In the previous post in this series we looked at how we can configure and control Auto DOP and we have explained which initialization parameters are used for that. Now let’s look at how HW characteristics and object statistics are used by the optimizer and how they impact the computation of the DOP.
The optimizer needs two things to compute the DOP for a statement, the amount of work to be done and the HW characteristics of the system.
Amount of work
For every operation in the plan the optimizer calculates the work in terms of the data size that operation processes, this is expressed in terms of bytes and number of rows. The source of this information is object statistics so like most anything else related to the optimizer keeping the object statistics up-to-date is very important for Auto DOP too.
Processing rates
Besides the amount of work the optimizer also needs to know the HW characteristics of the system to understand how much time is needed to complete that amount of work. Consequently, the HW characteristics decribe how much work a single process can perform on that system, these are expressed as bytes per second and rows per second and are called processing rates. As they indicate a system’s capability it means you will need fewer processes (which means less DOP) for the same amount of work as these rates go higher; the more powerful a system is, the less resources you need to process the same statement in the same amount of time.
There are two kinds of processing rates, IO and CPU. Let’s look at how they are used in versions 11.2 and 12.1.
Processing rates in 11.2
11.2 uses only the IO processing rate which is expressed as IO megabytes per second. This rate shows how much IO a single process can perform per second. There are two methods to populate this value, you can run IO calibration, or you can manually insert or update the value in the RESOURCE_IO_CALIBRATE$ table as explained in MOS note 1269321.1. Both of these methods require an instance restart to take effect.
You can query DBA_RSRC_IO_CALIBRATE to see the value for this processing rate.
select MAX_PMBPS from DBA_RSRC_IO_CALIBRATE;
If you do not run IO calibration and if you have not manually inserted this value Auto DOP will not be used and you will see a related note in the plan output.
- automatic DOP: skipped because of IO calibrate statistics are missing
The recommended value for Exadata for this is 200MB/sec. This is the value you will get if you use the Exadata dbm template when creating the database.
11.2 looks at only scan operations and uses the object statistics and the IO processing rate to compute a DOP for each scan operation. The maximum of these operation DOPs is chosen as the statement DOP.
Note that this was a conscious decision to alleviate the first switch to Auto DOP for customers. A common practice of users of manual DOP was to pick DOP values as object attributes based on the object size; for example, a customer could choose to set all tables below 2GB to serial, tables between 2GB and 10GB to a DOP of 4, and all tables larger than 10GB to a DOP of 16 as “default” for his or her system. Auto DOP to some extent mimics such a practice, albeit with more flexibility.
In the following example only plan line id 8 effects the DOP as it is the only scan operation.
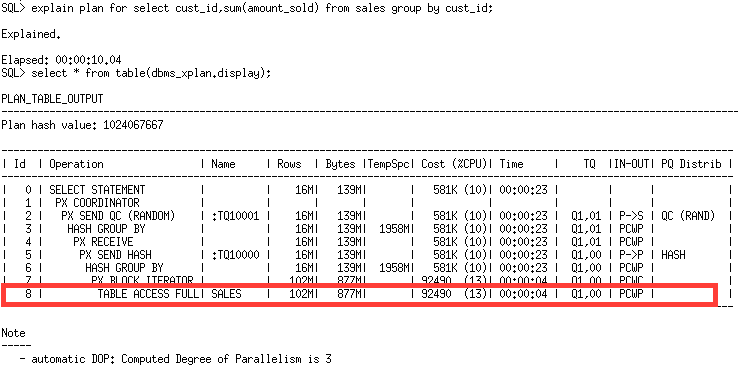
You can use the ADVANCED format option of DBMS_XPLAN to see the where the DOP comes from.
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY(format=>'advanced'));
It displays the object that derived the DOP decision.

Processing rates in 12.1
The most significant difference between 12.1 and 11.2 is that Auto DOP now takes more processing rates into account as it uses the CPU and IO cost of all operations.
12.1 uses the IO processing rate just like 11.2 did. The most important difference is that 12c does not require this value to be populated. It uses a default value of 200MB/sec when this value is not set by the user. If you already have this value set you can keep it as is. If you are in 12.1 and starting to use Auto DOP we recommend starting with the default value.
One of the drawbacks of Auto DOP in 11.2 was the lack of CPU costing which could lead to CPU-heavy statements to run with a DOP that was deemed too low. Since each operation in a plan requires CPU as well, the optimizer needs to take the CPU operations into account as well to compute a DOP that reflects the real resource usage of a statement. That is why CPU processing rates were introduced in 12.1. There are basically two CPU rates used for Auto DOP, bytes per second and rows per second. These specify how much data a single process on the CPU can process per second.
