Welcome back! We hope that you’re enjoying these introductory blogs about Oracle Cloud Infrastructure (OCI) Data Integration. To get the list of previous blogs related to Data Integration, refer to the Data Integration blog site. Today, we’re learning about the schema drift feature in OCI Data Integration.
What is schema drift?
Schema drift happens when sources or targets change metadata. You’re often faced with dynamic data sets and constantly changing requirements. Fields, columns, and types can be added, removed, or changed on the fly. Without handling schema drift, data flows become vulnerable to upstream data source changes. Typical extract, transform, load (ETL) patterns fail when incoming columns and fields change because they tend to be tied to those source names. Schema drift can happen on the source and target systems.
With the help of schema drift, data flows become more resilient and adapt automatically to any changes. You don’t need to redesign your data flows when changes occur.
Implementing schema drift in OCI Data Integration
Prerequisites
- Based on the previous blogs on Data Integration and Oracle documentation, you have set up a workspace, projects, and applications and understand the creation and execution of a Data Flow using integration tasks.
- Corresponding data assets, such as sources and targets, are defined in the workspace.
Let’s explore how to deal with schema drift and extend it to more complex transformation scenarios. In this case, we load the data from a CSV file (“Emp_Records.csv”) to Autonomous Data Warehouse. The following screenshot shows the data in the CSV file:
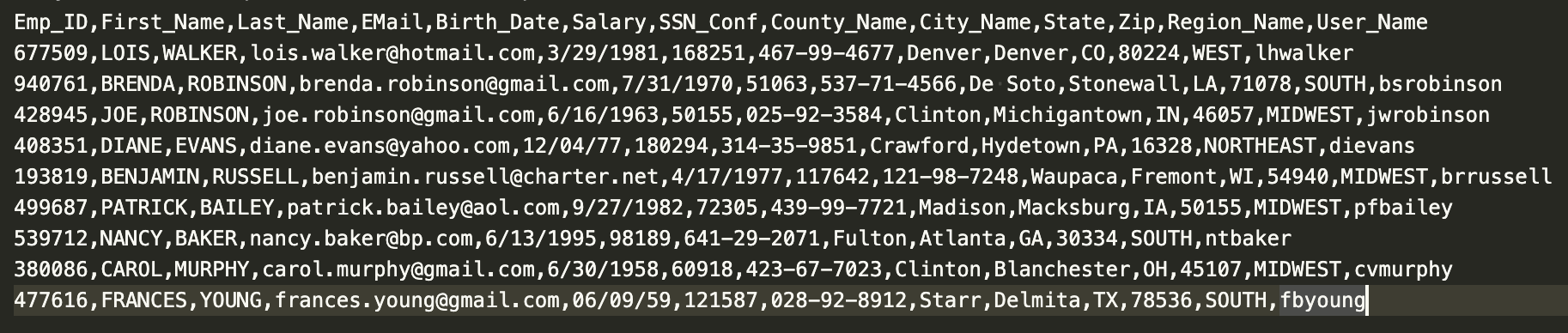
The following transformations are performed as part of the schema drift:
- SSN_Conf is confidential information, so in the Data Integration data flow, we hash the information.
- All the date columns in the format “MM/DD/YYYY” are standardized to the date format “DD-MM-YYYY.”
- All the columns ending with “_name” are converted in the proper case.
- New columns, such as Phone_No_Conf, Password_Conf, and Joining_Date, are added as part of late bindings.
Let’s begin!
Creating the data flow using schema drift with an existing source file, creating the integration task, publishing the task into applications, and running the task
- Place the source CSV File (“Emp_Records.csv”) in an OCI Object Storage bucket.
- Add a Source Operator pointing to that CSV file and enable the schema drift option in the source operator if needed. It is enabled by default.
