whether it is made obsolete by Exadata off-loading…
In other words, should you look at one, the other or both? The answer is that you will want both, and there are a variety of reasons for that.
First of all, on the query side you will hopefully be using partitioning (often range partitioning) for partition elimination. From an I/O perspective that looks roughly like this*:
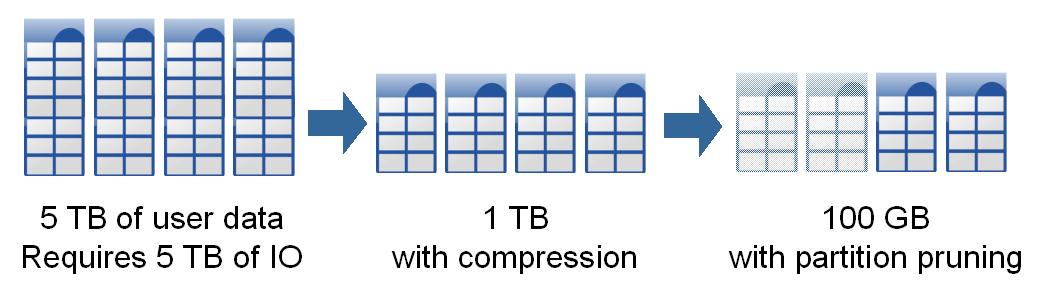
In essence, partition pruning allows you to reduce a 5TB I/O operation to a much smaller I/O operation and therefore much faster return of the information. Compression is something that may or may not be used. In this example we are compressing the data and further reducing the I/O numbers.
So far there is nothing new here, with Exadata however you will see a further reduction. After applying a smart scan, both the rows returned (remember Exadata is smart storage and actually knows rows and columns should be returned!) and the columns returned are further reduced. This is on top of partitioning. You will get something like this:
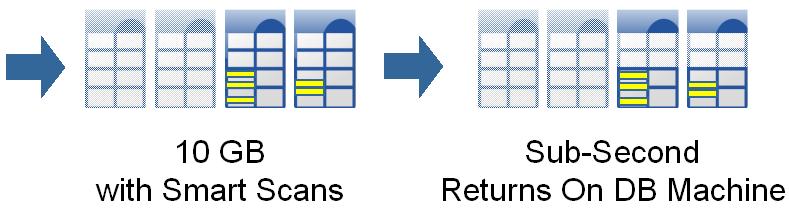
The conclusion from a query and I/O perspective is therefore that you will benefit from both.Obviously, in the above case both partitioning and smart scans work in conjunction to create nice dramatic effects… which are real in many scenarios. Oftentimes however a query will benefit from either pruning or from a smart scan. Not having one or the other will therefore diminish the overall performance.
There is another aspect that should be considered as well. That is parallel processing. With the Oracle Database Machine we put a whole bus load of cores onto your data. Both at the storage tier as well as the compute tier. This inevitably means you want to do most of the work – on large data sets – in parallel. Hash partitioning plays a crucial role in parallel processing as you can do parallel joins within a set of query slaves. The slaves do not have to talk to someone else if both sides of the join are hash partitioned on the same hash key.
So, on a Database Machine, partitioning will allow you to leverage the parallel power of the system. Again, you want partitioning on an Exadata system…
* Just as a disclaimer — the numbers are for illustration only.
