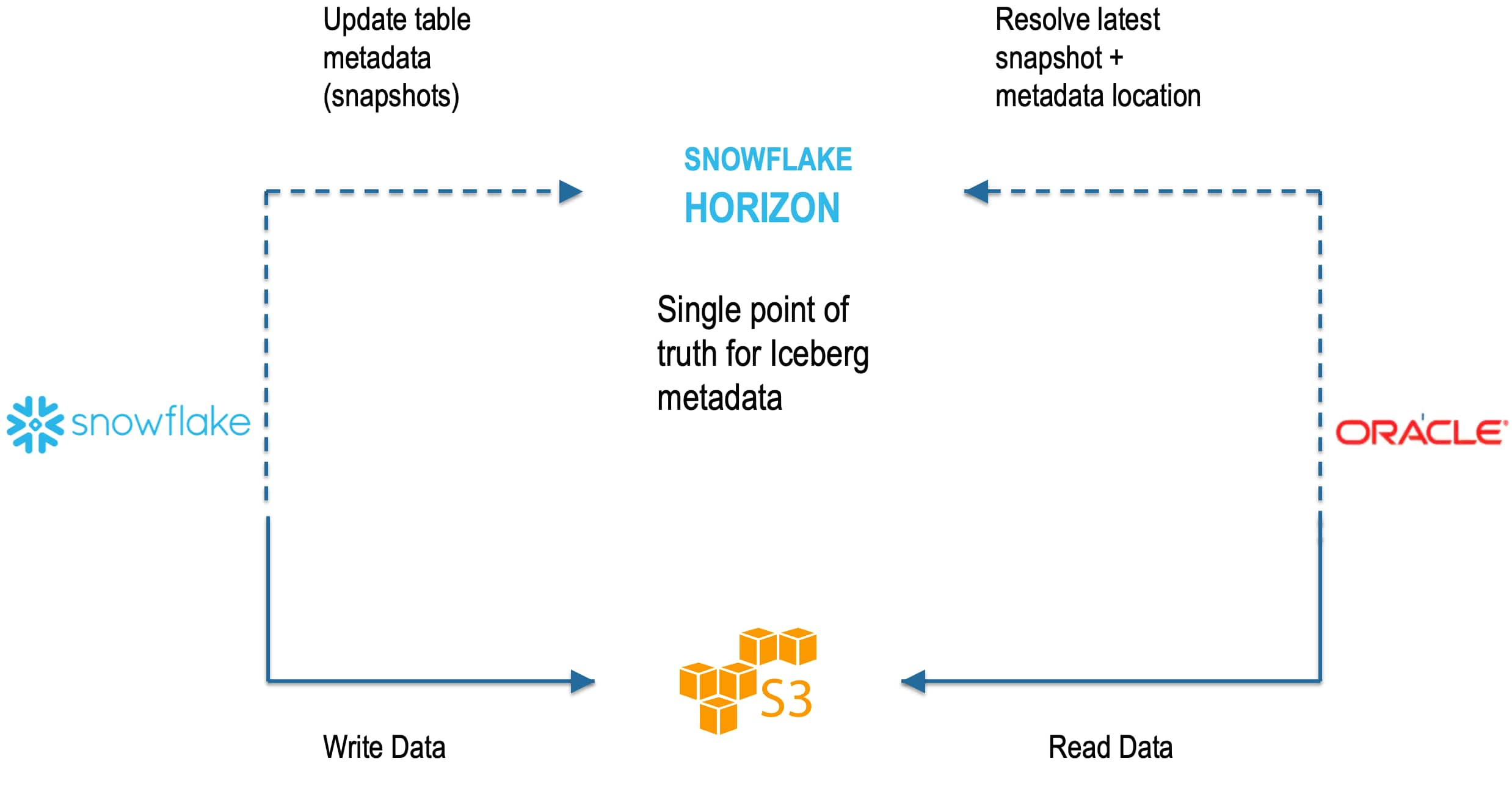
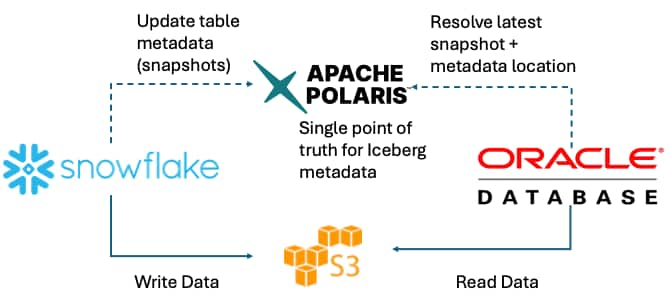
