In today’s data-driven world, efficient data integration has become a cornerstone of business success. Oracle Cloud Infrastructure (OCI) Data Integration’s Managed Incremental Extract from Oracle Fusion is a powerful feature designed to simplify the process of extracting data from Oracle Fusion and loading it into your data lake on a schedule. In this blog, we’ll explore the capabilities and benefits of this solution and how it can streamline your data integration processes. OCI Data Integration is a cloud-native, fully managed service offered by Oracle Cloud. It empowers organizations to seamlessly extract, transform, and load (ETL) data from various sources into their data lakes. Whether you’re dealing with on-premises databases or cloud applications like Oracle Fusion, OCI Data Integration provides a robust and scalable solution.
Traditionally, data extraction involved retrieving all the data from a source system whenever an update was required. This approach is not only time-consuming but also resource-intensive. Extracting the entire dataset, especially from large and complex applications like Oracle Fusion, can lead to inefficiencies and increased operational costs. We looked at a custom approach in this previous blog, where we implemented a user managed incremental data extraction for Fusion Applications. In this blog, we use an Oracle service managed solution to extract data from Fusion Applications.
Instead of extracting all the data every time, incremental extraction only retrieves the data that has changed or is new since the last extraction. This approach minimizes data transfer volumes, reduces processing time, and ensures that the data in your data lake remains up-to-date.
The Fusion source operator provides an option to select managed incremental extraction, upon selection of this option OCI Data Integration controls the execution and update the last extract date variable for the user internally, it also provides user the capability to override the internal dates if needed for manual repair or maintenance reruns.
In this article we will also see how to parameterize a dataflow and then use it to easily replicate multiple Fusion PVOs.
