Oracle Data Integrator (ODI) enables seamless data integration across diverse environments. A common need is to load multiple flat files from a local machine into a single Oracle Autonomous Data Warehouse (ADW) table with auditability and error handling.
This blog outlines a solution using ODI mappings, packages, procedures, and a Jython/Python script to track, process, and archive files efficiently.
Solution Architecture
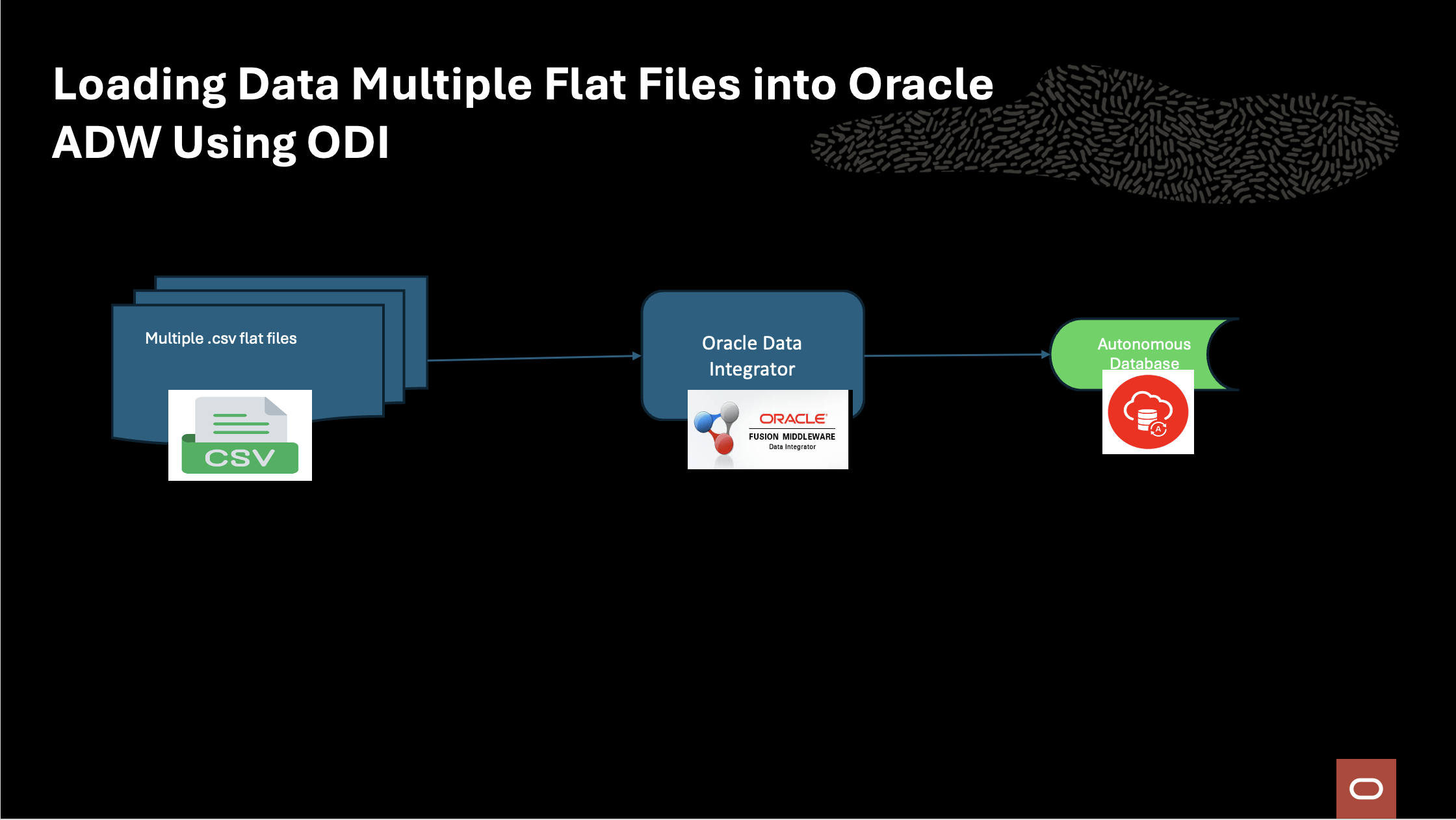
Solution Strategy
The solution uses the following key components:
-
Audit Tables
-
Store metadata about files processed (file name, timestamp, status, row counts, etc.).
