Cassandra is an open source, distributed, NoSQL wide column store database system. Cassandra is used across different industries for various use cases.
GoldenGate for Big Data supports data capture from Cassandra 3x, 4x and Cassandra Datastax DSE. You can refer to certification matrix for compatibility. Once data is captured with GoldenGate for Big Data, it is written into a trail format which can be used to replicate the data into any GoldenGate supported target.
In this blog, we will go through the details of setting up data capture from Cassandra 4x with GoldenGate for Big Data 21.12. Please note that, GoldenGate for Big Data and Cassandra runs in the same VM.
Pre-requisites for Cassandra Capture:
- Enable CDC in source Cassandra cluster and cassandra.yaml file should be updated in all the nodes of the cluster. Virtual nodes must be enabled on every Cassandra node by setting the num_tokens parameter in cassandra.yaml. In cassandra.yaml file, set cdc_enabled=true and set a path for cdc_raw_directory (for example /var/lib/cassandra/data/cdc_raw). There might be other configurations needed depending on the Cassandra version used. You can refer to Cassandra Documentation for more details. Also, please make sure that cdc_raw directory has read and write access.
- Enable CDC in source cassandra table if needed. You can refer to Cassandra Documentation for more details.
- If you’re extracting from Datastax DSE, please take a copy of Datastax installation into GoldenGate for Big Data server. GoldenGate for Big Data uses some of the libraries from Datastax installation.
- If your GoldenGate Big Data and Cassandra servers are on different nodes, please configure SFTP or NFS between nodes. GoldenGate for Big Data accesses to CDC commit log files on every live node in the cluster through SFTP or NFS. Also, you need to create a known_hosts file in GoldenGate for Big Data server so that it can access all the Cassandra nodes.
If you’re running a simple test, you can insert data into the table with an insert statement. As the data is inserted, transactions will be stored in memory tables, not in the disk, till it reaches a certain limit. They’re also written into the log files in commitlog directory in the Cassandra server’s data folder. When the limit is reached in the memory tables, transactions are flushed to actual tables and moved into cdc_raw directory. Few insert statements that we execute for the test scenarios are not enough for reaching the memory limits & flush. To trigger the flush, you can restart the Cassandra server and data will be moved into cdc_raw. GoldenGate for Big Data reads the change data from the log files located in cdc_raw directory and if there are no files there, it will not capture the data.
Downloading dependencies:
Our reccomendation is to use GoldenGate for Big Data 21.8 or later for Cassandra capture. With the enhancements introduced in 21.8, extract configuration is more simple. For Cassandra version compatibility, please refer to certification matrix.
After GoldenGate for Big Data installation is complete, you can use dependency downloader to download dependency jar files for Cassandra 4x. Dependency downloader downloads all the required dependency jar files into a single directory. You can find the dependency downloader at GG_HOME/opt/DependencyDownloader. You can use cassandra_capture_3x.sh for Cassandra 3x dependencies, cassandra_capture_4x.sh for Cassnadra 4x dependencies and cassandra_capture_dse.sh for Datastax DSE dependencies. If you’re extracting from Datastax DSE, please take a copy of Datastax installation into GoldenGate for Big Data server. GoldenGate for Big Data uses some of the libraries from Datastax installation.
Class path sample for Cassandra 3x/ 4x dependencies: ggjava/ggjava.jar:DependencyDownloader/dependencies/cassandra_capture_4x(3x)/*
Class path sample for Datastax DSE dependencies: ggjava/ggjava.jar:{/path/to/dse-6.x}/resources/cassandra/lib/*:{/path/to/dse-6.x}/lib/*:{/path/to/dse-6.x}/resources/dse/lib/*:DependencyDownloader/dependencies/cassandra_capture_dse/*
For this blog, I executed cassandra_capture_4x.sh. In GG_HOME/opt/DependencyDownloader/dependencies directory, I can see a directory created by dependency downloader. This directory holds all dependency files needed by GGBD to capture from Cassandra 4x.

