Enterprises maximize their data integration efforts by building common tasks and patterns that can be reused across the organization. This post illustrates different approaches in OCI Data Integration for building your data integration applications in a good way. There’s a few concepts within OCI Data Integration that help with reusing logic and tasks. Here we will look at three; parameters, rules and applications. Parameters are familiar to us from all programming languages. Rules are a little different but are useful for generically shaping data or generically performing transformations on attributes. Applications are like templates that can be reused when constructed well across the organization and across the community.
Parameters
Parameters are really useful in OCI Data Integration dataflows and pipelines (all tasks support parameters — SQL Task, REST task, OCI Dataflow etc) – they are all about about reusing logic. Working smart and not doing the same thing over and over. Let’s see the different parameter types that can be defined and some use cases to illustrate the capabilities. What can be parameterized?
- Data Entity
- Data entity name or pattern
- Schema/bucket
- Connection
- Data Asset
- Filter / Join conditions
- Scalar parameters
Here’s some use cases for each of these;
- Data Entity — the source and target operators in dataflows can have the data entity parameterized. You can design using a CSV, run passing a CSV or a compressed CSV or many compressed CSVs (patterns of objects)! For tables you may want to modify the table name or even have the SQL Query representing the entity passed into the execution; you can have a data entity that is a reference to an existing table/object/query or a new table/object. A use case for this could be for example a generic dataflow which has a source table say in an Oracle database and a target Parquet object say in Object Storage, each of these can be parameterized and then the task used to export a table specified at runtime along with the folder/object name where the data is written. We can then take this even further and parameterize the data asset and connection representing the database and export from an ADW or ATP or any of the other data asset types!
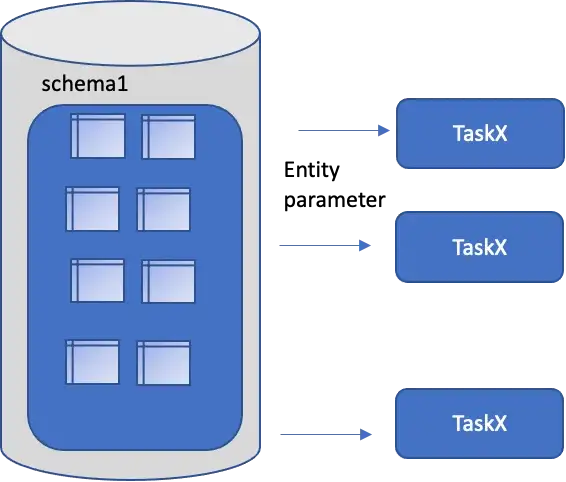
- Data Entity name or pattern can be parameterized as a string. Rather than parameterizing the entire entity the name can be parameterized.
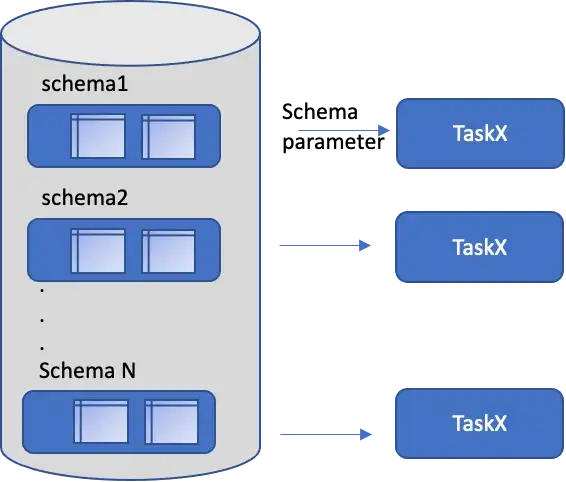
- Schema/Bucket — the source and target operators in dataflows can have the schema parameterized. Many applications will have a cookie cutter approach with a tenant/customer in each schema or same logic for different buckets, the schema content/entities are the same, just switching the schema allows reuse of DataFlow for many uses. The schema can be a database schema or a bucket even.
