The Real-Time SQL Monitoring feature (SQL Monitor) was introduced in 11g to make it easier to monitor the execution of long-running SQL statements. As of 12c this tool is part of both Oracle Enterprise Manager Cloud Control and Oracle Enterprise Manager Database Express.
SQL Monitor is especially helpful in monitoring parallel statements as these statements access, join, aggregate and analyze large amounts of data. In this post we talk about how to use SQL Monitor to monitor parallel statements. It requires a basic understanding of how parallel execution (PX) works, for an introduction to Oracle Parallel Execution please see the white paper Oracle Parallel Execution Fundamentals. The examples used here were taken from Oracle Enterprise Manager Database Express on a 12.1.0.2 database. You can click on the images to see the full size versions of the screenshots.
General View of Monitored Statements
The main page of SQL Monitor shows all monitored statements, their statuses, durations, degree of parallelism (DOP), and the database time they consumed.
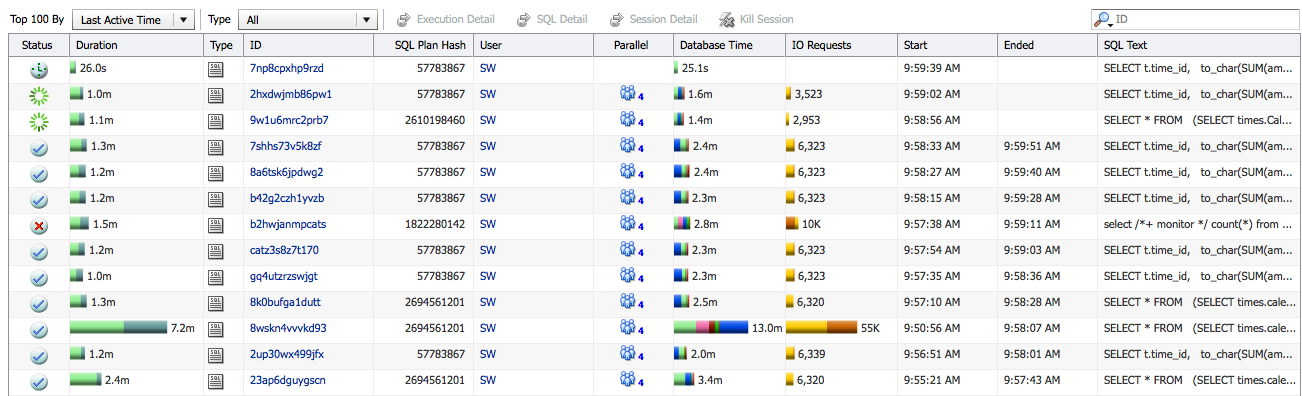
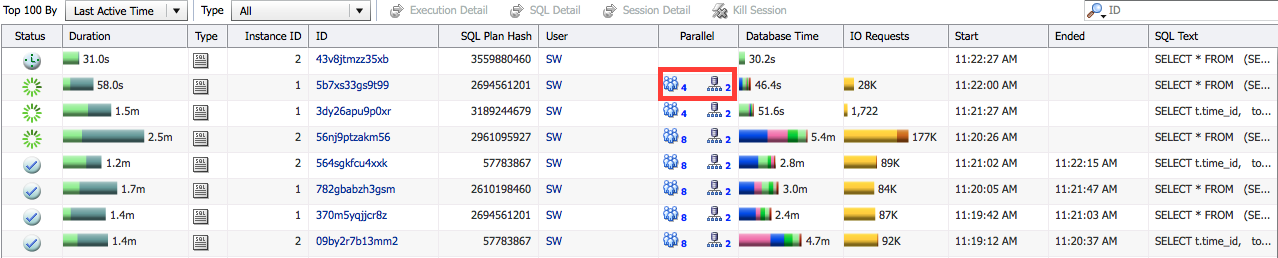
For Real Application Clusters (RAC) databases this page also shows the number of instances used for each statement.
The Status column indicates whether a statement is running, finished, or queued. The clock icon ( ) means the statement is queued, the throbber icon (
) means the statement is queued, the throbber icon ( ) means the statement is running, and the checkmark icon (
) means the statement is running, and the checkmark icon ( ) means the statement is completed. The cross icon (
) means the statement is completed. The cross icon ( ) means the statement was cancelled, killed, or got an error. You can see the actual error message when you hover over that icon.
) means the statement was cancelled, killed, or got an error. You can see the actual error message when you hover over that icon.

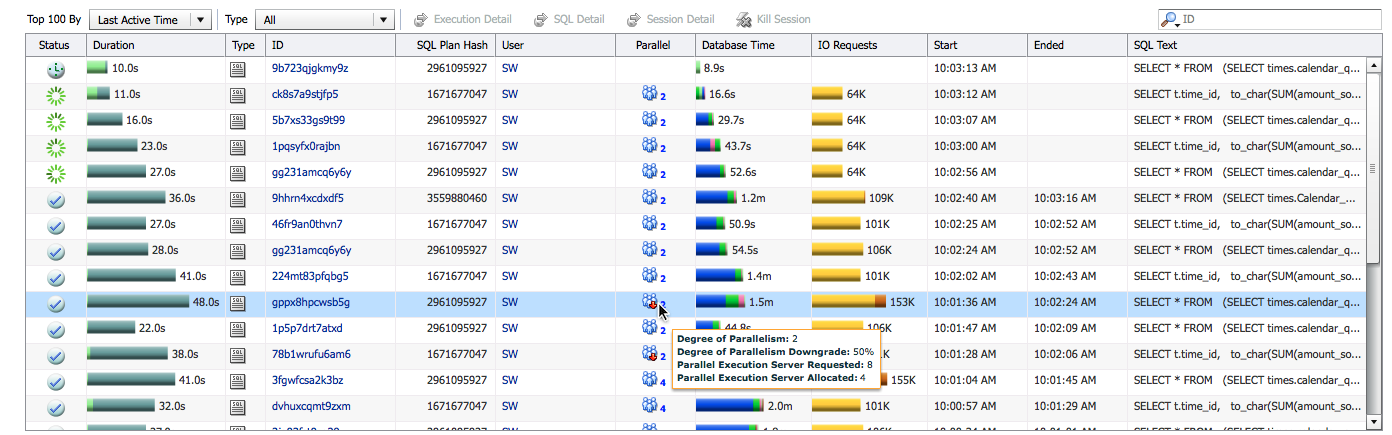
The Parallel column shows the actual degree of parallelism (DOP) for the statement. A down arrow icon ( ) indicates that the DOP was downgraded. When you hover over it you can see the downgrade percentage, the number of parallel execution (PX) servers requested, and the number of PX servers allocated.