Configuring GoldenGate for Big Data Cassandra Extract:
Before configuring extract, create some transactions in your source Cassandra table and restart the Cassandra; so that, it can flush the cdc log files to cdc_data_raw directory.
- In GoldenGate for Big Data Administration Service, go to Configuration/ Database and click Add Credentials. Provide Credential Domain, Credential Alias, User ID as cassandra://<user_name>@<cassandra_host> and Password. Click Submit.
If you’re configuring for a Cassandra cluster, you can configure more than one node. For example: cassandra://db-user@127.0.0.1,127.0.0.2:9042.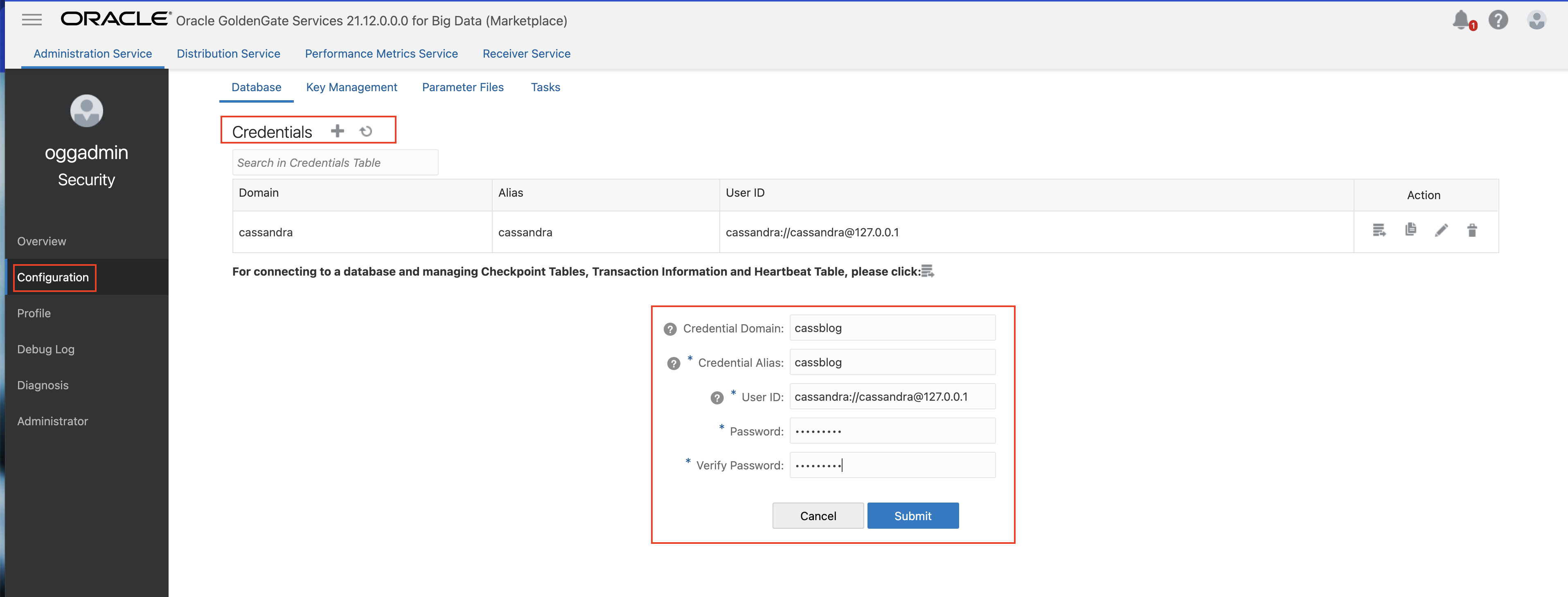
- Under Action, click Connect to Database to test the connection. If connection is succesful, you see TRANDATA Information. You can search for the source Cassandra table names.