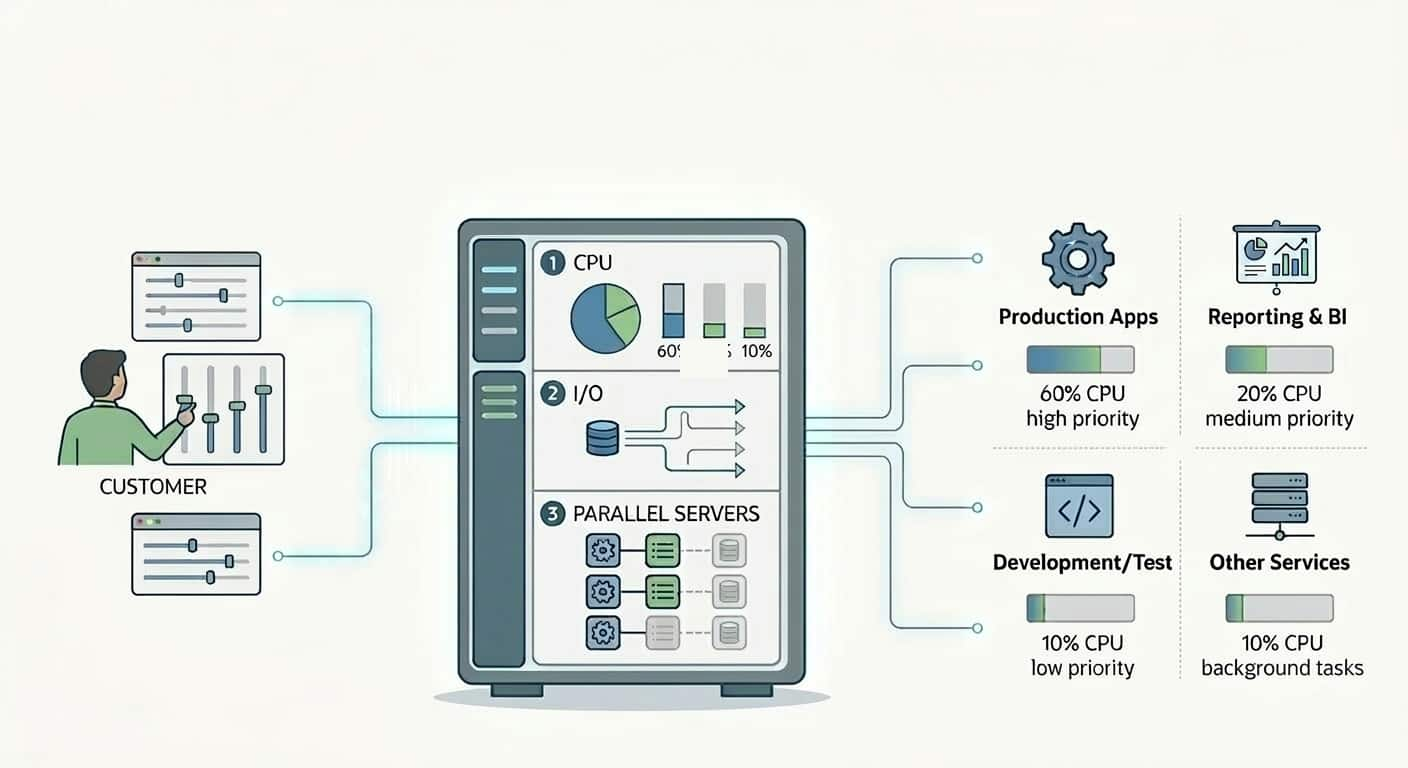
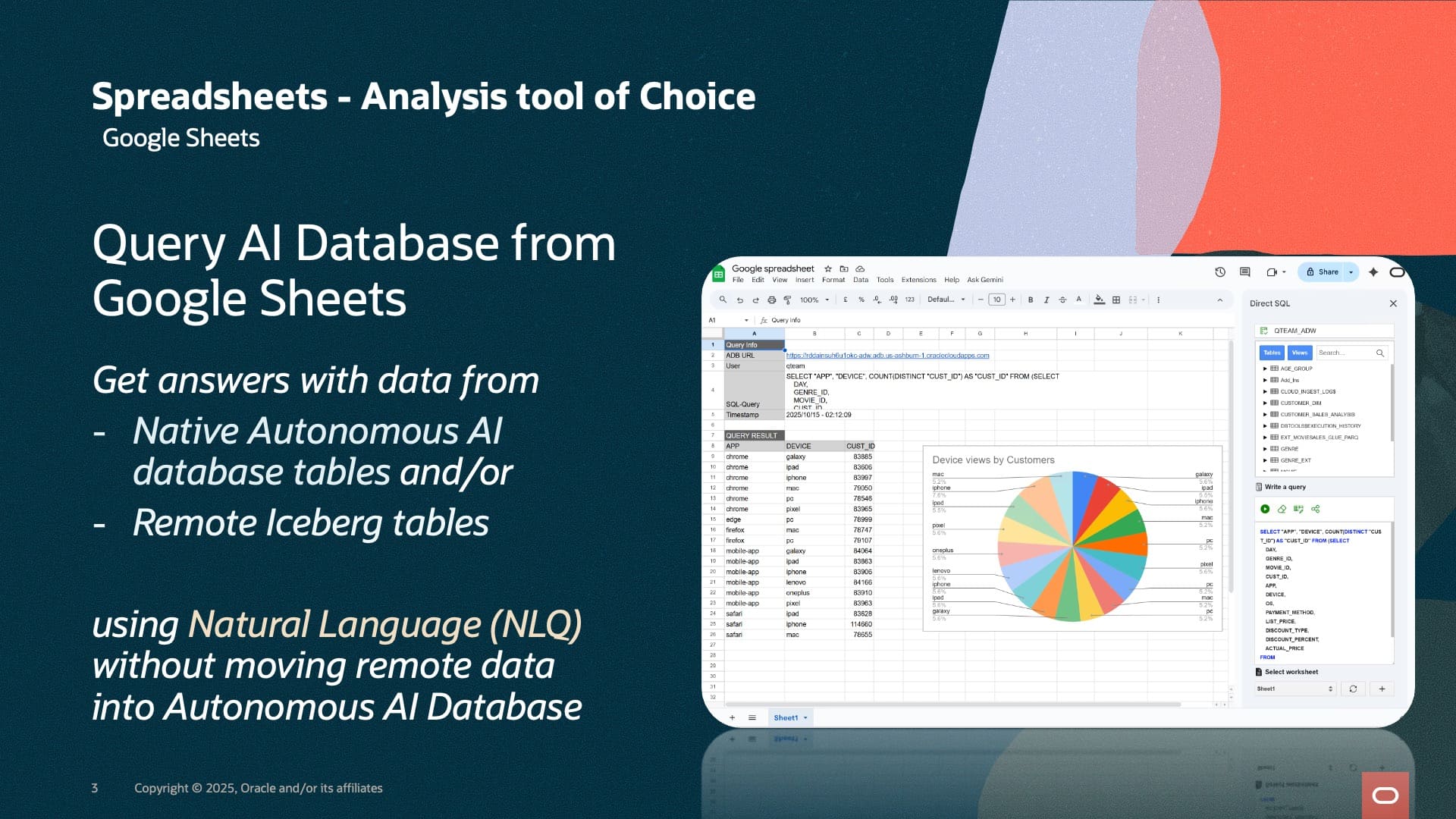
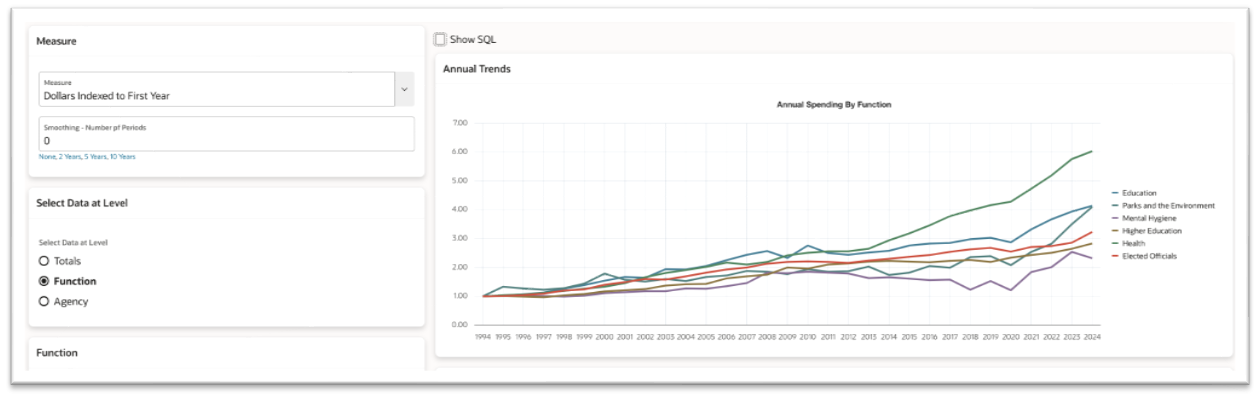