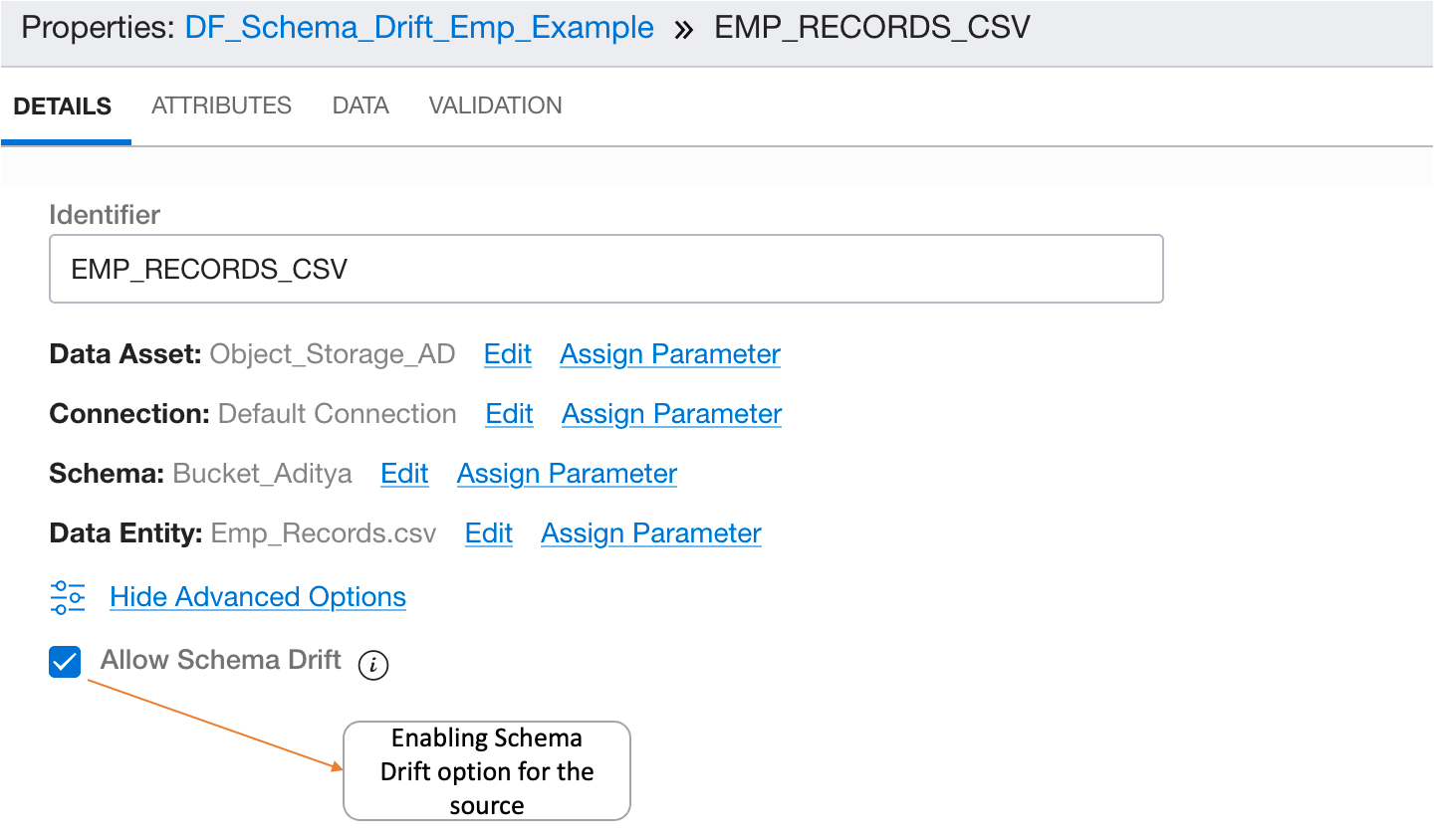
-
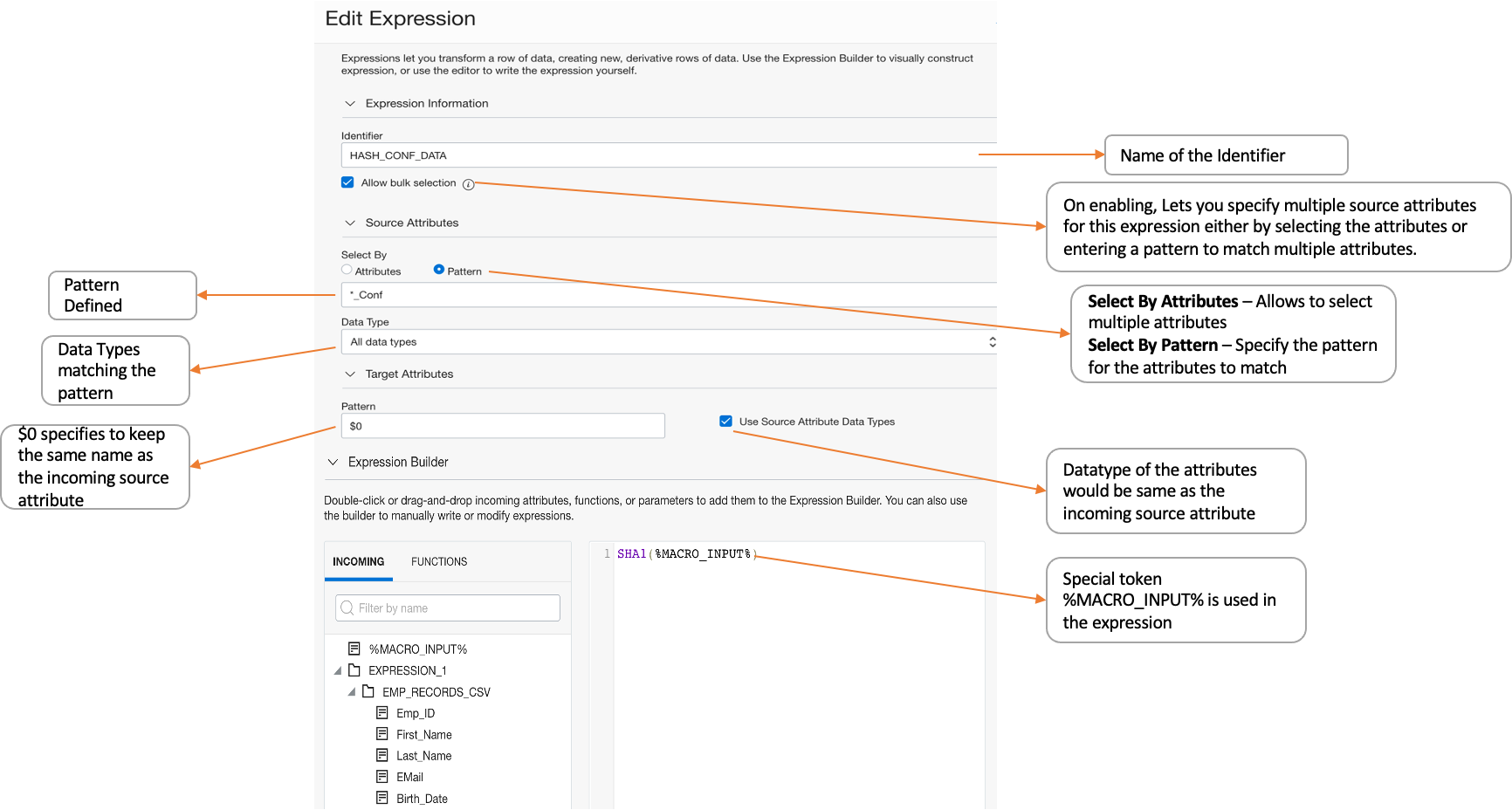
Then add an Expression Operator and click Add Expression. You can perform bulk transformations on sets of attributes with the following commands.
- Specify a pattern (name plus datatype) for the attributes to match.
- Specify a new data type for the resultant attributes or keep the existing one.
- Specify a new name for the resultant attributes.
- Use a special token (%MACRO_INPUT%) in the expression.
