In my previous posts, I was talking about different features of the Big Data SQL. Everything is clear (I hope), but when you start to run real queries you may have doubts – is it a maximum performance which I could get from this Cluster? In this article, I would like to explain steps which are required for the performance tuning of the Big Data SQL.
SQL Monitoring.
First of all, the Big Data SQL is the Oracle SQL. You may use to start to debug Oracle SQL performance/other issues with SQL Monitor. Same for Big Data SQL. For start working with it, you may need to install OEM and use the lightweight version of it – Database Express. If you don’t want/like/can use GUI tools you may use it with SQLPLUS, like it showed here.Some of the performance problems could be unrelated with Hadoop and may be a general Oracle Database issues, like active using TEMP tablespace
Many of the waiting events are standard for Oracle Database, you may found the only couple which is specific for the Big Data SQL:
1) “cell external table smart scan” – which is the typical event for Big Data SQL and it tells us that something happens (scan) on the Hadoop side.
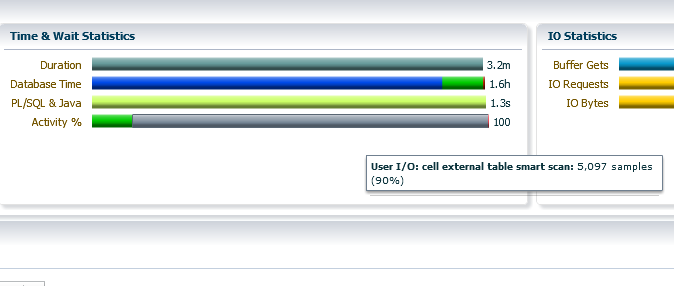
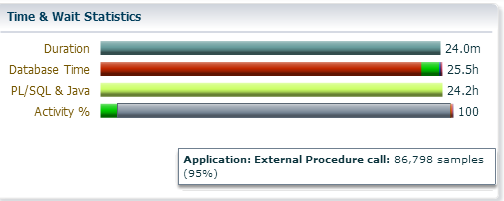
2) “External Procedure call” – this event is also natural for the Big Data SQL, through the extproc Database fetch the metadata and define the block location on the HDFS for future planning, but if you observe a lot of “External Procedure call” the waiting events – it could be a bad sign. Usually, it means that you fetch the HDFS block on the Database side and parse/process it there (without the offloading)
Quarantine.
If your query has failed few times it may be placed in the quarantine. It works like in Exadata – SQLs which are in the quarantine will not proceed on the cell side and instead this will be shipped to the Database and proceed there (“External Procedure Call” wait event will tell you about this).
For checking, which queries are in the quarantine you have to run:
[Linux] $ dcli -C bdscli -e "list quarantine"
for dropping it off:
[Linux] $ dcli -C "bdscli -e "drop quarantine all""
Storage Indexes.
Storage Indexes (SI) is very powerful performance feature. I explained the way how it works here. I don’t recommend you to disable it. In most cases, SI brings you the great performance boost. But it has one downside – first few runs are slower than without SI. But again I don’t recommend you to disable it. If you want to get consistent performance with SI – I advise you to warm it up by running few times query, which returns exactly 0 rows. It may be done by putting WHERE predicate which is never TRUE, for Example:
SQL> select * from customers WHERE age= -1 and passport_id = 0;
The first run will be slow, but after few times query will be finished within couple seconds.
Data types.
Well, let’s imagine that you made sure, that everything that may work on the cell side works there (in other words you don’t have a lot of “External Procedure Call” wait events), don’t have any Oracle Database related problem, Storage Indexes warmed up, but you may still think that query could run faster.
Next thing to check is datatype definition in the Oracle Database and Hive. In nutshell – you may work in few times slower with wrong datatype definition. Ideally, you just pass the data from Hadoop level to the database layer without any transformation otherwise, you burn a lot of CPU resources on the cell side. I put all details here, so be very careful with your Oracle DDLs.
File Formats.
Big Data SQL has a lot of improvements for working with Text Files (like CSV). It proceeds it in C engine.
You may also get some profit from the Columnar File Formats like Parquet File or ORC. The main optimization is Predicate Push Down. Another one big optimization, which you could do with the Columnar File Formats is list less columns. Avoid queries like,
SQL> select * from customers
instead, list the minimum number of columns:
SQL> select col1, col2 from customers
If you are creating parquet files it may also be useful to reduce page size for reducing Big Data SQL memory consumption. For example, you could do this with hive – create the new table:
hive> CREATE TABLE new_tab STORED AS PARQUET tblproperties ("parquet.page.size"="65536") AS SELECT * FROM old_tab;
What is your bottleneck?