-
Help ensure traceability and avoid duplicate processing.
-
-
Single ODI Mapping
-
Designed to process data from flat files into the target ADW table.
-
A variable is used to dynamically pick up each file from the local directory.
-
-
ODI Package & Procedure
-
Package controls the end-to-end orchestration.
-
Procedure loops through the list of files and updates audit tables after each load.
-
-
Jython Script
-
Reads available files from the local directory.
-
Inserts file metadata into the audit table before processing begins.
-
Helps maintain a consistent list of files to be loaded.
-
-
Archival Mechanism
-
Once a file is successfully processed, it is moved from the local processing directory into an archive directory.
-
This ensures processed files are not picked up again while maintaining a historical copy.
-
Implementation Steps
1. Prepare Audit Table
Create an audit table in ADW to capture file details such as:
-
File name
-
Process start and end timestamps
-
Status (In Progress, Success, Failed)
-
Row counts
--DDL script
CREATE TABLE "SRC"."FILES_AUDIT"
( "CATEGORY" VARCHAR2(200 BYTE) COLLATE "USING_NLS_COMP",
"SUB_CATEGORY" VARCHAR2(200 BYTE) COLLATE "USING_NLS_COMP",
"PATH" VARCHAR2(200 BYTE) COLLATE "USING_NLS_COMP",
"NAME" VARCHAR2(50 BYTE) COLLATE "USING_NLS_COMP",
"STATUS" VARCHAR2(50 BYTE) COLLATE "USING_NLS_COMP",
"LINES_COUNT" NUMBER,
"CREATION_DATE" DATE DEFAULT SYSDATE,
"PICKUP_DATE" DATE,
"PROCESSED_DATE" DATE,
"LOAD_TIME_SECONDS" NUMBER,
"SESSION_ID" NUMBER
) DEFAULT COLLATION "USING_NLS_COMP" ;
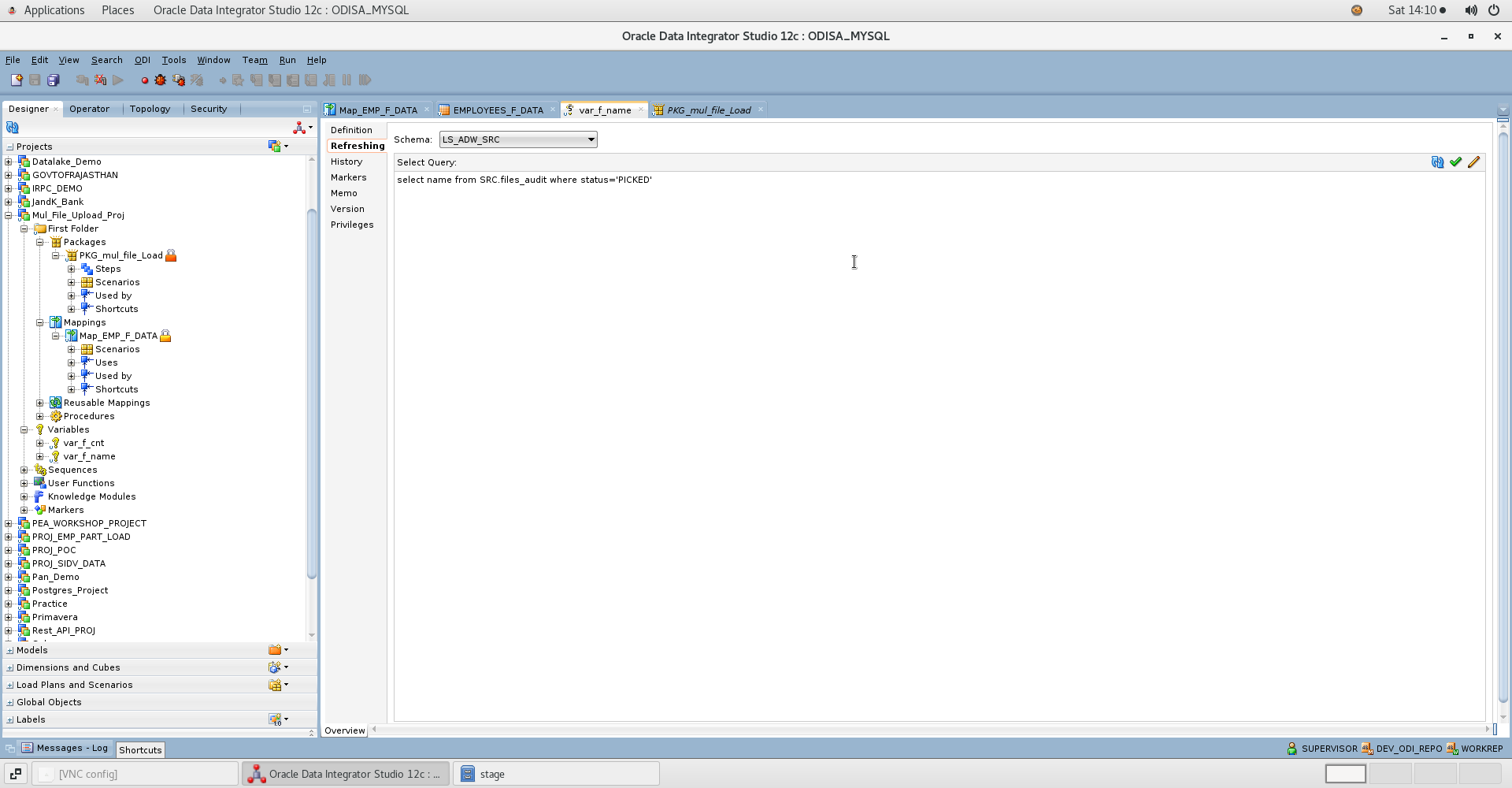
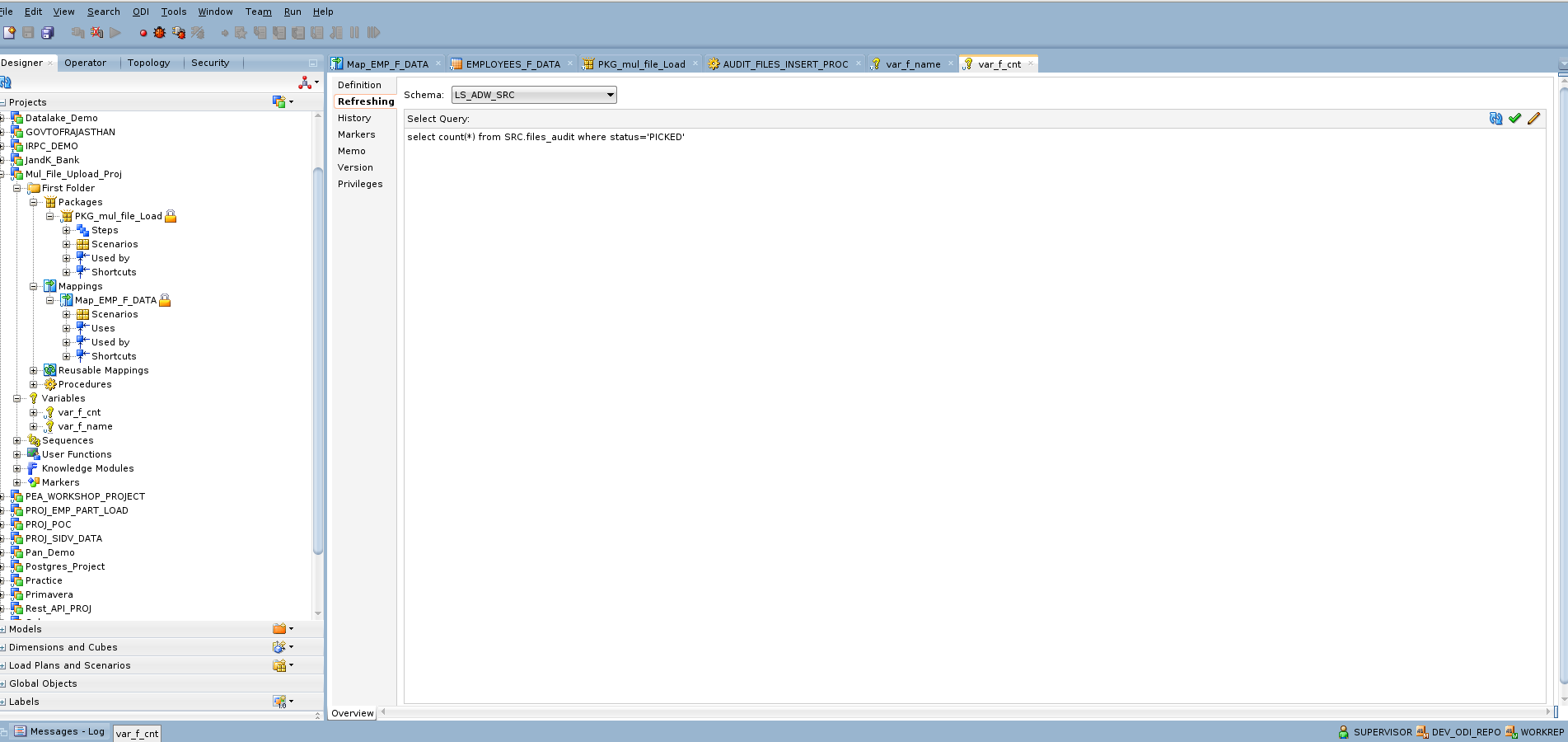
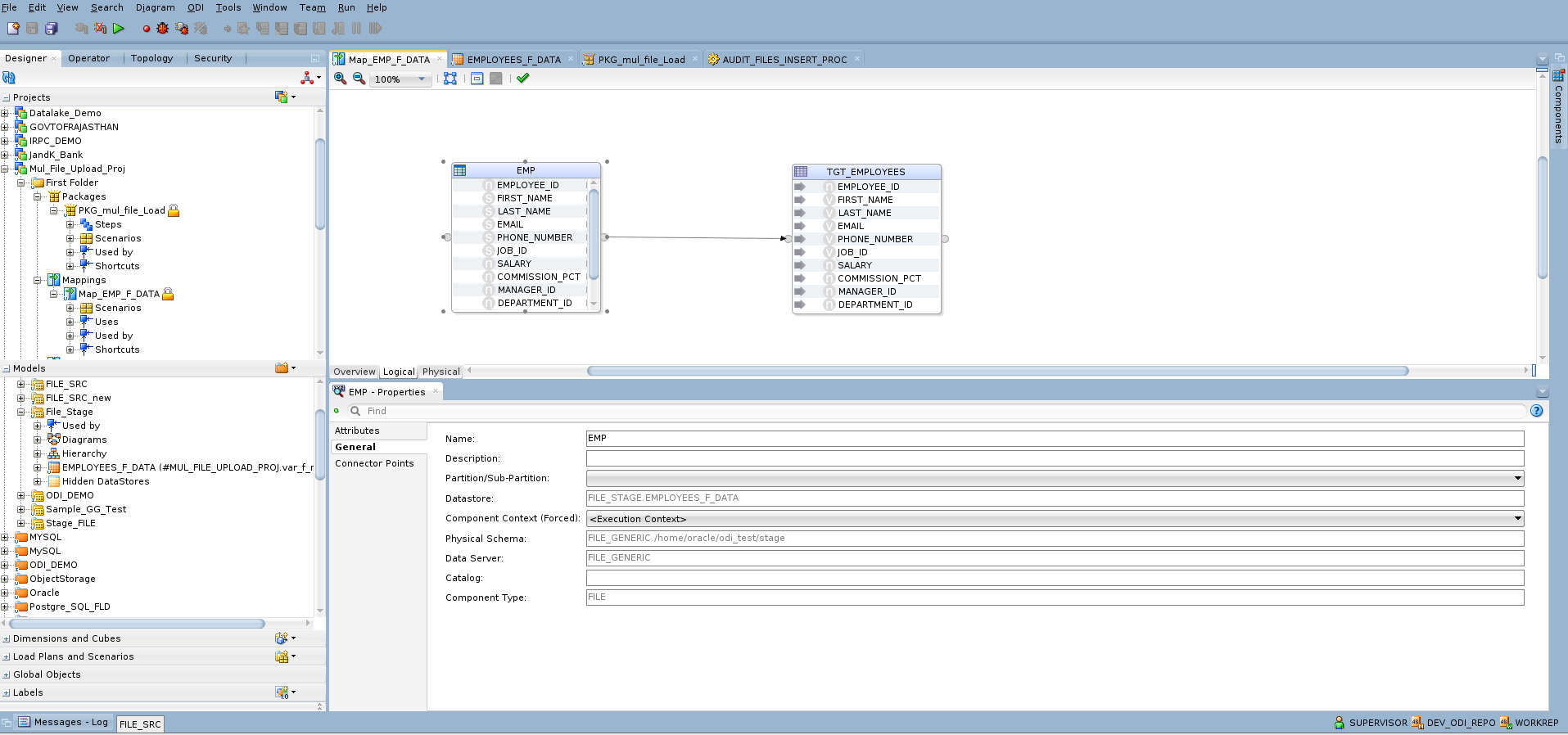
2. Create ODI Mapping
-
Define a mapping to load flat file data into the target ADW table.