) indicates that the DOP was downgraded. When you hover over it you can see the downgrade percentage, the number of parallel execution (PX) servers requested, and the number of PX servers allocated.
SQL Execution Details
To look at the details of a statement, click on the SQL_ID (found in the ID column) of that statement. This takes you to the SQL Monitor report for that specific statement. The SQL Monitor report shows general information like SQL text, elapsed time, DOP, time and wait statistics, as well as detailed execution plan statistics. This helps us to find out where the execution time was spent and focus on those areas for performance tuning.
For statements that are still running a green arrow icon ( ) indicates the steps that are currently being executed. The page refreshes every 15 seconds so that you can monitor the progress of those statements. You can change the refresh interval at the top right of the screen or you can use the refresh button (
) indicates the steps that are currently being executed. The page refreshes every 15 seconds so that you can monitor the progress of those statements. You can change the refresh interval at the top right of the screen or you can use the refresh button (  ) at the top right to manually refresh the page.
) at the top right to manually refresh the page.
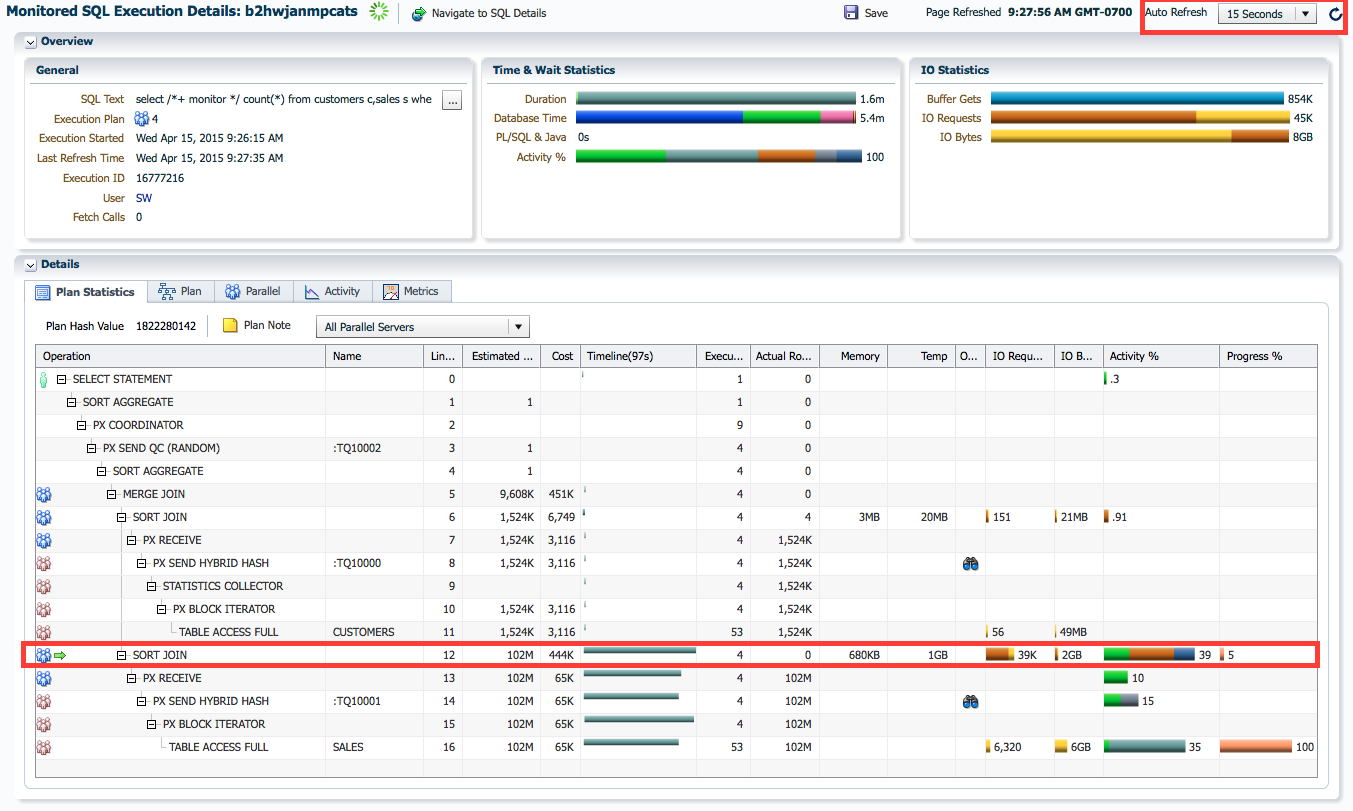
For completed statements the report shows the final statistics for that execution of the statement.
