contributed by Ayush Ganeriwal
In this post we shall discuss the new in-session parallelism
introduced in the ODI12c release. ODI12c now comes with the intelligence to
concurrently execute part of the mappings that are independent of each other.
For example the data load into C$ tables from two disparate data source is done
in parallel as these operations are independent of each other and can be done
simultaneously. Similarly, such parallelism can be achieved for flow control
and target loads too in different use cases. ODI12c automatically identifies
the session tasks that can be executed concurrently and generates code for
their parallel execution. Users can visually see what part of the mapping would
be executed in parallel and if needed this behavior can be changed to execute
tasks sequentially if the business logic demands so.
Parallelism Display in Deployment Plan
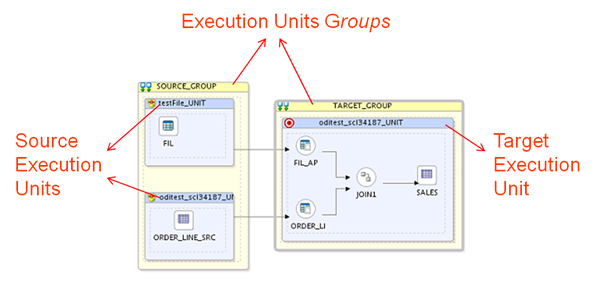
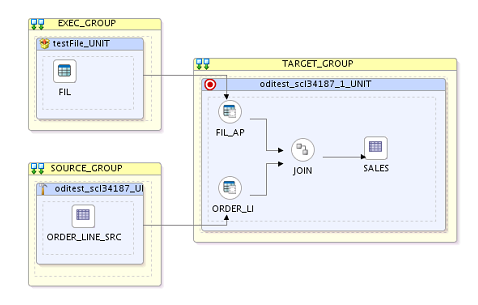
A typical deployment plan is shown above where the data from
a file and relations data store are first loaded into C$ tables in staging area
and then joined and loaded into target table. Here different source stores and
their corresponding C$ tables, join components and, the target data store are
organized in separate blue and yellow boxes which are called execution units
and execution unit groups respectively. Execution unit group contains one or
more execution units which are independent of each other and can be executed
concurrently. Execution unit contains the set of operations that need to be
executed serially. In above example the SOURCE_GROUP contains two execution
units which are independent of each other and are executed in parallel. The
TARGET_GROUP contains only one execution unit indicating absence of
parallelism.
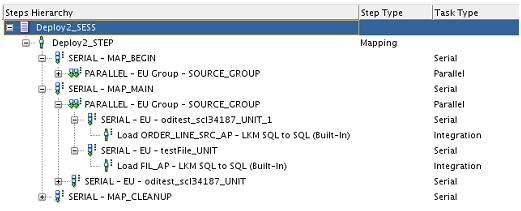
How is parallelism achieved within a session?
The session tasks within a step are now generated in a
hierarchical manner similar to a load plan steps hierarchy. There are a couple
of new type of tasks introduced namely Serial task and Parallel task. These are
container tasks which can have one or more child tasks under them. As the name
suggests the child tasks under a serial container task would be executed
serially whereas the children tasks of parallel container task would be
executed in parallel. These container tasks can be nested within each other
resulting in multiple levels in the task hierarchy. Depending upon the
deployment plan, ODI12c generates the hierarchy of these serial and parallel tasks
to achieve in session parallelism. Here is example of a serial and parallel
task hierarchy.
Mapping segments candidate for Parallelism
Following below are some of the common mapping parts under
which tasks are usually independent of each other and can be performed
simultaneously.
1. Loading source data into staging area
2. Loading data into multiple target tables
3. Performing flow control on I$ table
These are some of the common candidate area for parallelism
and depending upon the mapping flow there may be other areas that could be
executed in parallel. Let’s look at an example of one of the above common
parallelism candidates and see how the behavior can be altered by tweaking the deployment
plan.
Loading source data
into staging area
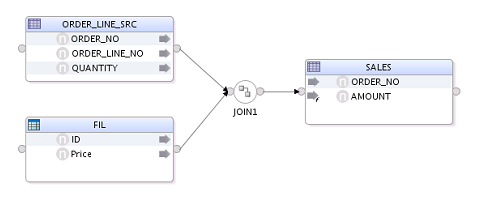
In this mapping a file and DB table are joined and then
loaded in the target table. ODI generates following deployment plan for it so
that the sources can be loaded in collector tables in staging are concurrently and
then join and target load related tasks performed sequentially.