-
Parameterize the source file location using an ODI variable.
var_f_name and var_f_cnt are created to dynamically fetch file names marked with a ‘PICKED’ status from the audit table and to maintain the file counter as a loop control variable during package execution and source file is parametrized with var_f_name
3. Develop Jython Script
-
Script reads file names from the local directory.
-
Inserts file details into the audit table with “PICKED” status.
-
This Jython/Python code is created within a ODI procedure and below is the code for inserting information into audit table.
import os
from glob import glob
from java.sql import SQLException
path = '<%=odiRef.getOption( "STAGE_DIR" )%>'
pattern = os.path.join(path,'*.csv')
sess_no = <%=odiRef.getSession("SESS_NO")%>
# Change the Path to Stage
os.chdir(path)
files = glob(pattern)
# Get the Connections
src_conn = odiRef.getJDBCConnection( "SRC" )
sql_stmt = src_conn.createStatement()
for file in files:
filename = os.path.basename(file) # Get the FileName
#linecount_cmd = 'wc -l %s | cut -d" " -f1'%(file)
#linecount = os.system() # Get the Number of lines in a file
fp = open(file,'r')
linecount = len(fp.readlines())
fp.close()
sql_query = """INSERT INTO SRC.files_audit VALUES
('EMP',NULL,'%s','%s','PICKED',%d,SYSDATE,NULL,NULL,NULL,%d)""" %(path,filename,linecount,sess_no)
try:
# Execute the statement to make entry in the audit table
sql_stmt.execute(sql_query)
except SQLException, se:
raise 'Error with Query \n%s'%(sql_query)
# Close the Connections
sql_stmt.close()
src_conn.close()
4. Build ODI Package & Procedure to Audit Tables
-
Package loops over files based on entries in the audit table.
-
For each file:
-
Mapping is executed to load data into ADW.
-
Procedure updates audit table with status and row counts.
-
-
On success, file is moved to the archive folder.
The screenshot below shows the ODI procedure used for updating the audit table, along with the corresponding SQL code.