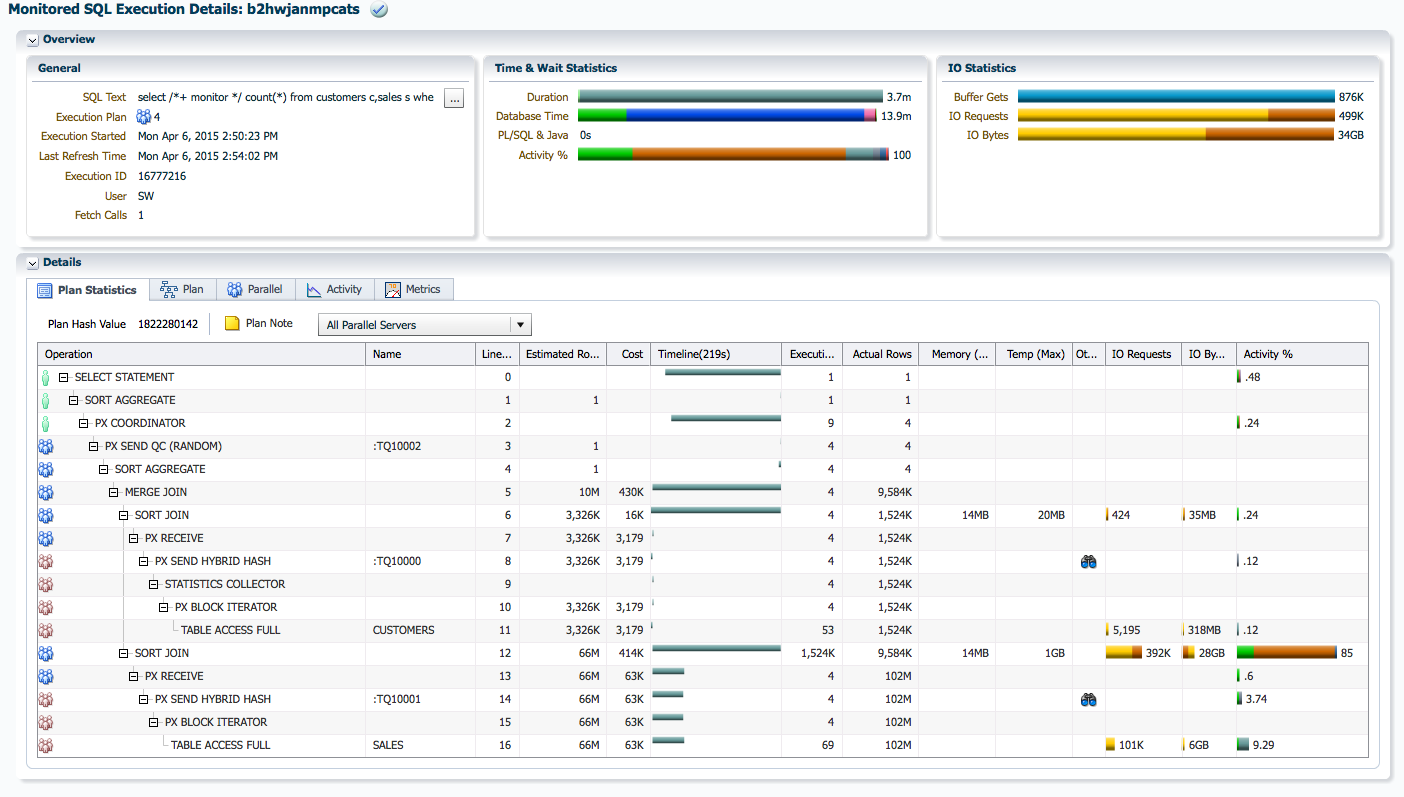
Let’s walk through a sample SQL Monitor report to find out what information it provides about parallel execution. The report used in this example can be found here.
Degree of Parallelism (DOP)
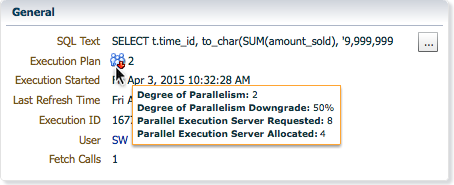
There are two places in the SQL Monitor report that show information about the DOP. First, you can see the runtime DOP in the General section.
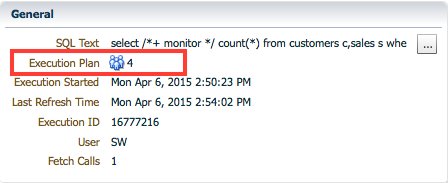
For RAC databases the same section also shows the number of instances used for parallel execution.
Second, you can click the Plan Note button in the Details section to find out more about the DOP.
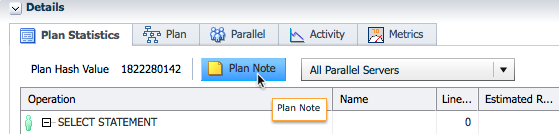
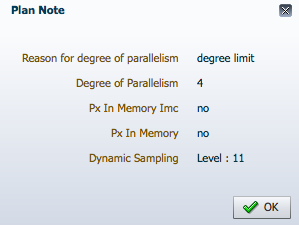
The Plan Note shows the requested DOP and the reason for picking that DOP. In this example we see that the DOP was set to 4 because of the parallel degree limit (set by the parallel_degree_limit parameter or set by the resource manager parallel_degree_limit_p1 directive).
If the DOP is downgraded the General section shows it with a down arrow icon ( ), when you hover over it you can see the downgrade percentage, the number of PX servers requested, and the number of PX servers allocated. In the following example a downgrade percentage of 50% indicates a DOP of 4 was requested but the DOP was downgraded to 2. The number of PX servers allocated was 4 (2 * DOP) in this example, it is because this statement had 2 sets of PX servers as a result of the producer-consumer model used in parallel execution.
), when you hover over it you can see the downgrade percentage, the number of PX servers requested, and the number of PX servers allocated. In the following example a downgrade percentage of 50% indicates a DOP of 4 was requested but the DOP was downgraded to 2. The number of PX servers allocated was 4 (2 * DOP) in this example, it is because this statement had 2 sets of PX servers as a result of the producer-consumer model used in parallel execution.
To find out why the DOP was downgraded you can look at the OTHER column for the PX COORDINATOR line in the Plan Statistics tab in the Details section.

This shows the runtime DOP and the reason for the downgrade.

Possible downgrade reasons are:
- 350 = DOP downgrade due to adaptive DOP
- 351 = DOP downgrade due to resource manager max DOP
- 352 = DOP downgrade due to insufficient number of processes
- 353 = DOP downgrade because slaves failed to join
In-Memory Parallel Execution
Plan Note also shows whether the statement uses in-memory affinity which makes sure the PX servers are allocated on the RAC nodes where in-memory tables reside, and whether In-Memory Parallel Execution is used. In this example, the statement did not use in-memory affinity (Px In Memory Imc is “no”), and it did not use In-Memory Parallel Execution (Px In Memory is “no”).
Time & Wait Statistics
The Time&Wait Statistics section shows the elapsed time, the database time, and the CPU and wait activity percentages for the statement.
The Duration bar breaks down the elapsed time into queue time and running time. In this example, we can see that the elapsed time is 3.7 minutes, the statement waited in the parallel statement queue for 9.3ms and had a running time of 3.6 minutes after queuing.