In the following screenshots, the column name ending with “_conf” are hashed. Here, “_conf” is used to identify the confidential data columns, like SSN.
Similarly, created expressions for the date columns and the columns ending with “_name.”
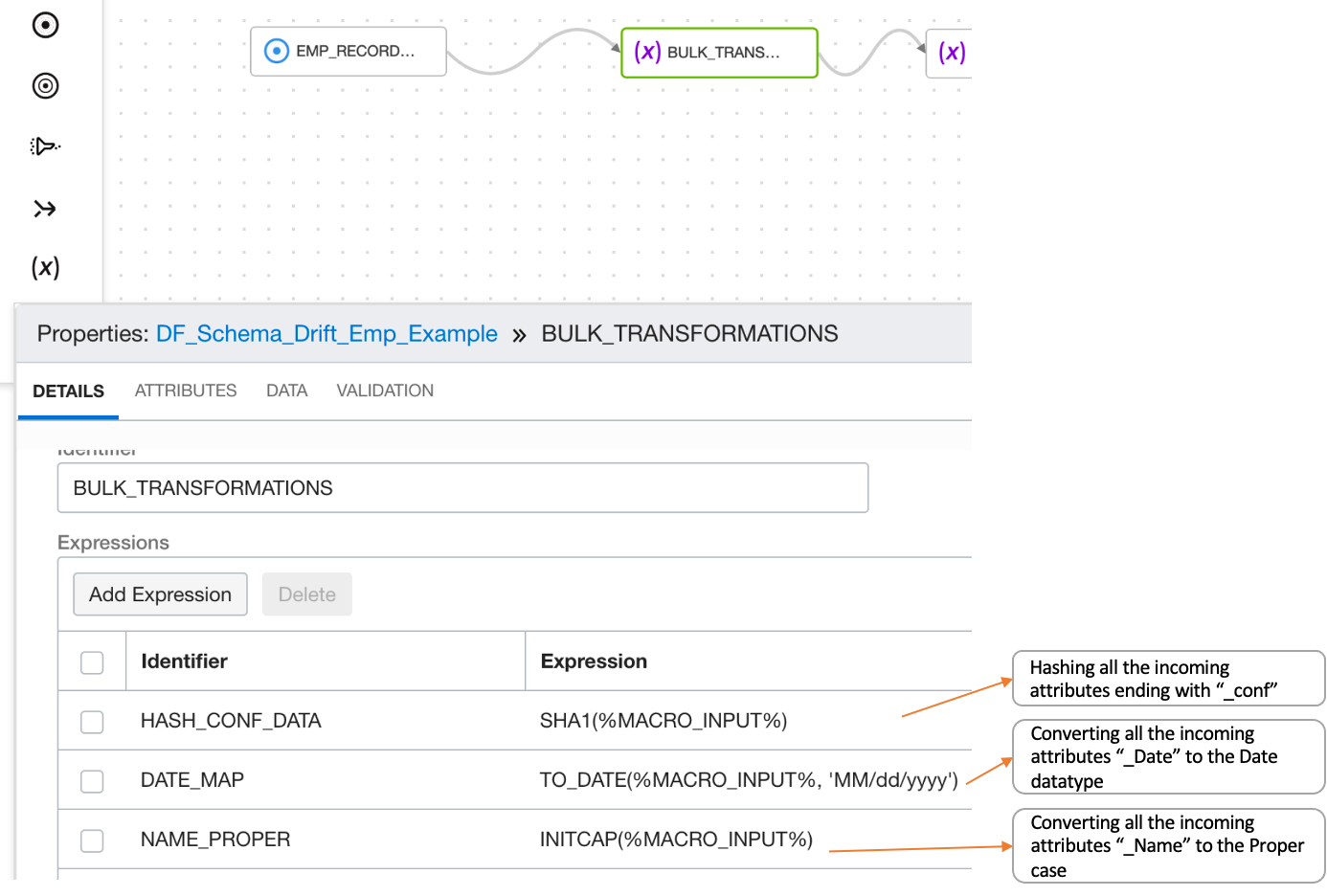
You can do the previous steps in the Data Xplorer in the Data tab, which results in creating the expression operator and adding the expressions. In the Data Xplorer, we have changed the case for the incoming attributes having “_Name” to Proper case.