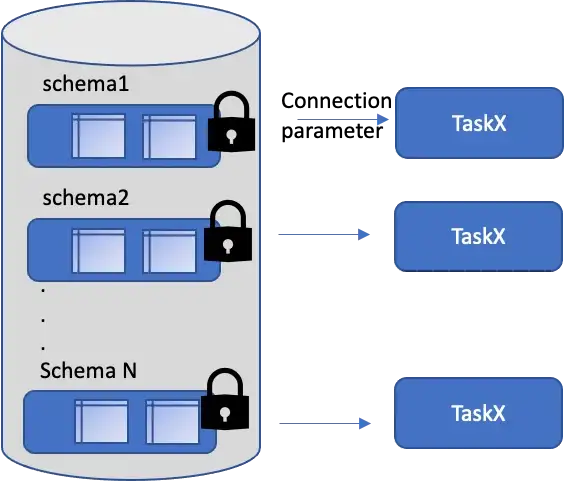
- Connection — sometimes the connection mechanism has to be switched at runtime for different uses for different authentication/authorization. The source and target operators in dataflows can have the connection parameterized.
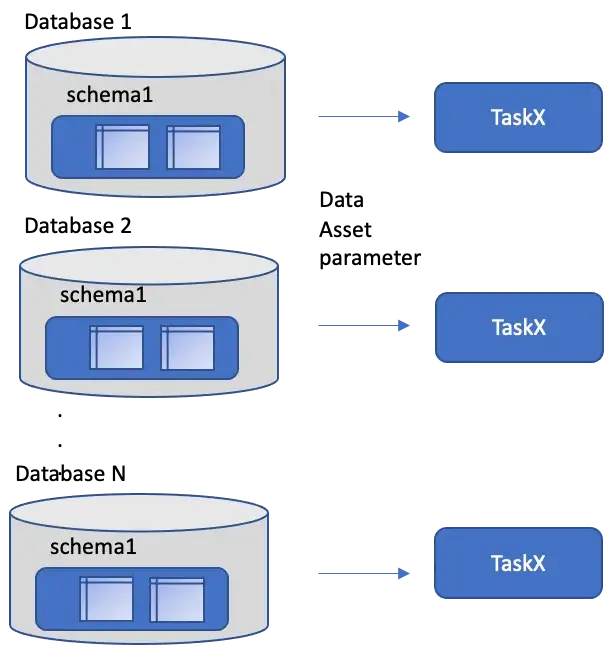
- Data Asset — many customers will have cookie cutter applications with tenants/customers in different databases for example. If you parameterize the data asset you would have to parameterize the connection also. The source and target operators in dataflows can have the data asset parameterized.
- Filter/Join conditions as parameters allow controlling what data is to be processed. The entire filter or join can be parameterized. If you have a generic flow that extracts changes but the column to identify changes is different across source tables / objects then you can parameterize the entire condition.
- Scalar valued (eg text) parameters — this allows allow controlling how expressions are defined at runtime. This can be configured in many operators within dataflow such as within the source operator itself as a SQL query, within other operators such as filter, join, lookup, pivot, split or expression/aggregate expressions. For example you could parameterize part of a filter condition to get orders created after a value. The value can be passed as a parameter (FILTER_1.ORDER_TXNS.ORDER_DATE > $LAST_LOAD_DATE) or you could parameterize an entire source operator using custom SQL and SOURCE_QUERY parameter could be defined as SELECT * from WATERMARKDATA where LAST_UPDATED > CURRENT_DATE-1 it can then be referenced as ${SOURCE_QUERY}. You can also parameterize part of the custom SQL query — such as SELECT * from WATERMARKDATA where LAST_UPDATED > ‘${LAST_LOAD_DATE}’. These are incremental extract use cases from a source where we could parameterize either the whole query or by passing the date of the last extract into a dataflow and the parameter will be used in a filter condition.
There is an existing blog that describes more details here.
Rules
Rules are really useful in OCI Data Integration dataflows — they are all about about building generic logic for shaping and transforming data. Many times in designs whether its in a programming language like SQL, Python, Java etc we build hard-wired solutions that are rigid to change.
It’s easy to shape the data and exclude/rename attributes based on patterns, so you can easily shape the data if you are creating new data sets to be consumed.
The example here illustrates filtering attributes that start with C*, then performing an action to exclude these attributes. Today there may be only 3 attributes when I designed this, but in 6 months times this rule when executing would exclude any new attributes that are added when this dataflow processes the data.