Let’s begin the implementation of managed incremental extraction of Fusion data.
Create DIS Dataflow with incremental extractions from FA PVO
In this example, we create a DataFlow to extract CodeCombinationExtractPVO VO in the Finance subject area and load into an Autonomous Data Warehouse.
Unlike in the case of user managed extraction in which we perform Full extraction first and followed by Incremental extraction, we will start with incremental extraction by selecting the extract strategy as ‘Incremental’ and choose the Last Extract date option as ‘Managed’.
We create a DataFlow for the extraction of CodeCombinationExtractPVO VO in the Finance subject area and load into an Autonomous Data Warehouse. We select the extract strategy as ‘Incremental’ and choose the Last Extract date option as Managed.

Figure 1: DataFlow source configuration for managed Incremental extraction
We select the Create new data entity option in the target operator so OCI DI will create a table and load the data (you can also create a table in ADW with required constraints in advance and select it as target with Merge as Integration Strategy).
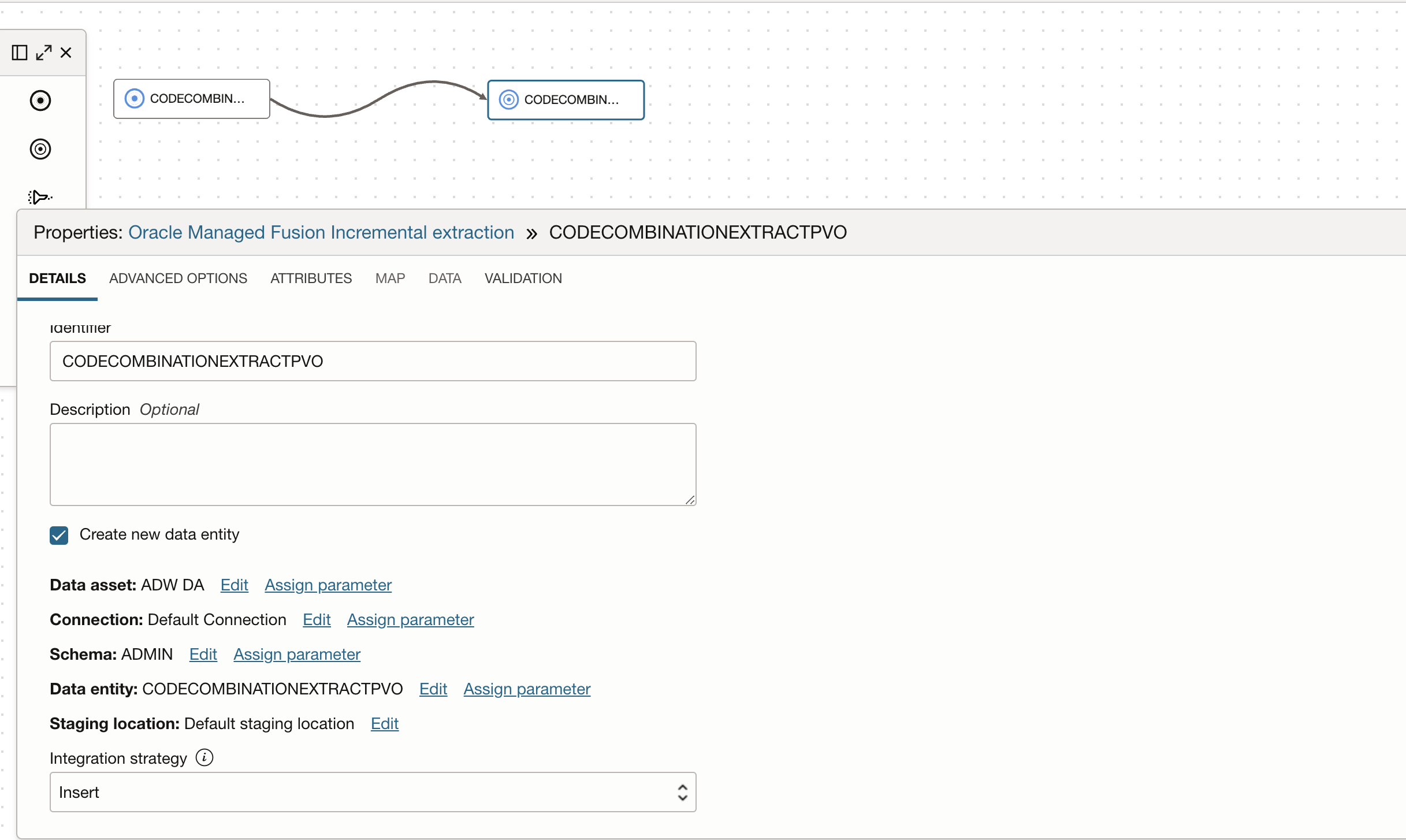
Figure 2: Target operator configuration
Run the dataflow
Now create an integration task and publish to your application.
When we run this published Integration task, we get an option to override the SYS.LAST_LOAD_DATE which is by default set to 1970-01-01. You can either keep this last load date as it is or edit to override this Last load date to different date in case not all historic data is needed, this is where you can define a cut-off date for your initial extract/load.
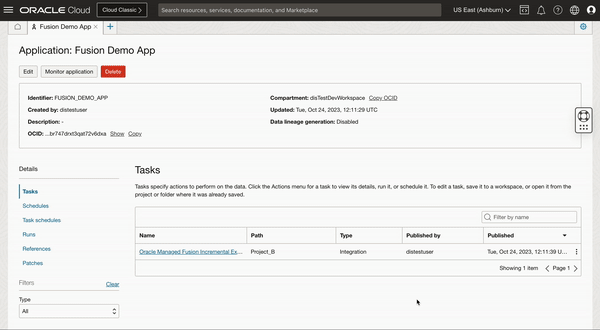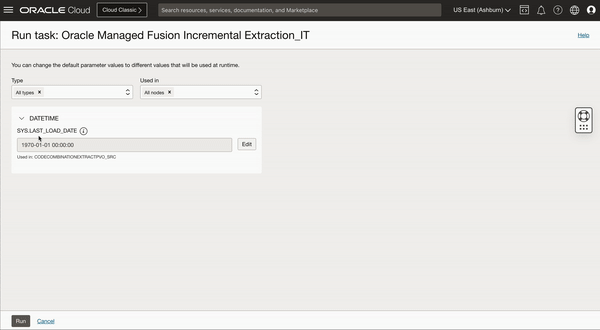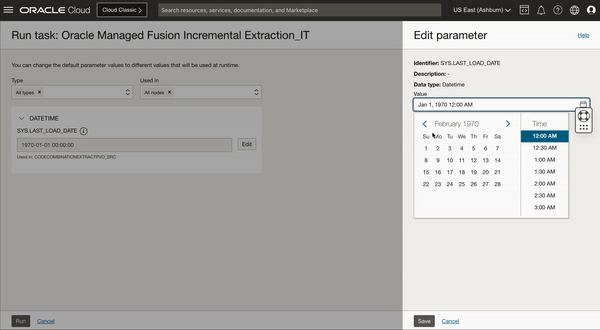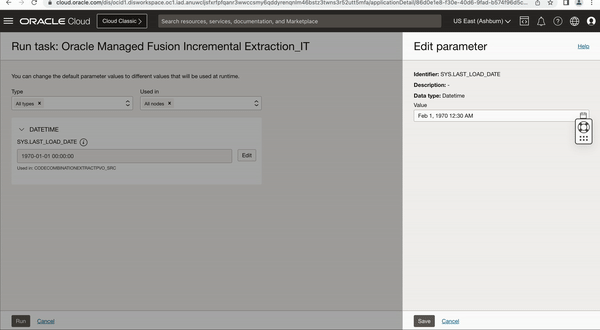
Figure 3: Runtime configuration to set the last load date
For every task OCI DI stores the last extract state in the application, it store the last successful task run start timestamp as LAST_LOAD_DATE and this LAST_LOAD_DATE is updated in the state after every successful task run.
