By Shabbir Tayabali, Consulting Technical Manager
In this post, I’ll discuss how a confusion matrix benefits machine learning; I’ll also share a case study.
Subscribe to the Oracle Data Science Newsletter to get the latest machine learning and data science content sent straight to your inbox!
What is a confusion matrix?
A confusion matrix is a way of assessing the performance of a classification model. It is a comparison between the ground truth (actual values) and the predicted values emitted by the model for the target variable.
A confusion matrix is useful in the supervised learning category of machine learning using a labelled data set. As shown below, it is represented by a table. This is a sample confusion matrix for a binary classifier (i.e. 0-Negative or 1-Positive).
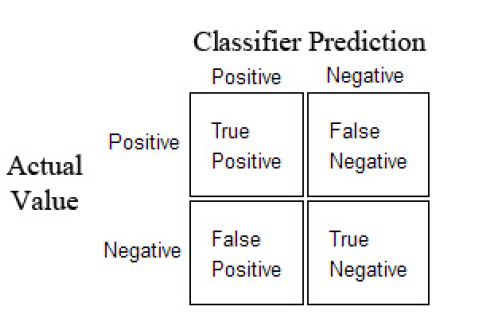
Diagram 1: Confusion Matrix
The confusion matrix is represented by a positive and a negative class. The positive class represents the not-normal class or behavior, so it is usually less represented than the other class. The negative class, on the other hand, represents normality or a normal behavior.
We build models to predict what is not normal (anomaly detection) as accurate as possible – for example, we would like to predict potential defaulters as defaulters, or potential diabetics as diabetics.
Here are the four quadrants in a confusion matrix:
True Positive (TP) is an outcome where the model correctly predicts the positive class.
True Negative (TN) is an outcome where the model correctly predicts the negative class.
False Positive (FP) is an outcome where the model incorrectly predicts the positive class.
False Negative (FN) is an outcome where the model incorrectly predicts the negative class.
Data set:
To understand the confusion matrix using a case study, I will use the UCI Machine Learning data set for breast cancer.
Here are the attributes mentioned in the data set:
- Sample code number: id number
- Clump Thickness: 1 – 10
- Uniformity of Cell Size: 1 – 10
- Uniformity of Cell Shape: 1 – 10
- Marginal Adhesion: 1 – 10
- Single Epithelial Cell Size: 1 – 10
- Bare Nuclei: 1 – 10
- Bland Chromatin: 1 – 10
- Normal Nucleoli: 1 – 10
- Mitoses: 1 – 10
- Class: (2 for benign, 4 for malignant) – Binary classifier.
This data set has a set of attributes (numbered 1 to 10) which are independent attributes. They help to decide the class of cancer. The 11th attribute (Class) is called the dependent attribute. The “Class” attribute has values either 2 (benign class) or 4 (malignant class).
The data set is labelled and hence forms part of the supervised machine learning category.
As a general rule, the data analyst should mark the underrepresented class as “1” and the normal class with “0” in the data set. The algorithm will detect it accordingly and thereby derive the values of TP, TN, FP and FN. However, in this data set, the class values are 2 and 4, respectively.
The question is: Will the algorithm still detect the normal and underrepresented classes correctly to build the confusion matrix?
The initial data exploration shows:
- Total records of the data set: 699
- Patients with benign cancer: 458 (65.5% of data set)
- Patients with malignant cancer: 241 (34.5% of data set)
The malignant class is underrepresented (not-normal) class wherein the benign class is the normal class in this data set. Therefore, the malignant class would represent the positive class, while the benign class would represent the negative class in the confusion matrix.
The interpretation of the TP, TN, FP, FN will be:
True Positives would be correct identification of the malignant class, while the True Negatives would be correct identification of the benign class.
Similarly, the False Positives would be incorrect prediction of the malignant class, and False Negatives would be incorrect prediction of the benign class.
The objective of the model is to increase the values of True Positives and True Negatives while bringing the values of False Positives and False Negatives to zero.
Model and confusion matrix
I have used support vector classifier model (SVC) to predict the class type. The train and test split ratio is 80/20. I’ve selected 559 records as the train set and the rest (140) as the test set.
The Python code snippets are in Appendix A.
Interpretations of the output
1. The confusion matrix created on the train data set is
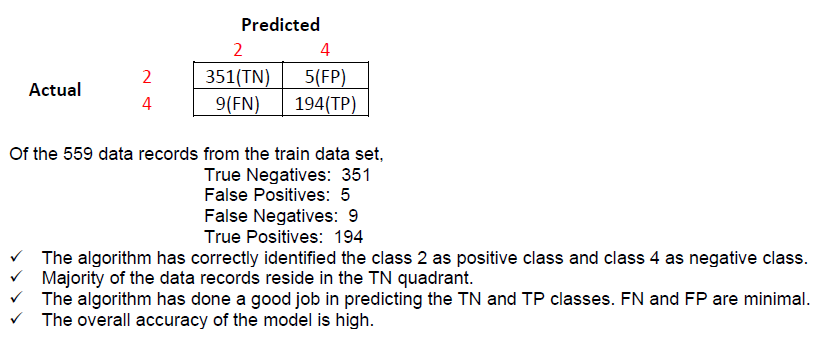
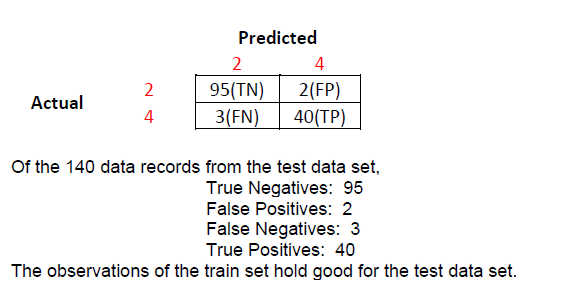
2. The confusion matrix created on the test data set is
3. The confusion matrix code for train data set is :
confmatrix_trainset = confusion_matrix(y_train,predict_train, labels=labels)
Changing the position of parameters y_train and predict_train can reverse the position of Actual and Predicted values as shown in Diagram 1. This will change the values of FP and FN. Hence, the position of the two parameters is very important. This is true for the test data set as well.
