Big Data SQL has perfect wonderful heritage from the Oracle RDBMS. One of those representative is Bloom Filter. This feature was available in Oracle 10g and Big Data SQL use it for improve Join performance. Before show you couple concrete examples, let me remind (explain) what Bloom Filter is.
Bloom Filter abstract example. Input.
Independently of any technology speaking, Bloom Filter is data structure that could answer you to one simple question: “Does element X exist in array Y”. Answer could be either “definitely no” or “Maybe”. Bloom Filter is array, that has two main input parameters: array length and set of the hash functions, that could return value in diapason of array’s length. Let’s consider example of bloom filter.
Input:
1) Input (target) dataset. We will check the availability of the element in this array. And will create bloom filter over this dataset.
[oracle, database, filter]
Note: this dataset IS NOT bloom filter.
2) Length of the bloom filter. Let’s say it’s 12 (just because i deside so:) )
3) Set of the hash functions. I would choose three hash functions: h1, h2, h, each one will return numberic value, that stay in between [1,12] (because array lenght is 12, have been chosen on previous step).
Bloom Filter abstract example. Bloom Filter Creation.
For create bloom filter you have to :
– Apply each hash function for each element of input array
– Mark bloom filter elements by results of previous step.
Bellow is picture that illustrate those steps.
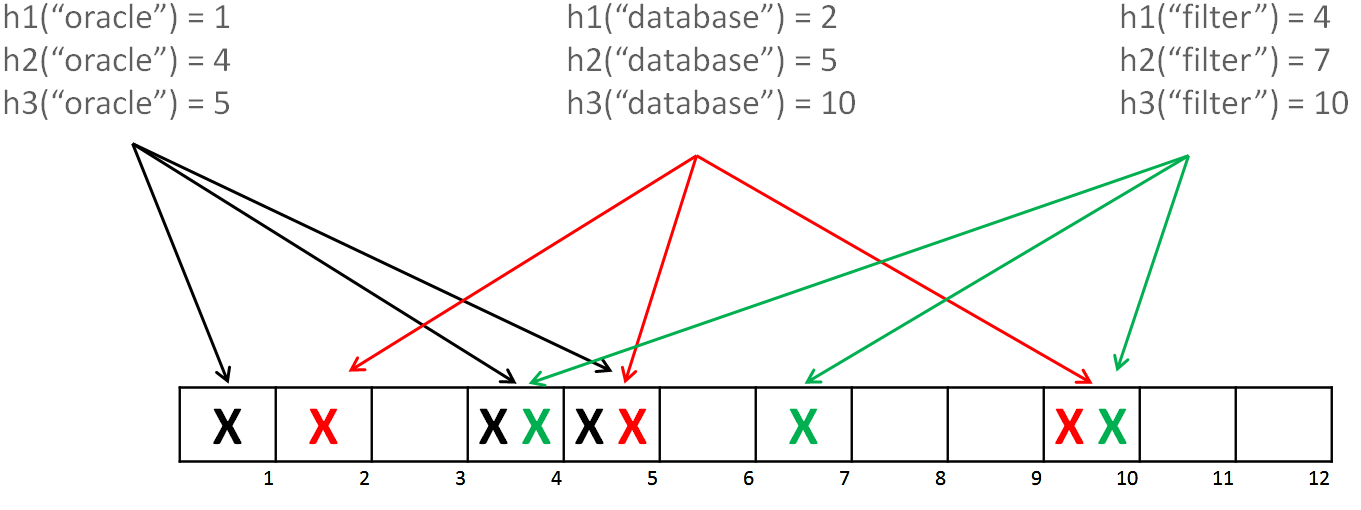
in fact it doesn’t matter how many hash of each element exist in each bloom filter array element one or all. So, we will remark filter as boolean (at least one element exist or not exist).

now we created bloom filter and ready to start using it.
Bloom Filter abstract example. Bloom Filter Using.
Now, let’s start use bloom filter. I have input array [oracle, database, filter] and i need to check whether soem element exist in this array or not. For exampe, i want to check fact of existing “oracle” element. For this i need to calculate all three hash functions of “oracle” and check matching in bloom filter.
