In this post I’ll cover some new capabilities in the Apache Spark 1.1 release and show what they mean to ODI today. There’s a nice slide shown below from the Databricks training for Spark SQL that pitches some of the Spark SQL capabilities now available. As well as programmatic access via Python, Scala, Java, the Hive QL compatibility within Spark SQL is particularly interesting for ODI…… today. The Spark 1.1 release supports a subset of the Hive QL features which in turn is a subset of ANSI SQL, there is already a lot there and it is only going to grow. The Hive engine today uses map-reduce which is not fast today, the Spark engine is fast, in-memory – you can read much more on that elsewhere.
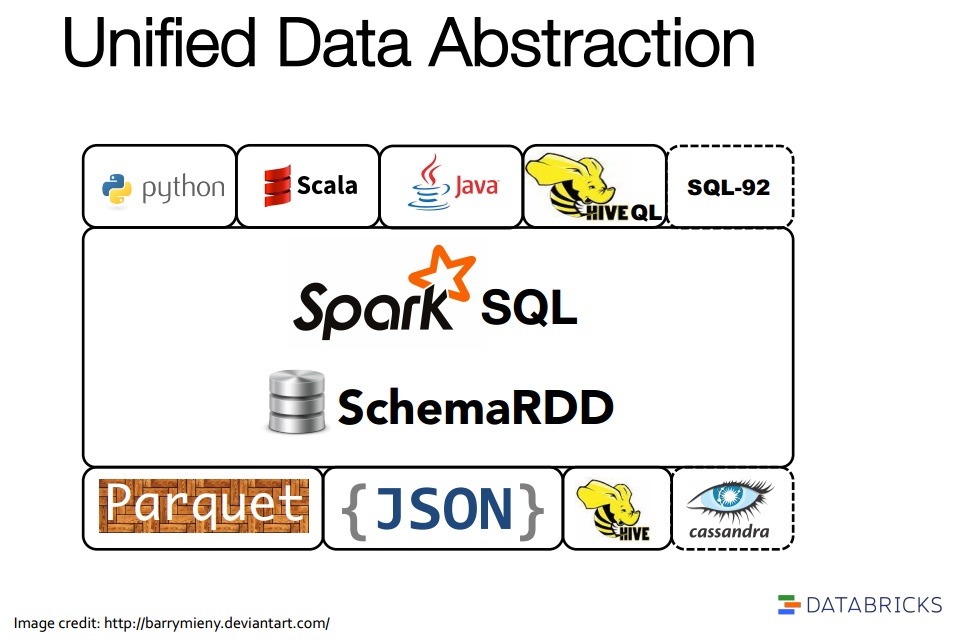
Figure taken from from the Databricks training for Spark SQL, July 2014.
In the examples below I used the Oracle Big Data Lite VM, I downloaded the Spark 1.1 release and built using Maven (I was on CDH 5.2). To use Spark SQL in ODI, we need to create a Hive data server – the Hive data server masquerades as many things, it can can be used for Hive, for HCatalog or for Spark SQL. Below you can see my data server, note the Hive port is 10001, by default 10000 is the Hive server port – we aren’t using Hive server to execute the query, here we are using the Spark SQL server. I will show later how I started the Spark SQL server on this port (Apache Spark doc for this is here).
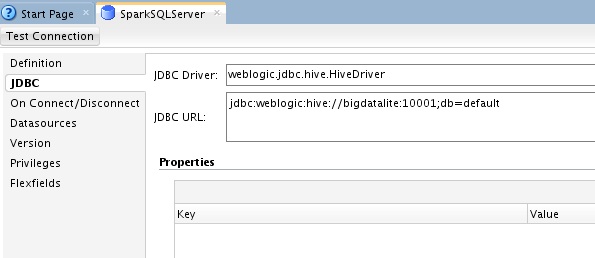
I started the server using the Spark standalone cluster that I configured using the following command from my Spark 1.1 installation;
./sbin/start-thriftserver.sh –hiveconf hive.server2.thrift.bind.host bigdatalite –hiveconf hive.server2.thrift.port 10001 –master spark://192.168.122.1:7077
You can also specify local (for test), Yarn or other cluster information for the master. I could have just as easily started the server using Yarn by specify the master URI as something like –master yarn://192.168.122.1:8032 where 8032 is my Yarn resource manager port. I ran using the 10001 port so that I can run both Spark SQL and Hive engines in parallel whilst I do various tests. To reverse engineer I actually used the Hive engine to reverse engineer the table definitions in ODI (I hit some problems using the Spark SQL reversing, so worked around it) and then changed the model to use my newly created Spark SQL data server above.
