Use case: Real-time replication of transaction data from an on-premises database to Amazon Managed Streaming for Apache Kafka MSK) using GoldenGate & GoldenGate for Big Data with TLS Client authentication.
Architecture:
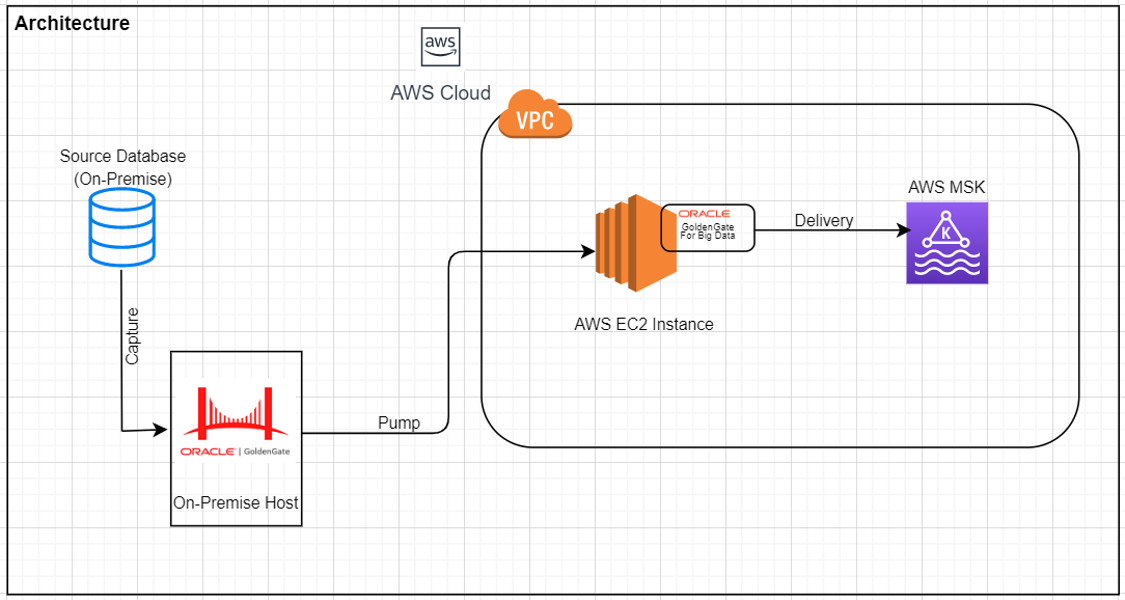
- GoldenGate 19.1
(Source Database can be any of the GoldenGate supported databases) - GoldenGate for Big Data 19.1
- AWS EC2 Instance
- Amazon MSK
Pre-Requisite Steps:
- GoldenGate should be already configured to extract data from the source database and to pump extract trails to AWS EC2 instance.
- VPC and subnets already configured in AWS Cloud
- Replication to AWS MSK Kafka Cluster doesn’t require any special Kafka handler, default GoldenGate For Big Data Kafka Handler can be used.
- AWS EC2 instance already provisioned with enough storage to hold GoldenGate trail files.
Connecting To Your Linux Instance from Windows Using PUTTY
- Please refer to the following link & the instructions in it that explain how to connect to your instance using PUTTY.
- And also on how to Transfer files to your instance using WinSCP.
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/putty.html
- And also on how to Transfer files to your instance using WinSCP.
Download, Installation and Configuration of the GoldenGate for Big Data Binaries, Java (JDK or JRE) version 1.8 & Kafka Client Binaries
- Download GoldenGate for Big Data 19.1 from the following location: https://www.oracle.com/middleware/technologies/goldengate-downloads.html
- The Oracle GoldenGate for Big Data is certified for Java 1.8. Before installing and running Oracle GoldenGate 19.1, you must install Java (JDK or JRE) version 1.8 or later. Either the Java Runtime Environment (JRE) or the full Java Development Kit (which includes the JRE) may be used.
sudo yum install java-1.8.0
- Create an Amazon MSK Cluster, you can use Amazon MSK to create clusters that use Apache Kafka version 1.1.1, 2.2.1, 2.3.1, or 2.4.1.