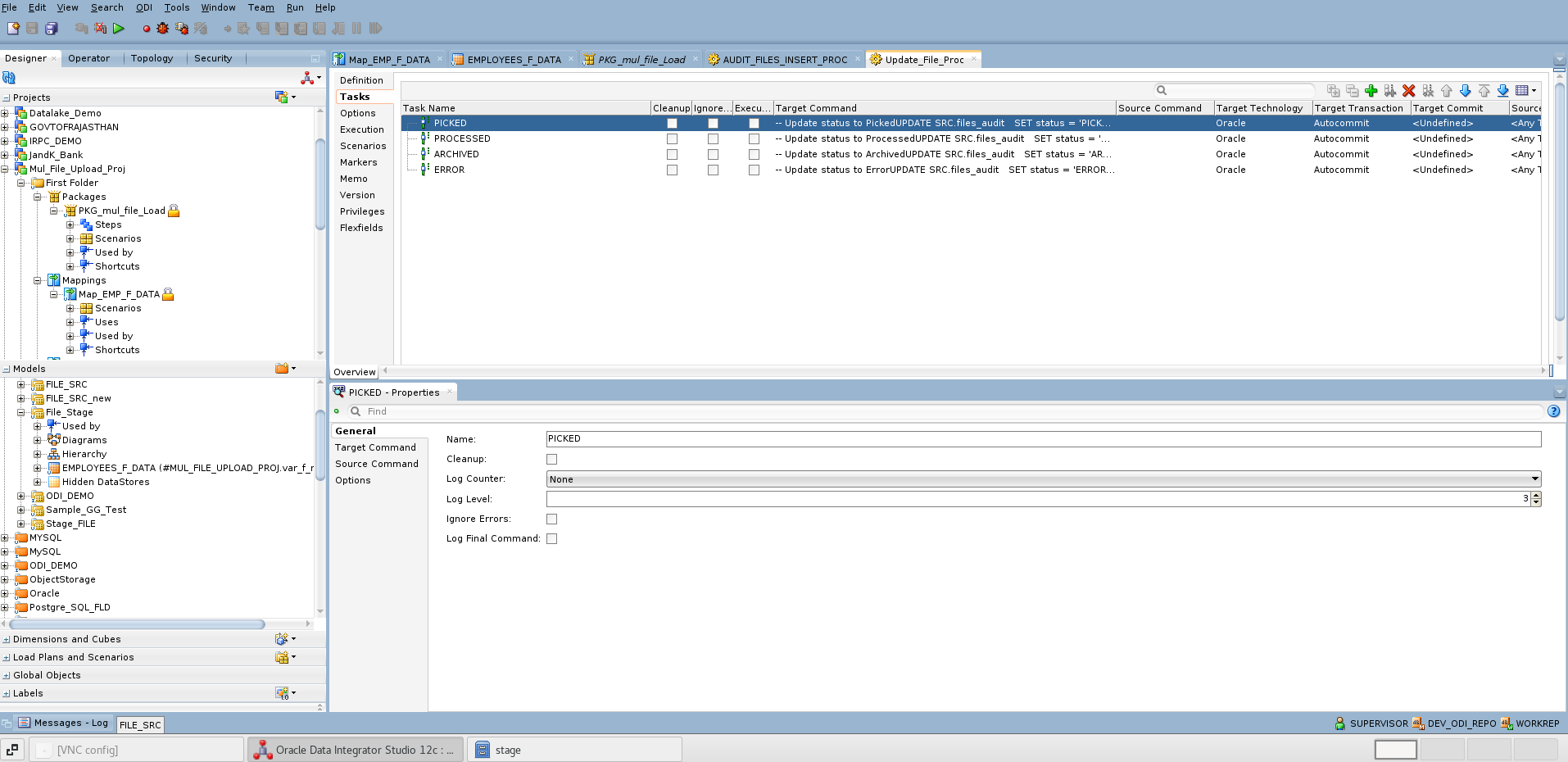
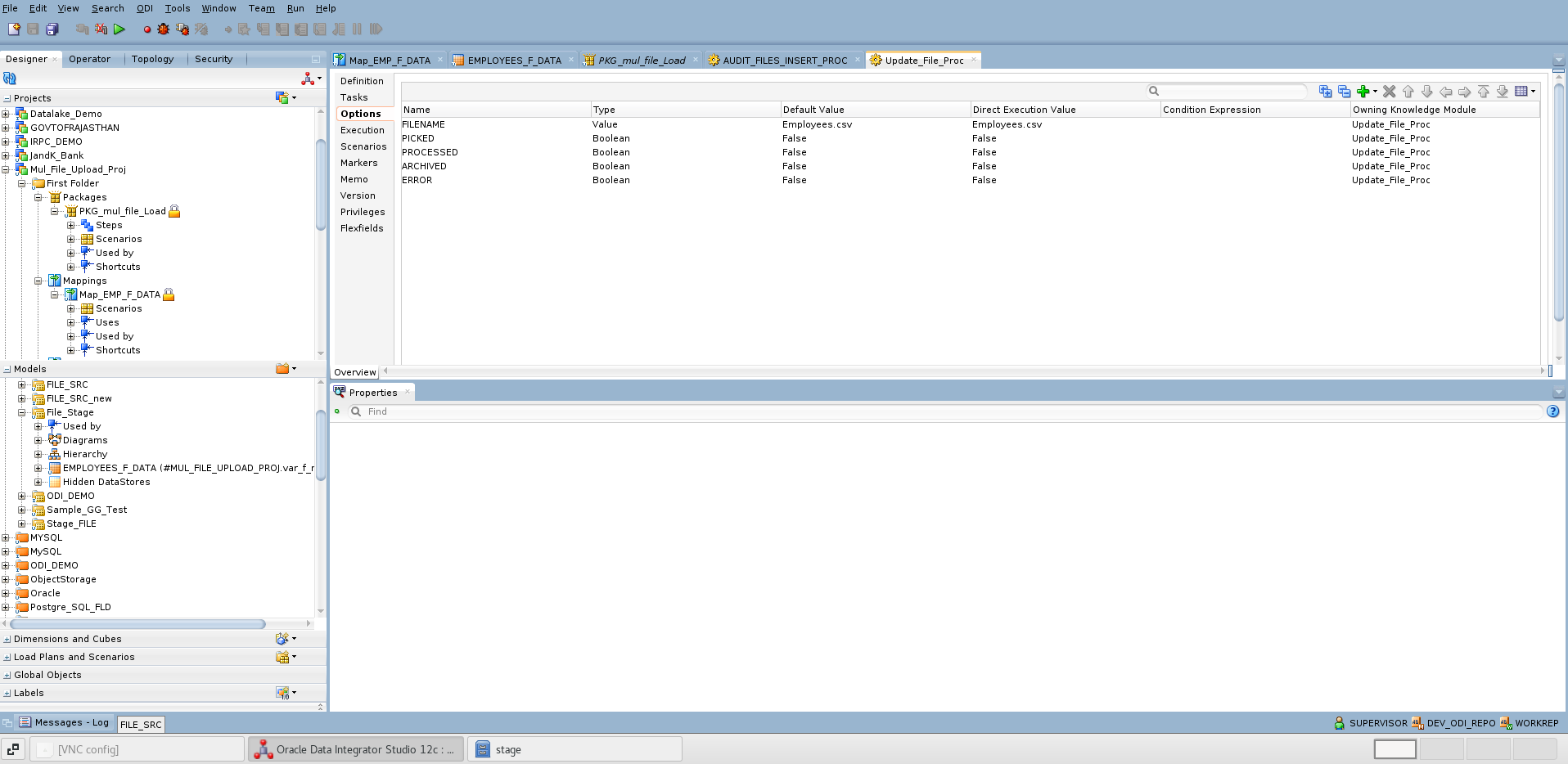
-- Update status to Picked
UPDATE SRC.files_audit
SET status = 'PICKED', session_id = <%=odiRef.getSession("SESS_NO")%>, pickup_date = SYSDATE
WHERE name = '<%=odiRef.getOption("FILENAME")%>'
-- Update status to Processed
UPDATE SRC.files_audit
SET status = 'PROCESSED', session_id = <%=odiRef.getSession("SESS_NO")%>, PROCESSED_DATE = SYSDATE
, load_time_seconds = (SYSDATE - pickup_date)*24*60*60
WHERE status = 'PICKED'
AND name = '<%=odiRef.getOption("FILENAME")%>'
-- Update status to Archived
UPDATE SRC.files_audit
SET status = 'ARCHIVED', session_id = <%=odiRef.getSession("SESS_NO")%>
WHERE status = 'PROCESSED'
AND name = '<%=odiRef.getOption("FILENAME")%>'
-- Update status to Error
UPDATE SRC.files_audit
SET status = 'ERROR', session_id = <%=odiRef.getSession("SESS_NO")%>
WHERE name = '<%=odiRef.getOption("FILENAME")%>'
Once all the individual components are configured, they can be combined into a single ODI package for execution. The screenshot below illustrates this setup.