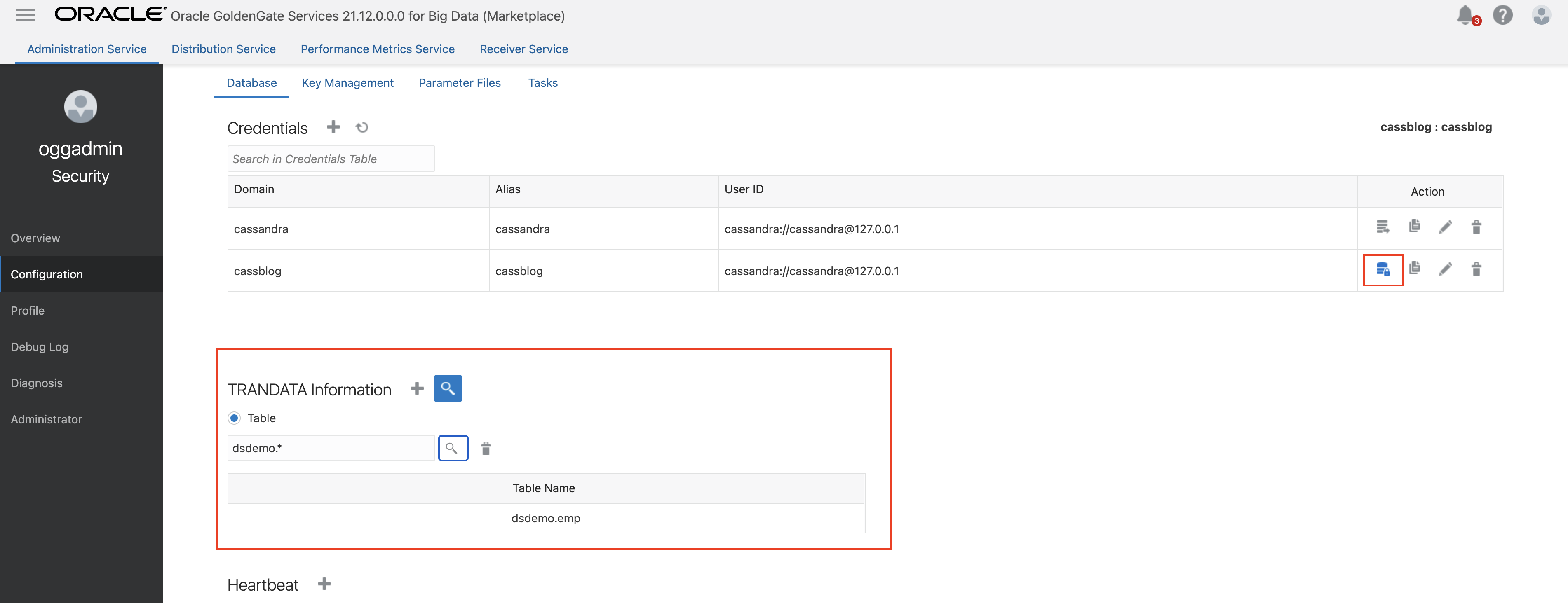
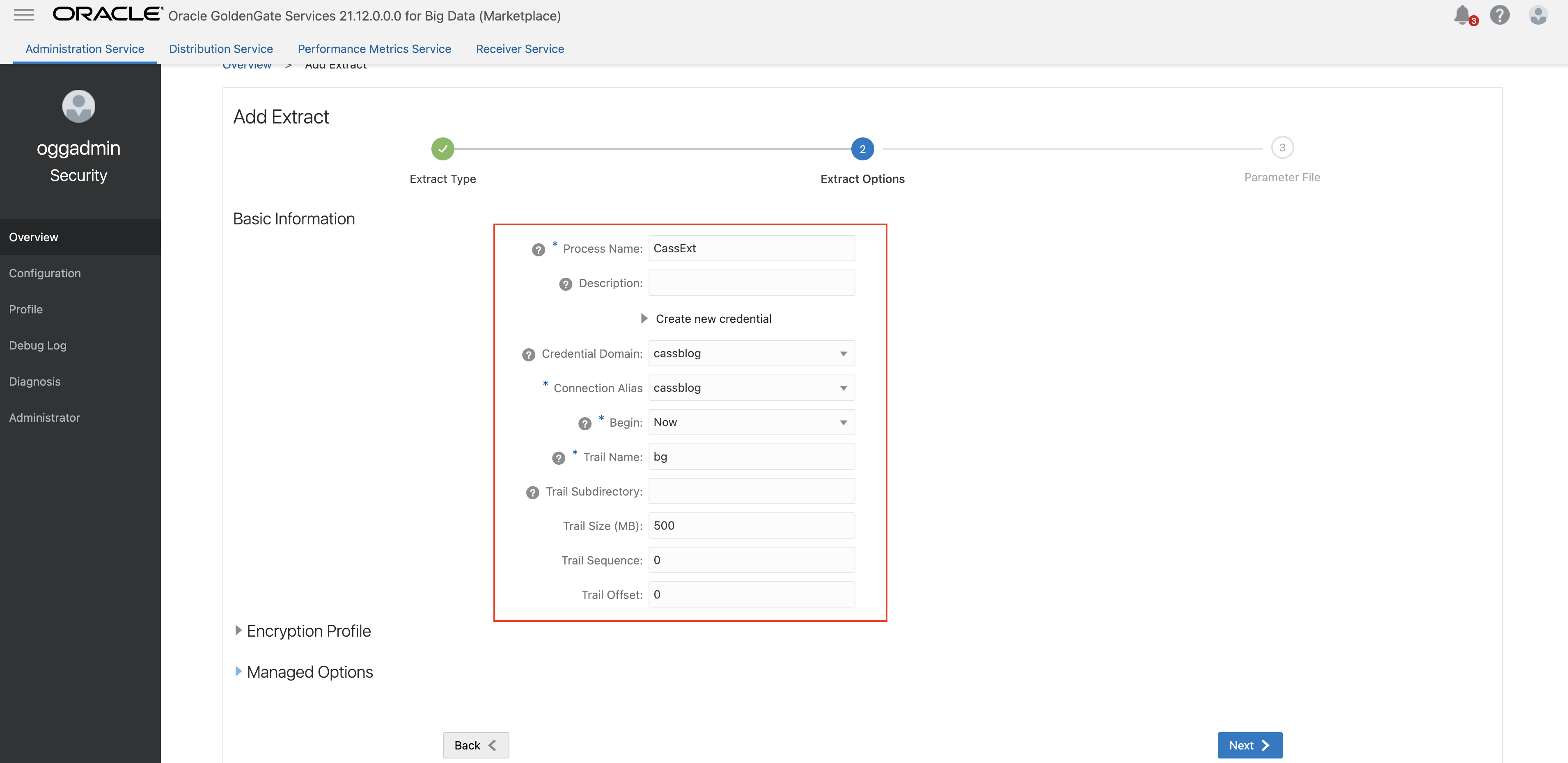
- In GoldenGate for Big Data Administration Service/ Overview, click Add Extract.
- In Extract Type, select Cassandra as Source and Change Data Capture Extract as Extract Type. Click Next.