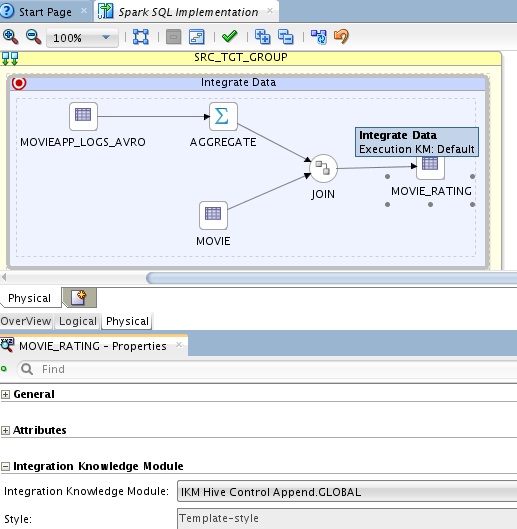
Then I built my mappings just like normal – and used the KMs in ODI for Hive just like normal. For example the mapping below aggregates movie ratings and then joins with movie reference data to load movie rating data – the mapping uses the datastores from a model obtained from the Hive metastore;
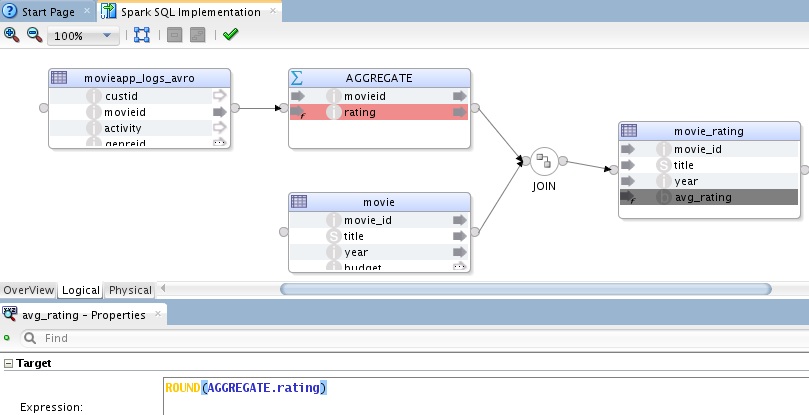
If you look at the physical design the Hive KMs are assigned but we will execute this through the Spark SQL engine rather than through Hive. The switch from engine to engine was handled in the URL within our our Hive dataserver.
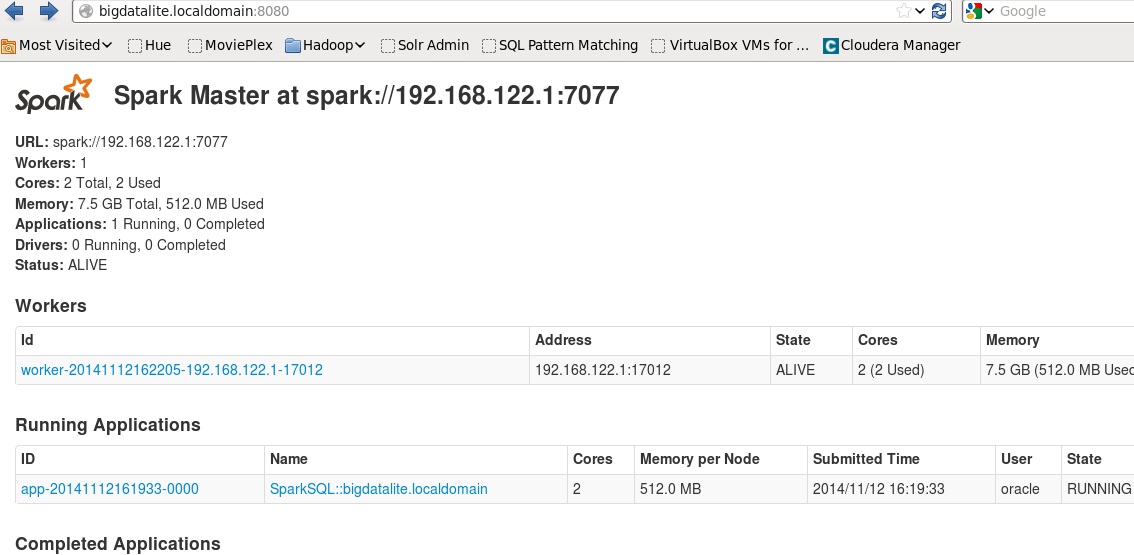
When the mapping is executed you can use the Spark monitoring API to check the status of the running application and Spark master/workers.
You can also monitor from the regular ODI operator and ODI console. Spark SQL support uses the Hive metastore for all the table definitions be they internally or externally managed data.
There are other blogs from tools showing how to access and use Spark SQL, such as the one here from Antoine Amend using SQL Developer. Antoine has also another very cool blog worth checking out Processing GDELT Data Using Hadoop. In this post he shows a custom InputFormat class that produces records/columns. This is a very useful post for anyone wanting to see the Spark newAPIHadoopFile api in action. It has a pretty funky name, but is a key piece (along with its related methods) of the framework.
- // Read file from HDFS – Use GdeltInputFormat
- val input = sc.newAPIHadoopFile(
- “hdfs://path/to/gdelt”,
- classOf[GdeltInputFormat],
- classOf[Text],
- classOf[Text]
- )
Antoine also provides the source code to GdeltInputFormat so you can see the mechanics of his record reader, although the input data is delimited data (so could have been achieved in different ways) it’s a useful resource to be aware of.
If you are looking at Spark SQL, this post was all about using Spark SQL via the JDBC route – there is another whole topic on transformations using the Spark framework alongside Spark SQL that is for future discussion. You should be aware of and check out the Hive QL compatibility documentation here, check what you can do can’t do within Spark SQL today. Download the BDA Lite VM and give it a try.