You can create Amazon MSK cluster either through AWS Management Console or through AWS CLI. Follow the link for reference
https://docs.aws.amazon.com/msk/latest/developerguide/msk-create-cluster.html
- Run the following command to download Apache Kafka client (for example Kafka 2.2.1) on the EC2 machine.
wget https://archive.apache.org/dist/kafka/2.2.1/kafka_2.12-2.2.1.tgz
tar -xzf kafka_2.12-2.2.1.tgz
- Before moving onto installing and configuring GoldenGate for Big Data 19.1, we can set up client authentication (in our case EC2 instance) To enable client authentication with TLS for connections from GoldenGate to AWS MSK brokers, it needs an ACM Private Certificate configured by Certificate Authority.
- To create a cluster that supports client authentication and to set up a client to use authentication, configure the certificate on EC2 where you’ll be running GoldenGate for Big data. Refer to the following link for details:
https://docs.aws.amazon.com/msk/latest/developerguide/msk-authentication.html
This step is really important, as any data being replicated is encrypted with TLS 1.2. By default, it encrypts data in transit between the brokers of your MSK cluster. So, whenever the client machine connects to the AWS MSK Cluster it presents this certificate.
- Create a file named client.properties under bin directory of Kafka client installation. Make sure to add the following ssl configurations to client.properties file as a last step for enabling SSL.
security.protocol=SSL
ssl.truststore.location=/tmp/kafka_2.12-2.2.1/kafka.client.truststore.jks
ssl.keystore.location=/tmp/kafka_2.12-2.2.1/kafka.client.keystore.jks
ssl.keystore.password=Your-Store-Pass
ssl.key.password=Your-Key-Pass
- Unzip the GoldenGate for big data (19.1) zip file:

- Now extract the GoldenGate 19.1.tar file using “tar -xvf” command.

- After the “tar –xvf” operation finishes, the entire GoldenGate directory structure looks like this:
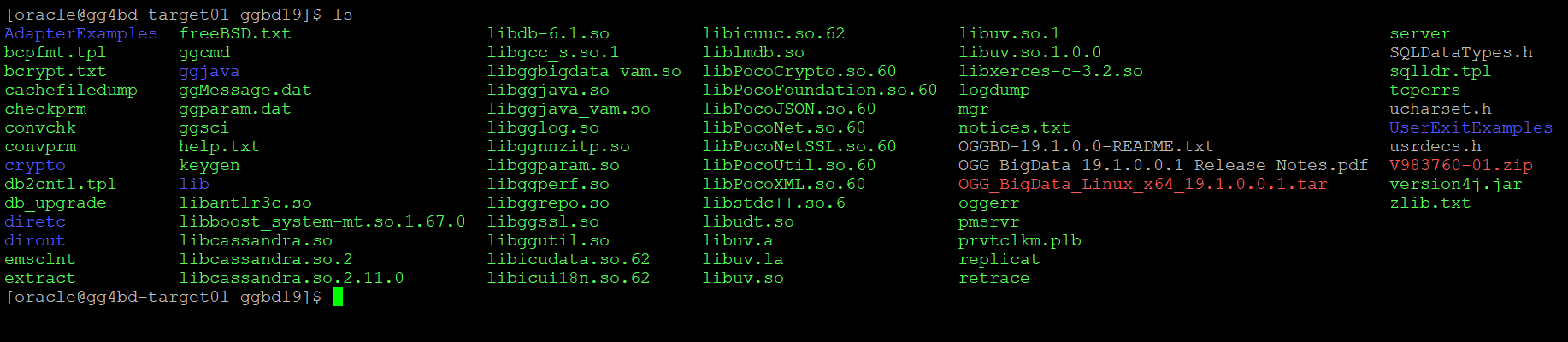