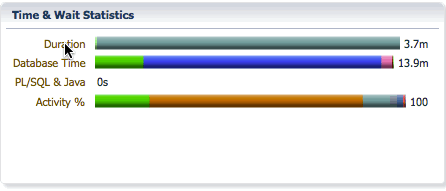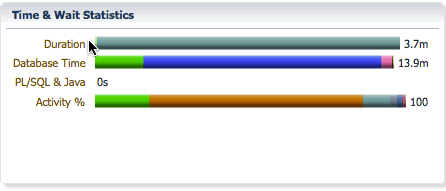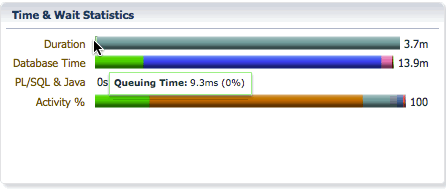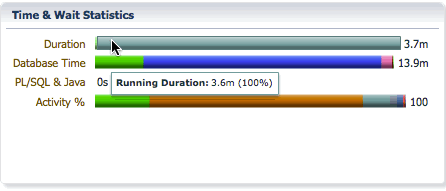
The Database bar shows us the same information as it does for a serial statement, the difference is the database time will be much higher than the elapsed time as the database time for all PX servers are accumulated in this number. It shows the CPU time and wait times classified into wait event classes like user I/O, concurrency, etc… In this example, we see that we spent 2.3 minutes on CPU, 11.1 minutes on I/O, etc…
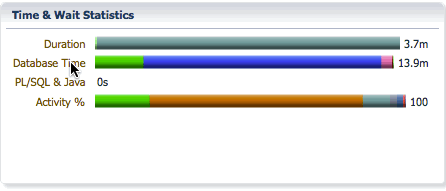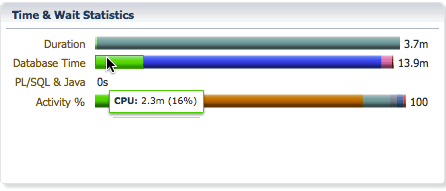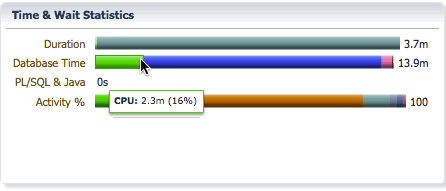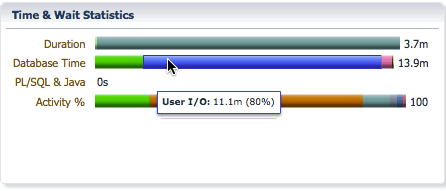
The Activity bar shows the percentage of CPU time and wait times so that we can focus on the most time consuming event for performance tuning. In this example, we see that we spent 18% of the time on CPU, 69% of the time in direct path temp writes, and about 8.8% of the time in direct path temp reads.
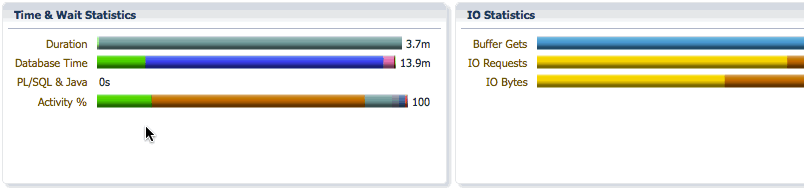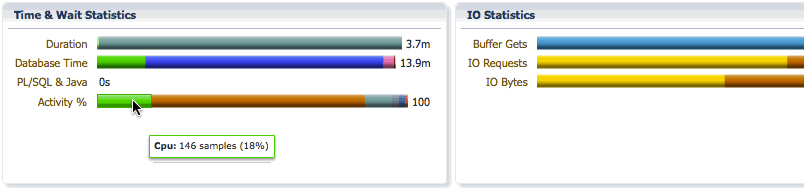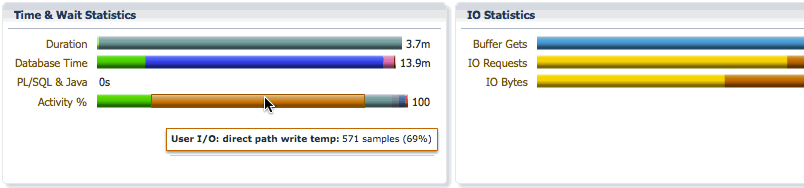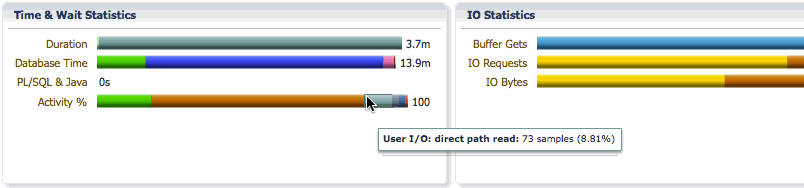
PX Server Sets
The Plan Statistics tab in the Details section shows the execution plan and runtime statistics for each plan step like the number of rows processed, wait events, number of IOs, etc… This section also shows the PX coordinator and the PX server sets indicating which operation was executed by which.
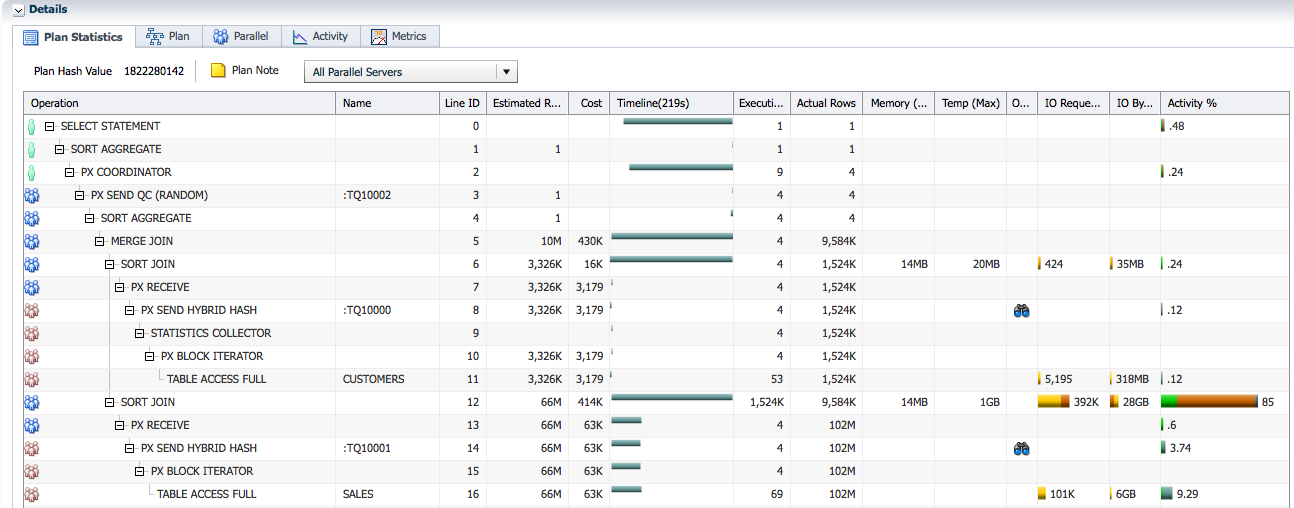
The PX coordinator is shown with a person icon (![]() ), each PX server set is shown as a people icon with a different color. In this example we see two sets, one red (
), each PX server set is shown as a people icon with a different color. In this example we see two sets, one red ( ) and one blue(
) and one blue( ). The red set executed the operations with Line IDs 8-11 and 14-16 whereas the blue set executed the operations with Line IDs 3-7 and 12-13. Since the DOP is 4, each set has 4 PX servers. The operations executed by the PX coordinator were Line IDs 0-2.
