Oracle recommends using Parallel Replicat (PR) on databases with high volume throughput. The source database might be a system with hundreds or even thousands of sessions managing many transactions concurrently. There is only one single Replicat program applies the changes to the target database. The Apply parallelism of PR is the key to solving the problem of how to keep up with this workload: Parallel Replicat applies transactions successfully in real-time while remaining the transaction integrity.
Giving an example:
If one transaction deletes content, say from an old backup or history table, while an online order application runs transactions on entirely independent tables, PR identifies that there are no relations between the tables of those transactions, and the PR can apply those sets of transactions concurrently. The delete transaction on the target system could even finish faster at the target database than the online order, even when it started later at the source database.
The other case is about transactions that are dependent on each other. Say, you are making changes to one and the same table record OE.ORDERS: The first transaction makes an INSERT operation, while the next set of transactions performs UPDATE operations on the same record. In this case, PR identifies the dependencies, and the Appliers are scheduled the way that they must wait on each other. Even foreign key relations between tables such as OE.ORDERS and OE.ORDER_ITEMS are identified by Parallel Replicat.
Dependency calculation is based on the columns of primary key, unique indexes, and foreign keys on the target database. For this reason, it is important to add supplemental logging to those scheduling columns at the source database for a simple Replication environment (source and target system are identical). This is one of the reasons why you ADD TRANDATA/SCHEMATRANDATA beforehand. Based on the before images of the change, Replicat calculates the dependencies and schedules them accordingly.
By default Parallel Replicat uses 4 Appliers to apply transactions in parallel. If necessary and enough CPU resources are available, you can increase the parallelism to gain a higher Replication throughput. This scales if there are no transaction dependencies.
If the number of dependent transactions at the source database is high, the Replication throughput may decrease as the transaction integrity must be remained so that source and target database are globally consistent.
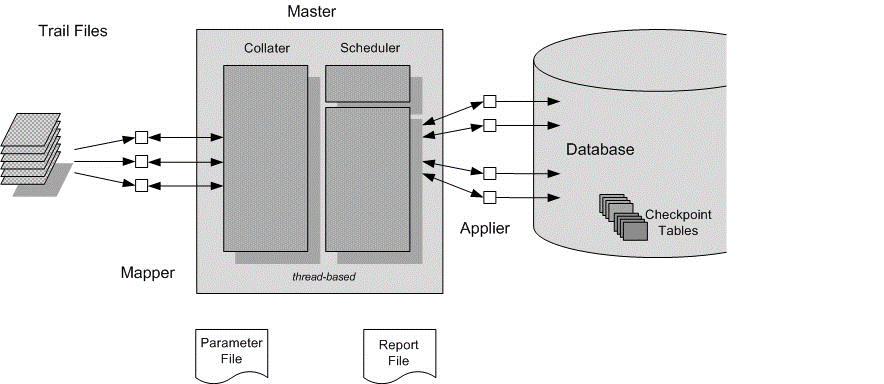
Architecture of Parallel Replicat (integrated and non-integrated):
- Multiple mappers read changes from the Trail file and pass them to the main process.
- The main process merges the changes and schedules the transaction for the Appliers.
- Each applier is managing a full transaction. (*)
In general, it is sufficient to manage the parallelism of the Appliers only.
Let’s run an experiment:
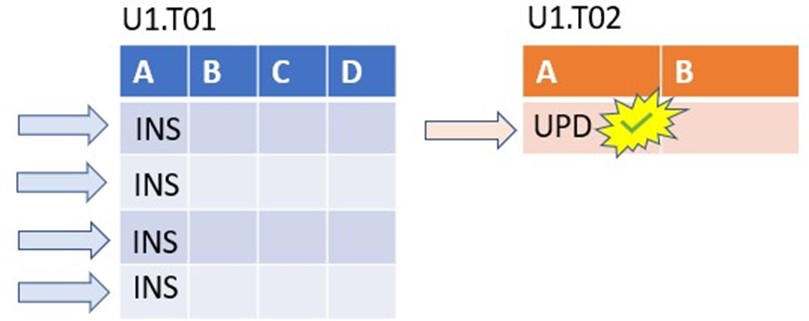
The 1st case shows an example of an independent transactions: INSERT operations are running on entirely unrelated records.
In contrast, the 2nd case shows an example of dependent transaction pattern: In each transaction, there is also a single UPDATE operation on one and the same record.
Replicat detects the dependency on the table U1.T02, and the 2nd Applier must wait until the 1st Applier finishes the 1st transaction: This counts as a dependency WAIT.
| independent Workload |
dependent Workload |
|
|
|
 |
 |
|
|
begin |
In my example, I am using AdinClient. You can also get the information from the WEB-UI or use the REST Calls to retrieve the data from the GoldenGate instance. Note that some of the following content is visible within the report file.
With the status command, you get the information about the current active Appliers. Those appliers are concurrently performing DML operation into the database.
adminclient> SEND REPLICAT REPN, STATUS
| Independent Workload |
Dependent Workload |
| Map Parallelism: 2 |
Map Parallelism: 2 |
The stats command shows for Parallel Replicat also information about the dependencies between tables. If the parent and child table are the same, the dependency is most often based on the primary key or unique index, otherwise, there is a Foreign Key relationship between the tables.
adminclient> STATS REPLICAT REPN
| Independent Workload |
Dependent Workload |
| Workload dependency statistics:
|
Workload dependency statistics: CHILD PARENT COUNT |
You can even drill deeper and check the dependencies with a dependency graph. Note that this is only available for Parallel Replicat.
adminclient> SEND REPLICAT REPN, DEPENDENCYINFO
| Independent Workload |
Dependent Workload |
| Scheduler 0: Transaction groups currently being executed: Group 0:4249226121.2.28.874 |
Scheduler 0: Transaction groups currently being executed: Group 0:4249226121.5.23.872, 4249226121.6.12.881, 4249226121.9.23.879, 4249226121.2.7.867, Waiting transactions: |
This experiment shows you how much impact the transaction on the source database might have. Even there is only change that causes the dependency, the appliers managing those transactions must wait.
How to solve this issue? There may be two solution that needs to be analyzed carefully.
- You might want to take the dependency causing table out of the Replicat and place it in another (classic) Replicat. In this case, there are no dependencies anymore as each Replicat applies the changes independently. However, you are slicing the transactions. In case of the experimental example, this works fine. This might be different in financial business applications where a deep understanding of the transaction pattern is needed.
- If you change the transaction pattern at the source, you can avoid those dependencies. In the experimental example, you might change the UPDATE into an INSERT so that there are no primary key dependencies. However, you may not have access to the business application and are not able to make changes to the transaction pattern/business logic.
With this simple experimental case, I show how transactions are managed within PR. Depending on the workload on the source database and its transaction patterns, PR will fully utilize parallelism or not. There might be cases where you can increase parallelism to a maximum. All Appliers will run transactions independently into the database. There might also be cases where a higher parallelism does not increase in performance. I also provide the instruments (commands) to do the analysis and find out whether there are transaction dependencies.