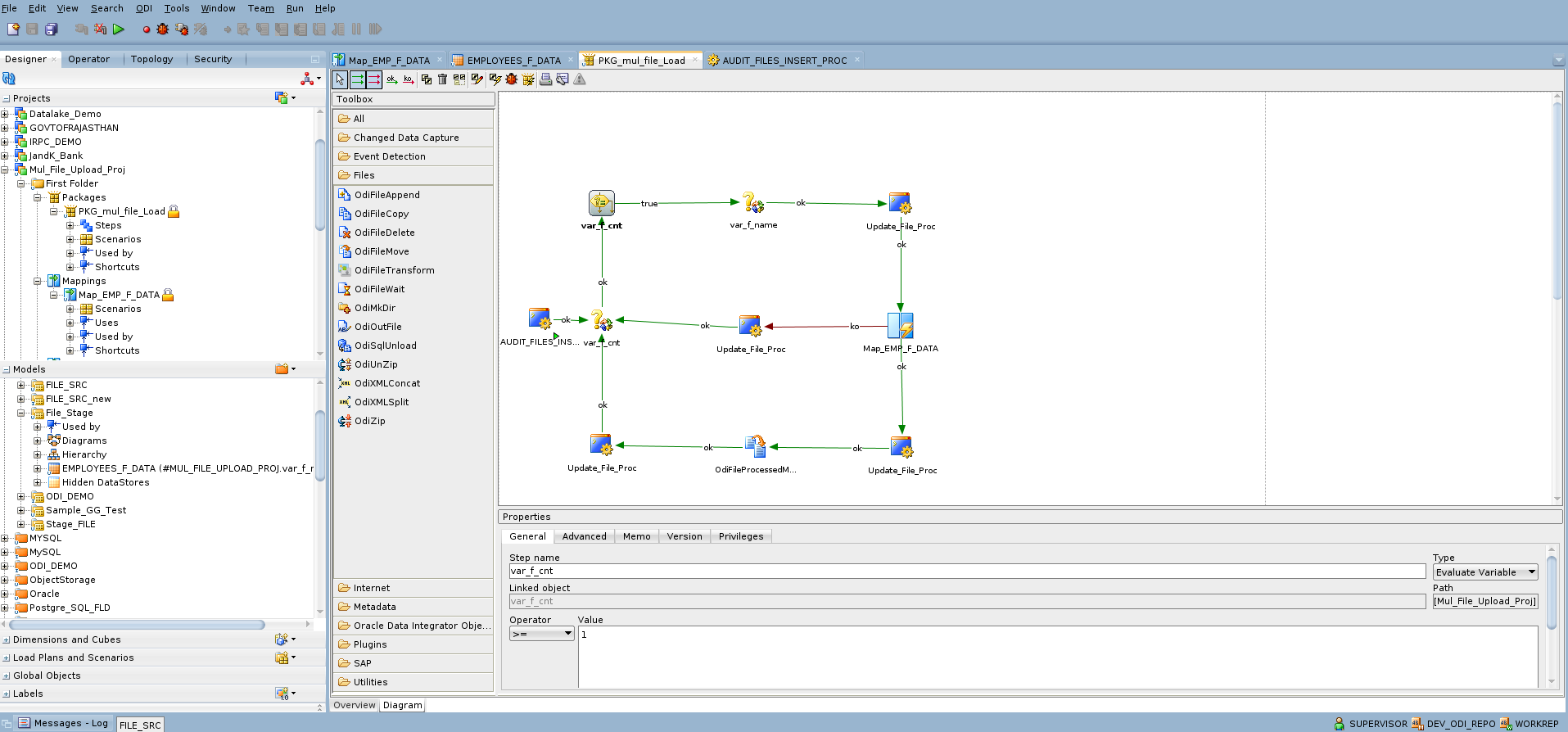
After the file data is successfully loaded and processed into the Autonomous Database target table, the source files are moved to an archive folder using the odiFileMove package step. This ensures that processed files are securely archived and excluded from future runs.
If the mapping encounters an error during execution, the audit table is updated with an error status for the corresponding run record. Control then moves to the end of the package job execution, ensuring that the error is logged, and file processing is properly closed.
I hope that this blog helps as you learn more about Oracle Data Integration’s unique capabilities on multiple file data load. For more information, check out the documentation.