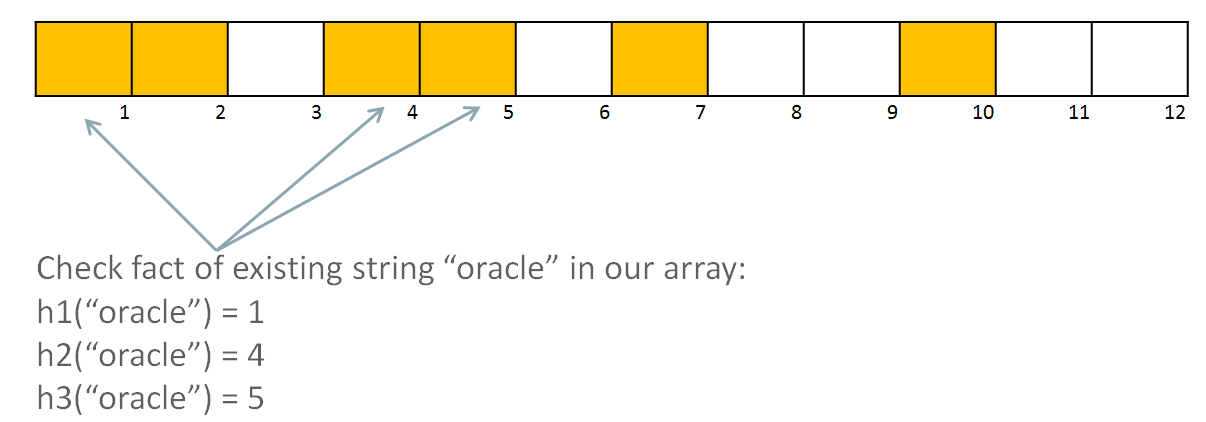
“oracle” matches with all filled elements of the bloom filter, so answer will be “this element maybe exist in target array”. So, we need to scan all target dataset to define exist or not this element. But why answer is “maybe”? Let’s consider another example. I want to check – does element “Alex” exist in my target array:
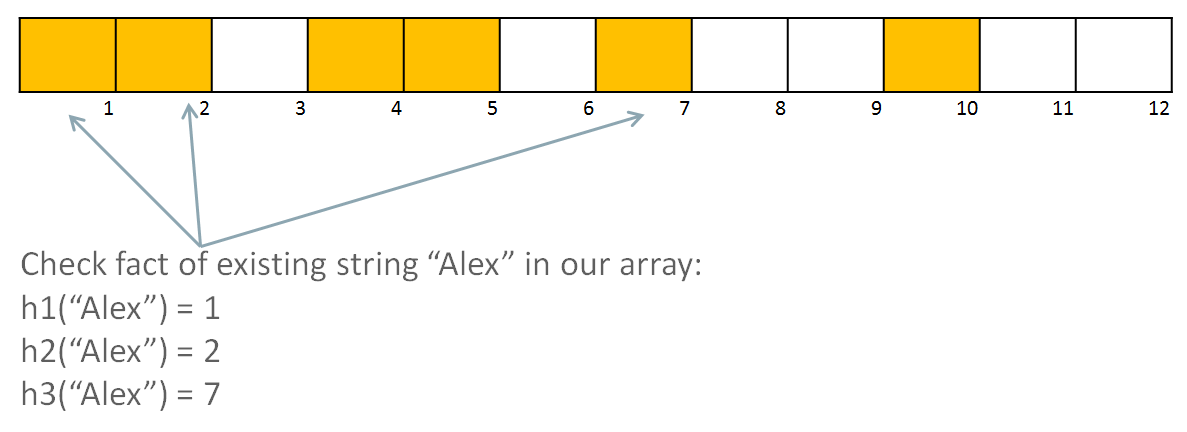
this hash functions of this element again match with all filled bloom filter values. But bloom filter element 1 is true, because h1(oracle)=1, element 2 is true because h1(database)=2, element 7 is true, because h2(filter)=7. Answer again will be maybe and subsequent full scan will detect this. But what the profit of bloom filter? Real profit comes from answer “definitely no”. If we will consider next example, when i’ll check existing of element “byte”:

h2 returns index to the sixth element, which is false. So, answer will be element “byte” definitely absent in target array. It will allow us to skip this scan of this data.