All of these three processing rates are set to default values in 12.1 and they are stored in the new view V$OPTIMIZER_PROCESSING_RATE.
SQL> select OPERATION_NAME, DEFAULT_VALUE
2 from V$OPTIMIZER_PROCESSING_RATE
3 where OPERATION_NAME in ('IO_BYTES_PER_SEC','CPU_BYTES_PER_SEC', 'CPU_ROWS_PER_SEC');
OPERATION_NAME DEFAULT_VALUE
-------------------- --------------------
IO_BYTES_PER_SEC 200.00000
CPU_BYTES_PER_SEC 1000.00000
CPU_ROWS_PER_SEC 1000000.00These values indicate a single process can scan 200MB/sec, it can process 1GB/sec or 1,000,000 rows/sec. These are the default values and we recommend starting with these defaults.
If you want to change these values you can use the new procedure DBMS_STATS.SET_PROCESSING_RATE to set them manually. In this case the values will be populated in the MANUAL_VALUE column of V$OPTIMIZER_PROCESSING_RATE. Unfortunately because of a bug the optimizer will not start using the values you set manually immediately, you need to set the parameter _optimizer_proc_rate_source to MANUAL for them to take effect. We will fix this bug so that manually set values will be used immediately without changing any parameters.
For the IO rate in 12.1 you still can use the old methods explained for 11.2 and the value you set will be reflected in this new view, but we recommend not using those methods and use this new procedure instead for both IO and CPU processing rates.
There is a simple reason for this: “overloading” the collection of IO statistics on a system with having a direct impact on the calculation of Auto DOP turned out to be not the best decision we made, so we are going to fix this (we had cases where people ran IO calibration to see what their system was capable of and inadvertently changed their system’s Auto DOP behavior).
When computing the DOP for a statement, unlike 11.2, 12.1 looks at all operations and also the plan shape. It computes two separate DOPs for each operation, one based on IO rates, the other based on CPU rates, these are called IO DOP and CPU DOP respectively. For the CPU DOP it uses both CPU_BYTES_PER_SEC and CPU_ROWS_PER_SEC and uses the one that gives a higher DOP. The highest of the IO DOP and CPU DOP is chosen as the operation DOP. The optimizer then looks at the plan shape and calculates the statement DOP based on operation DOPs.
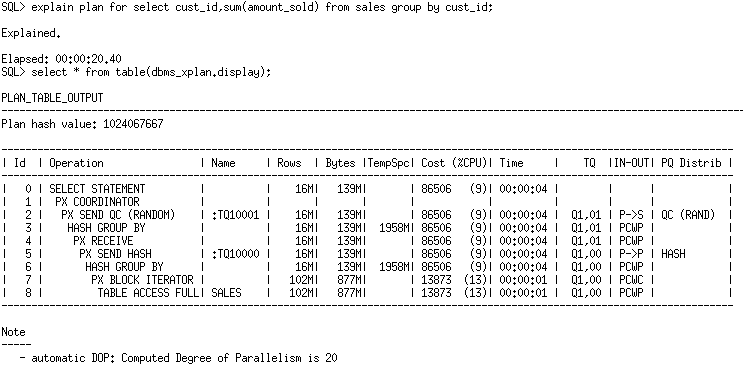
Since 12.1 takes into account all operations rather than only IO operations you can get higher DOPs in 12.1 compared to 11.2. Using the previous sample query you now get a DOP of 20 in 12.1 compared to a DOP of 3 in 11.2.
So, what should I do now?
For users who are switching to Auto DOP, in 11.2 we recommend starting with a value of 200MB/sec for the IO rate.
In 12.1 we recommend not running IO calibration at all and starting with the default IO and CPU processing rates. Based on your testing you can change these values, increase them for lower DOPs, or decrease them for higher DOPs.
For users already using Auto DOP just keep what you have if you are happy with your current DOPs. If you are on 11.2 and upgrading to 12.1 start with the enhanced cost model that includes CPU costing as well and leave the default CPU rates; no need to touch the IO rate as you already have the IO rate set in 11.2. Be aware that the DOPs can change after the upgrade as the optimizer will start using the CPU processing rates in addition to the IO rate, which is a good thing from all we have seen so far; CPU intensive queries will just pick a higher, more accurate DOP. However, do not take this as blind rule: as for all upgrades you need to test your workload to make sure you are satisfied with the DOP changes.