- Enter *_Name as a naming pattern.
- Pick VARCHAR as the data type filter.
- Select Change Case transformation in the list and set it to “Proper” Type.

Also, we concatenated the First_Name and Last_Name to Full_Name in the Expression operator after the pattern definition.
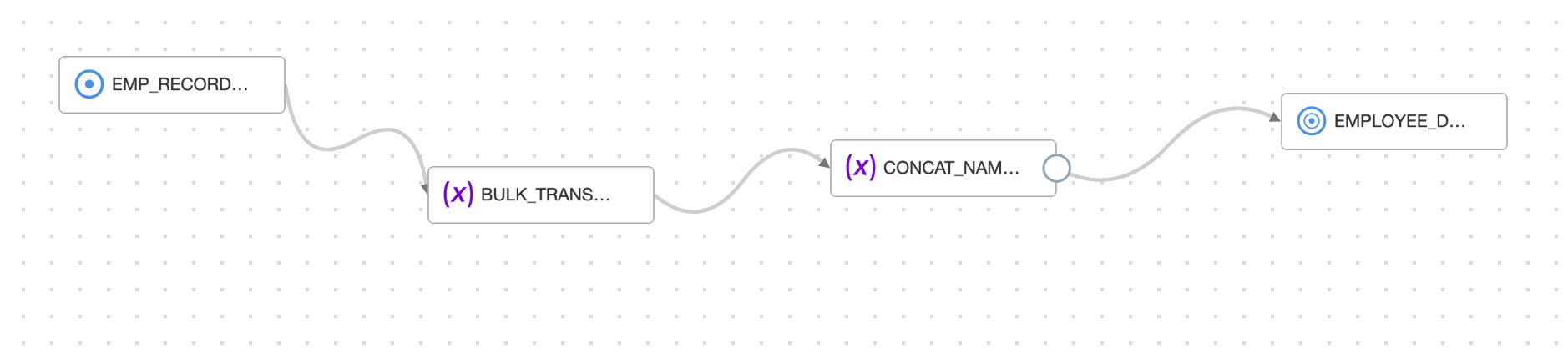
Add a target operator pointing to an Autonomous Data Warehouse table then click on Map. Map the attributes with the help of a pattern using “Map by pattern” where any new column added is automatically mapped with the help of patterns defined in the data flow.