). The red set executed the operations with Line IDs 8-11 and 14-16 whereas the blue set executed the operations with Line IDs 3-7 and 12-13. Since the DOP is 4, each set has 4 PX servers. The operations executed by the PX coordinator were Line IDs 0-2.
Parallel Distribution Methods
Plan Statistics shows the parallel distribution methods in the plan, just like the output of the Explain Plan command.
In the case of adaptive parallel distribution where the distribution method is decided in runtime, SQL Monitor shows the runtime distribution method used in the OTHER column of the corresponding plan line. In this example, we see that an adaptive distribution method was used (HYBRID HASH).
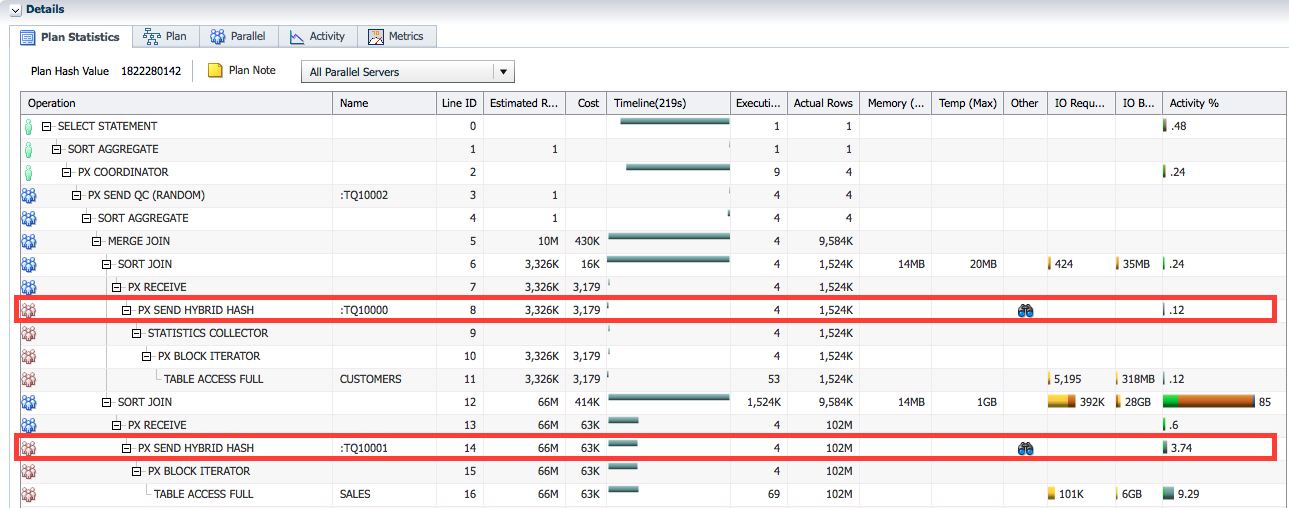
When you click on the binocular icon ( ) in the OTHER column of the related lines (Line IDs 8,14) the runtime distribution is shown.
) in the OTHER column of the related lines (Line IDs 8,14) the runtime distribution is shown.

Possible runtime distribution methods for adaptive distribution are:
- 5 = Round-robin
- 6 = Broadcast
- 16 = Hash
CPU, IO, and Memory Usage
The Metrics tab shows you information about the CPU, IO, and memory usage of the statement. You can see the number of CPUs used, the IO and memory throughput, the number of reads and writes, amount of memory and temporary space used.