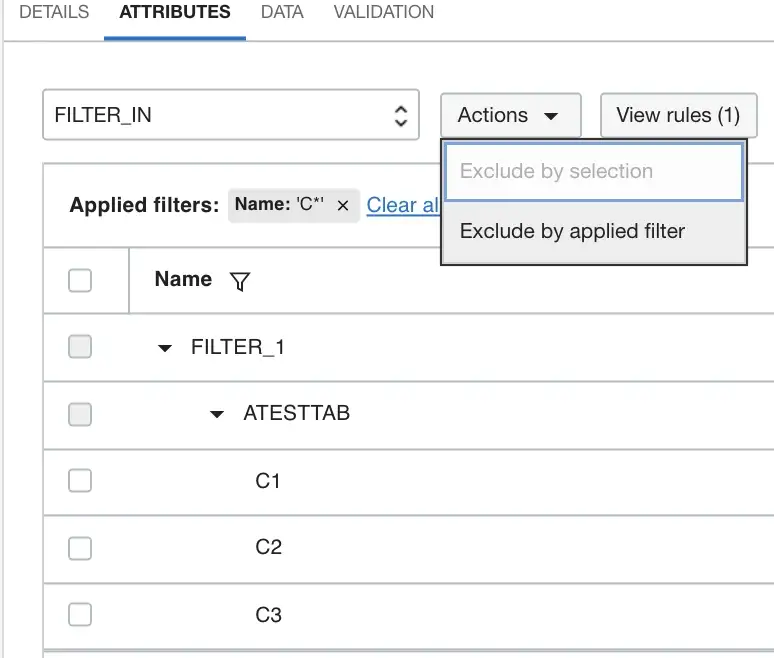
For transforming in a generic manner, you can do something similar; defined the attributes to be transformed using a pattern and/or datatype and then define an expression using a special syntax to transform all attributes that match that pattern and/or datatype.
In the example below, we uppercase all attributes that match C*, the expression uses the special %MACRO_INPUT% tag in order to reference the attributes that match. This saves us doing this expression transformation 3 times in this dataflow AND it will also work in the future if more attributes match that criteria!
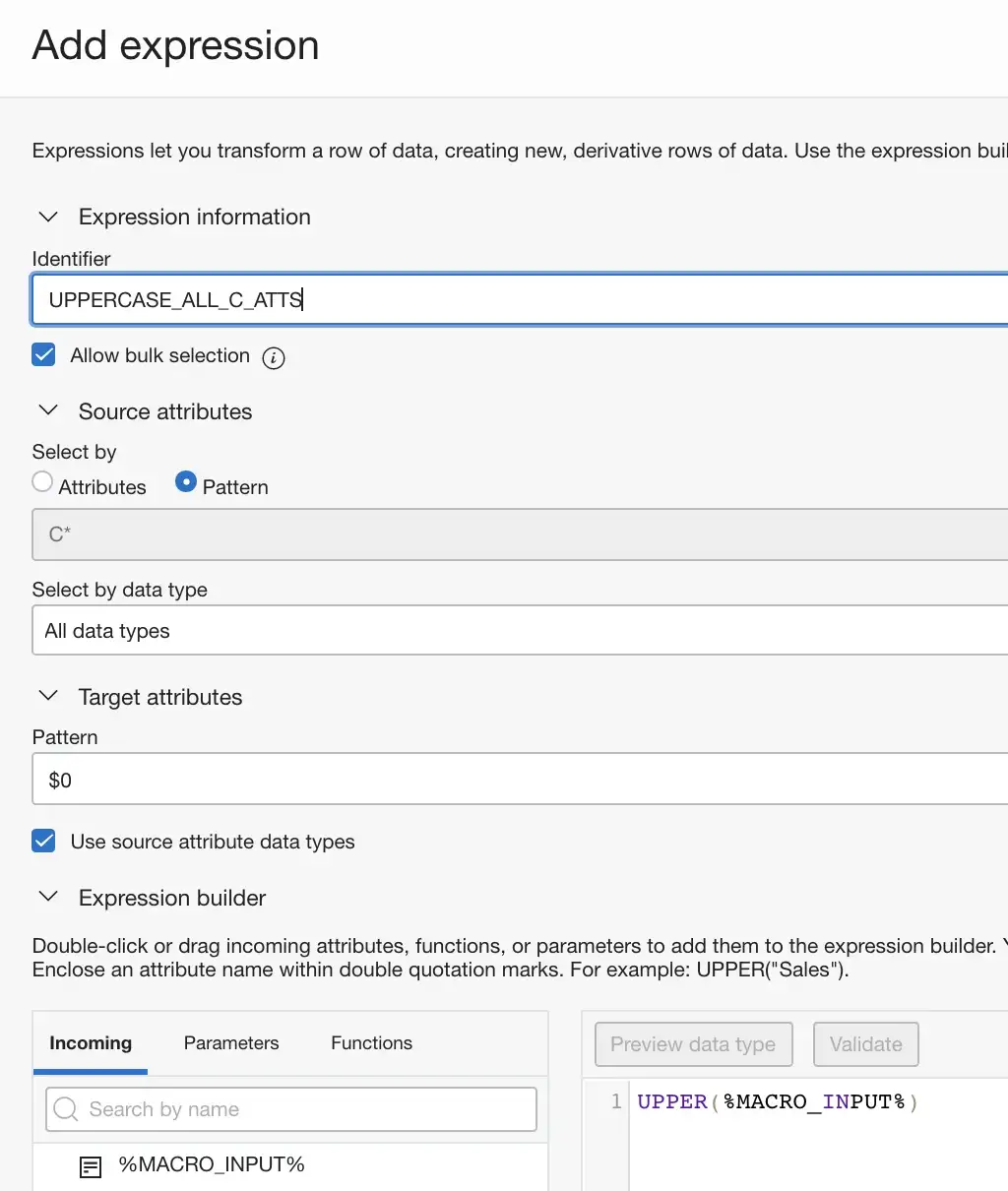
This capability is really useful to build resilient dataflows where common logic is defined once and it also minimizes the housekeeping that you have to do when there are changes…if next month more attributes are added following the pattern the dataflow does its job and transforms, renames or excludes those new attributes! See this post on Transforming Attributes the productive way.
Applications