Our first Fusion extraction job started at Tue, Oct 24, 2023, 12:35:11 UTC and extracted data into ADW.
Second incremental extraction job is using 2023-10-24 12:35:11 which is the start timestamp of first job as LAST_LOAD_DATE and performing the next incremental extraction.
In case, if an extraction fails, it won’t update the LAST_LOAD_DATE state so next extraction will use last successful extraction start time as LAST_LOAD_DATE and performs the incremental extraction.
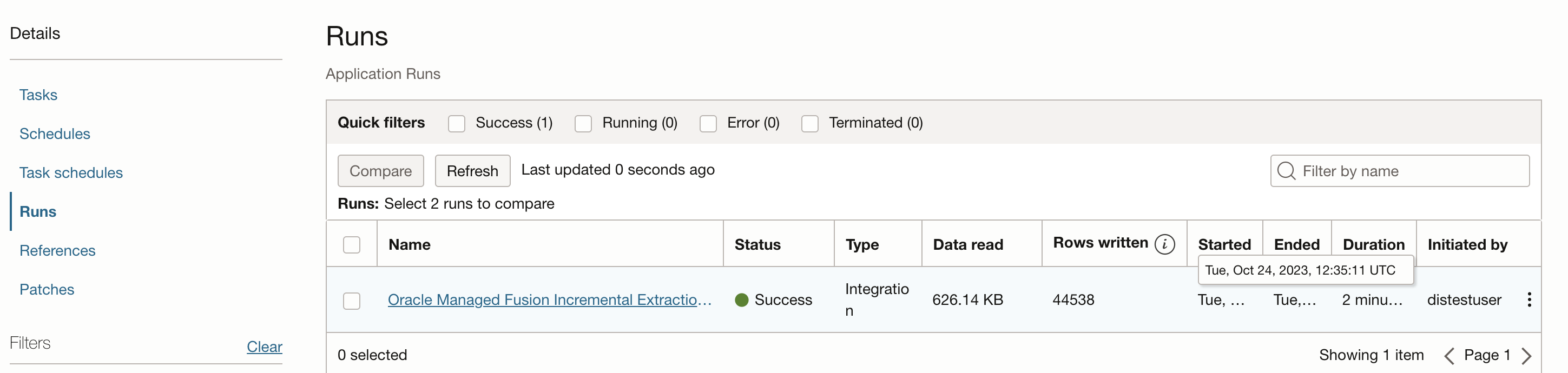
Figure 4: First Fusion extraction job started at Tue, Oct 24, 2023, 12:35:11 UTC