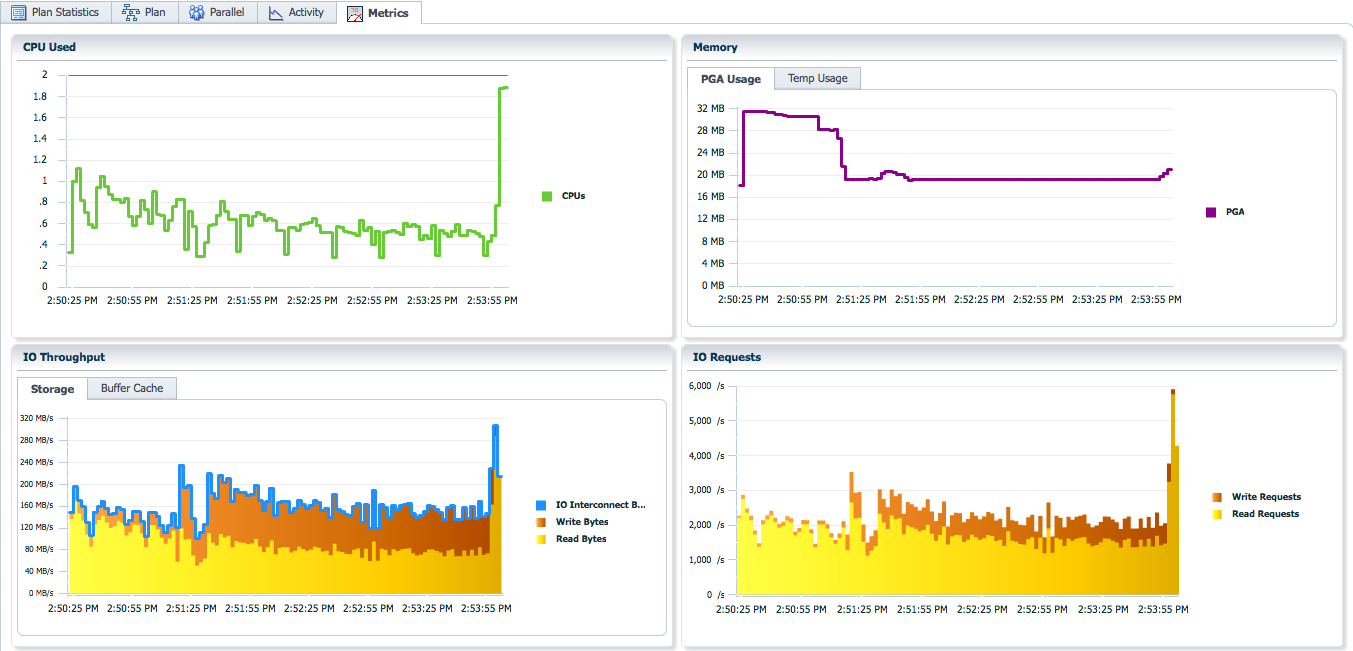
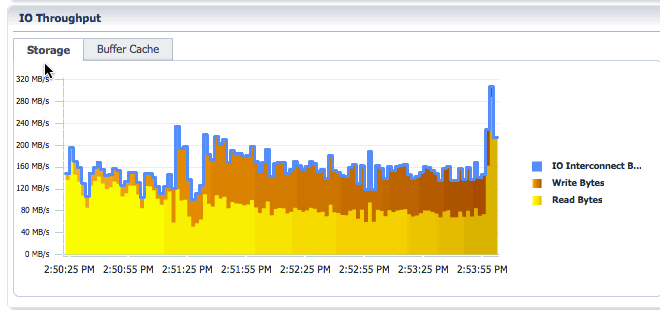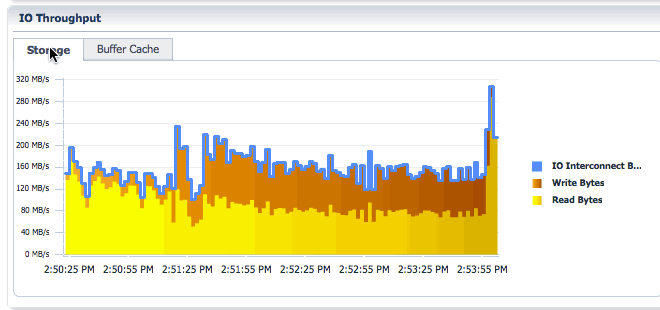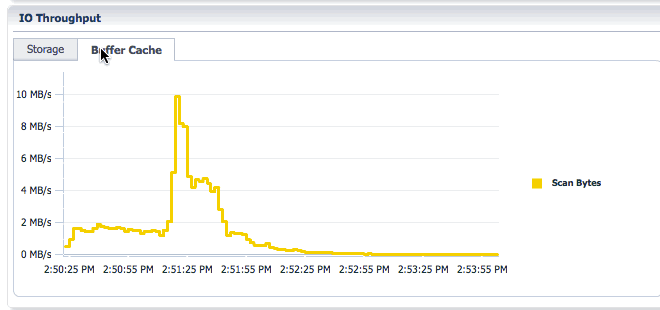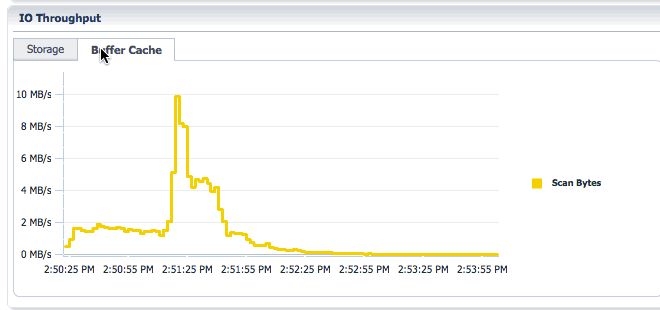
You can toggle between Storage and Buffer Cache tabs in the IO throughput section to look at the IO throughput and the memory (buffer cache) throughput.
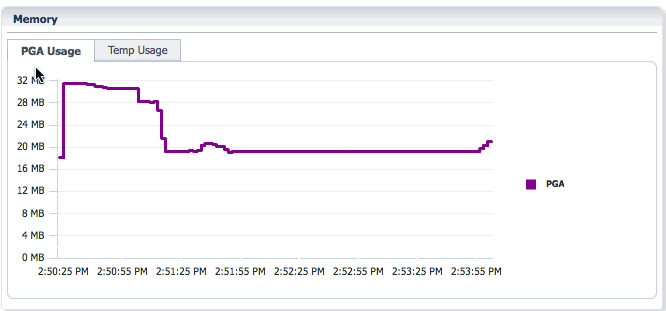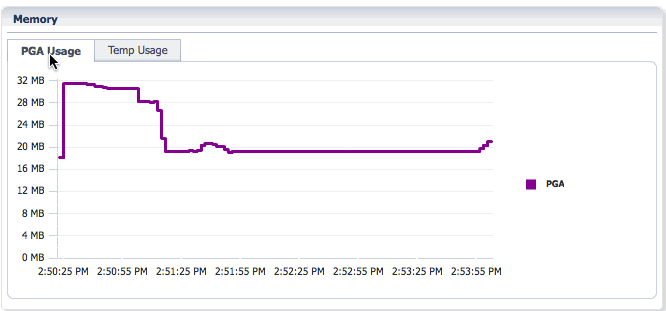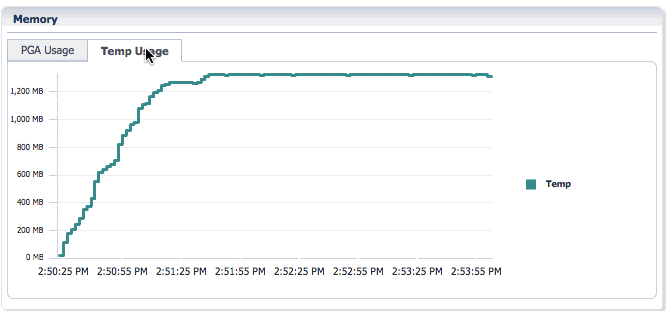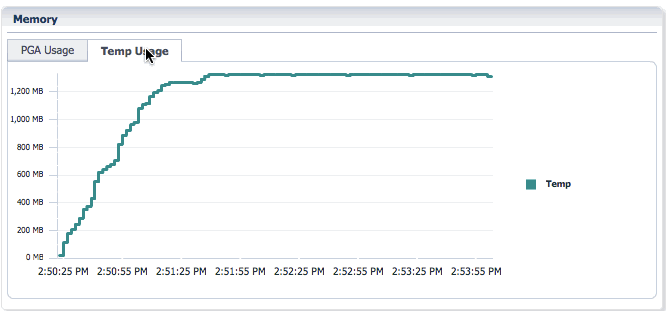
You can toggle between PGA Usage and Temp Usage to look at the PGA memory usage and temporary space usage for the statement.