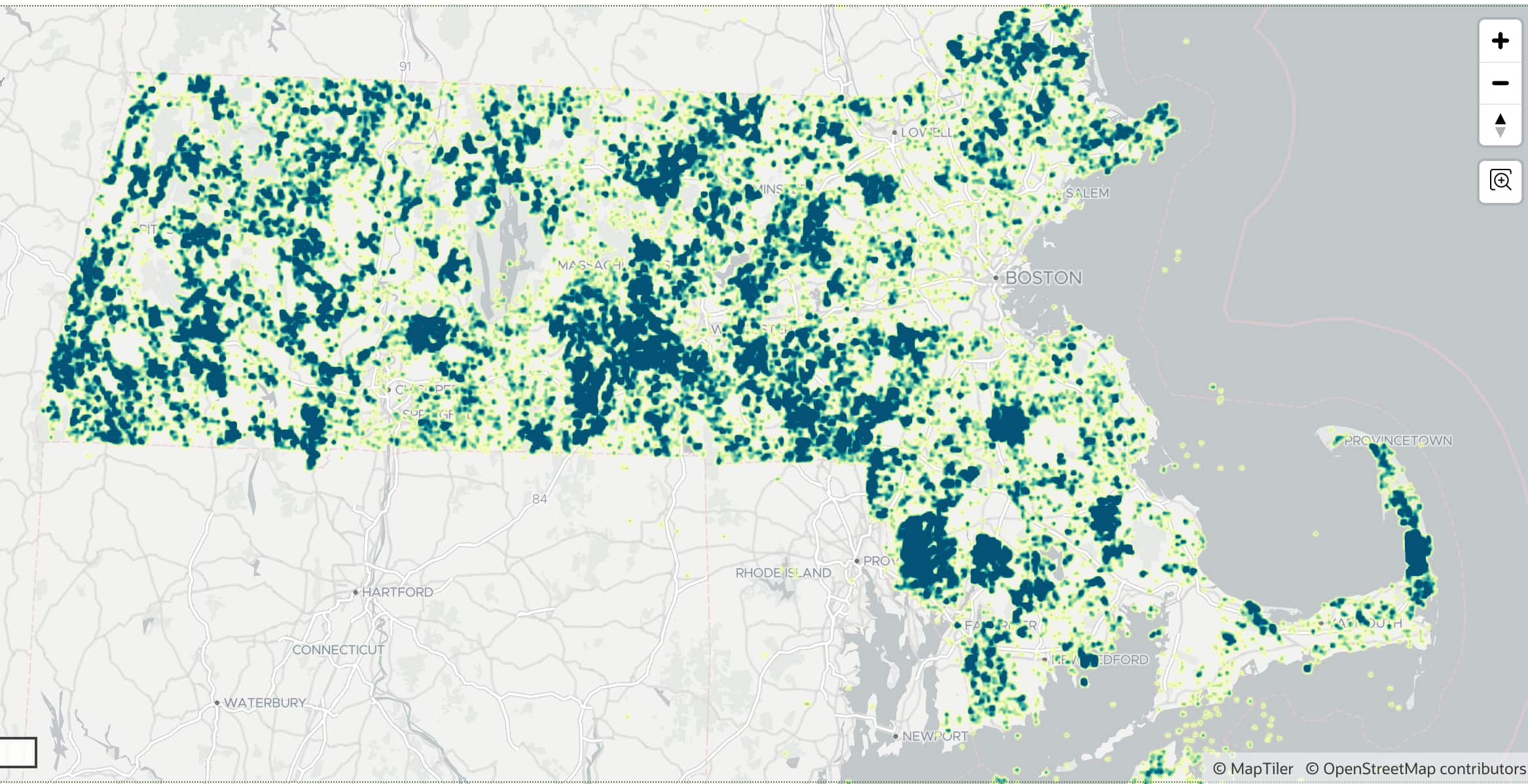
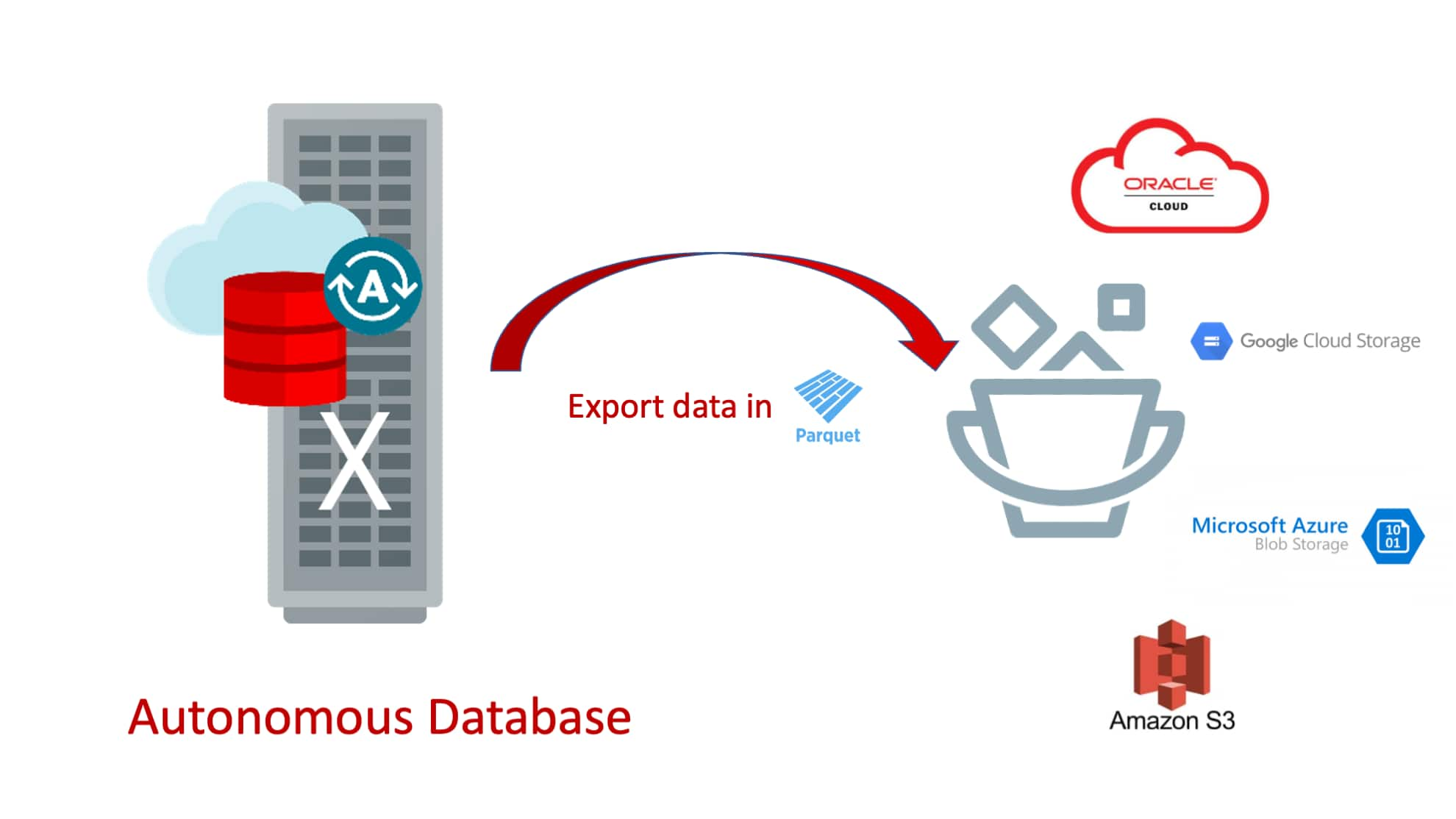