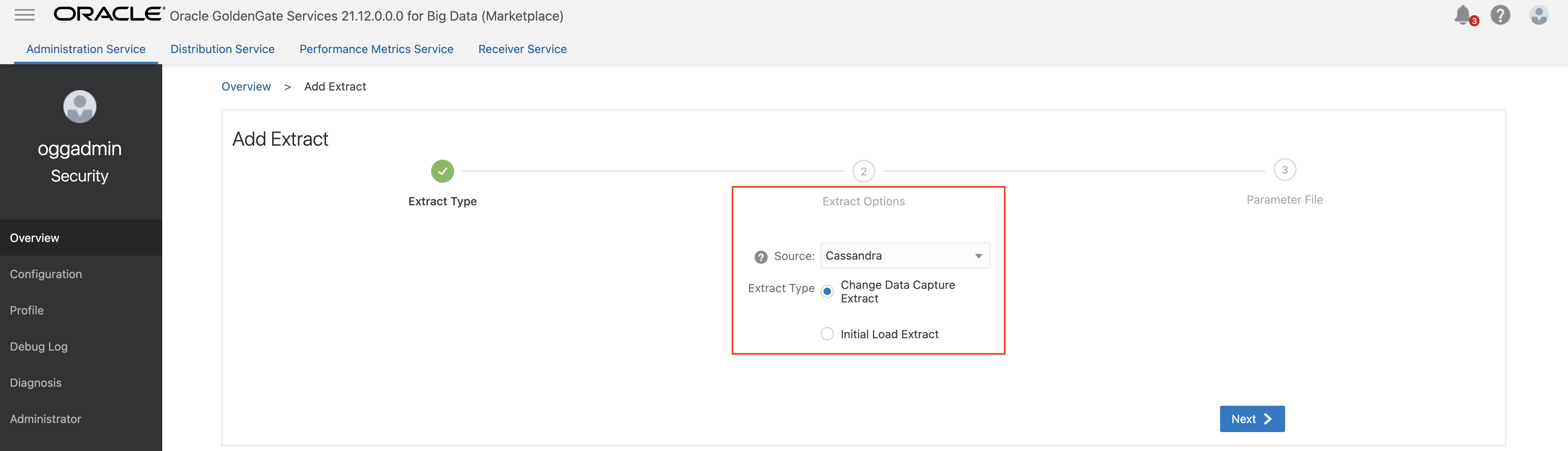
- Provide the details in Extract Options. For Credential Domain and Connection Alias, select the domain and alias created in step 1. Click Next.
- Update the Parameter File with required parameters. Review the parameters marked as TODO.
- Update JVMOPTIONS CLASSPATH and BOOTOPTIONS:
In CLASSPATH, you should include ggjava.jar and dependencies downloaded in classpath. ggjava.jar is located at $GG_HOME/ggjava/ggjava.jar. You should also provide the full path to depdencies you downloaded earlier. In BOOTOPTIONS, you need to provide path to cassandra.yaml file in Dcassandra.config.
For example: JVMOPTIONS CLASSPATH /u01/app/ogg/ggjava/ggjava.jar:/u01/app/ogg/opt/DependencyDownloader/dependencies/cassandra_capture_4x/* BOOTOPTIONS -Dcassandra.config=file:///etc/cassandra/conf/cassandra.yaml -Dcassandra.datacenter=datacenter1 - Edit SDK Version:
Provide your source Cassandra version in tranlogoptions cdcreadersdkversion as 3x, 4x or DSE.
For example: tranlogoptions cdcreadersdkversion 4x - Edit path to the CDC Commitlog Directory:
Provide the path to Cassandra CDC commitlog directory (for example cdc_raw) in tranlogoptions cdclogdirtemplate. Please make sure that Cassandra commitlog directory is read open.
For example: tranlogoptions cdclogdirtemplate /var/lib/cassandra/data/cdc_raw
!!! If GoldenGate for Big Data and Cassandra runs in different nodes, GoldenGate for Big Data uses SFTP or NFS to access to Cassandra commitlog files. If that’s the case, provide path to known_hosts file in tranlogoptions sftp knownhostsfile. For example: tranlogoptions sftp knownhostsfile /home/opc/known_hosts. If SFTP is configured with user name and password, use tranlogoptions sftp user <user> password <password> to provide username and password. - Define from which Cassandra Keyspace and Table data will be extracted.