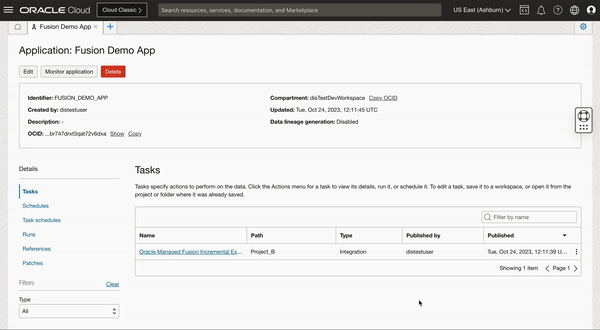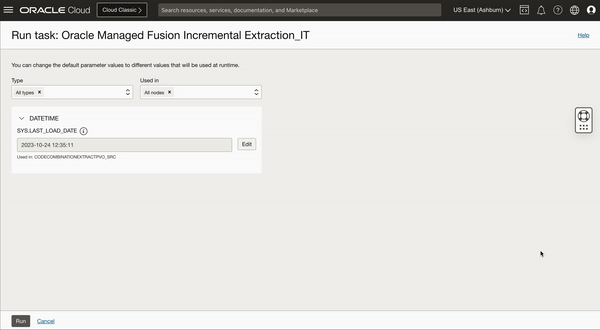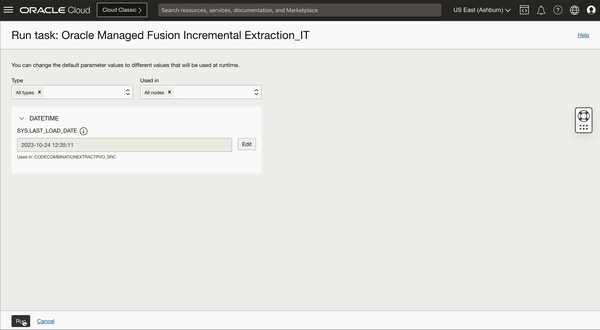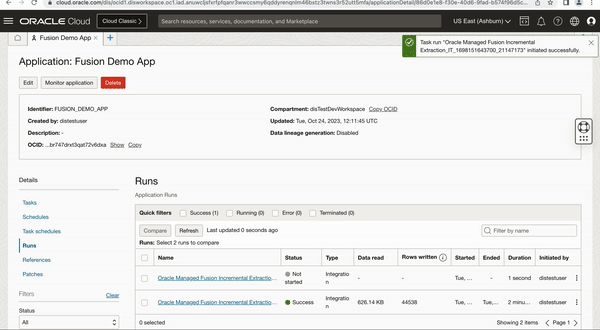
Figure 5: Last load date is changed to First Fusion extraction job start time
Note: Since target table is created in ADB, we will modify the target table and define primary/unique constraints. Select Integration Strategy as Merge (merge loads only new and update existing records) in the Target operator and republish the task.
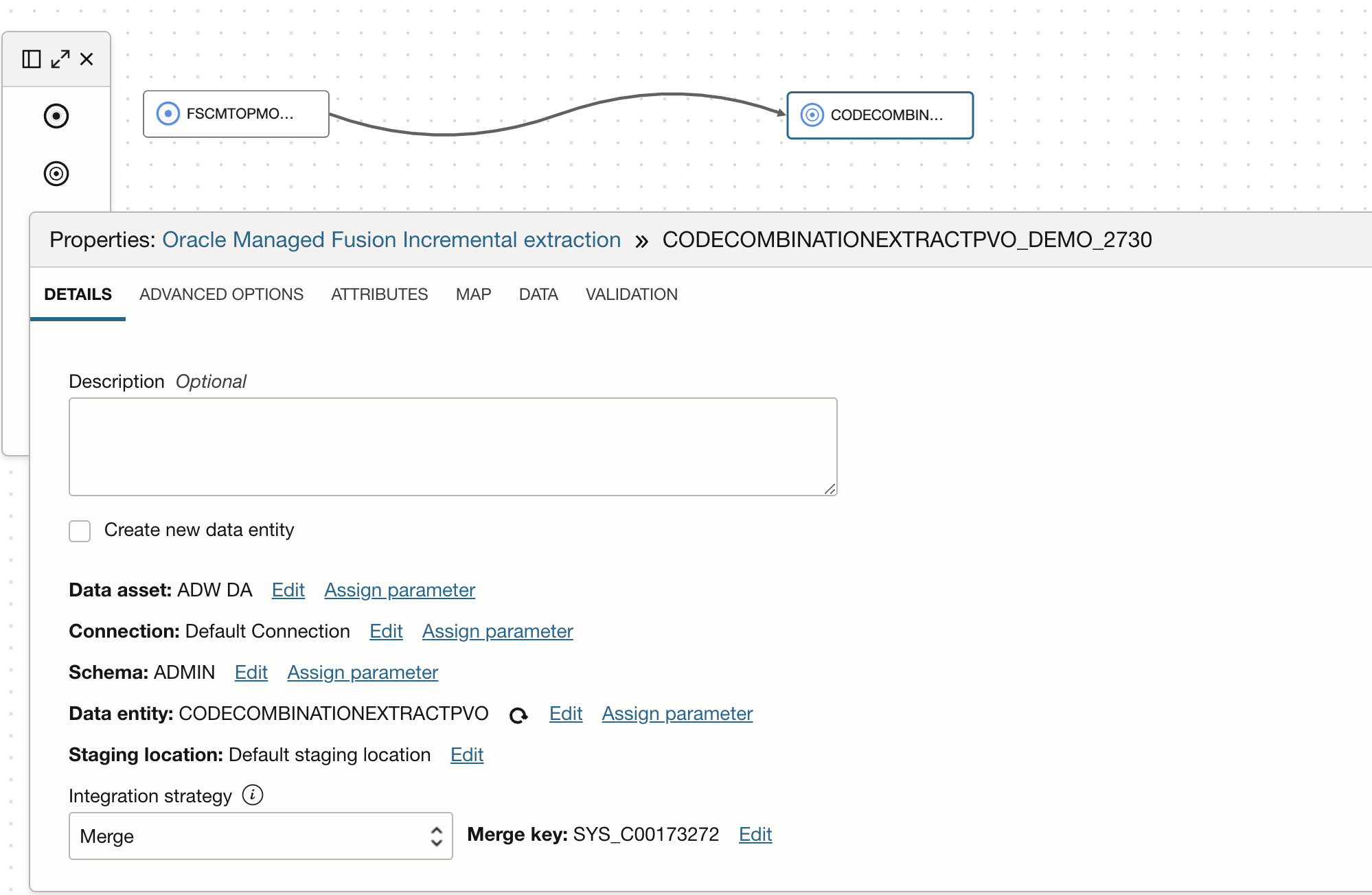
Figure 6: Target operator with Merge Integration Strategy
Create a parameterized dataflow