Confusion metrics
There are multiple accuracy metrics that can be generated from the confusion matrix.
✓ Accuracy
(all correct / all) = TP + TN / TP + TN + FP + FN
This is the general accuracy of the model. It is not useful, particularly when the classes are not equally represented i.e. the data is imbalanced in terms of the target classes. In our case study, we have imbalance classes with 65.5% of data representing the benign class and 34.5% representing the malignant class. Even if the model fails to identify the malignant class, the model may achieve a minimum accuracy of 65.5%. This is incorrect. Hence, we will need to derive class level metrics.
✓ Misclassification
(all incorrect / all) = FP + FN / TP + TN + FP + FN
Misclassification states how many cases were not classified correctly.
✓ Precision
(true positives / predicted positives) = TP / TP + FP
Precision states, out of all predicted malignant cases, how many actually turned out to be malignant. This is a class-level metric.
✓ Sensitivity aka Recall
(true positives / all actual positives) = TP / TP + FN
Sensitivity states, out of all the actual malignant cases, how many cases were correctly identified as malignant. This is a class-level metric.
Precision and Recall are critical class-level metrics. However, maximizing precision can pull down the value of recall, and vice versa.
In most problems, you could either give a higher priority to maximizing precision, or recall, depending upon the problem you are trying to solve. However, there is a simpler metric, known as F1-score, which is a harmonic mean of precision and recall.
The objective would be to optimize the F1-score.
F1-score = (2 * Precision * Recall) / (Precision + Recall)
Based on the confusion matrix and the metrics formula, below is the observation table.
Observation table
| Training Set (Total records = 559) |
|
| Metrics |
Score |
| Accuracy |
0.974 (97.4%) |
| Misclassification Error |
0.025 (2.5%) |
| Precision (Malignant Cases) |
0.974 (97.4%) |
| Recall (Malignant Cases) |
0.955 (95.5%) |
| F1-score |
0.964 |
| Test Set (Total records = 140) |
|
| Metrics |
Score |
| Accuracy |
0.964 (96.4%) |
| Misclassification Error |
0.035 (3.5%) |
| Precision (Malignant Cases) |
0.952 (95.2%) |
| Recall (Malignant Cases) |
0.930 (93.0%) |
| F1-score |
0.94 |
Conclusion
The general accuracy of the model using both train and test data set is similar and high.
Even the class level metrics are similar and high.
We can infer that the SVC model has been tuned appropriately, and has been able to do a good prediction on the test data set in terms of general accuracy, as well as class-level accuracy.
Overall, a confusion matrix helps improve the performance of machine learning classification models.
Want to learn more about machine learning and data science? Visit Oracle’s data science page.
Appendix A
Below are the python code snippets:
#Python Version – Python 3.6.4:: Anaconda, Inc.
#Sklearn version = 0.19.1
#Import the necessary libraries
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
#Create the 80/20 Train-Test split on the independent variables. Drop the dependent attribute “Class”
target = dataset[“Class”]
features = dataset.drop([“ID”,”Class”], axis=1)
X_train, X_test, y_train, y_test = train_test_split(features,target, test_size = 0.2, random_state = 10)
# Building a Support Vector Machine on train data
svc_model = SVC(C= .1, kernel=’linear’, gamma= 1)
svc_model.fit(X_train, y_train)
#Predict train and test dataset
predict_train = svc_model.predict(X_train)
prediction = svc_model.predict(X_test)
# check the accuracy on the train and test set
print(svc_model.score(X_train, y_train))
print(svc_model.score(X_test, y_test))
Output:
0.9749552772808586
0.9642857142857143
#Confusion matrix created for the train data set
confmatrix_trainset = confusion_matrix(y_train,predict_train, labels=labels)
pd.DataFrame(confmatrix_trainset, index=labels, columns=labels)
Output:
|
|
2 |
4 |
|
| 2 |
|
351 |
9 |
| 4 |
|
5 |
194 |
#Confusion matrix metrics created for the train data set
tn, fp, fn, tp = confusion_matrix(predict_train,y_train).ravel()
print(“True Negatives : “,tn)
print(“False Positives : “,fp)
print(“False Negatives : “, fn)
print(“True Positives : “, tp)
Output:
True Negatives : 351
False Positives : 5
False Negatives : 9
True Positives : 194
#Confusion matrix created for the test data set
confmatrix_testdata = confusion_matrix(prediction, y_test, labels=labels)
pd.DataFrame(confmatrix_testdata, index=labels, columns=labels)
Output:
| 2 |
4 |
|
| 2 |
95 |
2 |
| 4 |
3 |
40 |
#Confusion matrix metrics created for the test data set
tn, fp, fn, tp = confusion_matrix(prediction,y_test).ravel()
print(“True Negatives : “,tn)
print(“False Positives : “,fp)
print(“False Negatives : “, fn)
print(“True Positives : “, tp)
Output:
True Negatives : 95
False Positives : 2
False Negatives : 3
True Positives : 40