We’re excited to announce a new release of Oracle Cloud Infrastructure (OCI) Data Integration. This release provides new development lifecycle enhancements to improve user productivity. We continue to increase the depth of extract, transform, and load (ETL) options to help you more effectively design and monitor data flows, tasks, and overall processes through newly provided operators and transformations. We also continue to expand the integration with other services within the OCI ecosystem.
Cloud native, serverless integration
OCI Data Integration is a recently launched, cloud-native, fully managed serverless ETL solution. Organizations building data lakes for Data Science on Oracle Cloud, and departments building data lakes and data marts using autonomous databases can gain great business value by using a solution that can help simplify, automate, and accelerate the consolidation of data for use.
Data Integration is graphical, providing a no-code designer, interactive data preparation, profiling options, and schema evolution protection, all powered by Spark ETL or ELT push-down. If you’re not familiar with this new service, check out this blog to find out more: What is Oracle Cloud Infrastructure Data Integration?
OCI Data Integration is available in all OCI commercial regions.
New features
We’re helping customers be even more productive through this release.
User experience, productivity, and performance enhancements
Operators come into play in the graphical user interface as you build a custom data integration flow diagram. They help you select, filter, and shape the data.
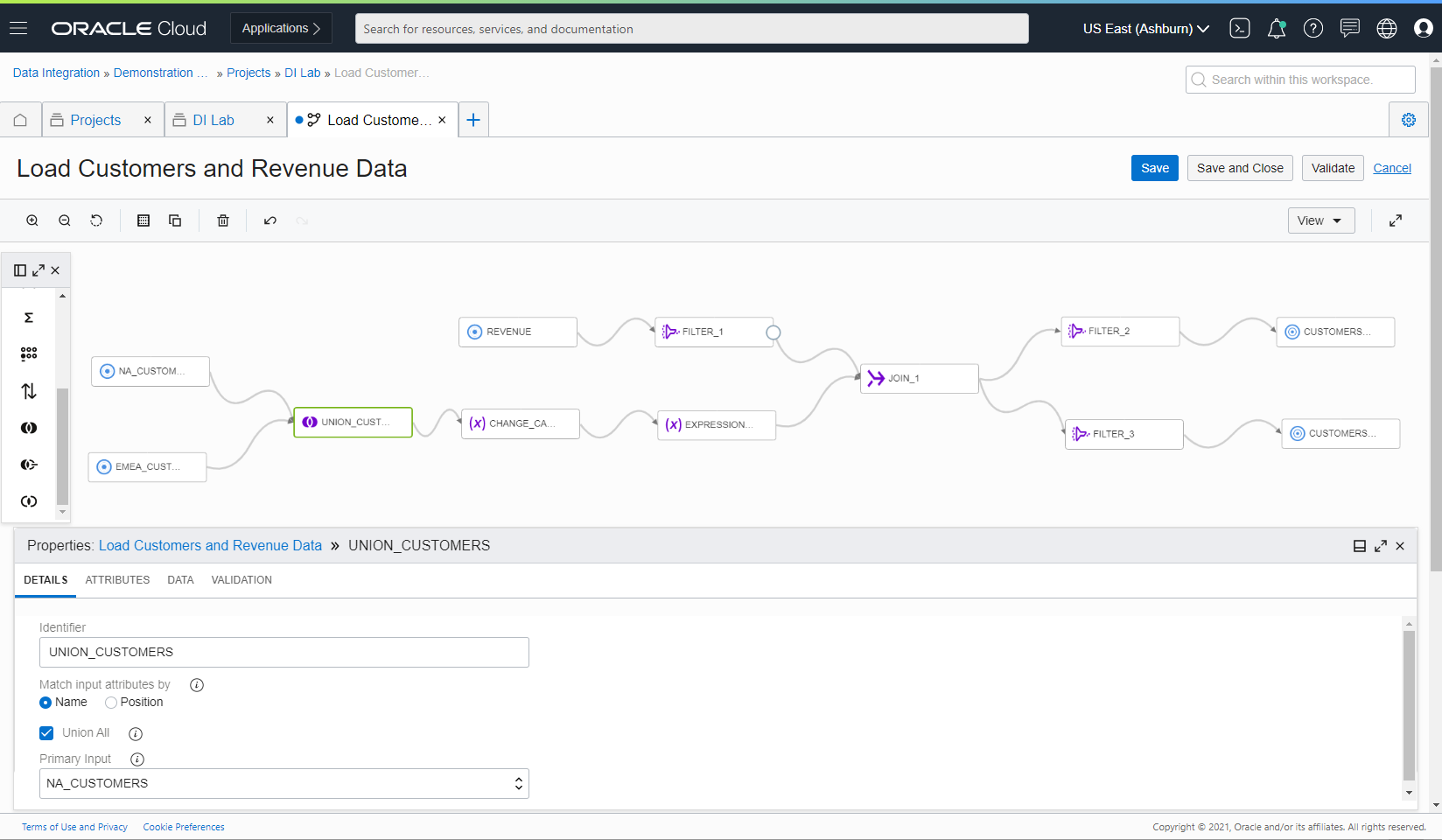
Figure 1: Data flow editor
This release includes the following new operators:
- Pivot: Allows you to take unique row values from one attribute in an input source and pivot the values into multiple attributes in the output.
