Big Data SQL 4.0 introduces a data processing enhancement that can have a dramatic impact on query performance: distributed aggregation using in-memory capabilities.
Big Data SQL has always done a great job of filtering data on the Hadoop cluster. It does this using the following optimizations: 1) column projection, 2) partition pruning, 3) storage indexes, 4) predicate pushdown.
Column projection is the first optimization. If your table has 200 columns – and you are only selecting one – then only a single column’s data will be transferred from the Big Data SQL Cell on the Hadoop cluster to the Oracle Database. This optimization is applied to all file types – CSV, Parquet, ORC, Avro, etc.
The image below shows the other parts of the data elimination steps. Let’s say you are querying 100TB data set.

- Partition Pruning: Hive partitions data by a table’s column(s). If you have two years of data and your table is partitioned by day – and the query is only selecting 2 months – then in this example, 90% of the data will be “pruned” – or not scanned
- Storage Index: SIs are a fine-grained data elimination technique. Statistics are collected for each file’s data blocks based on query usage patterns – and these statistics are used to determine whether or not it’s possible that data for the given query is contained within that block. If the data does not exist in that block, then the block is not scanned (remember, a block can represent a significant amount of data – oftentimes 128MB). This information is automatically maintained and stored in a lightweight, in-memory structure.
- Predicate Pushdown: Certain file types – like Parquet and ORC – are really database files. Big Data SQL is able to push predicates into those files and only retrieve the data that meets the query criteria
Once those scan elimination techniques are applied, Big Data SQL Cells will process and filter the remaining data – returning the results to the database.
In-Memory Aggregation
In-memory aggregation has the potential to dramatically speed up queries. Prior to Big Data SQL 4.0, Oracle Database performed the aggregation over the filtered data sets that were returned by Big Data SQL Cells. With in-memory aggregation, summary computations are run across the Hadoop cluster data nodes. The massive compute power of the cluster is used to perform aggregations.
Below, detailed activity is captured at the customer location level; the query is asking for a summary of activity by region and month.
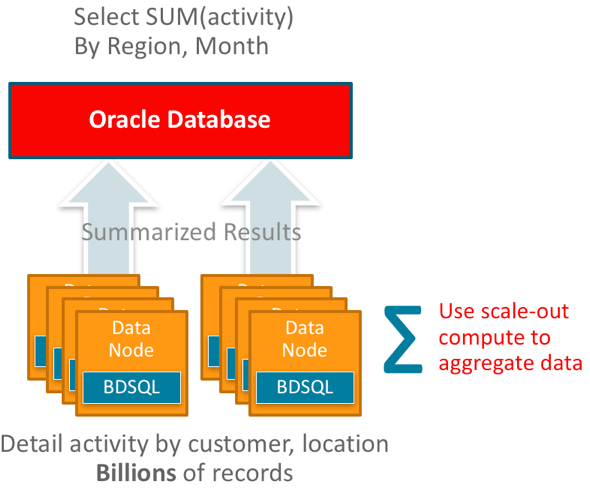
When the query is executed, processing is distributed to each data node on the Hadoop cluster. Data elimination techniques and filtering is applied – and then each node will aggregate the data up to region/month. This aggregated data is then returned to the database tier from each cell – and the database then completes the aggregation and applies other functions.
Big Data SQL is using an extension to the in-memory aggregation functionality offered by Oracle Database. Check out the documentation for details on the capabilities and where you can expect a good performance gain.
The results can be rather dramatic, as illustrated by the chart found below:
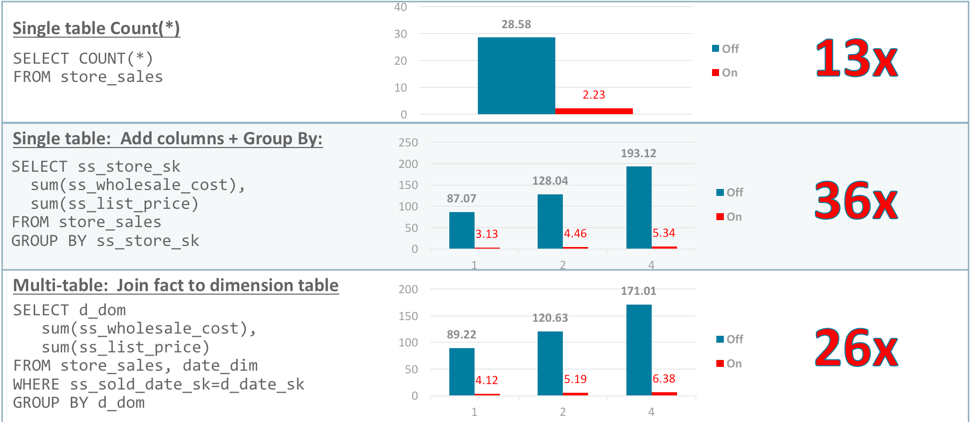
This test compares running the same queries with aggregation offload disabled and then enabled. It shows 1) a simple, single table “count(*)” query, 2) a query against a single table that performs a group by and 3) a query that joins a dimension table to a fact table. The second and third examples also show increasing the number of columns accessed by the query. In this simple test, performance improved from 13x to 36x :-).
Lots of great new capabilities in Big Data SQL 4.0. This one may be my favorite :-).