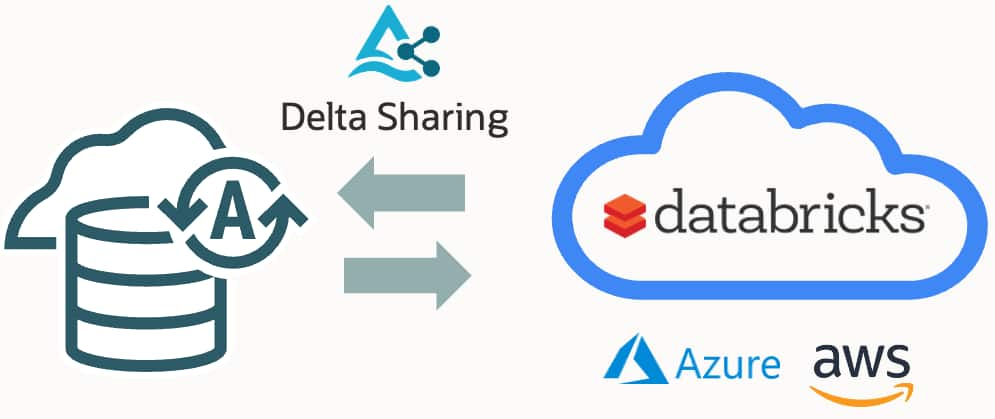
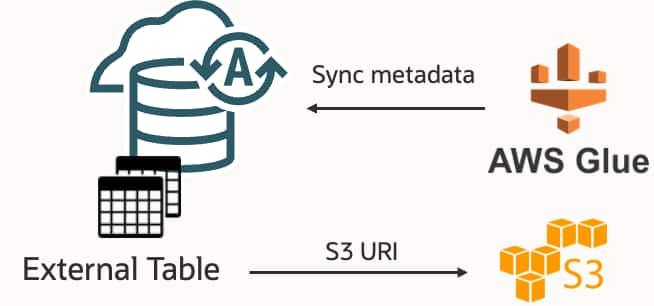