- Function: Allows you to use and invoke a function deployed in Oracle Functions to process data from an input source in Data Integration.
- Lookup: Performs a query and transformation using a lookup condition and input from two sources: A primary input source and a lookup input source.
- SQL override: Allows SQL to be used directly instead of selecting a data entity. When this SQL query syntax is validated, the output of the SQL results is the attributes of the source operator.
These operators allow you to quickly and easily express complex transformations. Check out the full review of OCI Data Integration operators.
We’ve also made enhancements to the data flow editor, such as the ability to move objects like folders, tasks, data flows, and pipelines from one project or folder to another. When and how often saving and committing changes can happen have also been enhanced. We’ve also added the ability to support hierarchical data types in source and target data entities.
To assist you in getting started and exploring data, you can enable sample projects to explore different data flows. If you have artifacts such as data flows, you can enable samples and explore what’s been created for you to aid your productivity.
Also, we’ve added the option a full SQL push-down operation, where you can push all transformations defined in a data flow to databases, and the data moves directly from the source database to the target database. Data Integration supports full SQL push-down processing when the source and target databases are the same data asset, such as an Autonomous Data Warehouse instance, for improved performance.
Monitoring gets better!
Monitoring is greatly improved. You can now monitor workspaces, applications, and task runs for better visibility into data integration processes and your data. You can also compare two-task runs, see values of the parameter in task runs, filter on the status of a task run (success, failed, queued, and terminated), and see the total numbers of runs, successful runs, and failed runs in an application. Metrics for OCI Data Integration are also now available at the workspace level, such as workspace uptime and total data processed.
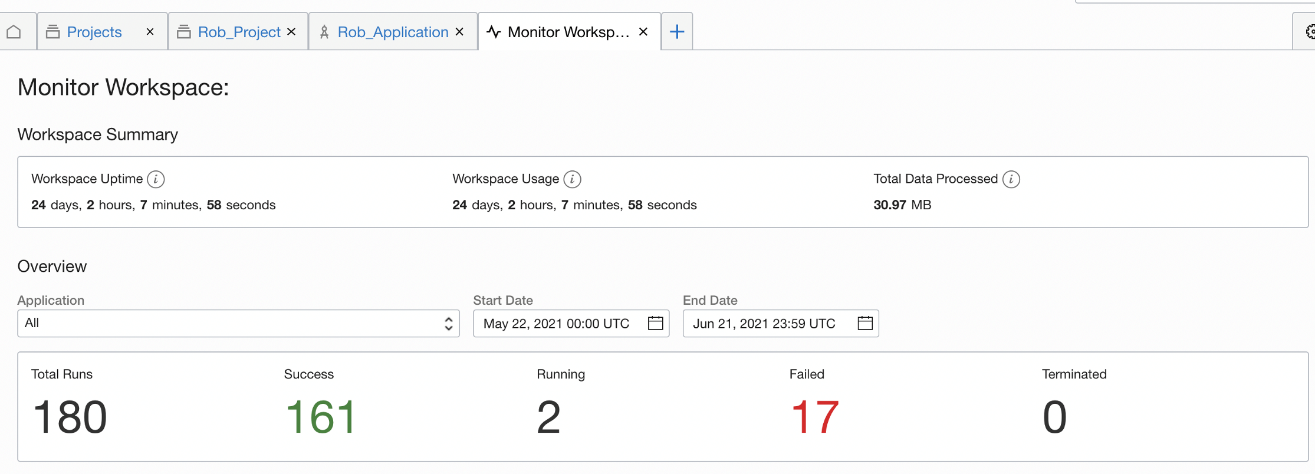
Figure 2: Monitoring of workspace
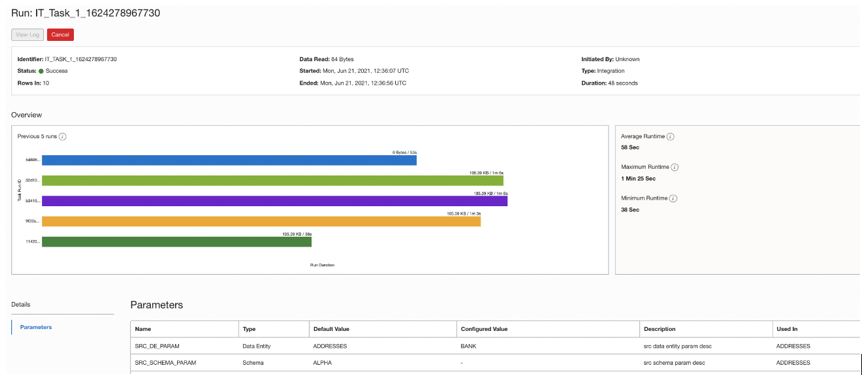
Figure 3: Monitoring of task runs
As it relates to a pipeline graph, run details showing the set of tasks and activities in the pipeline from start to finish is now available. The successful and failed paths and the run status of a task or activity are indicated on the graph. In this pipeline graph, you can zoom in or out to change the focus, view the pipeline parameters and configured values used in the current run, select a node in the pipeline to see more details, including parameters and configured values, and refresh the graph if the pipeline task run is incomplete.
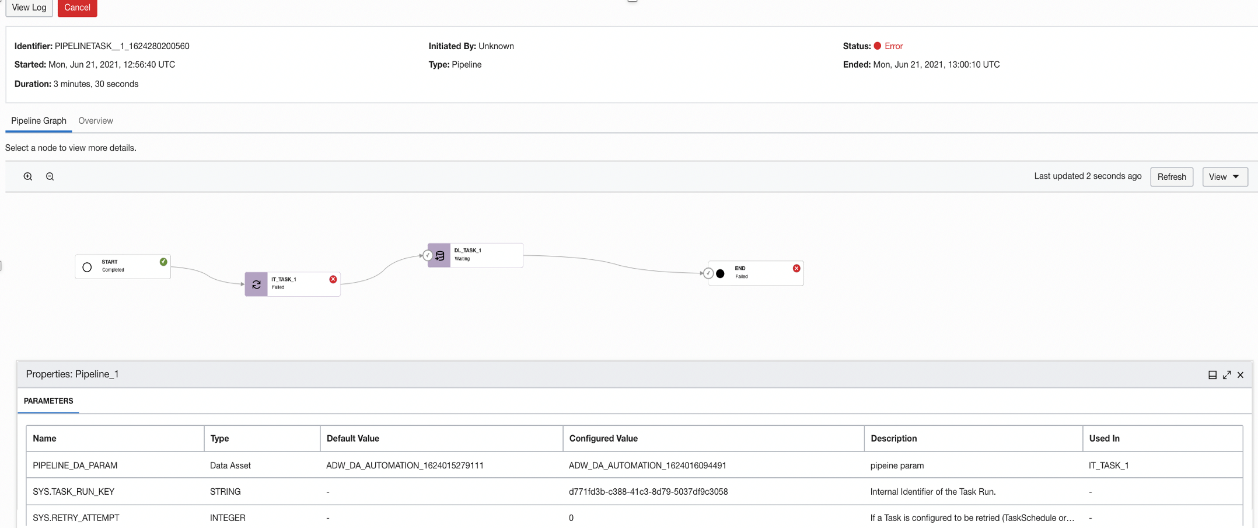
Figure 4: Pipeline graph showing run details
Integration with other ecosystem services
We also continue to expand the interoperability with and between other services within the OCI ecosystem. You can write Spark applications using Java, Python, SQL, and Scala in OCI Data Flow, and you can now create Data Flow tasks in Data Integration and schedule them the way you can schedule any other task, like Data Integration, pipeline, SQL, and data loader tasks. You can override driver shape, executor shape, and the number of executors in the Data Flow task as appropriate.