Applications are really useful in OCI Data Integration for defining templates of work that can be reused and shared across the enterprise and the community — applications can be copied and synced across tenancies, so its possible to copy this task container into your environment and reuse existing parameterized tasks. To take an example, a colleague of mine built an application which provided an OCI Data Safe solution, I had been looking to build a solution in this area and rather than me doing all of this from the ground up I reached out to him and asked if he would share the tasks. With some policy handshake between his tenancy and mine I was able to copy his application with all of the prebuilt tasks and start working in my environment. The application consisted of pipeline tasks and REST tasks in this specific example – the original blog post describing the solution is here and had a number of pipelines and REST tasks defined such as this pipeline.
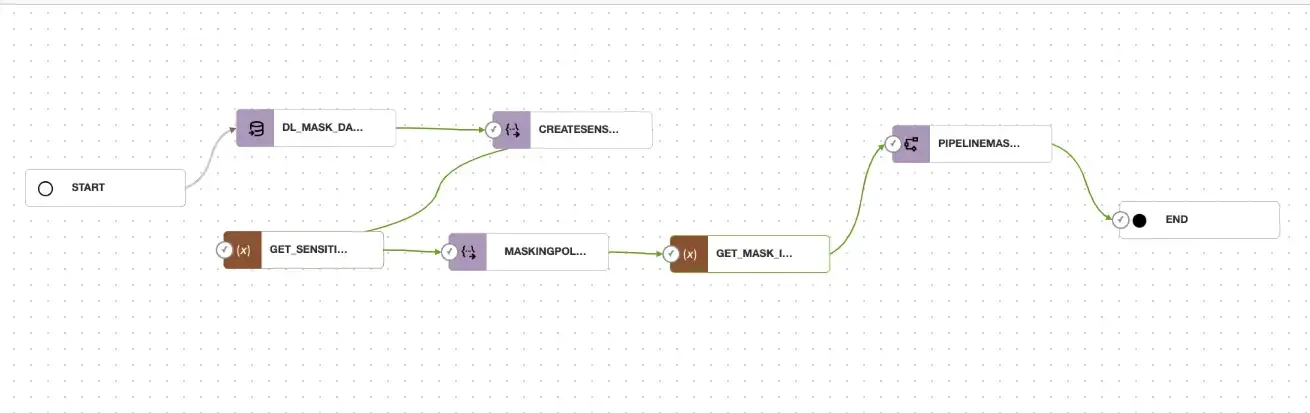
With OCI Data Integration I could leverage this prebuilt pipeline a copy into my workspace application below;