- You can have a look at the directory structure( files extracted) and then go to “AdapterExamples” directory to make sure kafka handler is extracted:

- The Kafka directory under big-data contains Kafka Replicat parameter file(kafka.prm),Kafka properties file (kafka.props) and Kafka producer file

- Export the JAVA_HOME & LD_LIBRARY_PATH as shown below:
export JAVA_HOME=<path-to-Java-1.8>/jre1.8.0_181
export LD_LIBRARY_PATH=<path-to-Java 1.8>/lib/amd64/server:$JAVA_HOME/lib

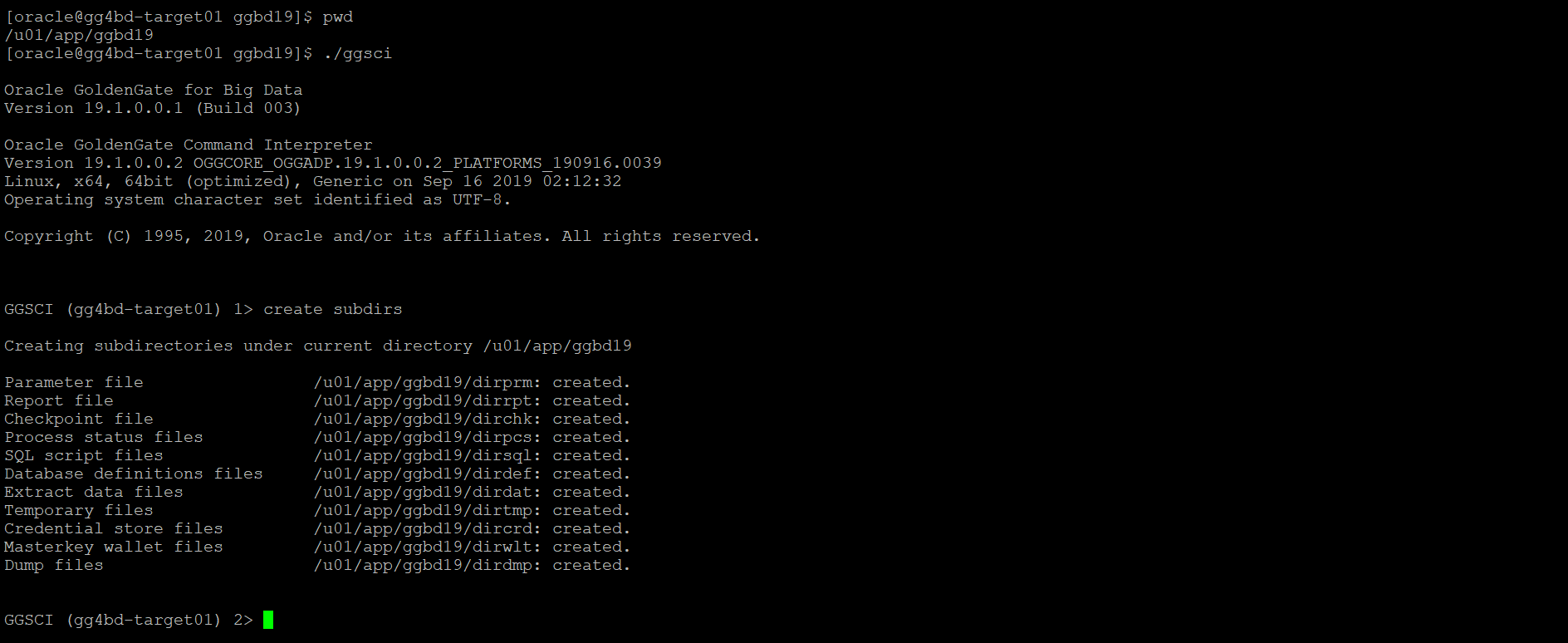
- Once you’re done, log into GoldenGate Instance using ./ggsci command and issue create subdir command to create the GoldenGate specific directories:
- Configure the Manager parameter file and add an open PORT to it:
Example: edit param mgr
PORT 1080
- Copy these three files (custom_kafka_producer.properties kafka.props rkafka.prm) of the replicat (from ./AdapterExamples/big-data/kafka) to ./dirprm directory of the GoldenGate Instance.
- Traverse back to GoldenGate Directory, execute ./ggsci and Add replicat in the GoldenGate instance using the following command:
add replicat rawsmsk, exttrail <source_Trail_files_location>
[NOTE: A demo trail is already present at the location: AdapterExamples/trail/tr]
- Once your AWS MSK cluster is in ACTIVE state, run the AWS CLI describe-cluster command on EC2 to get the ZookeeperConnectString. To get the AWS MSK Cluster ZookeeperConnectString, run the following command on EC2 using AWS CLI:
aws kafka list-clusters –region <region-name eg:us-east-1>
Create an Apache Kafka topic using ZookeeperConnectString in Kafka distribution create topic script/utility:
bin/kafka-topics.sh –create –zookeeper <ZookeeperConnectString> –replication-factor 3 –partitions 1 –topic <specify-topic-name-here>
A word of caution, we cannot have a replication factor greater than the number of broker nodes. So, make sure while creating Topics you have a replication factor less than or equal to the number of broker nodes of AWS MSK cluster.