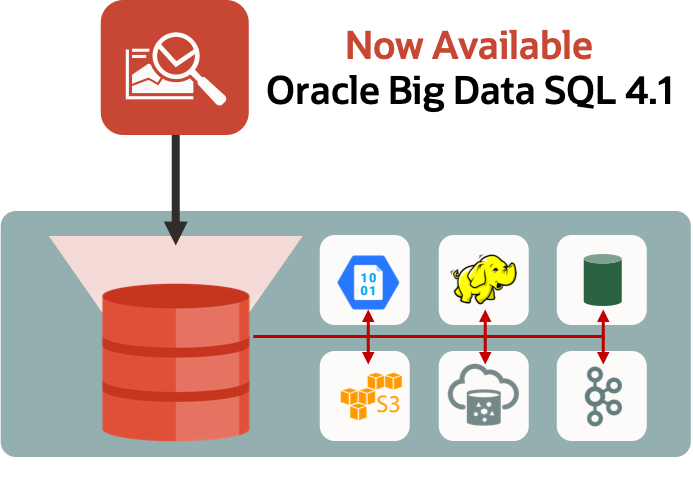
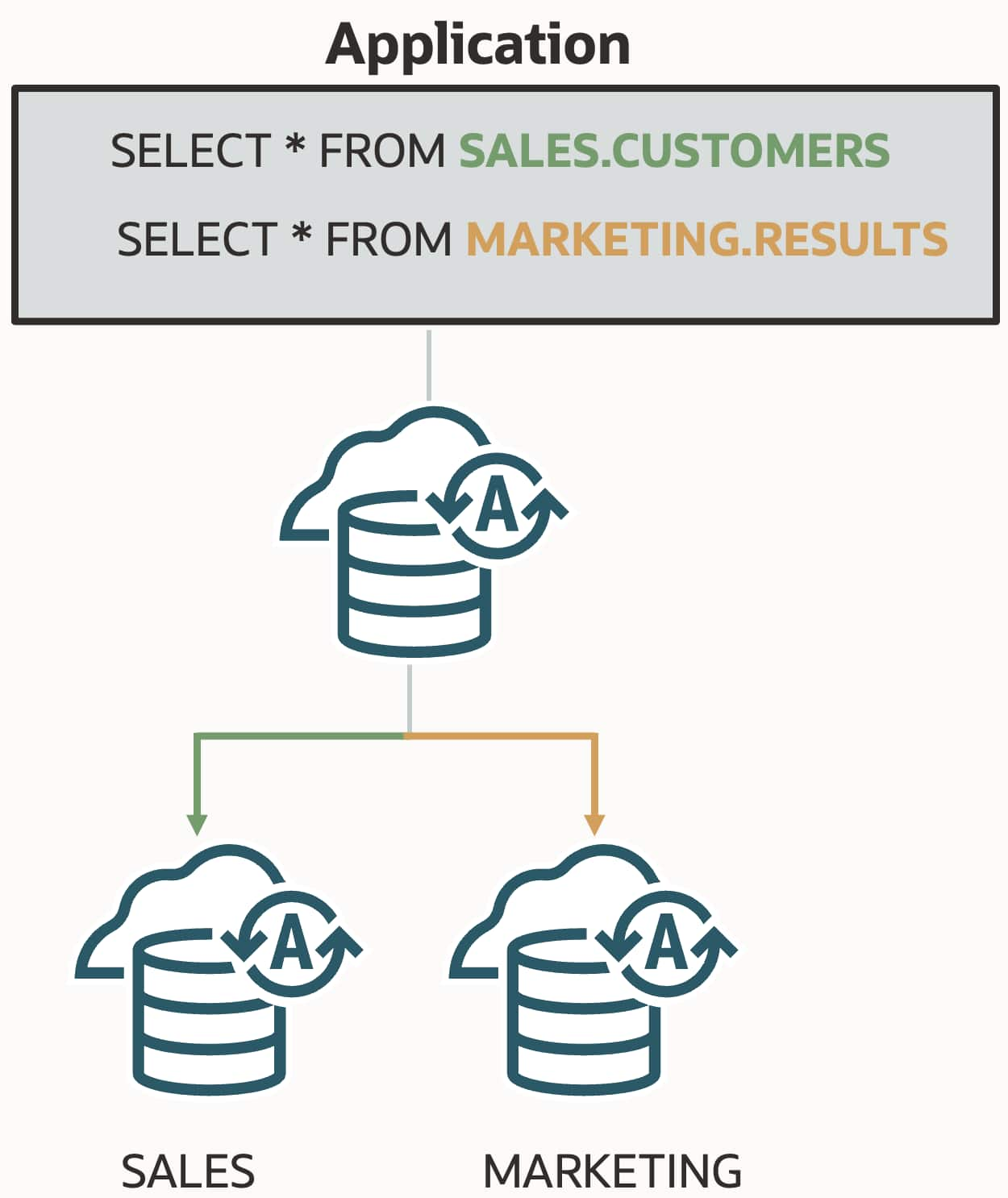
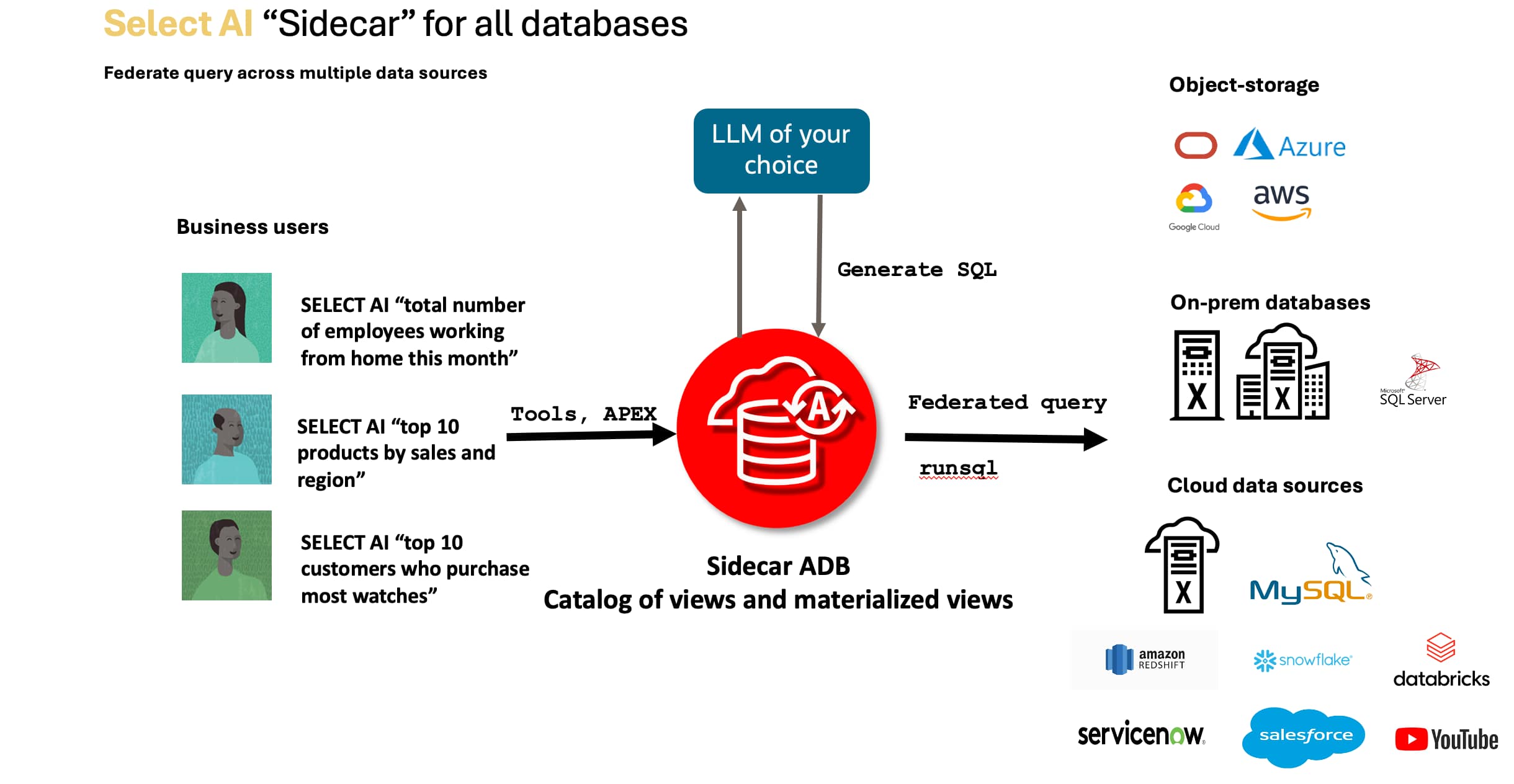