Work Distribution Across PX Servers
You can look at individual PX servers and their activity statistics in the Parallel tab.

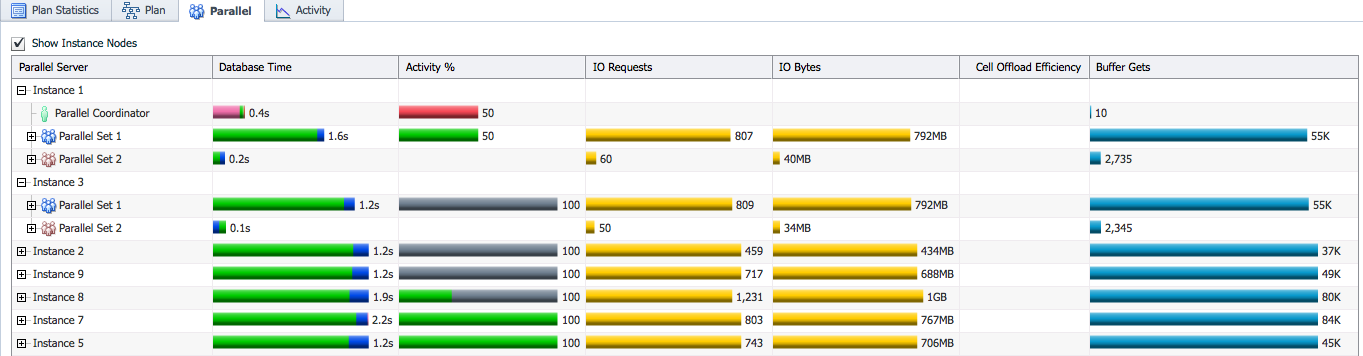
This shows you the database time spent by each PX server set and their activity percentages compared to the total time. Here, we see that parallel set 1 consumed 11.8 minutes of database time and parallel set 2 consumed 2.1 minutes. 86% of the activity was done by parallel set 1 and 13% of the activity was done by parallel set 2. The variance between the database time consumed by different PX sets is not critical as it depends on what operations are executed by each set.
The important thing to be careful about is the distribution of work across PX servers in a single set. If you expand the parallel sets you can see the activity of individual PX servers.
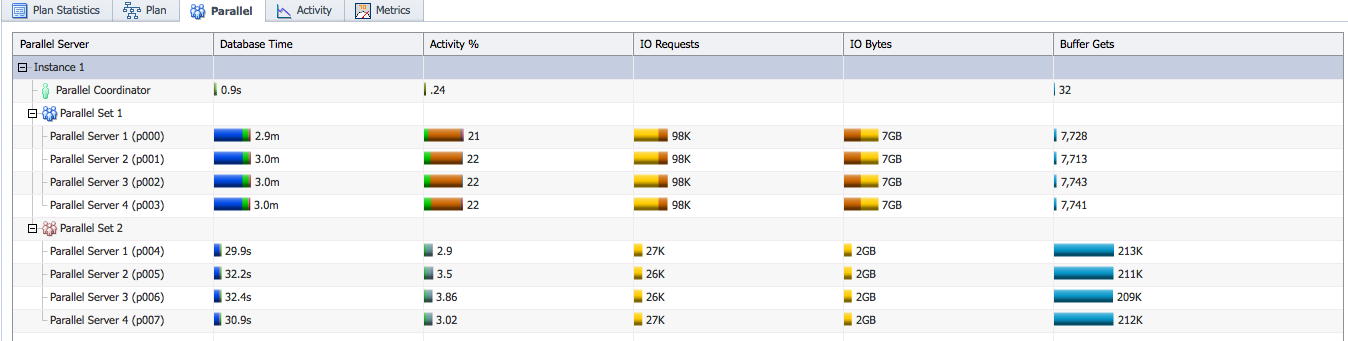
The database time spent by each PX server gives a picture of how the work was distributed between PX servers. If the database time of each PX server is similar, it means every PX server performed equal amount of work. If the database time difference between PX servers is high that may indicate a problem with the data and work distribution between PX servers. This results in lower utilization of some PX servers which in turn results in bad performance. In this example, we see that each PX server in parallel set 1 performed about 21%-22% of the work, and each PX server on parallel set 2 performed about 2%-3% of the work, this indicates that the work was distributed equally across PX servers.
Here is a sample SQL Monitor report showing inequal work distribution across PX servers.
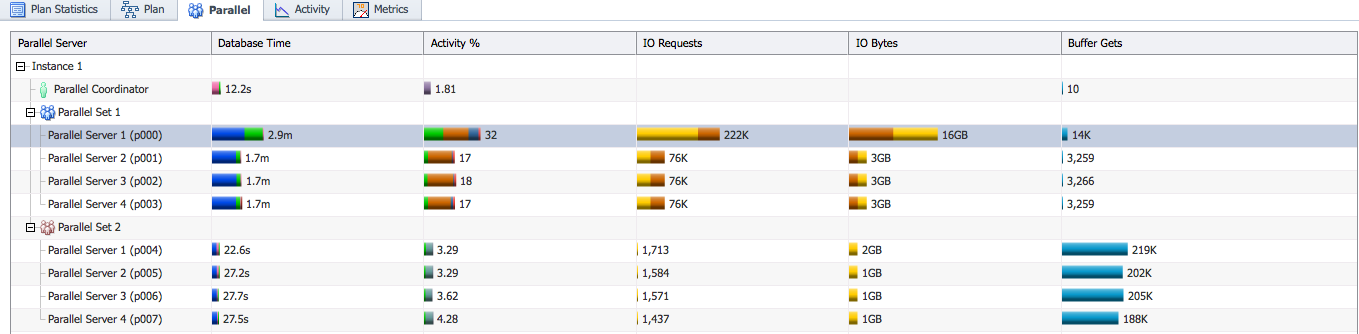
In this example, the process p000 consumed much more database time compared to other processes in the same set (p001, p002, p003). This indicates the performance of this query would be better if each PX server performed similar amount of work. To find out why this process did more work you can go to the Plan Statistics tab and look at the runtime statistics for that individual process. Near the Plan Note button there is a list of PX servers consuming significant amount of database time.