- Here GoldenGate acts as a Producer to AWS MSK Kafka stream, so to be able to replicat data to AWS MSK bootstrap server property needs to be specified in the custom_kafka_producer.properties file. The Broker servers connect string can be obtained through either the AWS Management Console or the AWS CLI command.
https://docs.aws.amazon.com/msk/latest/developerguide/msk-get-bootstrap-brokers.html - To get the AWS MSK Cluster Boostrap Broker string run the following command on EC2 using AWS CLI:
aws kafka get-bootstrap-brokers –cluster-arn <ClusterArn>
Replace ClusterArn with the Amazon Resource Name (ARN) that was obtained when AWS MSK cluster was created.
- Make the necessary changes to each of the GoldenGate configuration file as below:
custom_kafka_producer.properties file:
| #Bootstrap broker string obtained from Step above bootstrap.servers= <Bootstrap_broker_string> #bootstrap.servers=localhost:9092 acks=1 reconnect.backoff.ms=1000 value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer # 100KB per partition batch.size=16384 linger.ms=0 |
Kafka Replicat Parameter file:
| REPLICAT rawsmsk — Trail file for this example is located in “AdapterExamples/trail” directory — Command to add REPLICAT — add replicat rawsmsk, exttrail AdapterExamples/trail/tr TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props REPORTCOUNT EVERY 1 MINUTES, RATE GROUPTRANSOPS 10000 MAP <SOURCE_schema_name>.*, TARGET <topic_name>.*; |
Kafka Replicat Properties file:
| gg.handlerlist = kafkahandler gg.handler.kafkahandler.type=kafka gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties #The following resolves the topic name using the short table name #gg.handler.kafkahandler.topicName=<topic_name> gg.handler.kafkahandler.topicMappingTemplate=${tableName} #The following selects the message key using the concatenated primary keys gg.handler.kafkahandler.keyMappingTemplate=${primaryKeys} gg.handler.kafkahandler.format=json_row #gg.handler.kafkahandler.format=delimitedtext #gg.handler.kafkahandler.SchemaTopicName=mySchemaTopic #gg.handler.kafkahandler.SchemaTopicName=<topic_name> gg.handler.kafkahandler.BlockingSend =false gg.handler.kafkahandler.includeTokens=false gg.handler.kafkahandler.mode=op goldengate.userexit.timestamp=utc goldengate.userexit.writers=javawriter javawriter.stats.display=TRUE javawriter.stats.full=TRUE gg.log=log4j gg.log.level=INFO gg.report.time=30sec gg.classpath=dirprm/:<kafka_Client_path>/libs/*:<kafka_client_path>/config javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar gg.handler.kafkahandler.format.pkUpdateHandling=update |
- After making all the necessary changes you can start the Kafka replicat, which would replicate the trail data to AWS MSK Kafka stream.
- Crosscheck for Kafka replicat’s(rawsmsk) status, RBA and stats.
- Once you get the stats, you can view the rawsmsk.log from. /dirrpt directory which gives information about data sent to Kafka stream and operations performed.
- There are two ways to monitor the AWS MSK metrics:
The Kafka distribution provides a command utility to see messages from the command line. It displays the messages in various modes. Kafka provides the utility kafka-console-consumer.sh which is located at <kafka_installation>/kafka/bin/kafka-console-producer.sh to receive messages from a topic on the command line.
bin/kafka-console-consumer.sh –bootstrap-server <AWS_MSK_BootstrapBroker-String> –topic <Topic_name> –from-beginning
You can also monitor the metrics of AWS MSK kafka stream through AWS CloudWatch. AWS MSK and Amazon CloudWatch are integrated so that you can collect, view, and analyze CloudWatch metrics for your Kafka stream.
Content contributed by Mr. Shrinidhi Kulkarni, Staff Solution Engineer, Solution Engineering NA Technology, Oracle