You can also parameterize the dataflow and re-use this single dataflow to perform incremental extraction for multiple PVOs.
Configure the Source operator with Fusion data asset and connection, parameterize Schema and Entity with Extract Strategy as Incremental Oracle managed.
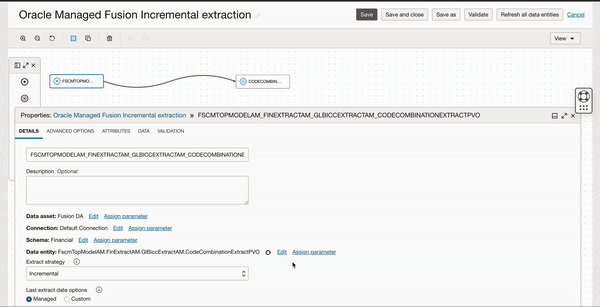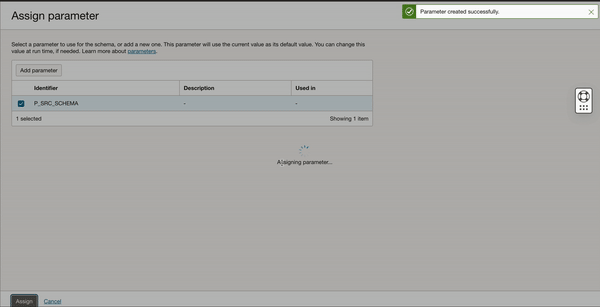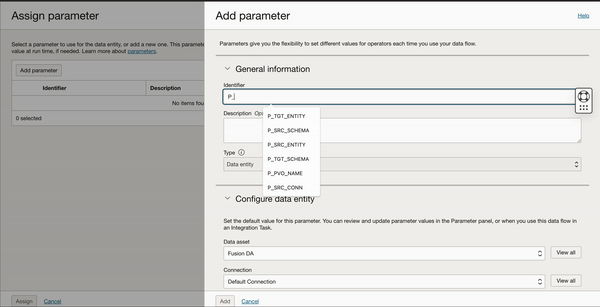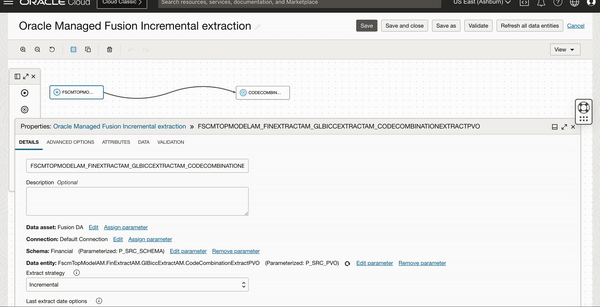
Figure 7: Source schema and entity parameterization
Configure the target operator with ADB data asset and connection, parameterize Schema and Entity.