Bloom filter in qeury plan
as you could think, to start using bloom filter in Oracle RDBMS you have to perform two steps. Create it over relatively small table and use it over big table. Those steps have pretty obvious names in query plan – “Join filter create” and “Join filter use”.
Bloom Filter and Big Data SQL. Hadoop only tables case.
It was abstract, now let’s consider how we could apply it in practice. Testcase:
1) Input data – two tables stored into Hadoop. Huge fact table:
SQL> SELECT COUNT(1) FROM store_sales_orc; 6385178703
Small dimension table:
SQL> SELECT COUNT(1) FROM date_dim_orc; 109573
2) Test query for test purposes i took querie from tpcds benchmark test:
SQL> SELECT * FROM (SELECT /*+ NOPARALLEL*/ dt.d_year, SUM(ss_ext_sales_price) sum_agg FROM date_dim_orc dt, store_sales_orc WHERE dt.d_date_sk = store_sales_orc.ss_sold_date_sk AND dt.d_moy = 12 GROUP BY dt.d_year ORDER BY dt.d_year, sum_agg DESC) WHERE rownum <= 100
I used “NOPARALLEL” hint for simplify query plan reading.
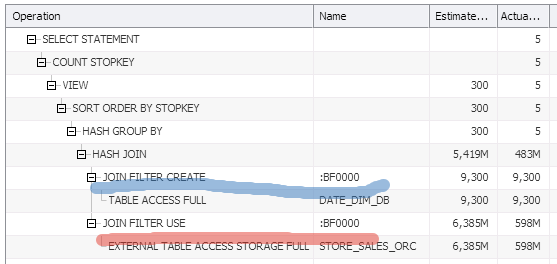
3) Query execution plan:
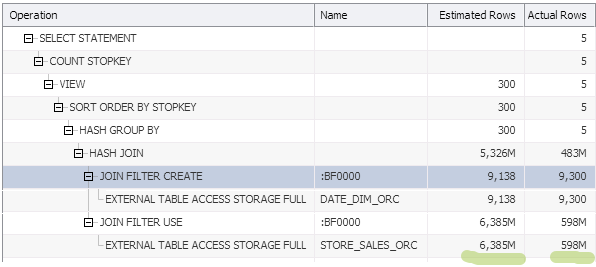
this plan shows that:
– Bloom Filter was created (“JOIN FILTER CREATE” step) over small dimension table (DATA_DIM_ORC). Cheap step
– Bloom Filter was applyed (“JOIN FILTER CREATE” step) over huge fact table (STORE_SALES_ORC). Expensive step
– Bloom Filter eliminate 91% of the data (column Actual Rows shows us 598M rows, which is 9% of STORE_SALES_ORC rows). You could measure Bloom Filter efficiency, by dividing actual rows by all table rows.
– All those steps were on the Hadoop side (not the database)
– Database perform final join
Let’s check how many bytes were transfered to the database. Let me remind about two statistic metrics “cell XT granule bytes requested for predicate offload” and “cell interconnect bytes returned by XT smart scan”. First one show how many bytes were requested to scan (how many data do i have on the disks. Second one shows how much data was transfered towards the database.