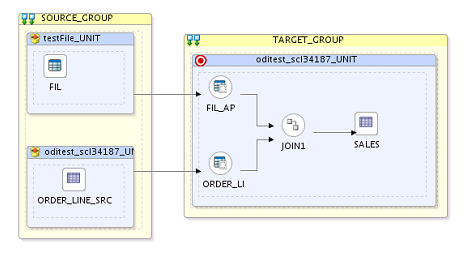
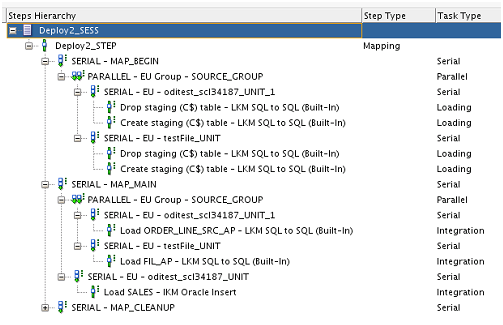
On executing the mapping with this deployment plan the tasks
hierarchy is generated as follows. We can notice here that following set of
tasks are organized under parallel container task
a. LKM tasks for dropping and recreating C$ tables
for each data sources
b. LKM task to load data into each of the C$ tables
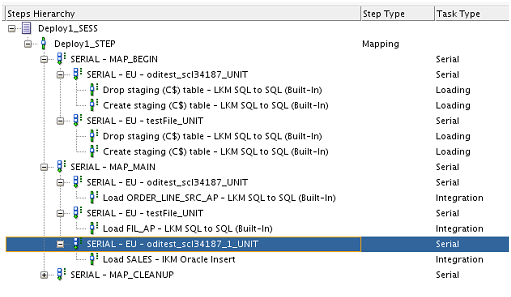
Suppose we do not want these C$ tables to be loaded in
parallelly and rather want them to load sequentially then we can achieve that
by simply modifying deployment plan by dragging and dropping one of the
execution unit outside of the execution unit group. This would create a
separate execution unit group for each of the source dataset forcing all the
execution units to run serially.
On executing the task hierarchy of it is generated as
follows showing serial execution of all tasks.
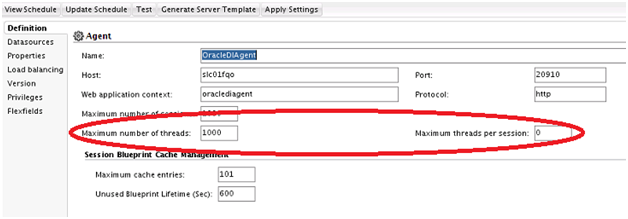
Threads configuration for parallel tasks
ODI12c runtime spawns a separate thread for each of the
parallel tasks in a session. This effectively means that execution of a highly
parallelize mapping may take high number of threads exhausting all system
resources. ODI provide two level of configuration to control the number of such
parallel threads in the physical agent configuration. One to control the
maximum number of threads in the agent and other is to control max thread count
within a session. A parallel task would be started only if a new thread can be
spawned according to these thread configurations. Therefore, these should be
kept at sufficiently large levels.
Connection management for parallel task
Since each of the parallel tasks is executed by a separate
thread, they should not work on the common connection for any non-transactional
behavior. So for performing the non-transactional operations each of the
parallel tasks acquires its own parallel connection from the connection pool.
Therefore, for highly parallel mappings the connection pool size should be
configured appropriately according to the level of parallelism.
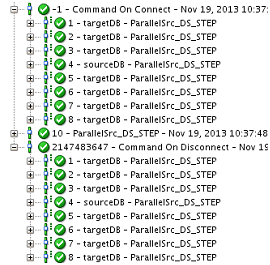
One other point to keep in mind here is that since each
parallel task acquires a new auto-commit connection closes it on task
completion thus the OnConnect/OnDisconnect tasks would be executed while
creating and closing of such connection. Thus you may see multiple
OnConnect/OnDisconnect tasks entries for a mapping having parallel tasks.
Another implication of such parallelism is that any parallel
tasks cannot rely on any alteration in database connection done by the earlier
tasks because each of the parallel tasks would get a new connection which would
be unaware of any operations performed by earlier tasks.
For operations performed on a transaction connection the
parallel tasks do not have much flexibility and has to perform operations one
by one. For such transactional connections synchronization is maintained so
that only one parallel task can perform operation on the connection. Thus
having parallel tasks participating in such transactions may actually degrade
performance due to the extra locking/unlocking for such synchronization.
The take-away
ODI12c allows parallelizing parts of a mapping to achieve extreme
performance. It has the intelligence to automatically identify parallelizable
parts within a mapping and also provide flexibility to achieve serial behavior
for special business needs. Such parallelism would result in an improved
performance and for even higher levels of parallelism the connections pool and
thread count can be further fine tuned.
For more uptodate Oracle Data Integration news also follow
the twitter feeds from @ORCLGoldenGate and @nmadhu2k3.