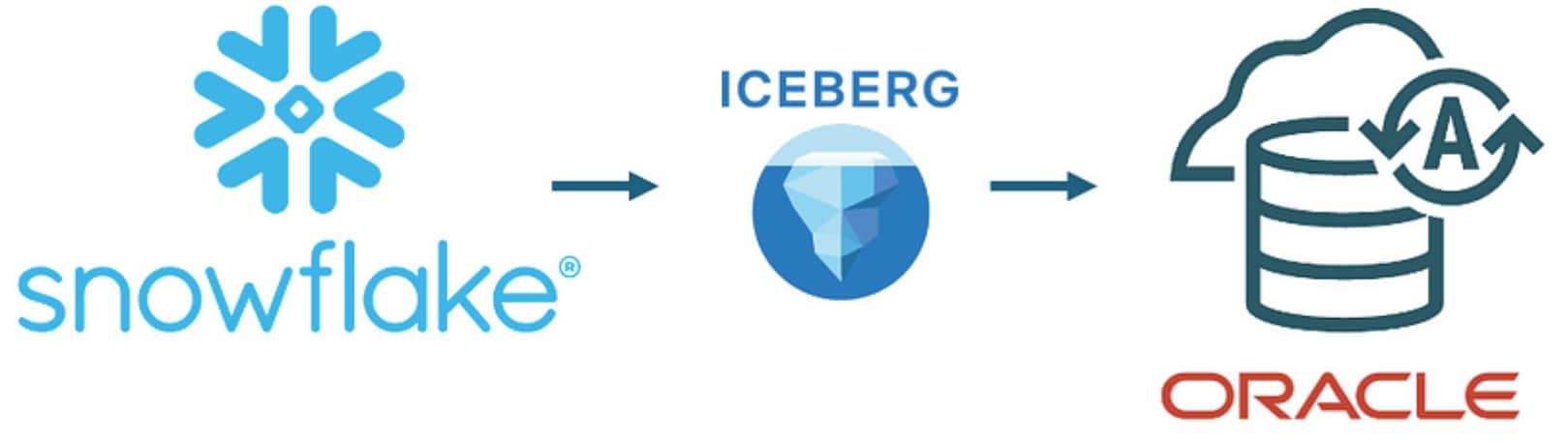
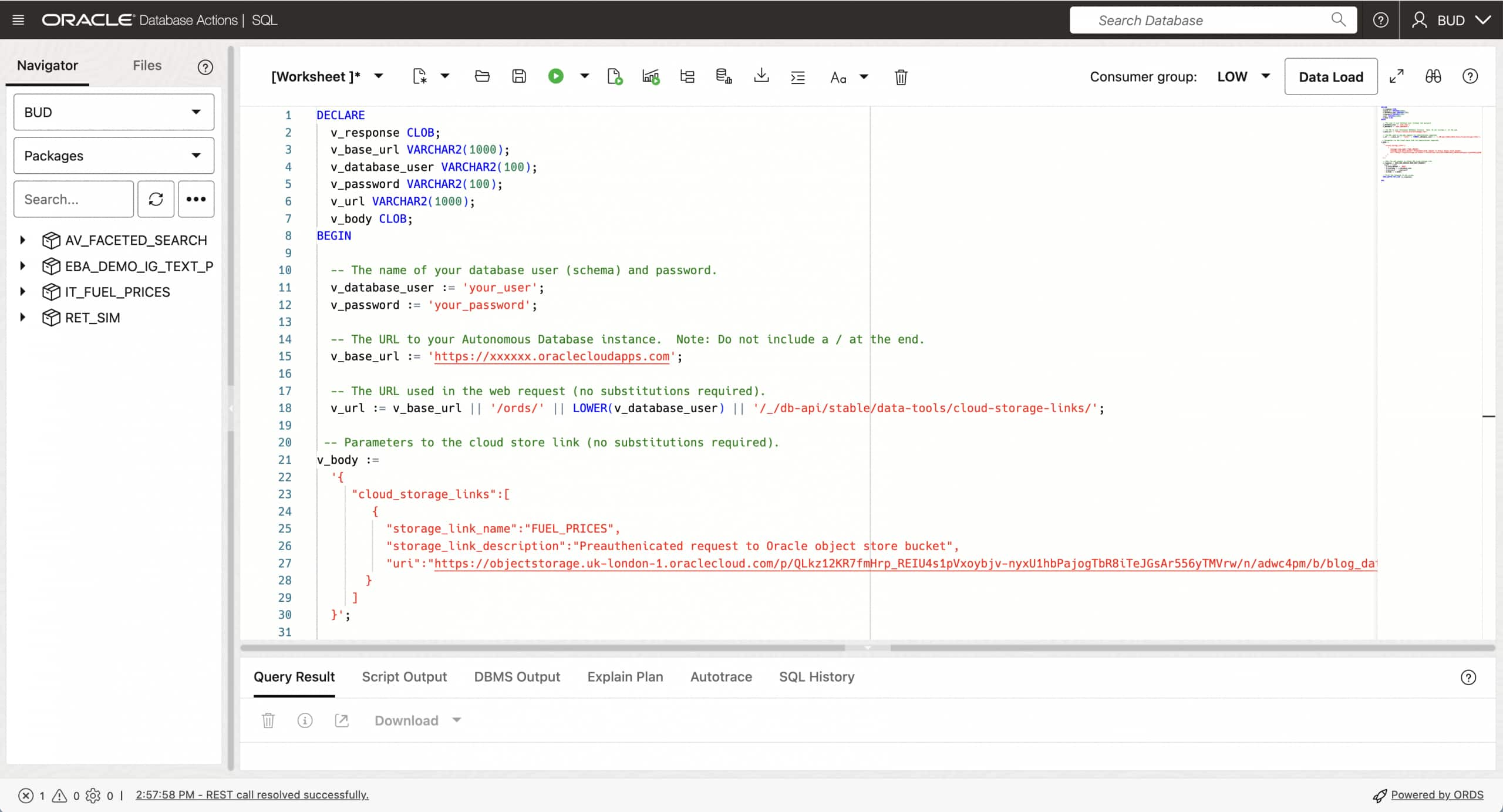