Figure 8: Target schema and entity parameterization
Save the dataflow, create an Integration Task and publish to an application.
Create a Task Schedule to perform incremental extraction for multiple PVOs
You can create a task schedule and configure parameters with combinations of schema and entity to load multiple PVO incrementally.
We are creating a task schedule and configuring parameters to incrementally extract JournalCategoryExtractPVO VO (since JournalCategoryExtractPVO belongs to financial offspring and target table is created under same schema so schemas are not changed)
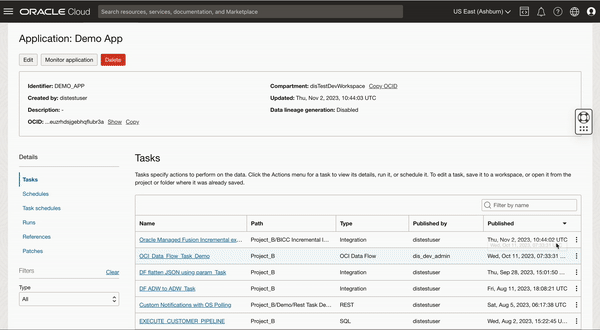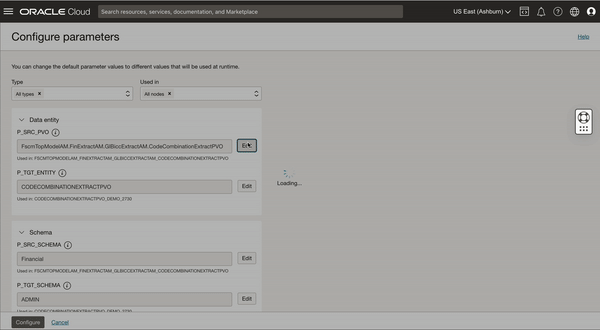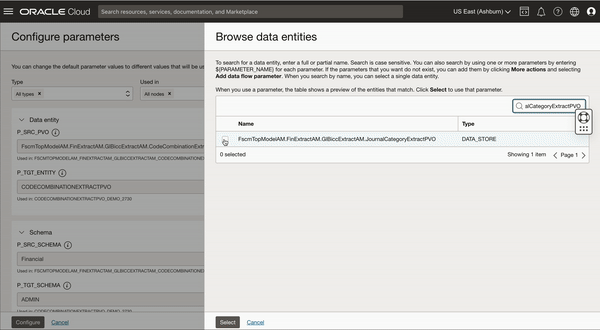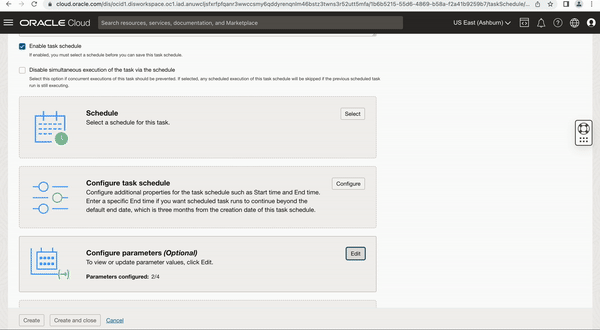
Figure 9: Task schedule creation to schedule another VO for extraction
Conclusion:
Here we have seen a solution that makes Fusion incremental data extraction easy, users can create a dataflow and select managed extraction, OCI Data Integration manages last load date within a data integration Task, controls the execution and update the last load date variable for the user internally, while still providing user the capability to override the internal dates if needed. This can then be scheduled and executed on a regular basis.
OCI Data Integration’s Managed Incremental Extract from Oracle Fusion simplifies the process of extracting data on a schedule into your data lake. By automating data extraction, offering processing, enhancing data consistency, optimizing performance, ensuring security and compliance, and promoting cost-efficiency, this solution is an invaluable asset for any organization relying on data from Oracle Fusion. Take advantage of OCI Data Integration to streamline your data integration processes and stay ahead in the competitive data-driven landscape.
We hope that this blog helps as you learn more about Oracle Cloud Infrastructure Data Integration. For more information, check out the tutorials and documentation. Remember to check out all the blogs on OCI Data Integration!