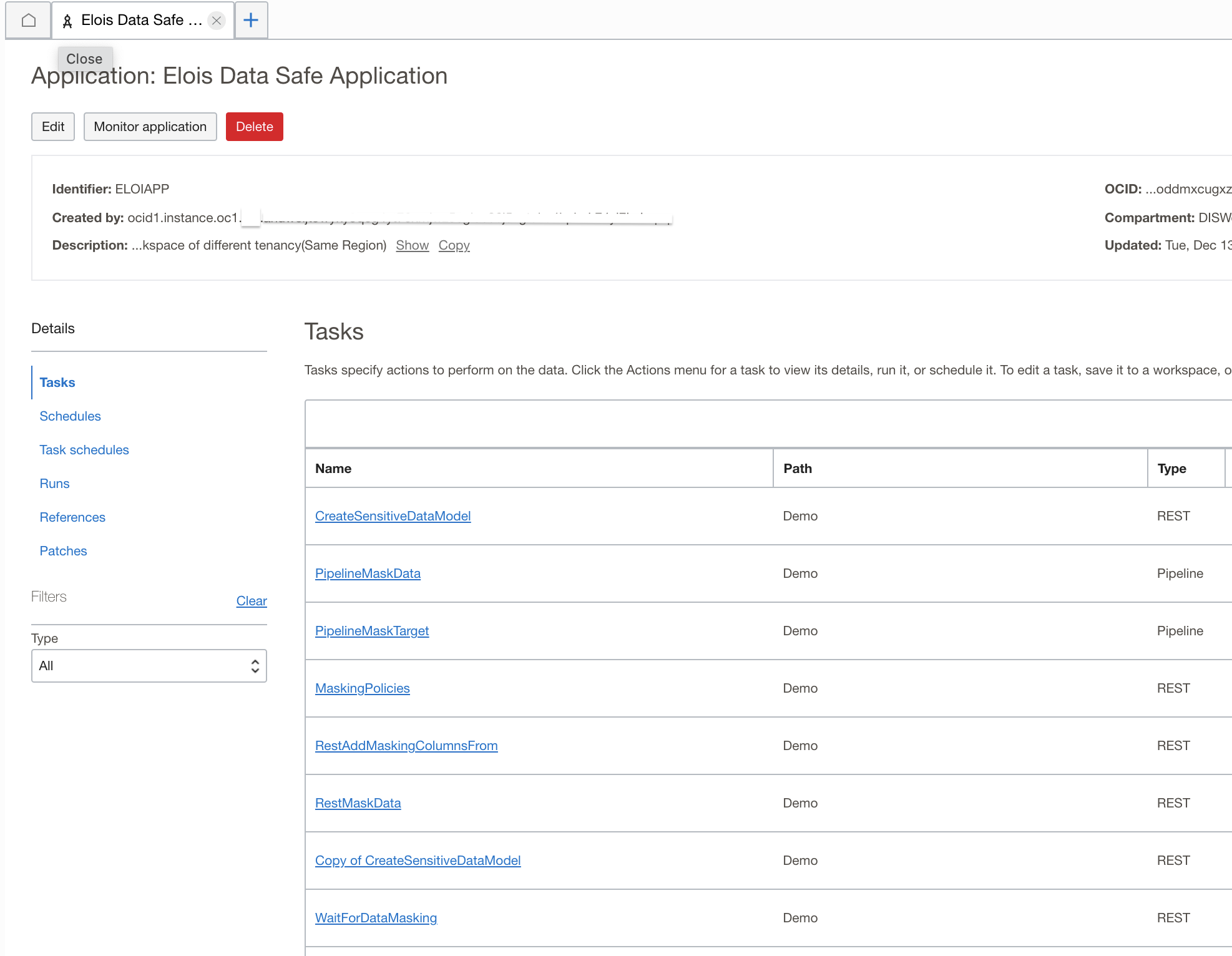
This process is described in the blog post here on Automating SDLC with OCI Data Integration. This was easy to reuse another colleague’s work to then let me focus on other tasks and using these solution templates that had already been built. Well constructed tasks that use parameterization can satisfy many different use cases and allow you to work effectively.
Wrapping it up
Here we have seen how enterprises can maximize their data integration efforts by building common tasks and patterns that can be reused across the organization. This post illustrated different approaches in OCI Data Integration for building your data integration applications in a good way from parameters, to rules to reuse of tasks using Applications. I hope you found it useful.
Have you seen some of our other blogs? Check out all the blogs related to Oracle Cloud Infrastructure Data Integration. To learn more, check out some Oracle Cloud Infrastructure Data Integration Tutorials and Documentation. For all other OCI services go to the Oracle Cloud home and try it for free!
