Schema on Read vs Schema on Write
So, when we talking about data loading, usually we do this with a system that could belong on one of two types. One of this is schema on write. With this approach, we have to define columns, data formats and so on. During the reading, every user will observe the same data set. As soon as we performed ETL (transform data in the format that most convenient to some particular system), reading will be pretty fast and overall system performance will be pretty good. But you should keep in mind, that we already paid a penalty for this when we’re loading data. Like an example of the schema on write system you could consider Relational database, for example, like Oracle or MySQL.
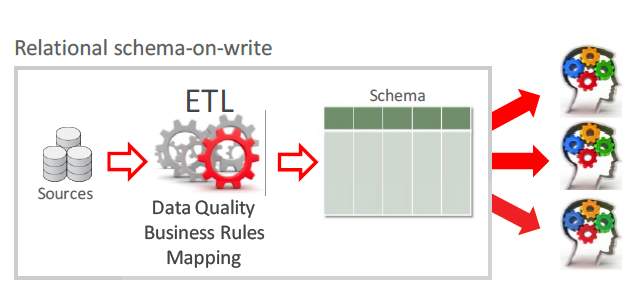
Schema on Write
Another approach is schema on read. In this case, we load data as-is without any changing and transformations. With this approach, we skip ETL (don’t transform data) step and we don’t have any headaches with the data format and data structure. Just load the file on a file system, like copying photos from FlashCard or external storage to your laptop’s disk. How to interpret data you will decide during the data reading. Interesting stuff that the same data (same files) could be read in a different manner. For instance, if you have some binary data and you have to define Serialization/Deserialization framework and using it within your select, you will have some structure data, otherwise, you will get a set of the bytes. Another example, even if you have simplest CSV files you could read the same column like a Numeric or like a String. It will affect on different results for sorting or comparison operations.
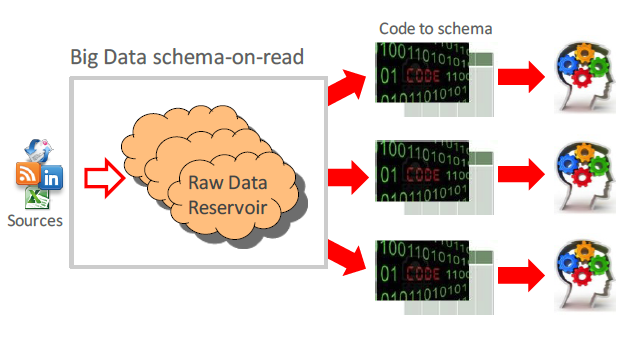
Schema on Read
Hadoop Distributed File System is the classical example of the schema on read system.More details about Schema on Read and Schema on Write approach you could find here.
Is schema on write always goodness?
Apparently, many of you heard about Parquet and ORC file formats into Hadoop. This is the example of the schema on write approach. We convert source format in the form which is convenient for processing engine (like hive, impala or Big Data SQL). Big Data SQL has the very powerful feature like predicate push down and column pruning, which allows you significantly improve the performance. I hope that my previous blog post convinced you that you may have dramatic Big Data SQL performance improvement with the parquet files, but have you immediately delete source files after conversion? don’t think so and let me give you the example why.
Transforming source data.
As a data source, I’ve chosen AVRO files.
{
"type" : "record",
"name" : "twitter_schema",
"namespace" : "com.miguno.avro",
"fields" : [ {
"name" : "username",
"type" : "string",
"doc" : "Name of the user account on Twitter.com"
}, {
"name" : "tweet",
"type" : "string",
"doc" : "The content of the user's Twitter message"
}, {
"name" : "timestamp",
"type" : "long",
"doc" : "Unix epoch time in seconds"
}
using this schema we generate AVRO file, which has 3 records:
[LINUX]$ java -jar /usr/lib/avro/avro-tools.jar random --schema-file /tmp/twitter.avsc --count 3 example.avro
on the next step we put this file into the hdfs directory:
[LINUX]$ hadoop fs -mkdir /tmp/avro_test/ [LINUX]$ hadoop fs -mkdir /tmp/avro_test/flex_format [LINUX]$ hadoop fs -put example.avro /tmp/avro_test/flex_format
hive> CREATE EXTERNAL TABLE tweets_flex ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat' LOCATION '/tmp/avro_test/flex_format' TBLPROPERTIES ('avro.schema.literal'='{ "namespace": "testing.hive.avro.serde", "name": "tweets", "type": "record", "fields": [ {"name" : "username", "type" : "string", "default" : "NULL"}, {"name" : "tweet","type" : "string", "default" : "NULL"}, {"name" : "timestamp", "type" : "long", "default" : "NULL"} ] }' );
to get access to this data from Oracle we need to create an external table which will be linked with hive table, created in the previous step.
SQL> CREATE TABLE tweets_avro_ext ( username VARCHAR2(4000), tweet VARCHAR2(4000), TIMESTAMP NUMBER ) ORGANIZATION EXTERNAL ( TYPE ORACLE_HIVE DEFAULT DIRECTORY "DEFAULT_DIR" ACCESS PARAMETERS ( com.oracle.bigdata.tablename=DEFAULT.tweets_flex) ) REJECT LIMIT UNLIMITED PARALLEL;
Now I want to convert my data to a format which has some optimizations for Big Data SQL, parquet for example:
hive> create table tweets_parq ( username string, tweet string, TIMESTAMP smallint ) STORED AS PARQUET; hive> INSERT OVERWRITE TABLE tweets_parq select * from tweets_flex;
as a second step of the metadata definition, I created Oracle external table, which is linked to the parquet files:
SQL> CREATE TABLE tweets_parq_ext ( username VARCHAR2(4000), tweet VARCHAR2(4000), TIMESTAMP NUMBER ) ORGANIZATION EXTERNAL ( TYPE ORACLE_HIVE DEFAULT DIRECTORY "DEFAULT_DIR" ACCESS PARAMETERS ( com.oracle.bigdata.cluster=bds30 com.oracle.bigdata.tablename=DEFAULT.tweets_parq) ) REJECT LIMIT UNLIMITED PARALLEL;
Now everything seems fine, and let’s query the tables which have to have identic data (because parquet table was produced in Create as Select style from AVRO).
SQL> select TIMESTAMP from tweets_avro_ext WHERE username='vic' AND tweet='hello' UNION ALL select TIMESTAMP from tweets_parq_ext WHERE username='vic' AND tweet='hello' ------------ 1472648470 -6744
Uuups… it’s not what we expect.. data have to be identical, but something went wrong. smallint datatype is not enough for the timestamp and this is the reason that we got wrong results. Let’s try to recreate parquet table in hive and run SQL in Oracle again.
hive> drop table tweets_parq; hive> create table tweets_parq ( username string, tweet string, TIMESTAMP bigint ) STORED AS PARQUET; hive> INSERT OVERWRITE TABLE tweets_parq select * from tweets_flex;
after reloading data we don’t need to do something in Oracle database (as soon as the table name in hive remains the same.
SQL> select TIMESTAMP from tweets_avro_ext WHERE username='vic' AND tweet='hello' UNION ALL select TIMESTAMP from tweets_parq_ext WHERE username='vic' AND tweet='hello' ------------ 1472648470 1472648470
bingo! results are the same!
Conclusion.
it’s a philosophical question what’s better schema on read or schema on write. The first one could give you flexibility and preserve from human mistakes.The second one is able to provide better performance. Generally, it’s a good idea to keep data in source format (just in case) and optimize it in another format which is convenient for the engine which scans your data. ETL could have wrong transformations and source data format will allow you to jump back to the source and reparse data in the proper way.