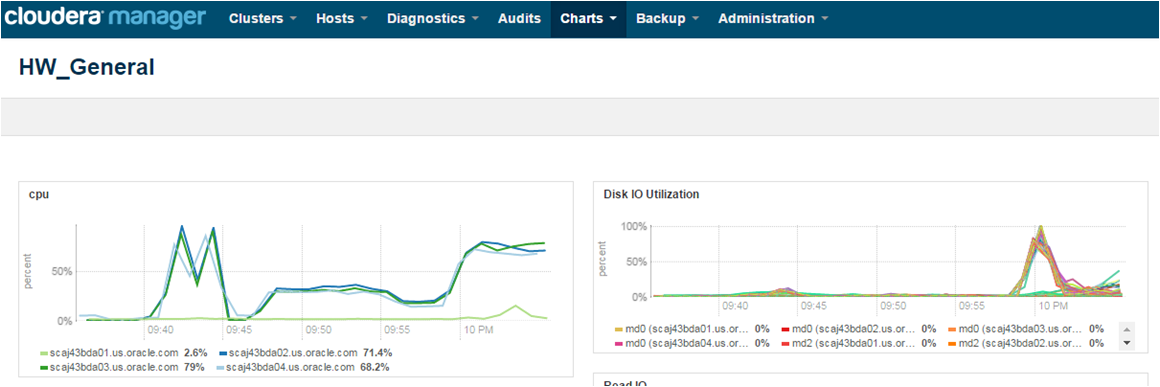
It’s very important to understand where is your bottleneck. Big Data SQL is the complex product which involves two sides – Database and Hadoop. Each side has few components which could limit your performance. For Database side I do recommend to use OEM. Hadoop is easier to debug with Cloudera Manager (it has a plenty of pre-collected and predefined charts, which you could find in the charts bookmark).
What is the whole picture?
Many thanks for Marty Gubar for this picture, that shows overall picture of the Big Data SQL processing:
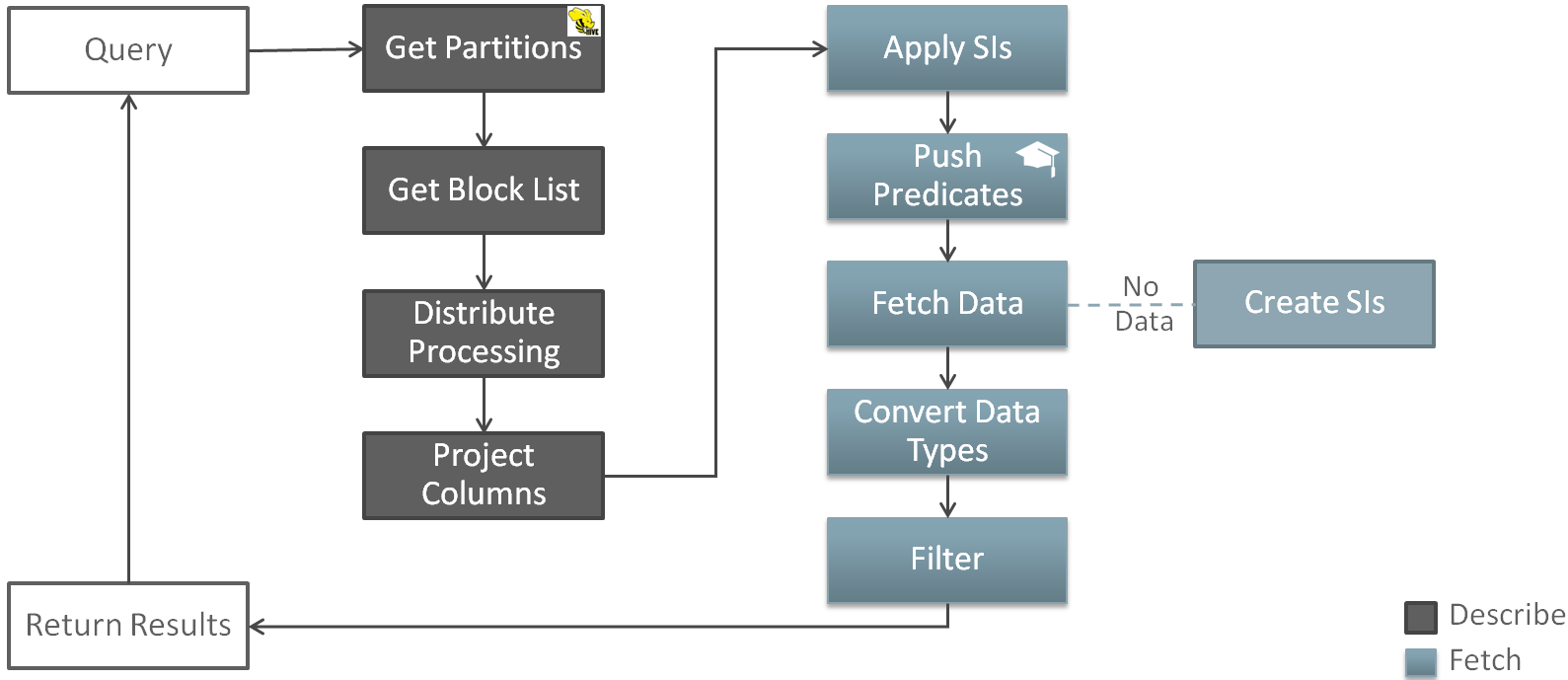
whenever you run the query first of all Oracle Database obtain the list of Hive partitions. This is the first Big Data SQL optimization – you read only data what you need. After this database obtain the list of the blocks and plan the scan in the way which will evenly distribute the workload. After the column prunning database runs the scan on the Hadoop tier. If Storage Indexes exist they are applied as a first step. After this (in case of parquet files or ORC) Big Data SQL applies Predicate Push Down and starts to fetch the data. Data stored in the Hadoop format and need to be converted to Oracle type. After this Big Data SQL run the Smart Scan (filter) over rest of the data (which were not prune out by Storage Indexes or Predicate Push Down).