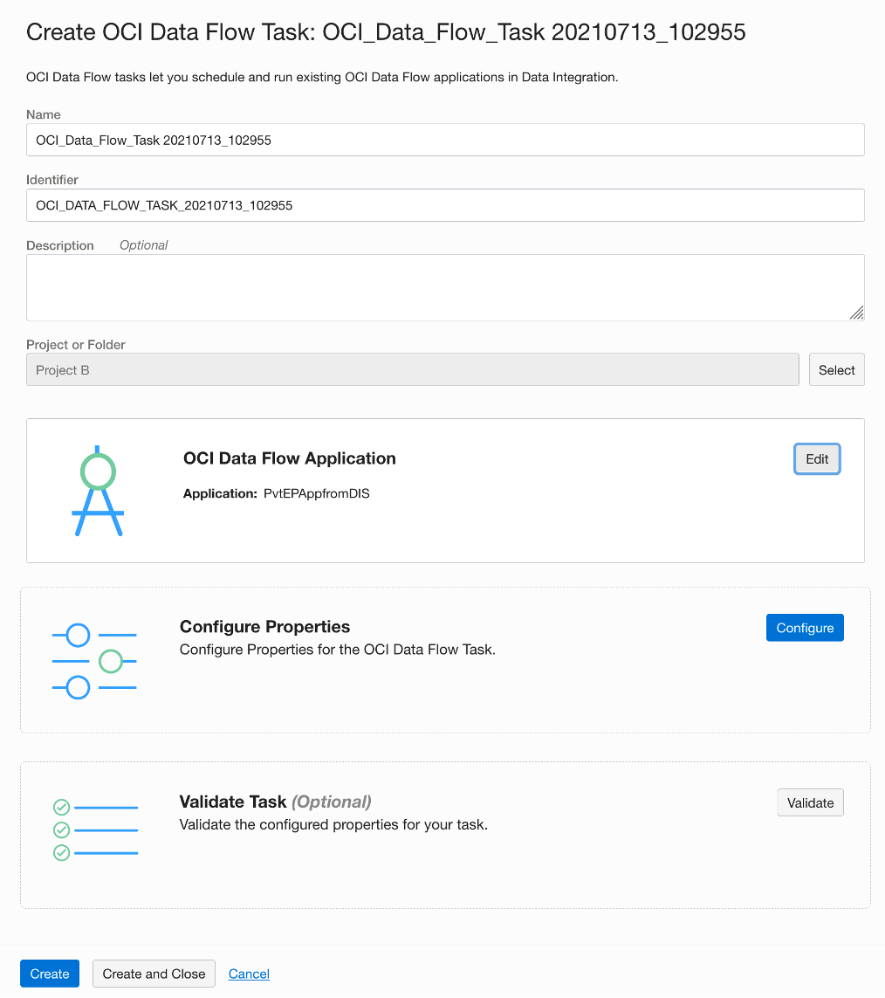
Figure 5: Data flow task
Want to know more?
Organizations are embarking on their next-generation analytics journey with data lakes, autonomous databases, and advanced analytics with artificial intelligence and machine learning in the cloud. For this journey to succeed, they need to quickly and easily ingest, prepare, transform, and load their data into Oracle Cloud Infrastructure. Data Integration’s journey is just beginning! Try it out today!
For some of the most recent highlights and more information, see the following resources:
- Load and transform data from Oracle Fusion Cloud Applications to build a data lake or data warehouse
- New Oracle Cloud Infrastructure Data Integration release adds pipelines and orchestration
- New Oracle Cloud Infrastructure Data Integration release focuses on connectivity and transformations
- Oracle Cloud Infrastructure Data Integration documentation
- Tutorials
- Oracle Cloud Infrastructure Data Integration blog