When the data flow design is complete, save it, create an integration task, publish to an application, and then run the corresponding task.

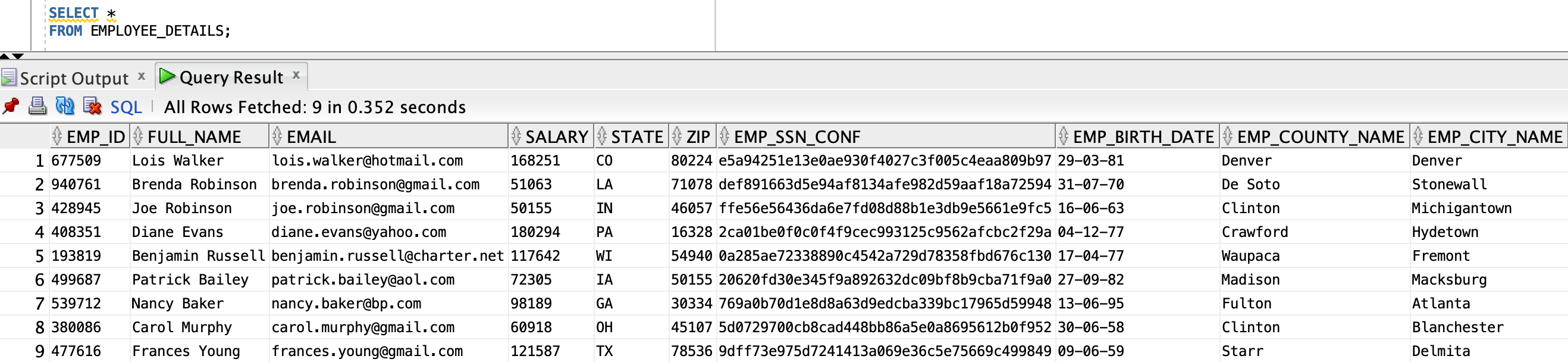
With the help of schema drift, new column values are automatically mapped to the target and populated without requiring any data flow or task change
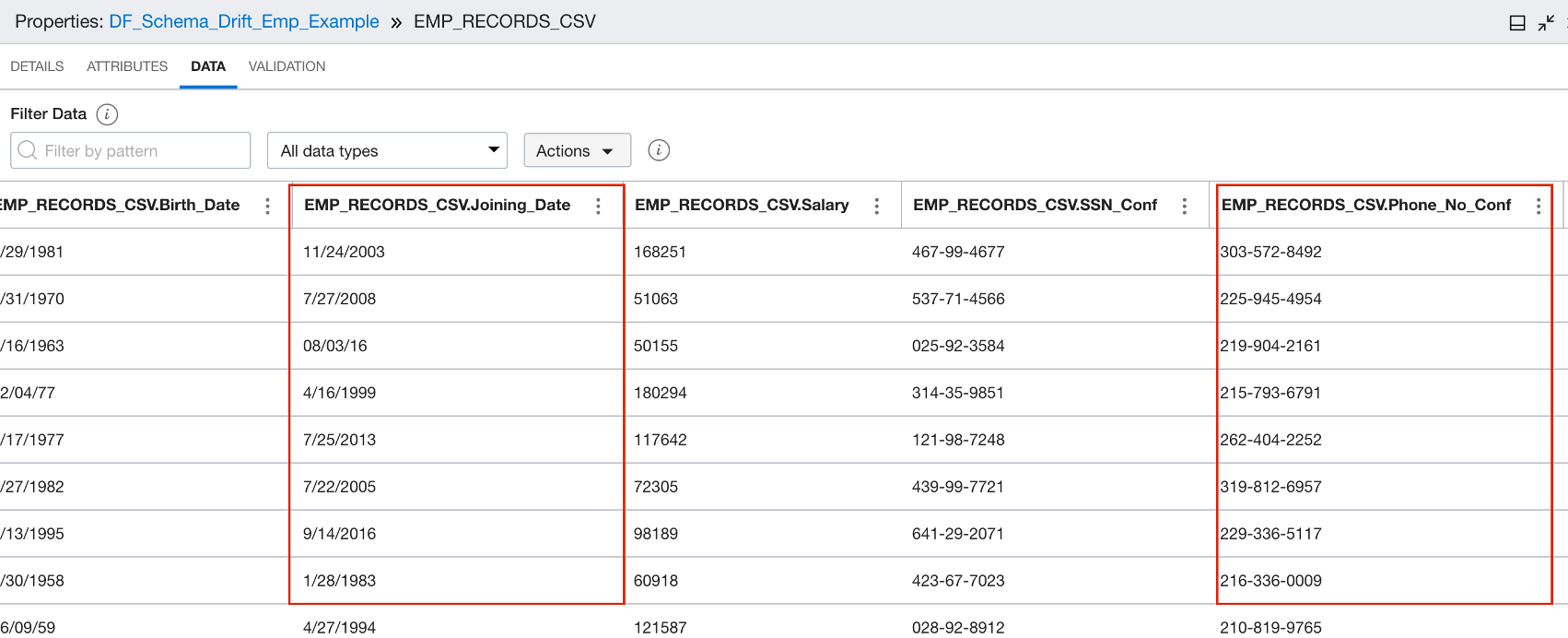
New columns, such as Joining_Date, Phone_No_Conf, Password_Conf, are added in the source CSV file, and the source is overwritten in Object Storage.