Update TABLE source.*; with source keyspace and table name. For example: TABLE dsdemo.*;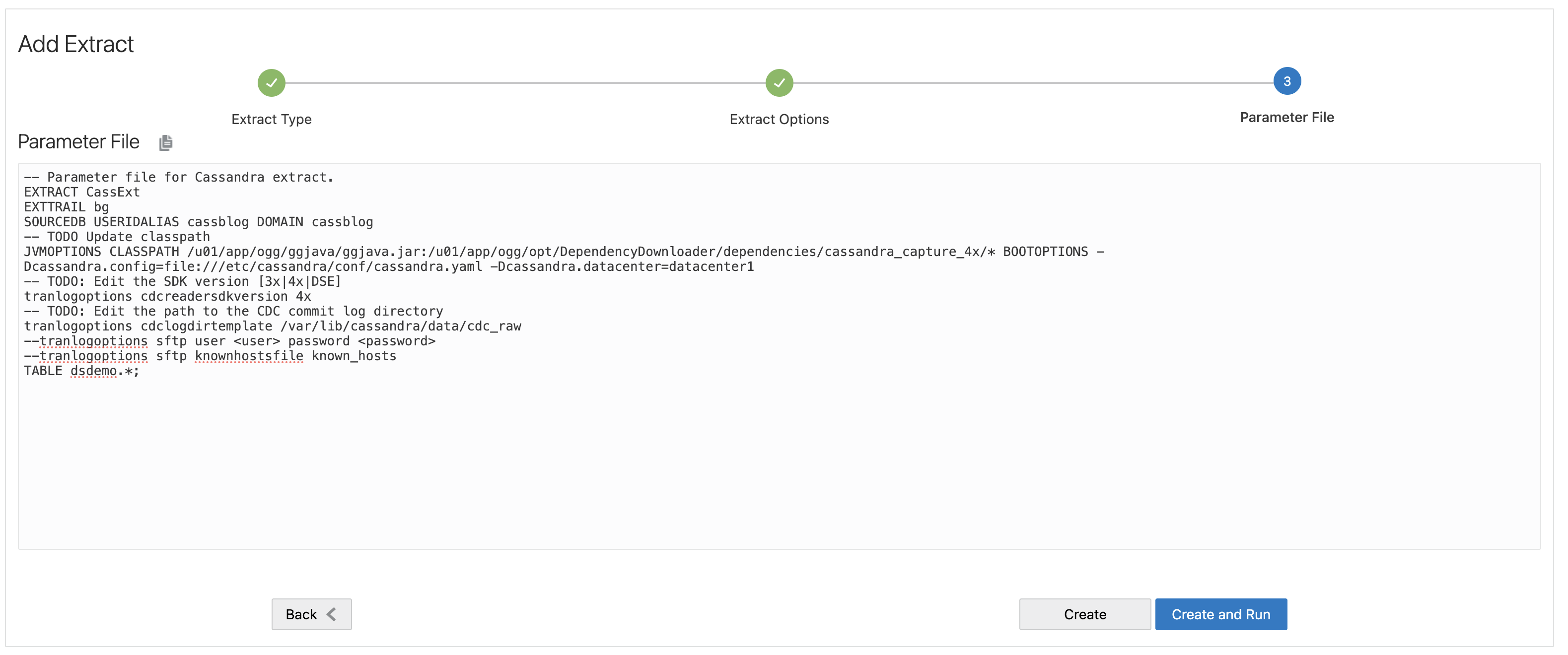
- Update JVMOPTIONS CLASSPATH and BOOTOPTIONS:
- Click Create and Run. If extract runs successfully, it will be checked with a green check. On the extract, click Action/ Details and click Statistics. If you don’t see any Table Statistics and no messages under Run Time Messages in Report file, it means that Cassandra has not flushed cdc commitlog files. You can restart Cassandra nodes to flush the commitlogs. This case is valid for testing Cassandra extract with few source operations. After Cassandra restart, you will need to restart the extract as well (it will abend as connection is lost during Cassandra restart). After Cassandra and Extract is restarted, check Statistics again. You should see the extract statistic populated.
