This posting will look at the aggregation component that was introduced in ODI 12c. For many ETL tool users this shouldn’t be a big surprise, its a little different than ODI 11g but for good reason. You can use this component for composing data with relational like operations such as sum, average and so forth. Also, Oracle SQL supports special functions called Analytic SQL functions, you can use a specially configured aggregation component or the expression component for these now in ODI 12c. In database systems an aggregate transformation is a transformation where the values of multiple rows are grouped together as input on certain criteria to form a single value of more significant meaning – that’s exactly the purpose of the aggregate component.
In the image below you can see the aggregate component in action within a mapping, for how this and a few other examples are built look at the ODI 12c Aggregation Viewlet here – the viewlet illustrates a simple aggregation being built and then some Oracle analytic SQL such as AVG(EMP.SAL) OVER (PARTITION BY EMP.DEPTNO) built using both the aggregate component and the expression component.
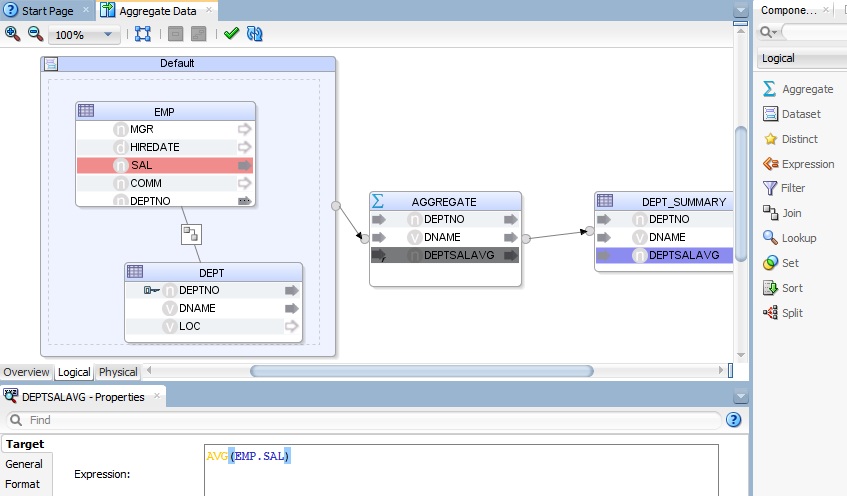
In 11g you used to just write the aggregate expression directly on the target, this made life easy for some cases, but it wan’t a very obvious gesture plus had other drawbacks with ordering of transformations (agg before join/lookup. after set and so forth) and supporting analytic SQL for example – there are a lot of postings from creative folks working around this in 11g – anything from customizing KMs, to bypassing aggregation analysis in the ODI code generator.
The aggregate component has a few interesting aspects.
1. Firstly and foremost it defines the attributes projected from it – ODI automatically will perform the grouping all you do is define the aggregation expressions for those columns aggregated. In 12c you can control this automatic grouping behavior so that you get the code you desire, so you can indicate that an attribute should not be included in the group by, that’s what I did in the analytic SQL example using the aggregate component.
2. The component has a few other properties of interest; it has a HAVING clause and a manual group by clause. The HAVING clause includes a predicate used to filter rows resulting from the GROUP BY clause. Because it acts on the results of the GROUP BY clause, aggregation functions can be used in the HAVING clause predicate, in 11g the filter was overloaded and used for both having clause and filter clause, this is no longer the case. If a filter is after an aggregate, it is after the aggregate (not sometimes after, sometimes having).
3. The manual group by clause let’s you use special database grouping grammar if you need to. For example Oracle has a wealth of highly specialized grouping capabilities for data warehousing such as the CUBE function. If you want to use specialized functions like that you can manually define the code here. The example below shows the use of a manual group from an example in the Oracle database data warehousing guide where the SUM aggregate function is used along with the CUBE function in the group by clause.
The SQL I am trying to generate looks like the following from the data warehousing guide;
- SELECT channel_desc, calendar_month_desc, countries.country_iso_code,
- TO_CHAR(SUM(amount_sold), ‘9,999,999,999’) SALES$
- FROM sales, customers, times, channels, countries
- WHERE sales.time_id=times.time_id AND sales.cust_id=customers.cust_id AND
- sales.channel_id= channels.channel_id
- AND customers.country_id = countries.country_id
- AND channels.channel_desc IN
- (‘Direct Sales’, ‘Internet’) AND times.calendar_month_desc IN
- (‘2000-09’, ‘2000-10’) AND countries.country_iso_code IN (‘GB’, ‘US’)
- GROUP BY CUBE(channel_desc, calendar_month_desc, countries.country_iso_code);
I can capture the source datastores, the filters and joins using ODI’s dataset (or as a traditional flow) which enables us to incrementally design the mapping and the aggregate component for the sum and group by as follows;

In the above mapping you can see the joins and filters declared in ODI’s dataset, allowing you to capture the relationships of the datastores required in an entity-relationship style just like ODI 11g. The mix of ODI’s declarative design and the common flow design provides for a familiar design experience. The example below illustrates flow design (basic arbitrary ordering) – a table load where only the employees who have maximum commission are loaded into a target. The maximum commission is retrieved from the bonus datastore and there is a look using employees as the driving table and only those with maximum commission projected.

Hopefully this has given you a taster for some of the new capabilities provided by the aggregate component in ODI 12c. In summary, the actions should be much more consistent in behavior and more easily discoverable for users, the use of the components in a flow graph also supports arbitrary designs and the tool (rather than the interface designer) takes care of the realization using ODI’s knowledge modules.
Interested to know if a deep dive into each component is interesting for folks. Any thoughts?