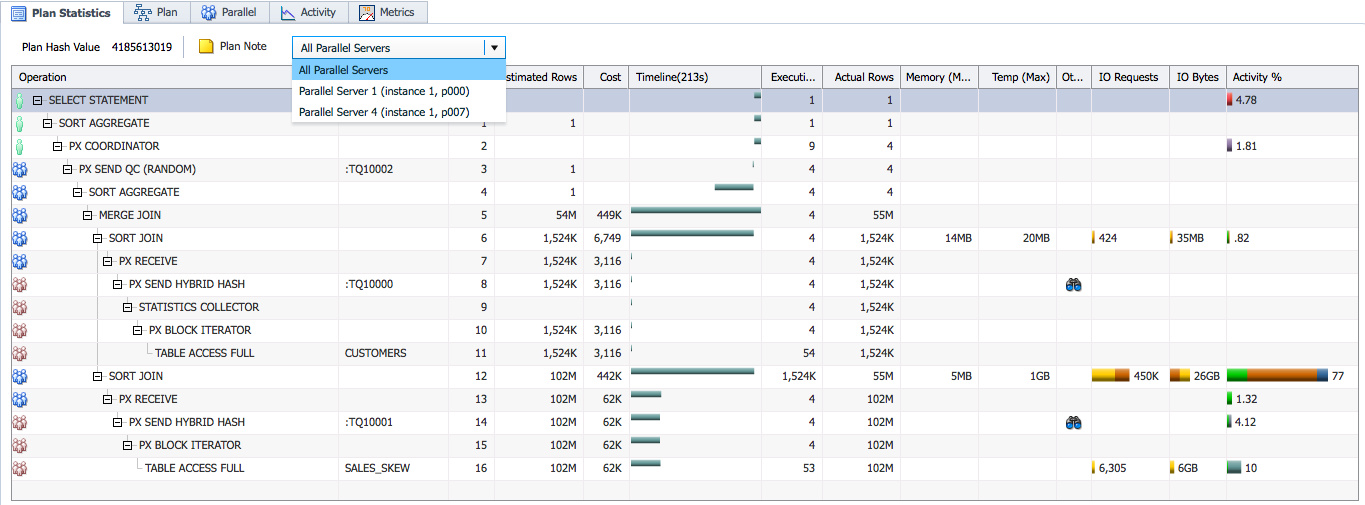
If we look at the statistics for the process p000 we see that it spent most of the time in the join operation, and it processed 51M rows of the SALES_SKEW table (Line ID 12).
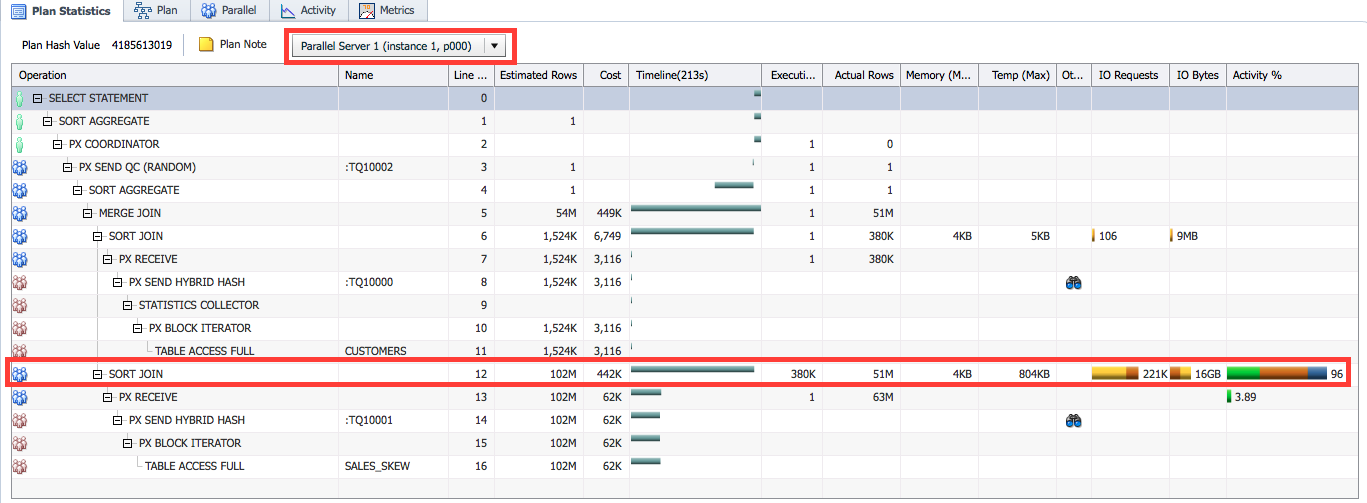
When you hover over the Actual Rows column for this line you can see the number of rows processed by this process compared to the number of rows processed by the whole parallel set. Here we see that this PX server processed 51M rows of the total 55M rows. The skew ratio of 3.73 indicates this process did 3.73/4 of the job as the DOP is 4 in this case.

This is because the join key column (CUST_ID) is highly skewed in the SALES_SKEW table, most of the rows have the same CUST_ID value. Since the plan is using HASH distribution (Line ID 14) all those rows were sent to the same process leading to inequal work distribution across PX servers.
For RAC databases Parallel tab shows the distribution of work across instances too, so you can compare the work done in each instance.

I hope this helps as a starting point for looking at parallel statements in SQL Monitor. As always, any comments are welcome.