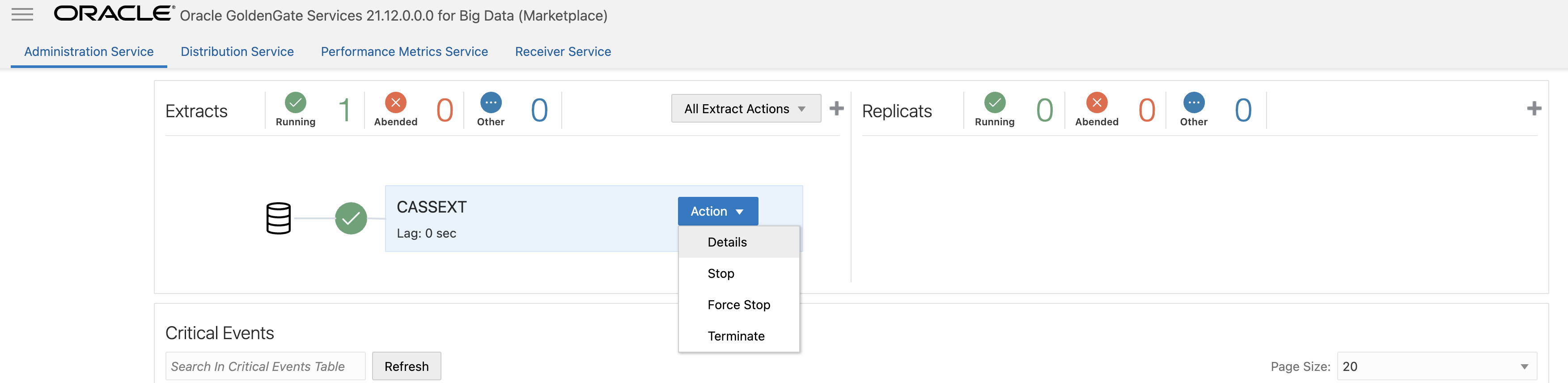

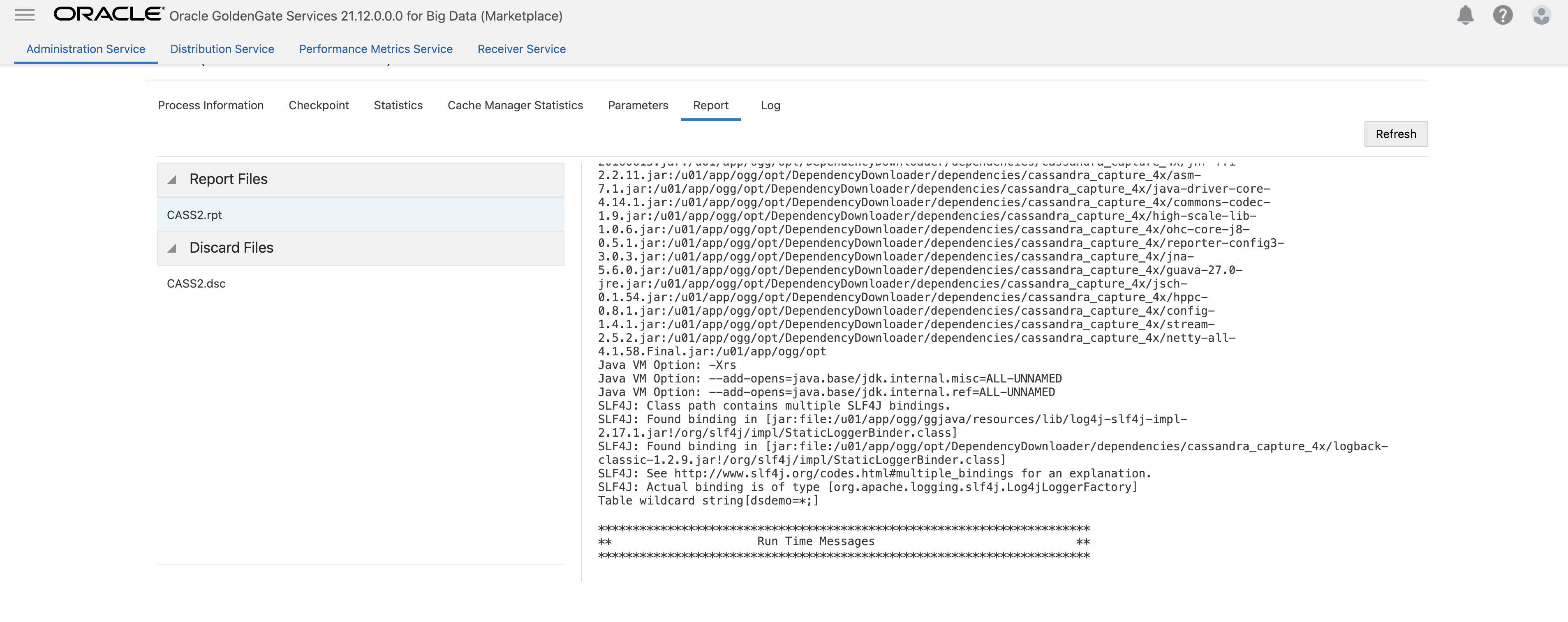
After Cassandra restart:
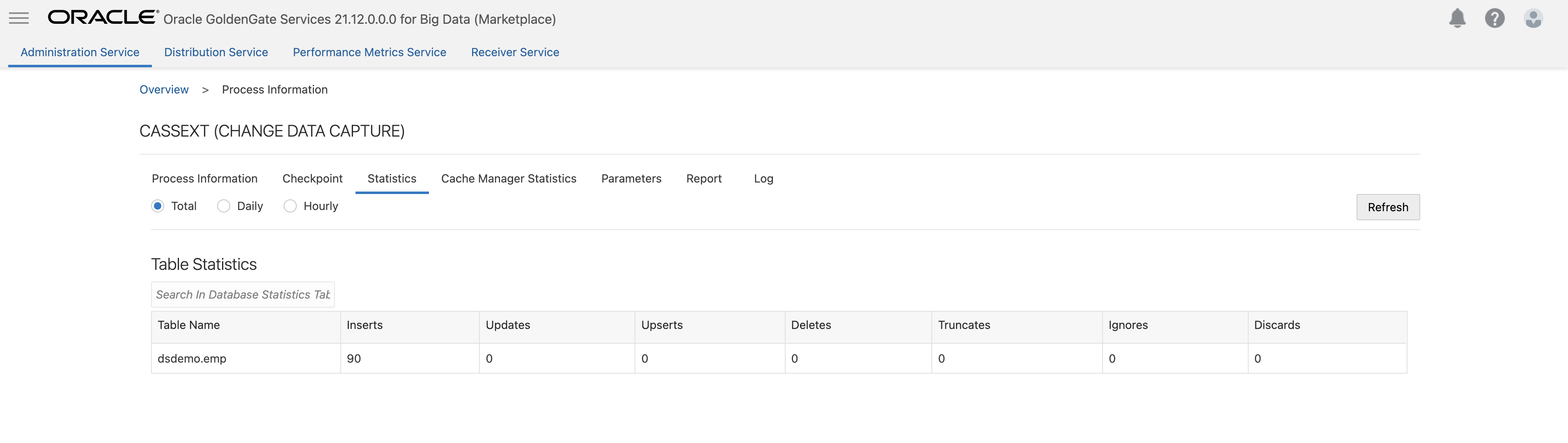
Cassandra Extract Troubleshooting:
- If your source is Datastax DSE and it is on a different server than GoldenGate for Big Data, copy Datastax DSE installation directories to GoldenGate for Big Data server. GoldenGate for Big Data uses some of the libraries from Datastax DSE installation. If not, Cassandra extract will abend with NoClassDefFoundError.
For example: Exception in thread “Thread-1” java.lang.NoClassDefFoundError: com/datastax/oss/driver/api/core/metadata/NodeStateListener - If you do not grant read access to cdc commitlog directory, GoldenGate for Big Data will not be able to read the commitlog files. In that case, extract will start; but no data will be captured.
- Cassandra applies frequent changes to their code for improvements and it impacts the extract behaviour as GoldenGate uses Cassandra classes. You can review the report file for error messages. In some Cassandra versions, we saw that Cassandra checks for some of the paths in cassandra.yaml file even if these paths are not used by GoldenGate. In such a case, you can create a dummy path in GoldenGate for Big Data server and Cassandra can check if that path exists.
For example: Exception occurred: [{}] org.apache.cassandra.exceptions.ConfigurationException: commitlog directory ‘/cassandra/commitlog/commitlog’ or, if it does not already exist, an existing parent directory of it, is not readable and writable for the DSE. Check file system and configuration.
For more details about configuring Cassandra Capture, please refer to GGBD product documentation.