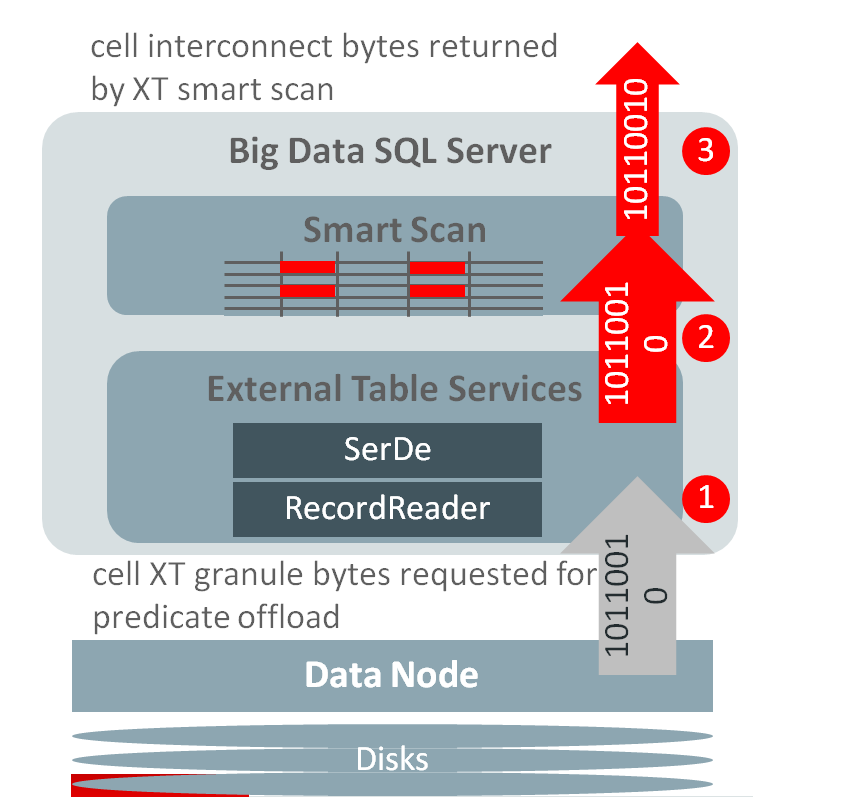
SQL> SELECT n.name, round(s.value/1024/1024/1024) FROM v$mystat s, v$statname n WHERE s.statistic# IN (462,463) AND s.statistic# = n.statistic#; cell XT granule bytes requested for predicate offload 229 cell interconnect bytes returned by XT smart scan 10
so, only 10 GB data was return to the DB instance. Not so bad!
Bloom Filter and Big Data SQL. In Database and Hadoop tables.
now let me show you second test case when data partly stored into Hadoop (huge fact table) and partly stored into Database (small dimension table). Pretty common, by the way, because dimansion table could be modified and modified pretty frequently (which is good for database), and in the same time fact table usually unmutable (which is good for Hadoop).

i ran the same test, only change table name (refer to the table that stores into database)
SQL> SELECT * FROM (SELECT /*+ NOPARALLEL*/ dt.d_year, SUM(ss_ext_sales_price) sum_agg FROM date_dim_db dt, store_sales_orc WHERE dt.d_date_sk = store_sales_orc.ss_sold_date_sk AND dt.d_moy = 12 GROUP BY dt.d_year ORDER BY dt.d_year, sum_agg DESC) WHERE rownum <= 100
Query plan is the same:
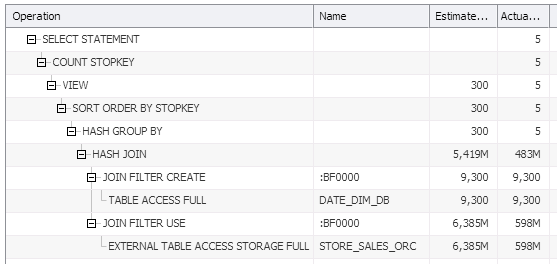
the same approach used for this query as well with only one difference. Bloom filter was generated on the databse side (cheap step), then pushed on the Hadoop (cell) side and applied to the big table. Other statistics also simillar:
SQL> SELECT n.name, round(s.value/1024/1024/1024) FROM v$mystat s, v$statname n WHERE s.statistic# IN (462,463) AND s.statistic# = n.statistic#; cell XT granule bytes requested for predicate offload 229 cell interconnect bytes returned by XT smart scan 8
from performance perspective those queries are also similar – take the same time (because main part of this query is applying bloom filter over store_sales_orc table).
Column Prunning and datatype transformation.
Big Data SQL also does another important stuffs (important from performance perspective):
– Column prunning. Try to use less columns in your query for get better performance
– Datatype convertation (from Java type to Oracle RDBMS types)