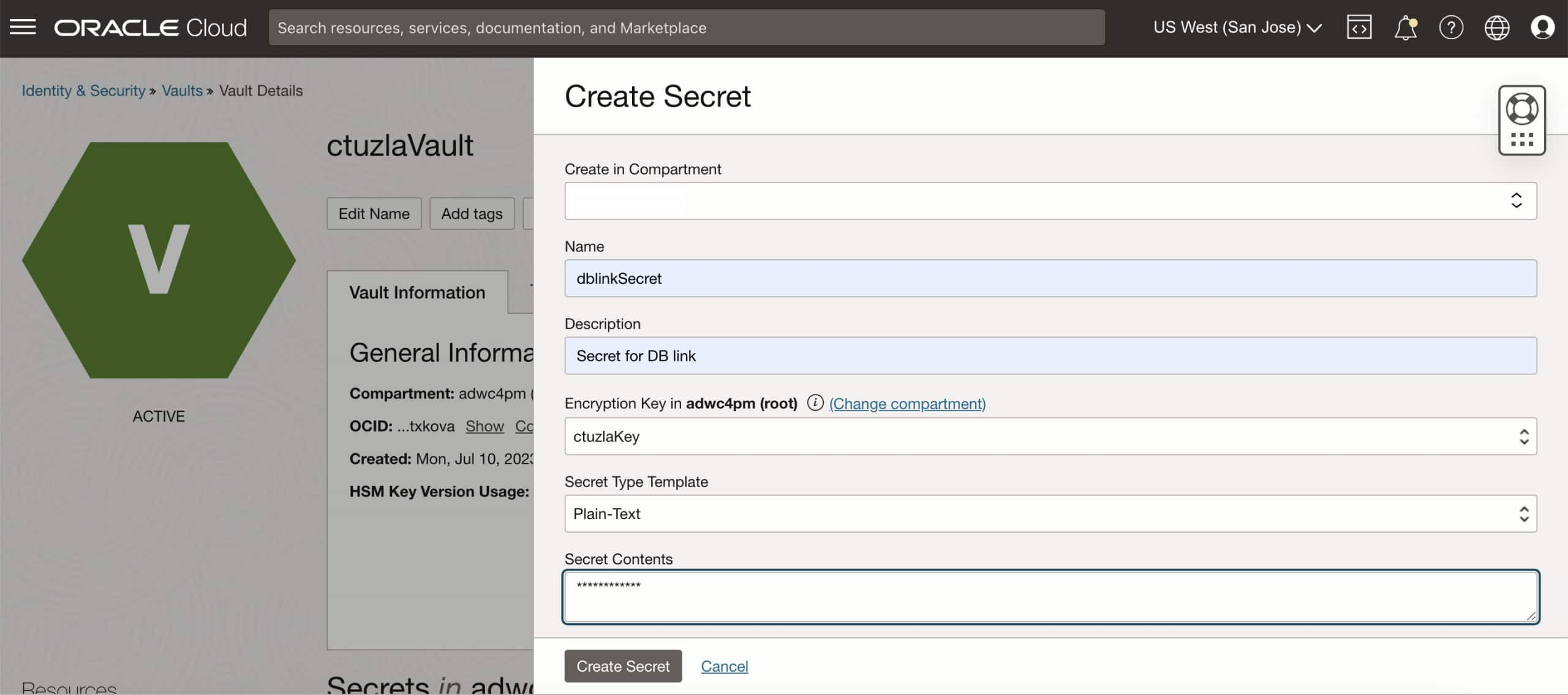
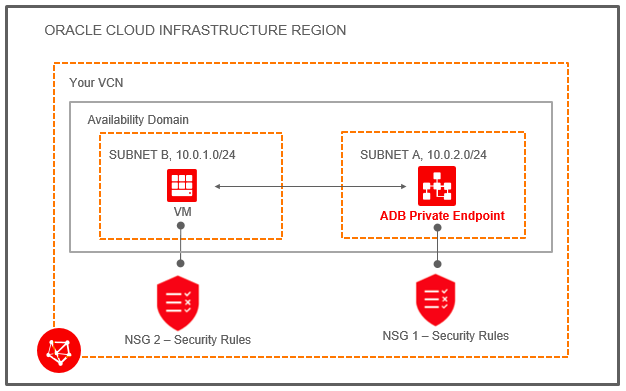
Information, tips, tricks and sample code for data management in an autonomous, cloud-native, data-driven world