In the data flow target operator, the Integration Strategy has been set as “overwrite,” so the data is truncated and inserted again. In the target, the new column values are null.

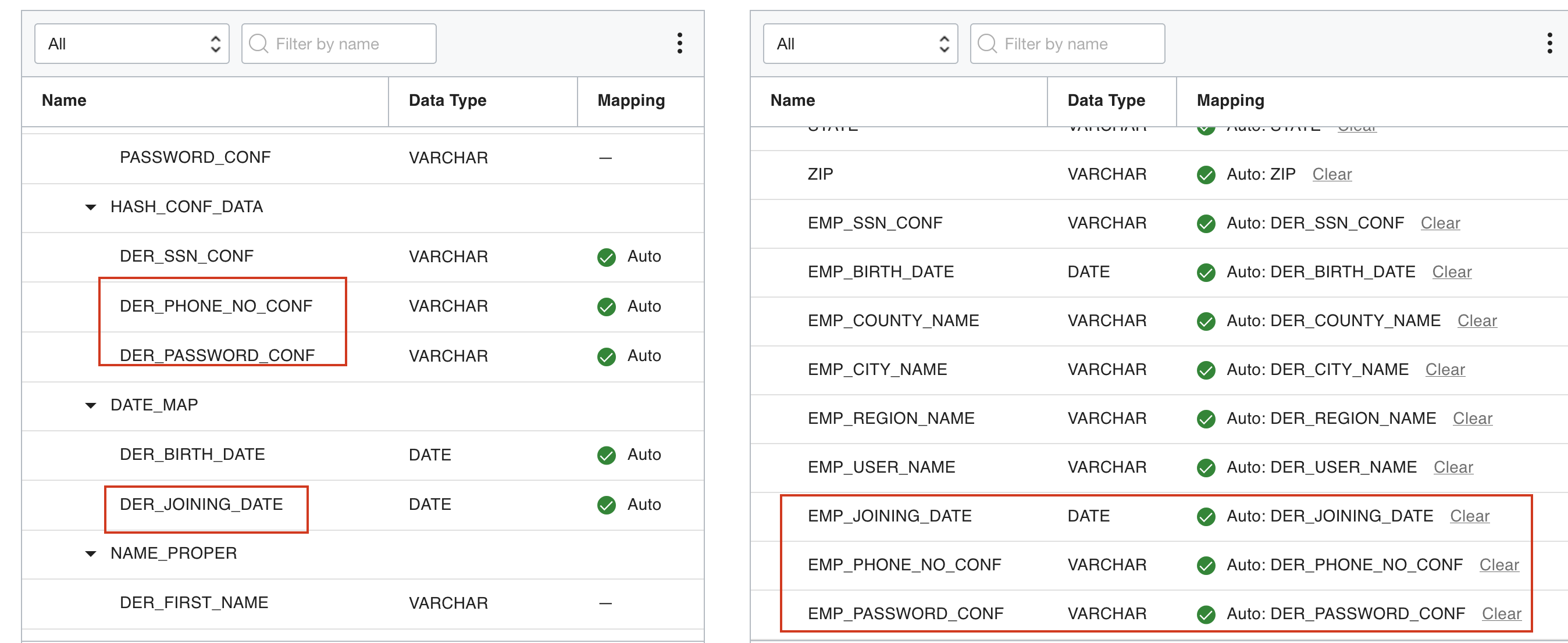
In the data flow, the new columns are reflected in the same order as the source. Transformation rules are automatically applied as well as the automapping in the target operator.
The following screenshot shows the mapping in the target operator:
Then we rerun the same published task in the application. The new columns are populated in the target “EMPLOYEE_DETAILS” table.
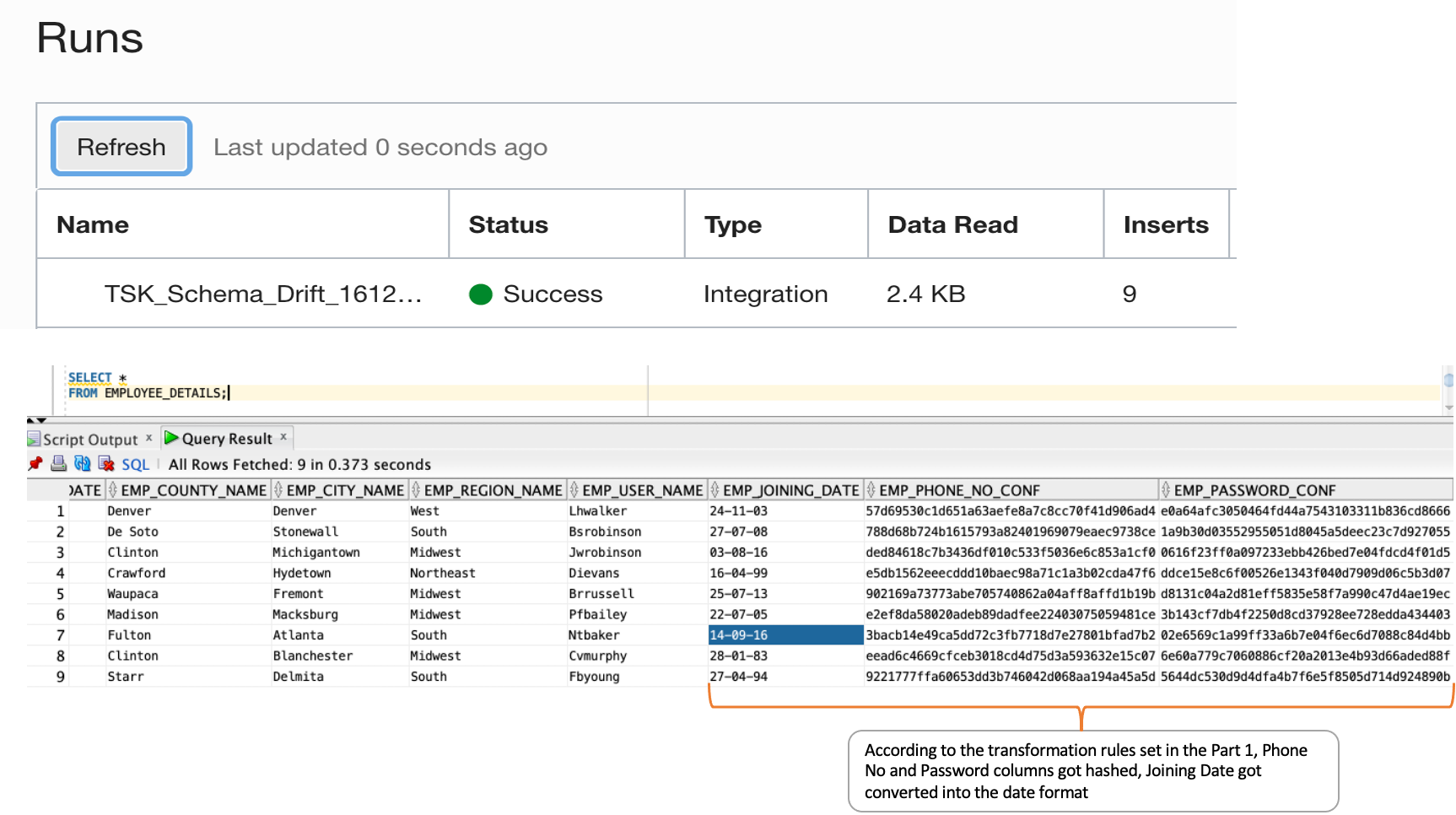
With this process, we can apply and use the schema drift feature in OCI Data Integration to help users by making the data flow more resilient to changes over time.
Conclusion
Have you seen some of our other blogs? Check out all the blogs related to Oracle Cloud Infrastructure Data Integration. To learn more, check out some Oracle Cloud Infrastructure Data Integration tutorials and documentation.
